Python爬虫实战 | (14) 爬取人民网滚动新闻
在本篇博客中,我们将使用selenium爬取人民网新闻中滚动页面的所有新闻内容,包括题目、时间、来源、正文,并存入MongoDB数据库。网址:http://news.people.com.cn/
打开后,发现这里都是一些滚动新闻,每隔一段时间就会刷新:

我们右键查看网页源代码,发现并没有当前页面的信息:
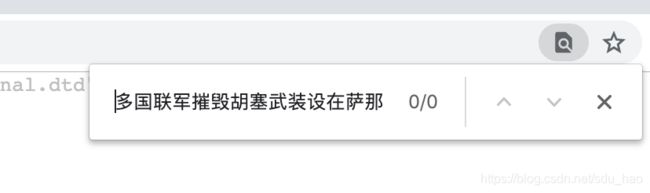
在源码页面搜索当前第一条新闻,并没有找到。
右键检查:
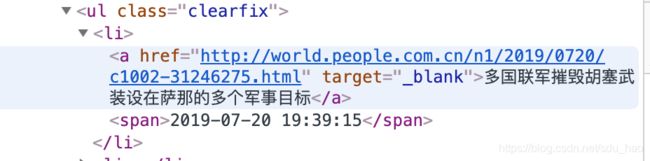
发现有当前页面的信息。说明当前页面是动态页面,即通过javascript渲染后得到的。因此,通过requests请求,是无法得到页面信息的,它得到的是网页最原始的代码,和右键查看网页源代码得到的是一致的。所以,我们需要使用selenium,模拟浏览器运行,来处理动态页面,从而爬取新闻信息。
程序主体框架如下:
import re
import pymongo
import time
import requests
from requests import RequestException
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from bs4 import BeautifulSoup
def get_response(url):
#发送请求、获取响应
pass
def get_news(url):
#获取新闻详细信息
pass
def get_page_news():
# 获取当前页面新闻url
pass
if __name__ == '__main__':
#连接mongodb
client = pymongo.MongoClient('mongodb://localhost:27017')
#选择数据库
db = client.News
#选择集合
news_col = db.peopleRollNews
#打开浏览器
browser = webdriver.Chrome()
browser.implicitly_wait(10)
#打开网址
browser.get('http://news.people.com.cn/')
#获取当前页面新闻url
get_page_news()
while True:
try:
#找到下一页按钮 并点击
'''
下一页
'''
browser.find_element_by_css_selector('.next').click()
get_page_news()
except NoSuchElementException:
print('NoSuchElementException')
browser.close()
break
右键检查当前页面,查看新闻的url:
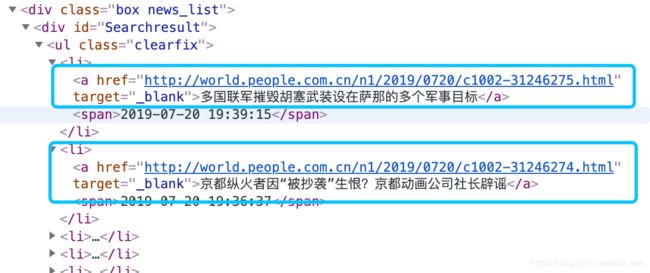
def get_page_news():
# 获取所有包含新闻url的a标签
news = browser.find_elements_by_xpath('//div[@id="Searchresult"]/ul/li/a')
for i in news:
link = i.get_attribute('href')
if not news_col.find_one({'link':link}): #去重
print(link,i.text)
#获取新闻详细信息
news = get_news(link)
news_col.insert_one(news)
time.sleep(5)获取页面的详细信息:
我们发现首页是动态页面,点击一条新闻进去之后的页面并不是动态页面,所以可以使用requests进行爬取。首先爬取每条新闻的页面信息。
def get_response(url):
try:
#添加User-Agent,放在headers中,伪装成浏览器
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
return None
except RequestException:
return None
解析页面信息,获取每条新闻的详细信息:
新闻正文分布在下图div标签的每个p标签中:
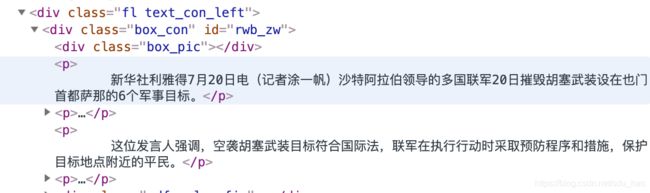
def get_news(url):
#获取新闻详细信息
html = get_response(url)
soup = BeautifulSoup(html,'lxml')
#标题
'''
多国联军摧毁胡塞武装设在萨那的多个军事目标
'''
pattern = re.compile('(.*?)
',re.S)
title = pattern.findall(html)[0]
print(title)
#日期
'''
2019年07月20日19:39 来源:新华社
'''
pattern = re.compile('\d+年\d+月\d+日\d+:\d+', re.S)
date = pattern.findall(html)[0]
print(date)
#来源
pattern = re.compile('来源:(.*?)',re.S)
source = pattern.findall(html)[0]
print(source)
#正文
article = soup.select('div[class="box_con"] p')
# 可能有小部分正文的标签不是上述格式 对其进行补充
if not article:
article = soup.select('div[class="content clear clearfix"] p')
if article:
article_list = []
for i in article:
print(i.text)
article_list.append(i.text)
news = {'link': url, 'title': title, 'date': date, 'source': source, 'article': article_list}
return news 爬取效果:
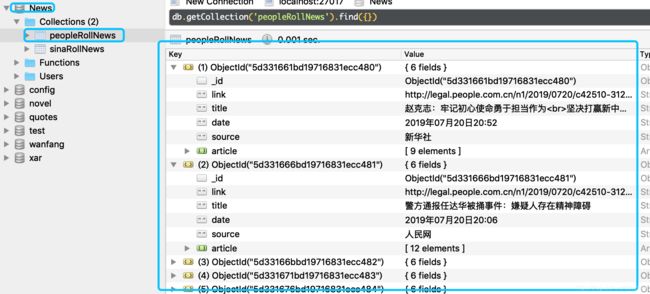
完整代码:
import re
import pymongo
import time
import requests
from requests import RequestException
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from bs4 import BeautifulSoup
def get_response(url):
try:
# 添加User-Agent,放在headers中,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except RequestException:
return None
def get_news(url):
#获取新闻详细信息
html = get_response(url)
soup = BeautifulSoup(html,'lxml')
#标题
'''
多国联军摧毁胡塞武装设在萨那的多个军事目标
'''
pattern = re.compile('(.*?)
',re.S)
title = pattern.findall(html)[0]
print(title)
#日期
'''
2019年07月20日19:39 来源:新华社
'''
pattern = re.compile('\d+年\d+月\d+日\d+:\d+', re.S)
date = pattern.findall(html)[0]
print(date)
#来源
pattern = re.compile('来源:(.*?)',re.S)
source = pattern.findall(html)[0]
print(source)
#正文
article = soup.select('div[class="box_con"] p')
# 可能有小部分正文的标签不是上述格式 对其进行补充
if not article:
article = soup.select('div[class="content clear clearfix"] p')
if article:
article_list = []
for i in article:
print(i.text)
article_list.append(i.text)
news = {'link': url, 'title': title, 'date': date, 'source': source, 'article': article_list}
return news
def get_page_news():
# 获取所有包含新闻url的a标签
news = browser.find_elements_by_xpath('//div[@id="Searchresult"]/ul/li/a')
for i in news:
link = i.get_attribute('href')
if not news_col.find_one({'link':link}): #去重
print(link,i.text)
#获取新闻详细信息
news = get_news(link)
news_col.insert_one(news)
time.sleep(5)
if __name__ == '__main__':
#连接mongodb
client = pymongo.MongoClient('mongodb://localhost:27017')
#选择数据库
db = client.News
#选择集合
news_col = db.peopleRollNews
#打开浏览器
browser = webdriver.Chrome()
browser.implicitly_wait(10)
#打开网址
browser.get('http://news.people.com.cn/')
#获取当前页面新闻url
get_page_news()
while True:
try:
#找到下一页按钮 并点击
'''
下一页
'''
browser.find_element_by_css_selector('.next').click()
get_page_news()
except NoSuchElementException:
print('NoSuchElementException')
browser.close()
break