整理
官网样例:https://docs.opencv.org/3.4.1/modules.html
1、图像处理基本操作
(1)、图像、视频的读入、显示以及写入
cv.imread()
cv.imshow()
cv.imwrite()
cv.VideoCapture()#摄像头读取
cv.namedWindow()#建立一个窗口
cv.waitKey()
cv.destoryAllWindows()
也可用:cv2.cv的LoadImage、ShowImage和SaveImage函数
(2)、图片属性获取:
print img.shape
# (640, 640, 3)
print img.size
# 1228800
print img.dtype
# uint8
# 在debug的时候,dtype很重要
(3)、cv.putText()在图像上输上文本并输出
cv2.putText(img, str(i), (123,456)), font, 2, (0,255,0), 3)
各参数依次是:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
(4)、cv.resize()图像的缩放
cv2.resize(src,dsize,dst=None,fx=None,fy=None,interpolation=None)
scr:原图,dsize:输出图像尺寸,fx:沿水平轴的比例因子,fy:沿垂直轴的比例因子,interpolation:插值方法
例:
res = cv.resize(src,None,fx=0.5,fy=0.5,interpolation=cv.INTER_CUBIC)
(5)、cv.warpAffine()图像的平移
第二个参数为变换矩阵 ,第三个参数为变换后尺寸,先列后行
rows,cols,ch = src.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(src,M,(cols,rows))
插播一张很厉害的图:
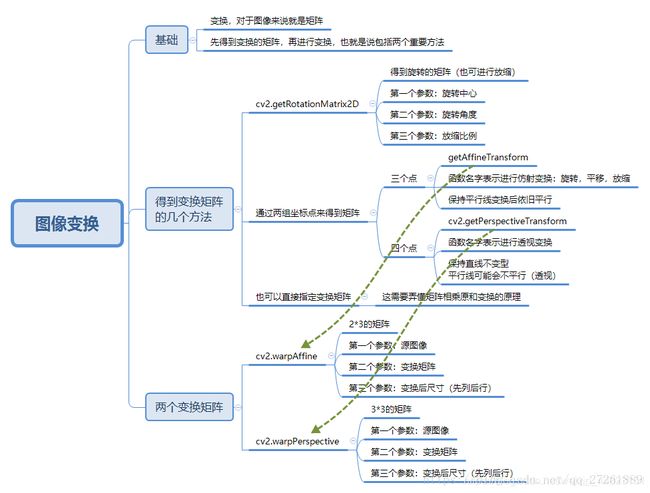
(6)、cv2.getRotationMatrix2D():图像的旋转
第一个参数:旋转中心,(x,y);第二个参数:旋转角度;第三个参数:缩放比例
M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1)
(7)、仿射变换------没搞懂
缩放(Scale)、平移(transform)、旋转(rotate)、反射(reflection, 对图形照镜子)、错切(shear mapping,感觉像是一个图形的倒影)
或者它们的任意组合。
仿射变换中集合中的一些性质保持不变:
(1)凸性
(2)共线性:若几个点变换前在一条线上,则仿射变换后仍然在一条线上
(3)平行性:若两条线变换前平行,则变换后仍然平行
(4)共线比例不变性:变换前一条线上两条线段的比例,在变换后比例仍然步
注:所有的三角形都能通过仿射变化为其他三角形,所有平行四边形也能仿射变换为另一个平行四边形。
例:
rows,cols,ch = src.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(src,M,(cols,rows))
(8)、cv.copyMakeBorder()为图片添加边距
copyMakeBorder( const Mat& src, Mat& dst,int top, int bottom, int left, int right,int borderType, const Scalar& value=Scalar() )
src,dst:原图与目标图像top,bottom,left,right分别表示在原图四周扩充边缘的大小
borderType:扩充边缘的类型,就是外插的类型,OpenCV中给出以下几种方式
- BORDER_REPLICATE
- BORDER_REFLECT
- BORDER_REFLECT_101
- BORDER_WRAP
- BORDER_CONSTANT
例:
BLUE = [255,0,0]
replicate = cv.copyMakeBorder(src,10,10,10,10,cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(src,10,10,10,10,cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(src,10,10,10,10,cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(src,10,10,10,10,cv.BORDER_WRAP)
constant= cv.copyMakeBorder(src,10,10,10,10,cv.BORDER_CONSTANT,value=BLUE)
cv.imshow("input image",constant)
2、图像的算术预算与逻辑运算
注:要求进行算术运算与逻辑运算的图像尺寸必须相等,白色RGB均为255,黑色均为0,中间颜色进行加减,范围为0-255,0-任何值等于其本身,255+任何值不变
算术运算:
cv.add()
cv.subtract()
cv.multiply()
cv.divide()
逻辑运算:
cv.bitwise_and()
cv.biwise_or()
cv.bitwise_not()#非,按位取反
3、色彩空间的相互转换
常见色彩空间:RGB、HSV、HIS、YCrCB、YUV
色彩空间的相互转换:格式
gray=cv.cvtColor(image,cv.COLOR_BGR2GRAY)
hsv = cv.cvtColor(m, cv.COLOR_BGR2HSV)
yuv= cv.cvtColor(m, cv.COLOR_BGR2YUV)
4、cv.inRange():
第一个参数:image
第二个参数:lowerb—下阈值
第三个参数:upperb—上阈值
例:
#追踪或者提取图像中的某种颜色
hsv=cv.cvtColor(frame,cv.COLOR_BGR2HSV)#将视频的色彩空间改成HSV模式
lower_hsv=np.array([0,0,0])#该颜色的HSV三个的最低值
upper_hsv = np.array([180, 255, 46])#改颜色的HSV三个的最高值
mask=cv.inRange(hsv,lowerb=lower_hsv,upperb=upper_hsv)#对颜色HSV的最高、最低值进行范围限定,可取出属于这个范围内的颜色,HSV各颜色范围:https://blog.csdn.net/zdyueguanyun/article/details/50739374
5、cv.addWeighted()函数:是将两张相同大小,相同类型的图片融合的函数
参数1:src1,第一个原数组.
参数2:alpha,第一个数组元素权重
参数3:src2第二个原数组
参数4:beta,第二个数组元素权重
参数5:gamma,图1与图2作和后添加的数值。不要太大,不然图片一片白。总和等于255以上就是纯白色了。
参数6:dst,输出图片
例:调整亮度
h,w,ch=image.shape
blank=np.zeros([h,w,ch],image.dtype)#创建一个空白对象
dst=cv.addWeighted(image,c,blank,1-c,b)#起到调整亮度的作用
6、cv.split()和cv.merge()通道的合并与拆分:
用例:
b,g,r=cv.split(src)#颜色的通道分离
cv.imshow("blue",b)
cv.imshow("green",g)
cv.imshow("red",r)
src[:,:,2]=0#列表元素的设置
src=cv.merge([b,g,r])#通道合并
cv.imshow("changed_image",src)
7、滤波相关API:
原理推文:
(1)cv.blur()—均值模糊
均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标像素为中心的周围8个像素,构成一个滤波模板,即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
定义:blur(src,ksize,dst=None, anchor=None, borderType=None)
定义是有5个参数,但最后三个均为none,所以也就2个参数
src:要处理的原图像
ksize: 必须是奇数卷积核,周围关联的像素的范围:代码中(5,5)就是5*5的大小,就是计算这些范围内的均值来确定中心位置的大小
dst=cv.blur(image,(5,5))#括号中中的数值参数分别代表x、y方向上的模数值
(2)medianBlurDemo()—中值模糊,适用于去除椒盐噪声
定义:medianBlur(src, ksize, dst=None)
ksize与blur()函数不同,不是矩阵,而是一个数字,例如为5,就表示了5*5的方阵
dst=cv.medianBlur(image,5)
(3)cv.GaussianBlur()—高斯模糊,高斯模糊对高斯噪声有抑制作用
高斯模糊原理讲解:http://www.ruanyifeng.com/blog/2012/11/gaussian_blur.html
GaussianBlur( InputArray src, OutputArray dst, Size ksize,double sigmaX, double sigmaY = 0, int borderType = BORDER_DEFAULT );
第三个参数Size ksize: 高斯内核大小
第四个参数double sigmaX: 高斯核函数在X方向上的标准偏差
第五个参数 double sigmaY: 高斯核函数在Y方向上的标准偏差,如果sigmaY是0,则函数会自动将sigmaY的值设置为与sigmaX相同的 值,如果sigmaX和sigmaY都是0,这两个值将由ksize.width和ksize.height计算而来。具体可以参考getGaussianKernel()函数查看具体细节。建议将size、sigmaX和sigmaY都指定出来。
第六个参数 int borderType=BORDER_DEFAULT: 推断图像外部像素的某种便捷模式,有默认值BORDER_DEFAULT,如果没有特殊需要不用更改,具体可以参考borderInterpolate()函数。
例:
dst=cv.GaussianBlur(src1,(0,0),15)
(4)cv.bilateralFilter()—高斯双边模糊—祛斑、美颜效果可由其实现
第一个参数d:即 distance,常规为 0 ,像素的邻域直径,可有sigmaColor和sigmaSpace计算可得
第二个参数:色彩空间的sigma参数,该参数较大时,各像素邻域内相距较远的颜色会被混合到一起,从而造成更大范围的半相等颜色—尽量取大
第三个参数:坐标空间的sigma参数,该参数较大时,只要颜色相近,越远的像素会相互影响—尽量取小
例:
dst=cv.bilateralFilter(image,0,150,5)
(5)cv.pyrMeanShiftFiltering()—均值迁移模糊—类似于油画效果
第一个参数 sp:(The spatial window radius) 定义的漂移物理空间半径大小
第二个参数 sr:(The color window radius) 定义的漂移色彩空间半径大小;
例:
dst=cv.pyrMeanShiftFiltering(image,10,50)
(6)customBlurDeom()—自定义模糊
filter2D(src,ddepth,kernel):
ddepth:深度,输入值为-1时,目标图像和原图像深度保持一致
kernel: 卷积核(或者是相关核),一个单通道浮点型矩阵
kennel = np.array([[0,-1,0],[-1,5,-1],[0,-1,0]],np.float32)#锐化操作,照片更加立体清晰
dst=cv.filter2D(image,-1,kennel)
cv.imshow("customedBlur",dst)
8、cv.floodFill():泛洪填充
cv2.floodFill(img,mask,seed,newvalue(BGR),(loDiff1,loDiff2,loDiff3),(upDiff1,upDiff2,upDiff3),flag)
第二个参数:mask:为掩码层,使用掩码可以规定是在哪个区域使用该算法,如果是对于完整图像都要使用,则掩码层大小为原图行数+2,列数+2.是一个二维的0矩阵,边缘一圈会在使用算法是置为1。而只有对于掩码层上对应为0的位置才能泛洪,所以掩码层初始化为0矩阵。np.uint8
第三个参数:seed:为泛洪算法的种子点,也是根据该点的像素判断决定和其相近颜色的像素点,是否被泛洪处理
第四个参数:newvalue:是对于泛洪区域新赋的值(B,G,R)
第五个参数:是相对于seed种子点像素可以往下的像素值
第六个参数:是相对于seed种子点像素可以往上的像素值
第七个参数:flag:为泛洪算法的处理模式

例:
copyImg=image.copy()#复制一张
h,w=image.shape[:2]
mask=np.zeros([h+2,w+2],np.uint8)
#整张填充,起始位置、三个通道的颜色
cv.floodFill(copyImg,mask,(3,30),(0,255,255),(100,100,100),(50,50,50),cv.FLOODFILL_FIXED_RANGE)
#FLOODFILL_FIXED_RANGE该填充模式改变图像,泛洪填充
cv.imshow("fill_color",copyImg)
9、直方图相关API:
图像直方图,是指对整个图像在灰度范围内的像素值(0~255)统计出现频率次数,据此生成的直方图,称为图像直方图。反映了图像灰度的分布情况,是图像的统计学特征。
(1)cv.calcHist():3通道直方图
第一个参数:images参数表示输入图像,传入时应该用中括号[ ]括起来
第二个参数:channels参数表示传入图像的通道,如果是灰度图像,那就不用说了,只有一个通道,值为0,如果是彩色图像(有3个通道),那么值为0,1,2,中选择一个,对应着BGR各个通道。这个值也得用[ ]传入。
第三个参数: mask参数表示掩膜图像。如果统计整幅图,那么为None。主要是如果要统计部分图的直方图,就得构造相应的掩膜来计算。
第四个参数 :histSize参数表示灰度级的个数,需要中括号,比如[256]
第五个参数: ranges参数表示像素值的范围,通常[0,256]。此外,假如channels为[0,1],ranges为[0,256,0,180],则代表0通道范围是0-256,1通道范围0-180
例:
color=('blue','green','red')
for i,color in enumerate(color):# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据下标和数据,一般用在 for 循环当中。
hist=cv.calcHist([image],[i],None,[256],[0,256])
plt.plot(hist,color=color)
plt.xlim([0,256])
plt.show("LineChart")
(2)cv.equalizeHist():直方图均衡化,直方图均衡化作用:增强图像的对比度, 黑色背景大米的例子----自适应均衡化
实质上是对图像进行非线性拉伸,重新分配图像象元值,使一定灰度范围内象元值的数量大致相等。这样,原来直方图中间的峰顶部分对比度得到增强,而两侧的谷底部分对比度降低,输出图像的直方图是一个较平的分段直方图:如果输出数据分段值较小的话,会产生粗略分类的视觉效果。
注:直方图均衡化是针对二值化图像的
gray=cv.cvtColor(image,cv.COLOR_BGR2GRAY)
dst=cv.equalizeHist(gray)
cv.imshow("equalize",dst)
(3)cv.createCLAHE():直方图部分均衡化,即对均衡化的参数可调节----自定义均衡化
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
clahe=cv.createCLAHE(clipLimit=3.0,tileGridSize=(8,8))#clipLimit该参数控制均衡化的程度
dst=clahe.apply(gray)
cv.imshow("clahe",dst)
(4)cv.compareHist():用来计算两个直方图相似度,必须是float32类型的
计算的度量方法有4个,分别为Correlation ( CV_COMP_CORREL )相关性,Chi-Square ( CV_COMP_CHISQR ) 卡方,Intersection ( method=CV_COMP_INTERSECT )交集法,Bhattacharyya distance ( CV_COMP_BHATTACHARYYA )常态分布比对的Bhattacharyya距离法。
hist1=createRGBhist(image1)
hist2 = createRGBhist(image2)
match1=cv.compareHist(hist1,hist2,cv.HISTCMP_BHATTACHARYYA)
match2 = cv.compareHist(hist1, hist2, cv.HISTCMP_CORREL)
match3 = cv.compareHist(hist1, hist2, cv.HISTCMP_CHISQR)
print("巴氏距离:%s,相关性:%s,卡方:%s".foramt(match1,match2,match3))
#巴氏距离:越小越相似;相关性:越接近1越相似;卡方:越小越相似
10、cvCalcBackProject():反向直方图
反向投影用于在输入图像(通常较大)中查找特定图像(通常较小或者仅1个像素,以下将其称为模板图像)最匹配的点或者区域,也就是定位模板图像出现在输入图像的位置。
推文:https://blog.csdn.net/SevenColorFish/article/details/6840719
IplImage** image, 输入图像:是一个单通道图像数组,而非实际图像
CvArr* dst, 输出结果:是一个单通道32位浮点图像,它的宽度为W-w+1,高度为H-h+1,这里的W和H是输入图像的宽度和高度,w和h 是模板图像的宽度和高度
CvSize patch_size, 模板图像的大小:宽度和高度
CvHistogram* hist, 模板图像的直方图:直方图的维数和输入图像的个数相同,并且次序要一致;例如:输入图像包含色调和饱和度,那么直方图的第0维是色调,第1维是饱和度
int method, 对比方式:跟直方图对比中的方式类似,可以是:CORREL(相关)、CHISQR(卡方)、INTERSECT(相交)、BHATTACHARYYA
float factor 归一化因子,一般都设置成1
例:
sample=cv.imread("E:\OpenCVTests\QQ20190813185411.png")#读取样本与目标图像,并将其转换为HSV色彩模式
target=cv.imread("E:\OpenCVTests\IMG_4686.JPG")
spHSV=cv.cvtColor(sample,cv.COLOR_BGR2HSV)
tarHSV=cv.cvtColor(target,cv.COLOR_BGR2HSV)
cv.imshow("sample",sample)
cv.imshow("target", target)
spHist=cv.calcHist([spHSV],[0,1],None,[32,32],[0,180,0,256])#得出样本直方图,第四个参数调节细分,越小越精细
cv.normalize(spHist,spHist,0,255,cv.NORM_MINMAX)#直方图归一化,映射到0-255,方可调用下一行API
#反向投影生成
dst=cv.calcBackProject([tarHSV],[0,1],spHist,[0,180,0,256],1)#1代表不放大或者缩小
cv.imshow("backProjectDemo",dst)
11、cv.matchTemplate():模板匹配函数,使用到了cv.minMaxLoc()函数
模板匹配:在整个图像区域发现与给定子图相匹配的小块区域,需要一个模板图像T,一个待检测图像–源图像S
工作方法:在待检测图像上,从左到右,从上到下,计算模板图像与重叠子图像的匹配度,像素值匹配度越大,两者相同的肯能性
resultd的尺寸和大小:模板在待测图像上每次在横向或是纵向上移动一个像素,并作一次比较计算,由此,横向比较W-w+1次,纵向比较H-h+1次,从而得到一个(W-w+1)×(H-h+1)维的结果矩阵,result即是用图像来表示这样的矩阵,因而图像result的大小为(W-w+1)×(H-h+1)。
使用函数cvMinMaxLoc(result,&min_val,&max_val,&min_loc,&max_loc,NULL);从result中提取最大值(相似度最高)以及最大值的位置(即在result中该最大值max_val的坐标位置max_loc,即模板滑行时左上角的坐标,类似于图中的坐标(x,y)。)
例:
tpl=cv.imread("E:\OpenCVTests\QQ20190814143008.png")
target = cv.imread("E:\OpenCVTests/timg (2).jpg")
cv.imshow("tpl",tpl)
cv.imshow("target", target)
methods=[cv.TM_SQDIFF_NORMED,cv.TM_CCORR_NORMED,cv.TM_CCOEFF_NORMED]#模板匹配的匹配方式
#1、平方不同3、相关性的归一化5、相关性因子的归一化
th,tw=tpl.shape[:2]
for md in methods:
print(md)#枚举类型的值
result=cv.matchTemplate(target,tpl,md)#每个算法算出结果的值,每个像素点根据算法都有算出来的对应的值
minVal,maxVal,minLoc,maxLoc=cv.minMaxLoc(result)#计算出result的最大、最小值,即可得到哪个像素区域是最佳匹配区域,即可得出匹配得到的位置
if md==cv.TM_SQDIFF_NORMED:#如果匹配方法是‘平方不同’,则应该取最小值,这与‘平方不同’算法得出的结果相关,越相关,result结果越暗,反之。
tl=minLoc#最坐上角的点
else:
tl=maxLoc#tl为起始的地方
br=(tl[0]+tw,tl[1]+th)#bottom right====最右下角的点,在tl的基础上加上长宽即可得,tl[0]、tl[1]表示从最左上角点出发的两个方向
cv.rectangle(target,tl,br,(0,0,255),2)#绘制矩形,绘制到原图上;tl、br表示长宽,第三个参数为颜色,第四个参数为线的宽度
#cv.imshow("match"+np.str(md),target)#将md变为str类型
cv.imshow("match" + np.str(md), result)#将结果图进行显示
12、图像二值化:
注:所有的二值化操作都是基于灰度图像
(1)全局二值化方法 cv.threshold():
第一个参数,InputArray类型的src,输入数组,填单通道 , 8或32位浮点类型的Mat即可。
第二个参数,OutputArray类型的dst,函数调用后的运算结果存在这里,即这个参数用于存放输出结果,且和第一个参数中的Mat变量有一样的尺寸和类型。
第三个参数,double类型的thresh,阈值的具体值。
第四个参数,double类型的maxval,当第五个参数阈值类型type取 THRESH_BINARY 或THRESH_BINARY_INV阈值类型时的最大值.
第五个参数,int类型的type,阈值类型,。
其它参数很好理解,我们来看看第五个参数,第五参数有以下几种类型
0: THRESH_BINARY 当前点值大于阈值时,取Maxval,也就是第四个参数,下面再不说明,否则设置为0
1: THRESH_BINARY_INV 当前点值大于阈值时,设置为0,否则设置为Maxval
2: THRESH_TRUNC 当前点值大于阈值时,设置为阈值,否则不改变
3: THRESH_TOZERO 当前点值大于阈值时,不改变,否则设置为0
4: THRESH_TOZERO_INV 当前点值大于阈值时,设置为0,否则不改变
例:
ret,binary=cv.threshold(gray,0,255,cv.THRESH_BINARY|cv.THRESH_OTSU) #0为阈值,可以改变其值,但当对其做出改变时,后面自动寻找阈值应该去掉,二者只能选其一;另,255为最大值
注这是opencv2版本五个参数值,opencv3已经有8个参数值,包括OTSU
(2)局部二值化方法 cv.adaptiveThreshold( )
binary=cv.adaptiveThreshold(gray,255,cv.ADAPTIVE_THRESH_MEAN_C,cv.THRESH_BINARY,25,10)#自适应阈值方法,可以一定程度去噪声
#int adaptiveMethod---在一个邻域内计算阈值所采用的算法(两种):cv.ADAPTIVE_THRESH_MEAN_C:计算出领域的平均值再减去第七个参数double C的值
# cv.ADAPTIVE_THRESH_GAUSSIAN_C高斯方法:计算出领域的高斯均值再减去第七个参数double C的值
#int thresholdType:这是阈值类型,只有两个取值,分别为 THRESH_BINARY 和THRESH_BINARY_INV
#int blockSize:必须是奇数;adaptiveThreshold的计算单位是像素的邻域块,邻域块取多大,就由这个值作决定
#double C
cv.imshow("binary", binary)
(3)自定义阈值
def customThreshold(image):#自定义阈值
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
h,w=gray.shape[:2]
m=np.reshape(gray,[1,w*h])#变成一行多列的一维数组
mean=m.sum()/(w*h)#平均值
print("mean:",mean)
ret,binary=cv.threshold(gray,mean,255,cv.THRESH_BINARY)#mean作为阈值
cv.imshow("binary", binary)
(4)超大图像二值化:
超大图像二值化----分块进行(方法:全局阈值VS局部阈值)
def bigImageBinary(image):
print(image.shape)
cw=256#步长
ch=256
h,w=image.shape[:2]
gray=cv.cvtColor(image,cv.COLOR_BGR2GRAY)
for row in range(0,h,ch):#从0开始,到h结束,以ch为步长
for col in range(0,w,cw):
roi=gray[row:row+ch,col:col+cw]#range of interest
dst=cv.adaptiveThreshold(roi,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY,127,20)
#亦可采全局阈值方法:具体选择哪种应该根据图像的具体情况来选择-------dst阈值
# cv.threshold(roi,0,255,cv.THRESH_BINARY|cv.THRESH_OTSU)
gray[row:row+ch,col:col+cw]=dst#将二值化后的部分结果给gray
print(np.std(dst),np.mean(dst))#输出图像的均值、图像的方差,均值及方差的大小可以判断是否图像为空白进行滤值,可以减少阈值分割带来的误差
cv.imwrite("E:\OpenCVTests/bigImage.jpg",gray)
12、图像金字塔
(1)cv.pyrDown()先对图像进行高斯平滑,然后再进行降采样(将图像尺寸行和列方向缩减一半)
高斯字塔:首先将原图像作为最底层图像G0(高斯金字塔的第0层),利用高斯核(5*5)对其进行卷积,然后对卷积后的图(去除偶数行和列)得到上一层图像G1,将此图像作为输入,重复卷积和下采样操作得到更上一层图像,反复迭代多次,形成一个金字塔形的图像数据结构
def pyramidDemo(image):#高斯金字塔
level=3
temp=image.copy()#复制一张
pyramidImeages=[]
for i in range(level):
dst=cv.pyrDown(temp)#降 API,原理在上方
pyramidImeages.append(dst)#加入列表
cv.imshow("pyramidDown"+str(i),dst)
temp=dst.copy()#为temp赋新值
return pyramidImeages
(2)cv.pyrUp()先对图像进行升采样(将图像尺寸行和列方向增大一倍),然后再进行高斯平滑
这个函数运行的过程就是先将图像的尺寸行和列方向都放大一倍,然后进行高斯平滑,不过此时高斯平滑的kernel是上面pyrDown()中的kernel乘上4,而不是完全相同。( 其实也很容易理解,行和列方向各放大一倍的结果就是图像的面积放大四倍,所以这里给之前的kernel乘以4)。
拉普拉斯金字塔:在高斯金字塔的运算过程中,图像经过卷积和下采样操作会丢失部分高频细节信息。为描述这些高频信息,人们定义了拉普拉斯金字塔(Laplacian Pyramid, LP)。用高斯金字塔的每一层图像减去其上一层图像上采样并高斯卷积之后的预测图像,得到一系列的差值图像即为 LP 分解图像。
def lapalianDemo(image):#拉普拉斯金字塔
pyramidImeages=pyramidDemo(image)#调用上方的函数
level=len(pyramidImeages)
for i in range(level-1,-1,-1):#start stop step
if(i-1)<0:
expand=cv.pyrUp(pyramidImeages[i],dstsize=image.shape[:2])
lpls=cv.subtract(image,expand)
cv.imshow("lapalianDown"+str(i),lpls)
else:
expand = cv.pyrUp(pyramidImeages[i], pyramidImeages[i-1].shape[:2])#内插放大后图像
lpls = cv.subtract(pyramidImeages[i-1], expand)#它的每一层L0图像是高斯金字塔本层G0图像与其高一层图像G1经内插放大后图像*G1的差
cv.imshow("lapalianDown" + str(i), lpls)
13、边缘检测
(1)cv.Sobel()
cv.Sobel(src,ddepth,dx,dy,dst=None,ksize=None,scale=None,delta=None,borderType=None)
ddepth:图像的颜色深度,针对不同的输入图像,输出目标图像有不同的深度,具体组合如下:
- 若src.depth() = CV_8U, 取ddepth =-1/CV_16S/CV_32F/CV_64F
- 若src.depth() = CV_16U/CV_16S, 取ddepth =-1/CV_32F/CV_64F
- 若src.depth() = CV_32F, 取ddepth =-1/CV_32F/CV_64F
- 若src.depth() = CV_64F, 取ddepth = -1/CV_64F
dx:int类型的,表示x方向的差分阶数,1或0
dy:int类型的,表示y方向的差分阶数,1或0
kSize:模板大小,前面虽然提到过,不过对于Sobel算子这里要补充下,这里的取值为1,3,5,7,当不输入的时候,默认为3。
例:
def sobelDemo(image):
gradX=cv.Sobel(image,cv.CV_32F,1,0)#对X方向上求梯度,第三个参数为处理图像的深度-----Scharr算子为Sobel算子的增强版,
# 将边缘更清晰的显示,可以提取图像微弱的边缘处
gradY = cv.Sobel(image, cv.CV_32F, 0, 1)#对Y方向上求梯度
grad_X=cv.convertScaleAbs(gradX)#求绝对值,转化到8位的图像上去
grad_Y = cv.convertScaleAbs(gradY)
cv.imshow("sobel_X",grad_X)
cv.imshow("sobel_Y", grad_Y)
gradxy=cv.addWeighted(grad_X,0.5,grad_Y,0.5,0)#整个图像的梯度
cv.imshow("sobel", gradxy)
(2)cv.Scharr ()
参数和Sobel算子一致,不过,该函数与Sobel的区别在于,Scharr仅作用于大小为3的内核。具有和sobel算子一样的速度,但结果更为精确
(3)cv.Laplacian()拉普拉斯
cv. Laplacian(src,ddepth,dst=None,ksize=None,scale=None,delta=None,borderType=None)
kSize:模板大小
scale:Double类型的,计算拉普拉斯可选比例因子,有默认值1
delta:加到输出像素的值,默认为0
borderType:边界模式。默认值BORDER_DEFAULT
例:
def lapalianDemo(image):#拉普拉斯梯度
dst=cv.Laplacian(image,cv.CV_32F)
lpls=cv.convertScaleAbs(dst)#求绝对值,转化到8位的图像上去
cv.imshow("lapalianDemo",lpls)
(4)cv.Canny ()
cv. Canny(image,threshold1,threshold2,edges=None,apertureSize=None,L2gradient=None)
threshold1:int类型的,低阈值
threshold2:int类型的,高阈值 —高阈值最好是低阈值的2/3倍
edeges:单通道存储边缘的输出图像
apertureSize:Sobel算子内核(kSize)大小
L2gradiend:Bool类型的,为真表示使用更精确的L2范数进行计算(两个方向的倒数的平方再开放),为假表示用L1范数(直接将两个方向导数的绝对值相加)
例:
def edgeDemo(image):
blurred=cv.GaussianBlur(image,(3,3),0)#降低噪声,因为Canny对噪声敏感
gray=cv.cvtColor(blurred,cv.COLOR_BGR2GRAY)
#梯度值计算
xgrad=cv.Sobel(gray,cv.CV_16SC1,1,0)
ygrad = cv.Sobel(gray, cv.CV_16SC1, 0, 1)#第三个参数为处理图像的深度,此处应该用整数型
#edgeOutPut=cv.Canny(gray,50,150)-----亦可使用本方法
edgeOutPut=cv.Canny(xgrad,ygrad,50,150)#第三四个参数为低、高阈值----高阈值最好是低阈值的2倍或者3倍
cv.imshow("CannyEdge",edgeOutPut)
dst=cv.bitwise_and(image,image,mask=edgeOutPut)#边缘彩色化
cv.imshow("Color Edge",dst)
14、霍夫检测
(1)霍夫直线检测cv.HoughLines()
cv.HoughLinesP()
(2)霍夫圆检测cv.HoughCircles()
cv.HoughCircles(image, method, dp, minDist, circles, param1, param2, minRadius, maxRadius)
第二个参数默认,因为检测圆的方法,OpenCV2.*.*版本之中只有霍夫梯度法
第三个参数可以设置为1就行–默认参数,步长
第四个参数:非常重要!!是圆心与圆心之间的距离,这是一个经验值。这个大了,那么多个圆就是被认为一个圆
第五个参数 就设为默认值就OK
第六个参数是根据你的图像中的圆大小设置,当这张图片中的圆越小,那么此值就设置应该被设置越小。当设置的越小,那么检测出的圆越多,在检测较大的圆时则会产生很多噪声。所以要根据检测圆的大小变化。
第七个和第八个参数 是你检测圆 最小半径和最大半径是多少。这个值也是为了进一步筛选检测出的圆
15、cv.findContours()轮廓查找
findContours( InputOutputArray image, OutputArrayOfArrays contours, int mode, int method, Point offset=Point());
搬运自:findContours()函数详解
contours:检测到的轮廓。是一个向量,向量的每个元素都是一个轮廓。因此,这个向量的每个元素仍是一个向量
hierarchy:各个轮廓的继承关系。hierarchy也是一个向量,长度和contours相等,每个元素和contours的元素对应。hierarchy的每个元素是一个包含四个整型数的向量
mod:检测轮廓的方法。有四种方法。
—CV_RETR_EXTERNAL:只检测外轮廓。忽略轮廓内部的洞。
—CV_RETR_LIST:检测所有轮廓,但不建立继承(包含)关系。
—CV_RETR_TREE:检测所有轮廓,并且建立所有的继承(包含)关系。也就是说用CV_RETR_EXTERNAL和CV_RETR_LIST方法的时候hierarchy这个变量是没用的,因为前者没有包含关系,找到的都是外轮廓,后者仅仅是找到所哟的轮廓但并不把包含关系区分。用TREE这种检测方法的时候我们的hierarchy这个参数才是有意义的。事实上,应用前两种方法的时候,我们就用findContours这个函数的第二种声明了。
—CV_RETR_CCOMP:检测所有轮廓,但是仅仅建立两层包含关系。外轮廓放到顶层,外轮廓包含的第一层内轮廓放到底层,如果内轮廓还包含轮廓,那就把这些内轮廓放到顶层去。
method:表示一条轮廓的方法。
– CV_CHAIN_APPROX_NONE:把轮廓上所有的点存储。
– CV_CHAIN_APPROX_SIMPLE:只存储水平,垂直,对角直线的起始点。对drawContours函数来说,这两种方法没有区别。
– CV_CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS:实现的“Teh-Chin chain approximation algorithm.”这个不太懂。他们的论文:Teh, C.H. and Chin, R.T., On the Detection of Dominant Points on Digital Curve. PAMI 11 8, pp 859-872 (1989)
offset:Optional offset by which every contour point is shifted. This is useful if the contours are extracted from the image ROI and then they should be analyzed in the whole image context。
相关函数:
area = cv.contourArea(contou)#轮廓矩形面积
x, y, w, h = cv.boundingRect(contou)#外接矩形的起始点以及长度、宽度
mm = cv.moments(contou)#求取几何距,字典类型的----通过键码取键值
cv.circle(image, (np.int(cx), np.int(cy)), 4, (0, 0,255 ), -1)#circle
cv.drawContours(dst,contous,i,(0,0,255),2)
传送至轮廓绘制及轮廓逼近完整代码
16、图像形态学
(1)cv.erode()—腐蚀
例:
gray=cv.cvtColor(image,cv.COLOR_BGR2GRAY)
ret,binary=cv.threshold(gray,0,255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU)
cv.imshow("binaryImage",binary)
kernel=cv.getStructuringElement(cv.MORPH_RECT,(2,2))#获得结构元素,第一个参数为结构元素的形状:矩形、交错形状、椭圆形
#第二个参:结构元素尺寸,即腐蚀的强度
dst=cv.erode(binary,kernel)#腐蚀
cv.imshow("erodeDemo",dst)
(2)cv.dilate()—膨胀
代码除函数名外其他都与erode()函数相同
17、高级形态学
开运算: MORPH_OPEN
先腐蚀,再膨胀,可清除一些小东西(亮的),放大局部低亮度的区域
闭运算: MORPH_CLOSE
先膨胀,再腐蚀,可清除小黑点
形态学梯度: MORPH_GRADIENT
膨胀图与腐蚀图之差,提取物体边缘
顶帽: MORPH_TOPHAT
原图像-开运算图,突出原图像中比周围亮的区域
黑帽: MORPH_BLACKHAT
闭运算图-原图像,突出原图像中比周围暗的区域
开闭操作亦可提取水平线或者垂直线,通过改变结构元素的尺寸:水平线---->如:(1,15);垂直线---->如:(15,1)
例:
#open=cv.morphologyEx(binary,cv.MORPH_OPEN,kernel)#中间参数--选择各种形态学操作
#cv.imshow("openResult",open)
18、人脸检测:
例:
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY) # 基于灰度图像的
faceDector = cv.CascadeClassifier( "E:\opencv-4.0.1-vc14_vc15\opencv-4.1.0-vc14_vc15\opencv/build\etc\haarcascades\haarcascade_frontalface_alt_tree.xml")
# 基于HAAR的,也可以基于LBP的,通过级联检测器来调用HAAR的人脸检测---下载OpenCV时自带了这些资源,无资源去https://github.com/opencv/opencv/tree/master/data
faces = faceDector.detectMultiScale(gray, 1.02, 5) # 检测出来的候选矩形框
'''
参数1:image--待检测图片,一般为灰度图像加快检测速度;
参数2:objects--被检测物体的矩形框向量组;
参数3:scaleFactor--表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
参数4:minNeighbors--表示构成检测目标的相邻矩形的最小个数(默认为3个)。
如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
这种设定值一般用在用户自定义对检测结果的组合程序上;
参数5:flags--要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置
CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,
因此这些区域通常不会是人脸所在区域;
参数6、7:minSize和maxSize用来限制得到的目标区域的范围。
'''
for x, y, w, h in faces:
cv.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255))
cv.imshow("faceDetect", image)