springboot整合quartz实现任务持久化(下)
一、springboot整合quartz实现任务持久化(下)
1.1 说明
已经两年没有写博客了,今天记录一篇前不久写的一篇研究笔记。
其实在上一章我们已经了解到如何将springboot与quartz整合了,但是前面的这种方式只是我们根据以往springboot的使用经验将两者结合到了一起。而现在我们将要了解的是springboot官方进行的与quartz的整合。
springboot官方整合quartz之后,提供了这么一个启动器:spring-boot-starter-quartz
1.2 官网地址
那么如何来使用springboot官方提供的spring-boot-starter-quartz呢,我们可以来参考官方文档:
sprint-boot-starter-quartz docs
1.3 官网解读
1.3.1 自动配置scheduler
我们打开上一小节记录的官网地址,可以看到这样的一段描述:
Spring Boot offers several conveniences for working with the Quartz scheduler, including the spring-boot-starter-quartz “Starter”. If Quartz is available, a Scheduler is auto-configured (through the SchedulerFactoryBean abstraction).
Beans of the following types are automatically picked up and associated with the Scheduler:
JobDetail: defines a particular Job. JobDetail instances can be built with the JobBuilder API.
Calendar.
Trigger: defines when a particular job is triggered.
其原文大意如下:
SpringBoot提供了一些便利的方法来跟quartz协调工作,这里边就包括spring-boot-starter-quartz这个启动器。如果quartz可用,那么一个scheduler调度器实例会通过SchedulerFactoryBean这个工厂bean自动配置到容器中。此外,JobDetail、Calendar、Trigger这些类型的bean一旦配置到容器中,这些bean就将会被自动采集并关联到scheduler上。
简单来说就是如果使用spring-boot-starter-quartz,我们就不需要手动配置一个scheduler到容器中了,它会给我们自动注入一个。
1.3.2 Job持久化
接着解读:
By default, an in-memory JobStore is used. However, it is possible to configure a JDBC-based store if a DataSource bean is available in your application and if the spring.quartz.job-store-type property is configured accordingly, as shown in the following example:
spring.quartz.job-store-type=jdbc
默认情况下,JobStore这个持久化配置采用的是基于内存的方式。但是,如果你的springboot应用中存在一个DataSource数据源bean,那么配置一个基于 JDBC 持久化的方式也是允许的。如果希望采用基于 JDBC 的持久化方式,则通过 spring.quartz.job-store-type 这个属性来进行配置,例如将它的持久化类型配置为 jdbc。
When the JDBC store is used, the schema can be initialized on startup, as shown in the following example:
spring.quartz.jdbc.initialize-schema=always
如果采用了JDBC的持久化方式,那么通过这样的配置可以在应用启动的时候初始化数据库的schema(schema在数据库中表示的是数据库对象集合):
spring.quartz.jdbc.initialize-schema=always
这句话的含义指的是,如果你不知道需要建哪些表,那么就配置好上述属性,使其在应用启动的时候将数据库中quartz持久化需要用到的表都创建好。
By default, the database is detected and initialized by using the standard scripts provided with the Quartz library. These scripts drop existing tables, deleting all triggers on every restart. It is also possible to provide a custom script by setting the spring.quartz.jdbc.schema property.
需要注意的是,如果你进行了上述配置,那么默认情况下,一旦检测到database,就会使用quartz库中提供的标准脚本来初始化数据库。每次重启应用的时候,这些脚本都会移除掉已经存在的表,并且将数据库中之前记录的全部触发器都会删除掉。如果你不希望使用quartz提供的这些脚本,也可以通过 spring.quartz.jdbc.schema 这个属性来指定你自定义的脚本路径。
1.3.3 quartz专用数据源配置
继续解读:
To have Quartz use a DataSource other than the application’s main DataSource, declare a DataSource bean, annotating its @Bean method with @QuartzDataSource. Doing so ensures that the Quartz-specific DataSource is used by both the SchedulerFactoryBean and for schema initialization.
如果要将quartz使用的数据源跟应用的主数据源区分开来,就需要在系统中通过 @Bean 和 @QuartzDataSource 两个注解配置一个 DataSource 的 bean。这样做能确保这个数据源能作为 quartz 专用的数据源,来用于SchedulerFactoryBean 工厂bean,以及初始化数据库的表结构。
1.3.4 job覆盖配置
继续解读:
By default, jobs created by configuration will not overwrite already registered jobs that have been read from a persistent job store. To enable overwriting existing job definitions set the spring.quartz.overwrite-existing-jobs property.
默认情况下,通过配置的方式创建出来的 job,它们并不会覆盖系统中已经从持久化仓库中读取到并且注册好的 job。如果希望 scheduler 启动就更新覆盖已存在的 Job,就需要设置 spring.quartz.overwrite-existing-jobs 这个属性。
1.3.5 自定义quartz配置
虽然 spring-boot-starter-quartz 给我们提供了几个非常方便的配置,但如果我们希望进行更多的诸如quartz.properties中的配置该怎么办呢?例如我们希望配置一个quartz集群该咋办呢?怎么把之前quartz.properties中的配置转移过来呢?
显然springboot官方也是考虑到了这一点的,我们接着解读:
Quartz Scheduler configuration can be customized using spring.quartz properties and SchedulerFactoryBeanCustomizer beans, which allow programmatic SchedulerFactoryBean customization. Advanced Quartz configuration properties can be customized using spring.quartz.properties.*.
我们可以通过 spring.quartz 这个属性来自定义 quartz 调度器的众多配置。除此之外,也支持通过编程的方式,自定义一个 SchedulerFactoryBean 来注入到容器中,通过这种方式来自定义quartz的配置。
那么更多的 quartz 属性配置则可以通过 spring.quartz.properties.* 这个属性来进行自定义配置。
这里,我们先记住这个属性!
继续解读:
In particular, an Executor bean is not associated with the scheduler as Quartz offers a way to configure the scheduler via spring.quartz.properties. If you need to customize the task executor, consider implementing SchedulerFactoryBeanCustomizer.
需要特别注意的是,虽然 quartz 给我们提供了 spring.quartz.properties 这种方式来配置调度器,但这种方式配置的调度器并没有跟 Executor 实例关联起来。如果你需要自定义一个任务执行器,就需要自己创建一个 SchedulerFactoryBeanCustomizer 的实现类。
这就是为什么我们在上一章介绍SpringBoot跟quartz的另一种整合方式中,要创建一个类继承 org.springframework.scheduling.quartz.SpringBeanJobFactory ,并实现 SpringBeanJobFactory;然后将这个工厂bean注入到容器中,再创建一个SchedulerFactoryBean调度器工厂实例,将这个自定义Job工厂实例交给调度器工厂实例维护了。
接下来我们回到 spring.quartz.properties.* 这个属性,在idea中安装Ctrl,然后鼠标左键点击这个属性,即进入到 QuartzProperties 类中,我们可以看到:

可以看到这就是一个Map,以之前我们在 quartz.properties 中配置的属性名作为 key,以其值作为 value 存进这个Map中来,然后转手就将这个Map里边保存的配置交给了quartz,因此原来的属性是怎么配置的,现在就可以像这样进行配置:
spring:
quartz:
# 用于客户化定义quartz的属性
properties:
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.clusterCheckinInterval: 20000
org.quartz.threadPool.threadCount: 10
1.3.6 Job的属性注入
那么假如我们希望做一个定时任务平台,将其作为一个独立的定时任务调度平台,然后写一个统一的sdk调用接口作为客户端,去调用其他系统的交易怎么办呢,显然我们需要能将sdk客户端组件以及mapper这些东西能够注入到我们的Job中来,才能够实现数据的查询和记录啊。
不要急,springboot同样考虑到了这一点,我们接着看:
Jobs can define setters to inject data map properties. Regular beans can also be injected in a similar manner, as shown in the following example:
自定义好Job之后,Job可以定义set方法来注入datamap的配置信息,也能用同样的方法注入普通的bean,还给我们举了一个例子:
public class SampleJob extends QuartzJobBean {
private MyService myService;
private String name;
// Inject "MyService" bean
public void setMyService(MyService myService) { ... }
// Inject the "name" job data property
public void setName(String name) { ... }
@Override
protected void executeInternal(JobExecutionContext context)
throws JobExecutionException {
...
}
}
通过案例介绍,我们完全可以将定时任务要做的业务数据另外创建一张表,然后再创建 Job 的时候将业务数据的 id 传进来,然后将Service、Mapper以及其他的组件之间通过 @Autowired 的方式注入进来就可以了。
1.4 案例
1.4.1 案例说明
通过前面的介绍,我们对spring-boot-starter-quartz已经有了非常详细的了解,对此,我们产生了这样的一个设想。在以往的学习和工作中,定时任务很多是通过在程序中进行代码配置的方式进行的,这样的方式显然并不能对系统乃至整个平台中的定时任务进行很好的管理。而我们希望开发一个定时任务调度平台,它作为一个调度平台独立运行,然后提供诸如添加、修改、删除、查询、启停等功能,并且能够对每个定时任务配置调度规则和业务参数,使该定时任务能够按照给定的调度计划定时的请求目标系统的定时交易,从而实现将定时调度作为平台的一种基础能力。
那么对于这样的一个目标,我们显然不可能在案例中直接进行设计,我们只需要在案例中可以看到能够对每个定时任务的业务参数配置在数据库中,并且将这个定时任务跟它的业务参数能很好的关联起来,能让定时任务在被调度执行的时候该任务能进行诸如 业务数据的查询、远程系统的RMI调用、记录业务数据 等功能即可。
1.4.2 业务表
现在我们根据前面的说明创建这样的一个数据库,并为定时任务添加业务数据表:
create database cmc default charset = utf8;
use cmc;
drop table if exists cron_job;
create table cron_job(
id INT not null auto_increment,
cron varchar(255) charset utf8 collate utf8_general_ci not null,
job_name varchar(255) not null unique,
job_group varchar(255) not null,
status varchar(10) not null,
primary key (id)
) default charset = utf8;
我们的目的就是在添加定时任务时,能将业务数据记录到这个表中,然后能将任务的业务数据 id 传入到任务Job中,支持其 Job 根据传入的 id 查询到业务数据就能窥探到我们目标实现的途径了。
1.4.3 依赖包
接下来我们导入主要依赖的jar包:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-quartzartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.4version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
由于我们将通过postman来进行测试,因此还需加入:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
1.4.4 application.yaml
接下来我们需要在配置文件中配置quartz使用 jdbc 的方式进行 Job 的持久化,并为其配置上数据源以及集群配置信息:
spring:
datasource:
url: jdbc:mysql://localhost:3306/cmc?characterEncoding=utf8
username: root
password: 123456
quartz:
# 指定job存储的类型,可选值:memory,jdbc
job-store-type: jdbc
jdbc:
# 是否初始化数据库 never,always,embedded
initialize-schema: never
# 调度器名称
scheduler-name: quartzScheduler2
# 设置应用启动后,延时多长时间启动调度器
startup-delay: 5s
# 是否自动启动quartz
auto-startup: true
# 是否等待所有job完成调度后才关闭scheduler
wait-for-jobs-to-complete-on-shutdown: true
# 是否覆盖已存在的任务,用于quartz集群,设置为true 则 quartzScheduler启动会更新已存在的Job
overwrite-existing-jobs: false
# 用于客户化定义quartz的属性
properties:
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.clusterCheckinInterval: 20000
org.quartz.threadPool.threadCount: 10
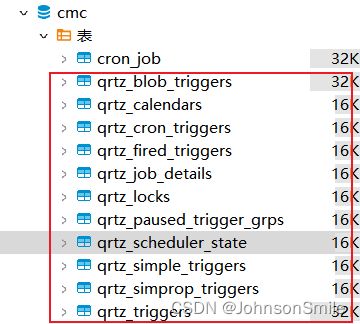
这里我们先将初始化数据库设为always,启动应用之后,其果然在数据库中创建好了quartz需要的十一张数据表:
1.4.5 model类
然后是业务数据表对应的model:
@Builder
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
@Data
public class CronJob implements Serializable {
private Integer id;
private String cron;
private String jobName;
private String jobGroup;
private String status;
}
1.4.6 mapper接口
接下来是操作数据的dao接口类:
@Repository
@Mapper
public interface CronJobMapper {
@Select("select id,cron,job_name,job_group,status from cron_job where id = #{id}")
@Results(id = "baseResult",value = {
@Result(id = true, column = "id", property = "id"),
@Result(column = "cron", property = "cron"),
@Result(column = "job_name", property = "jobName"),
@Result(column = "job_group", property = "jobGroup"),
@Result(column = "status", property = "status")
})
CronJob selectById(@Param("id") Integer id);
@Insert("insert into cron_job(id, cron, job_name, job_group, status) values " +
"(#{record.id},#{record.cron},#{record.jobName},#{record.jobGroup},#{record.status})")
int insert(@Param("record") CronJob record);
@Delete("delete from cron_job where id = #{id}")
int delete(@Param("id") Integer id);
}
1.4.7 service及其实现类
接下来我们需要定义一个接口提供诸如任务的查询、增加、删除、暂停和重启的功能:
public interface CronJobService {
CronJob selectById(Integer id);
int insert(CronJob record);
void pause(Integer id);
void resume(Integer id);
void delete(Integer id);
}
实现类:
@CommonsLog
@Service
public class CronJobServiceImpl implements CronJobService {
@Autowired
private CronJobMapper cronJobMapper;
@Autowired
private Scheduler scheduler;
@Override
public CronJob selectById(Integer id) {
return cronJobMapper.selectById(id);
}
@Transactional
@Override
public int insert(CronJob record) {
int result = cronJobMapper.insert(record);
if(result < 1){
throw new RuntimeException("新增定时任务失败");
}
JobDetail jobDetail = JobBuilder.newJob(TaskJob.class)
.withIdentity(record.getJobName(), record.getJobGroup())
.storeDurably()
.usingJobData("jobId", record.getId())
.build();
CronTrigger trigger = TriggerBuilder.newTrigger()
.forJob(jobDetail)
.withIdentity(record.getJobName(), record.getJobGroup())
.withSchedule(CronScheduleBuilder.cronSchedule(record.getCron()))
.build();
try {
scheduler.scheduleJob(jobDetail, trigger);
}catch (SchedulerException e){
throw new RuntimeException("新增定时任务失败", e);
}
return result;
}
@Transactional
@Override
public void pause(Integer id) {
CronJob cronJob = cronJobMapper.selectById(id);
if (cronJob == null){
throw new RuntimeException("该定时任务不存在");
}
JobKey jobKey = JobKey.jobKey(cronJob.getJobName(), cronJob.getJobGroup());
try {
boolean exists = scheduler.checkExists(jobKey);
if(!exists){
throw new RuntimeException("该定时任务不存在");
}
scheduler.pauseJob(jobKey);
}catch (Exception e){
throw new RuntimeException("暂停定时任务失败", e);
}
}
@Override
public void resume(Integer id) {
CronJob cronJob = cronJobMapper.selectById(id);
if (cronJob == null){
throw new RuntimeException("该定时任务不存在");
}
JobKey jobKey = JobKey.jobKey(cronJob.getJobName(), cronJob.getJobGroup());
try {
boolean exists = scheduler.checkExists(jobKey);
if(!exists){
throw new RuntimeException("该定时任务不存在");
}
scheduler.resumeJob(jobKey);
}catch (Exception e){
throw new RuntimeException("恢复定时任务失败", e);
}
}
@Transactional
@Override
public void delete(Integer id) {
CronJob cronJob = cronJobMapper.selectById(id);
if (cronJob == null){
throw new RuntimeException("该定时任务不存在");
}
JobKey jobKey = JobKey.jobKey(cronJob.getJobName(), cronJob.getJobGroup());
try {
int result = cronJobMapper.delete(id);
boolean exists = scheduler.checkExists(jobKey);
if(!exists || result < 1){
throw new RuntimeException("该定时任务不存在");
}
scheduler.deleteJob(jobKey);
}catch (Exception e){
throw new RuntimeException("删除定时任务失败", e);
}
}
}
1.4.8 定时任务Job类
关键来了:
@CommonsLog
@Data
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
@Component
@PersistJobDataAfterExecution
public class TaskJob extends QuartzJobBean {
private Integer jobId;
@Autowired
private CronJobMapper cronJobMapper;
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
log.info("-----------------------------------------------------");
log.info("执行中");
CronJob cronJob = cronJobMapper.selectById(jobId);
log.info(cronJob);
}
}
1.4.9 业务控制器
创建业务控制器如下所示:
@RestController
public class CronJobController {
@Autowired
private CronJobService cronJobService;
@GetMapping("/add")
public String add(@RequestBody CronJob cronJob){
try {
cronJobService.insert(cronJob);
} catch (Exception e){
e.printStackTrace();
return "fail";
}
return "ok";
}
@GetMapping("/pause")
public String pause(int id){
try{
cronJobService.pause(id);
} catch (Exception e){
e.printStackTrace();
return "fail";
}
return "ok";
}
@GetMapping("/resume")
public String resume(int id){
try{
cronJobService.resume(id);
} catch (Exception e){
e.printStackTrace();
return "fail";
}
return "ok";
}
@GetMapping("/delete")
public String delete(int id){
try{
cronJobService.delete(id);
} catch (Exception e){
e.printStackTrace();
return "fail";
}
return "ok";
}
}
1.5 测试功能
启动应用之后,首先就能看到这样的日志:

可见基于JDBC的持久化配置已生效,然后延迟启动和集群配置也生效了:

然后添加一个任务信息,然后重启,从日志中我们就能看到在启动后,自动加载了任务,并且开始了调度:
