【Linux】进程的理解
一.冯诺依曼体系结构
1.概念:冯诺依曼体系结构规定了硬件上的数据流动,大部分的计算机都遵守该体系结构。

输入设备:键盘,鼠标等
中央处理器cpu:运算器和控制器
存储器:物理内存
输出设备:显示器,打印机等
工作原理:执行程序时输入设备将数据加载到存储器中,存储器将数据传给中央处理器进行处理,中央处理器处理数据,再将数据写回到存储器中,最后存储器将数据刷新到输出设备上。
通过工作原理得出结论:cpu不直接和外设打交道,外设要输入或者输出数据只能从内存中读取或者写入,所有的设备都只和内存打交道。
以我们上网和自己的好友聊天为例子理解冯诺依曼体系结构:
我们的电脑:通过键盘将数据写入内存,cpu将内存中的数据进行处理,然后将数据再写入内存,最后内存将数据刷新到网卡。
好友的电脑:将网卡上的数据写道内存,内存将数据交给cpu处理,cpu再将数据写到内存,最后内存将数据刷新到显示器上。
二.操作系统
1.操作系用的实质:是对计算机进行软硬件资源做管理的软件
2.组成:内核(文件管理,进程管理,驱动管理,内存管理)和其他程序(函数库,shell等)
操作系统既然是做管理的软件,那如何理解管理:
-
操作系统作为管理者,主要做事情决策
-
而操作系统之下的驱动作为执行者,进行执行操作系统的决定
-
最后的底层硬件则是一个被管理的角色

怎么进行管理:
1.描述:先对被管理者进行描述,将其属性数据获取(数据写到struct结构体中)
2.组织:用链表或其他高效的数据结构进行管理数据(结构体),也就是对数据的操作达到管理的效果
系统调用和库函数概念:
1.在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用
2.系统调用在使用上功能比较基础,但对用户的要求相对也比较高,所以开发者对部分系统调用进行适度封装,从而形成库,利于更上层用户或者开发者进行二次开发
三.进程概念
什么是进程:一个运行起来的(加载到内存中)的程序叫做进程。
举个简单的例子,我们平时写的代码编译好之后就变为可执行的.exe文件,存放到磁盘中,当运行代码时,将我们的代码从磁盘加载到内存中,当然内存中可能还有其他的程序在运行,这么多的程序操作系统就要进行管理,管理的方法是: 先描述再管理。
描述进程----pcb
1.进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合;在Linux中描述进程的结构体叫做task_struct
2.Linux操作系统下的PCB是: task_struct-PCB的一种,task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息
管理进程: 结构体中包含着进程的所有的属性,现在管理进程就变为对一个个结构体进行管理,假设现在要执行优先级最高的进程,就变为先遍历每个结构体,找到优先级最高的进程,然后去执行。
1.查看进程
首先写一个死循环的函数,便于查看进程

运行该程序,就形成了进程。
ps ajx | grep 'main'
产看所有的进程并过滤出和’main'有关的进程:
![]()
这里显示出了有关main的进程,第一行代表运行起来的main程序,第二行代表的时我们查找main进程的指令也是一个进程。但是查找到的进程没有标题,每一列的数字代表的意思是啥我们都不知道,这时候就需要通过指令让系统为我们加上标题
ps axj | head -1 && ps ajx | grep 'main'
每一个进程都有一个进程标识符(PID)用来表示这个进程,PPID代表父进程。
在程序中查看PID和PPID:

getpid()获取该进程的pid getppid()获取进程的ppid

2.杀掉该进程
kill -9 PID

这个进程就被杀掉了
3.另一种查看进程的方法

每一个蓝色的文件夹就是一个进程的id
查看某个进程的相关信息:
ls /proc/pid(进程的id) 
总结:对于/proc/pid文件夹下的文件我们只有读权限,当该进程结束后该文件夹会被系统回收该文件夹下的exe文件表明的是这个进程对应在磁盘上的可执行程序的路径,文件夹下的其他文件代表的是进程的其他属性。一般情况下,当进程在内存中跑起来的时候就与我们的二进制文件没有什么关系了。
四.创建子进程
函数:fork()
函数的返回值:如果子进程创建成功给子进程返回 0 给父进程返回子进程的id
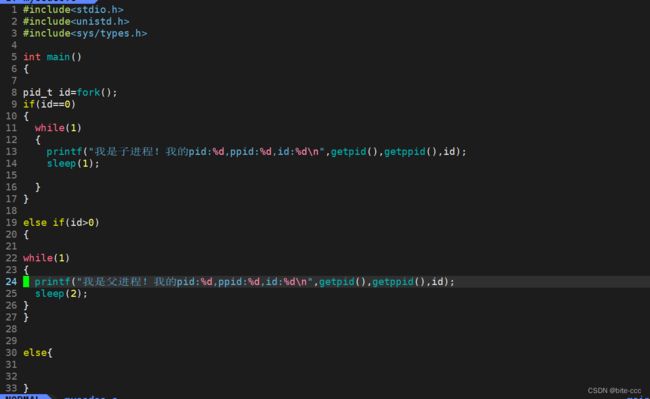
运行结果:

总结:
fork()之后会有父进程和子进程两个进程执行后续的代码,fork之后的代码被父子进程共享,通过返回值的不同让父子进程执行后续代码的一部分。