mysql查询优化:从原理到实践
1.mysql体系结构和索引介绍
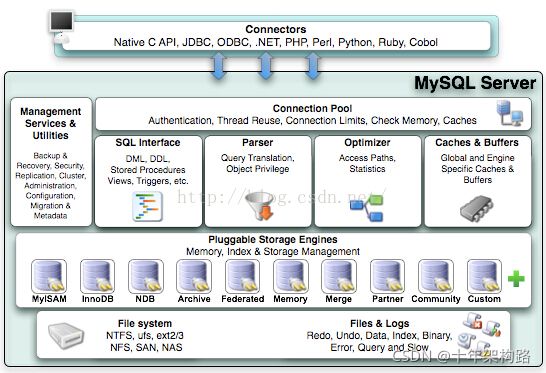
1.1 mysql体系结构
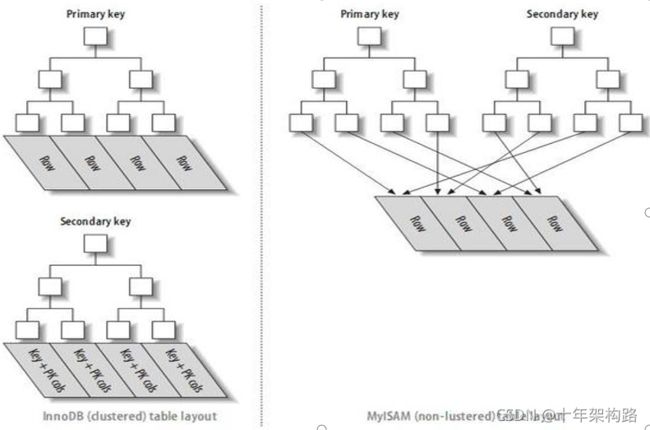
1.2 mysql索引介绍
mysql的innodb索引和myisam索引对比
2.sql语句过程简介和查询计划详解
2.1 mysql执行sql语句过程简介
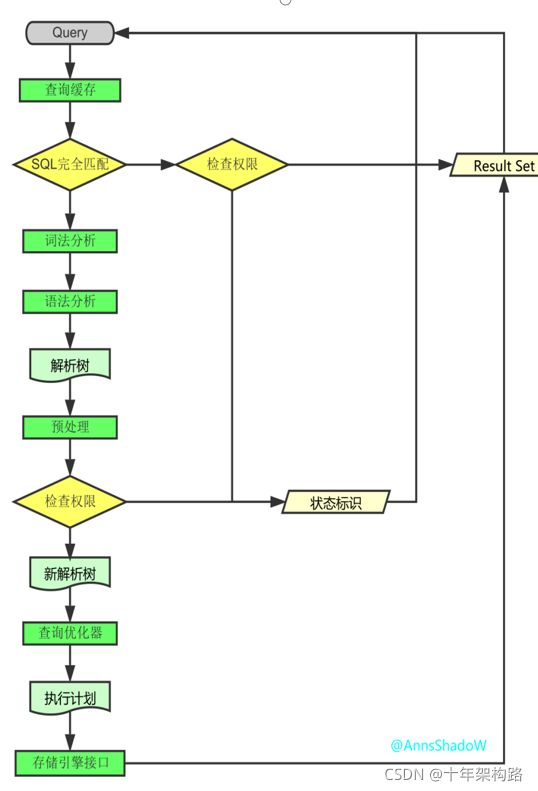
要想优化sql,必须要知道sql是怎样在mysql中执行的,如右图:
(1)客户端发起一条Query请求,监听客户端的‘连接管理模块’接收请求
(2)调用‘用户模块’来进行授权检查
(3)先查查询缓存,检查Query语句是否完全匹配,接着再检查是否具有权限,都成功则直接取数据返回
(4)上一步有失败则转交给‘命令解析器’,经过词法分析,语法分析后生成解析树
(5)如果是SELECT查询还会经由‘查询优化器’做大量的优化,生成执行计划
(6)模块收到请求后,通过‘访问控制模块’检查所连接的用户是否有访问目标表和目标字段的权限
(7)有则调用‘表管理模块’,先是查看table cache中是否存在,有则直接对应的表和获取锁,否则重新打开表文件
(8)根据表的meta数据,获取表的存储引擎类型等信息,通过接口调用对应的存储引擎处理
(9)上述过程中产生数据变化的时候,若打开日志功能,则会记录到相应二进制日志文件中
(10)Query请求完成后,将数据或者执行结果返回客户端
2.1 mysql执行sql语句过程简介
我们从中能够控制的是查询缓存和生成执行计划这两步
(1)查询缓存
查询缓存会存储sql文本和对应的查询结果,sql文本必须完全一致才能够用到查询缓存,表结构和数据的任何变化都会导致与该表相关的所有缓存失效,这种场景适合存储配置信息的数据库使用,不适合我们的场景,所以我们的查询缓存没有打开。
(2)生成执行计划
我们都知道,在数据库管理软件中,最大的性能瓶颈就是在于磁盘IO,也就是数据的存取操作上面。而对于同一份数据,当以不同方式去寻找其中某一点内容的时候,须要读取的数据量可能会有天壤之别,所消耗的资源自然也是区别甚大。所以,当须要从数据库中查询某个数据的时候,所消耗资源的多少主要取决于数据库以一个什么样的数据读取方式来完成查询请求,也就是取决于Query语句的执行计划。而不同写法的Query语句,经过MySQL Parse之后分解的执行计划也不同,即使优化器使用完全一样的统计信息来进行优化,最后所得出的执行计划也可能完全不一样。
2.2 mysql执行计划详解
MySQL Query Optimizer通过执行explain命令告诉我们它将使用一个怎么样的执行计划来优化query,explain是在优化query中最直接有效的验证我们想法的工具。
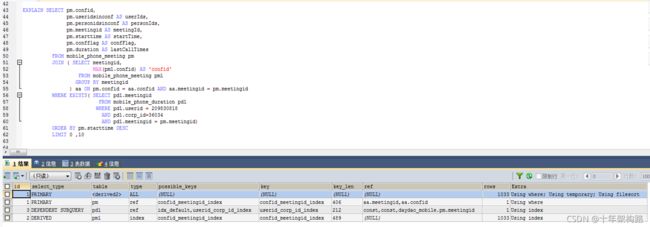
explain的输出结果包括id, select_type, table, type, possible_type, key, key_len, ref, rows, Extra
▶ id:MySQL Query Optimizer选定的执行计划中查询的序列号
▶ Select_type:它的值包括dependent unoin , primary , simple , derived , subquery , uncacheable subquery , union , union result
