预编译(3)
目录
命名约定:
#undef
命令行定义
条件编译
常见的条件编译指令
头⽂件的包含
头⽂件被包含的⽅式:
本地⽂件包含
库⽂件包含
嵌套文件包含
命名约定:
一般来讲函数的宏的使用语法很相似。所以语言本身没法帮我们区分二者那我们平时的一个习惯是:
- 把宏名全部大写
- 函数名不要全部大写
#undef
- 这条指令用于移除一个宏定义 。
- 如果现存的一个名字需要被重新定义,那么它的旧名字首先要被移除。

命令行定义
许多C的编译器提供了一种能力,允许在命令行中定义符号。
用于启动编译过程。
例如:
- 当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处。
- 假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要个数组能够大些。
int main()
{
int arr[sz;int i = 0;
for(i=0; i直接编译会报错,且这个只有在Linux中使用。
![]()
使用了命令行代码,对SZ进行的定义,指定为一个数

这就是类似于一种变长数组,数组的大小是一个变量值,变量值可以随意更改,而这个是在Linux中进行指定数组大小的 。
条件编译
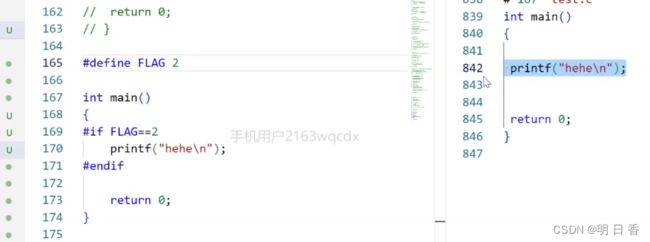
就是 满足条件就编译,不满足条件放弃编译,类似于判断语句或者判断条件。

只有满足2==3才会进入下一步也就是printf("hehe\n")
预编译前后对比

常见的条件编译指令
1.
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__
//..
#endif
2.多个分⽀的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif
头⽂件的包含
头⽂件被包含的⽅式:
本地⽂件包含
#include "filename"
查找策略:先在源⽂件所在⽬录下查找,如果该头⽂件未找到,编译器就像查找库函数头⽂件⼀样在 标准位置查找头⽂件。 如果找不到就提⽰编译错误。(两种方法)
库⽂件包含
#include 查找策略:查找头⽂件直接去标准路径下去查找,如果找不到就提⽰编译错误。
库文件的包含方式因为查找次数的原因,可以写出本地文件包含的方式,但是因为本地文件包含方式只有在第二次查找才会去标准库中进行搜擦,所以效率会慢很多。
嵌套文件包含
出现多个头文件的包含。
如:
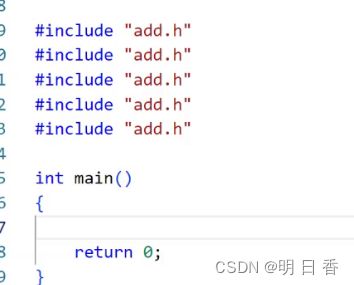
而在预编译中,函数申明的次数可以看出,这种头文件的重复使用,会出现多次函数声明 。

如果直接这样写,test.c⽂件中将add.h包含5次,那么add.h⽂件的内容将会被拷⻉5份在test.c中。
如果add.h ⽂件⽐较⼤,这样预处理后代码量会剧增。
如果⼯程⽐较⼤,有公共使⽤的头⽂件,被⼤家 都能使⽤,⼜不做任何的处理,那么后果真的不堪设想。
如何解决头⽂件被重复引⼊的问题?
答案:条件编译。
每个头⽂件的开头写:
#ifndef __TEST_H__
#define __TEST_H__
//头⽂件的内容
#endif //__TEST_H_或
#pragma once