侯捷 C++ STL标准库和泛型编程 —— 4 分配器 + 5 迭代器
4 分配器
4.1 测试
分配器都是与容器共同使用的,一般分配器参数用默认值即可
list<string, allocator<string>> c1;
不建议直接用分配器分配空间,因为其需要在释放内存时也要指明大小
int* p;
p = allocator<int>().allocate(512, (int*)0); // 临时变量调用函数
allocator<int>().deallocate(p,512); // 释放时需要指明之前申请的大小
4.2 源码解析
VC6下:allocator 中有 allocate,deallocate 其分别用函数 ::operator new 和 ::operator delete 来调用 c 中的 malloc 和 free
pointer allocate(size_type _N, const void*){...} // 后面一个参数只是用来指明类型的
void deallocate(void _FARQ *_P, size_type){...}
这里经过包装还是调用的 malloc 和 free,其执行效率变慢;且如果申请的空间比较小,会有较大比例的额外开销(cookie,调试模式所需空间等等)
GCC2.9 下:其容器都是调用的名叫 alloc 的分配器

其从0到15有一共16个链表,分别代表8字节到16*8字节,例如 #0 的位置用 malloc 要一大块内存,然后做切割,切成一块一块的8字节空间不带cookie,用单向链表穿起来;当要申请6字节的大小的空间时,其就会到 #0 中占用一块 —— 节省空间
在 GCC4.9 中各个容器又用回了 allocator,而上面的 alloc 变成了
__poll_alloc
5 迭代器
5.1 迭代器的设计准则
Iterator 必须提供5种 associated type(说明自己的特性的)来供算法来识别,以便算法正确地使用 Iterator
template <class T, class Ref, class Ptr>
struct __list_iterator
{
...
typedef bidirectional_iterator_tag iterator_category; // (1)迭代器类别:双向迭代器
typedef T value_type; // (2)迭代器所指对象的类型
typedef Ptr pointer; // (3)迭代器所指对象的指针类型
typedef Ref reference; // (4)迭代器所指对象的引用类型
typedef ptrdiff_t difference_type; // (5)两个迭代器之间的距离类型
// iter1-iter2 时,要保证数据类型以存储任何两个迭代器对象间的距离
...
}
// 迭代器回答
// | Λ
// | |
// | |
// V |
// 算法直接提问
template <typename I>
inline void algorithm(I first, I last)
{
...
I::iterator_category
I::pointer
I::reference
I::value_type
I::difference_type
...
}
但当 Iterator 并不是 class 时,例如指针本身,就不能 typedef 了 —— 这时就要设计一个 Iterator Traits
Traits:用于定义类型特征的信息,从而在编译时根据类型的不同进行不同的操作或处理 —— 类似一个萃取机(针对不同类型做不同操作:偏特化)

// I是class iterator进
template <class I>
struct Iterator_traits
{
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
// typename用于告诉编译器,接下来的标识符是一个类型名,而不是一个变量名或其他名称
// I::iterator_category 是一个类型名
// iterator_category是这个迭代器类型内部的一个嵌套类型(typedef ...)
};
// I是指向T的指针进
template <class T>
struct Iterator_traits<T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
// I是指向T的常量指针进
template <class T>
struct Iterator_traits<const T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type; // 注意是T而不是const T
// 按理说是const T,但声明一个不能被赋值的变量无用
// 所以value_type不应加上const
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
除了 Iterator Traits,还有很多其他 Traits
5.2 迭代器的分类
迭代器的分类对算法的效率有很大的影响
- 输入迭代器 input_iterator_tag:istream迭代器
- 输出迭代器 output_iterator_tag:ostream迭代器
- 单向迭代器 forward_iterator_tag:forward_list,hash类容器
- 双向迭代器 bidirectional_iterator_tag: list、红黑树容器
- 随机存取迭代器 random_access_iterator_tag:array、vector、deque

用有继承关系的class实现:
- 方便迭代器类型作为参数进行传递,如果是整数的是不方便的
- 有些算法的实现没有实现所有类型的迭代器类别,就要用继承关系去找父迭代器类别
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
算法 distance 将会按照迭代器的类别进行不同的操作以提升效率
- 如果迭代器可以跳,直接
last - first即可 - 如果迭代器不能跳,就只能一步一步走来计数
两者的效率差别很大

但如果迭代器类别是
farward_iterator_tag或者bidirectional_iterator_tag,该算法没有针对这种类型迭代器实现,就可以用继承关系来使用父类的实现(继承关系——“is a” 子类是一种父类,当然可以用父类的实现)
算法 copy 将经过很多判断筛选来找到最高效率的实现
其中用到了 Iterator Traits 和 Type Traits 来进行筛选
has trivial op=() 是指的有不重要的拷贝赋值函数(例如复数用的自带的拷贝赋值函数)
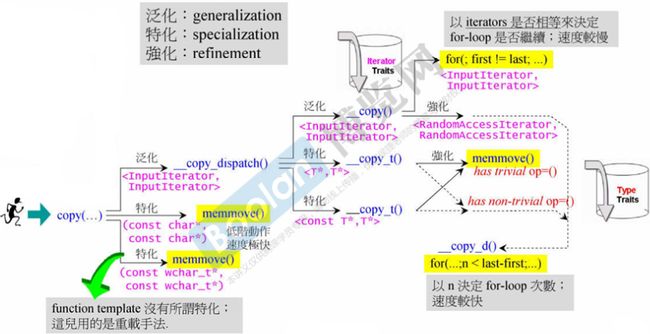
注意:由于 output_iterator_tag(例如 ostream_iterator)是 write-only,无法用
*来读取内容,所以在设计时就需要再写个专属版本
在源码中,算法都是模板函数,接受所有的 iterator,但一些算法只能用特定的 iterator,所以其会在模板参数的名称上进行暗示:
