【扩散模型】3、Stable Diffusion 原型 | High-Resolution Image Synthesis with Latent Diffusion Models

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 感知图像压缩
- 2.2 潜在扩散模型
- 2.3 条件机制
- 三、实验
论文:High-Resolution Image Synthesis with Latent Diffusion Models
代码:https://github.com/CompVis/latent-diffusion
出处:CVPR2022 | 慕尼黑大学
贡献:
- 提出了潜在扩散模型,通过将像素空间转换到潜在空间,能够在保持图像生成效果的同时降低计算量
- 相比纯粹的 transformer-based 方法,本文提出的方法更适合高维数据
- 在多个任务上都获得了很好的效果,包括图像生成、绘制、随机超分辨率等等,和基于像素空间的扩散模型相比显著降低了推理成本
- 可以对超分、绘制、语义合成等任务实现 ~1024x1024 px 的图像渲染
- 由于 cross-attention 的设计,还可以支持多模态训练,如 class-conditional、text-to-image、layout-to-image 等
一、背景
最近火热的 AI 绘画技术吸引了很多人的目光,AI 绘画今年取得如此广泛关注的原因,有很大的功劳得益于 Stable Diffusion 的开源。
Stable Diffusion 是一个基于 Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。
Stable Diffusion 在 LAION-5B 的数据库子集上训练了一个 Latent Diffusion Models,该模型专门用于文图生成。
Stable Diffusion 的原型就是 CVPR2022 的文章:High-Resolution Image Synthesis with Latent Diffusion Models
什么是潜在扩散模型:
- 将图像从像素空间转换到更低维的潜在空间
- 在潜在空间进行相关计算所需的计算量更少,效率更高
- 最后使用解码器从潜在空间复原到像素空间即可
现有的扩散模型(Diffusion Models,DM):
-
通过使用一系列的去噪自编码器,实现了很好的图像合成效果。
-
一般的扩散模型都需要直接在像素空间训练和运行,训练可能需要上百个 GPUs,在测试推理的时候也需要很多硬件支持。
-
如果我们希望生成一张分辨率很高的图片,这就意味着我们训练的空间是一个极其高维的空间,这会导致巨大的参数量和高昂的训练成本。
作者的改进点:
-
基于上述的扩散模型的计算量大的问题,本文作者就思考是否能够在有限的计算资源上训练 DM 模型,同时保持其效果。
-
比如 VAE 和 Diffusion 结合,可以先通过 VAE 将原来的高分辨率图转换到低维空间,然后在低维空间上训练扩散模型,之后通过 Decoder 将低维还原到高维空间。
VAE 可以看做 Encoder,这个过程是感知压缩,也就是忽略图像中的高频信息,保留低频信息,然后在低频图像上做扩散模型的训练,就可以加速很多。
本文提出来的叫做 “Latent”,即潜在空间,通过平衡【降低复杂度】和【保持图像细节】,能在保持保真度的同时实现模型的加速。

二、方法
本文如何从像素空间转换为潜在空间:
- 使用自编码模型来学习一个在感知上和图像空间等价的潜在空间
使用潜在空间的优势:
- 显著降低了复杂度
- 通过将图像转换到低维空间,可以获得计算更高效的扩散模型
- 能够利用从 UNet 架构中继承而来的扩散模型的归纳偏差,使得对具有特殊结构的数据很有效
- 得到的通用的压缩模型可用于训练多种不同的生成模型
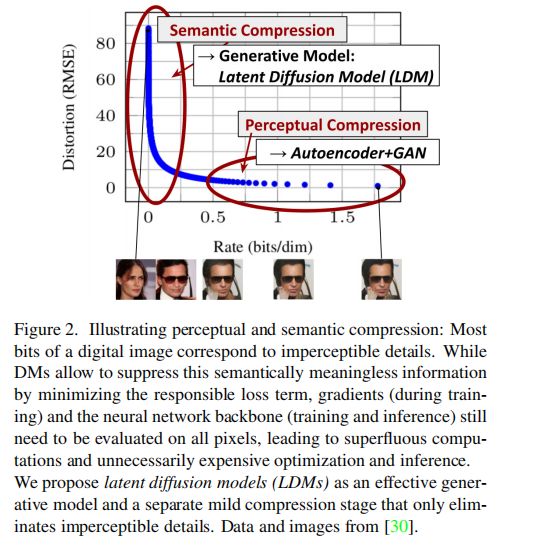
图 2 展示了一个训练过的模型的 Rate-Distortion 的权衡效果:
- 类似于其他的基于概率的模型,前缀空间的学习也分为两个阶段
- 第一个阶段是【感知压缩阶段,Perceptual Compression】:用于去除高频细节,学习少量的语义信息
- 第二个阶段是【语义压缩阶段,Semantic Compression】:使用生成模型学习数据的语义和概念
所以,对潜在模型空间的要求:
- 和像素空间在感知上等价
- 计算量更低
- 能够用于训练可以实现高分辨率图生成的扩散模型
由于扩散模型需要复杂昂贵的损失函数来在像素空间评估效果,所以仍然需要很大的计算时间和计算资源。
作者通过将压缩学习阶段和生成学习阶段分开来避免上面的问题:
- 使用自编码器模型来学习一个和像素空间类似但计算量明显降低的空间
- 远离高维空间后,扩散模型再计算上更高效
- 可以使用 U-Net 结构来学习扩散模型的归纳偏执
- 可以获得通用的压缩模型,可训练不同的生成模型,也可以用于下游任务
2.1 感知图像压缩
给定一个 RGB 空间的图像 x ∈ R H × W × 3 x \in R^{H \times W \times 3} x∈RH×W×3:
- 使用 encoder ε \varepsilon ε 将 x x x 编码到潜在空间 z = ε ( x ) z=\varepsilon(x) z=ε(x)
- 使用 decoder D D D 从潜在空间中将图像复原, x ~ = D ( z ) = D ( ε ( x ) ) \tilde{x}=D(z)=D(\varepsilon(x)) x~=D(z)=D(ε(x))
- encoder 会把原图下采样 f f f 倍
为了避免任意的高方差的潜在空间,作者对比了两者不同的正则化方法:
- K L − r e g KL-reg KL−reg:对学习的潜在空间世家标准的 KL 惩罚,类似于 VAE[46,49]
- V Q − r e g VQ-reg VQ−reg:在解码器内使用矢量量化层
2.2 潜在扩散模型
Latent Diffusion Models,LDM
1、扩散模型
扩散模型是一个概率模型,通过逐步的对一个正态分布的变量去噪,来学习数据的分布 p ( x ) p(x) p(x)。
扩散模型的目标函数如下:
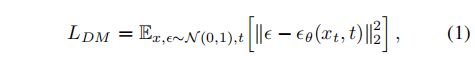
- t t t 是从 1 , 2 , . . . , T {1, 2, ..., T} 1,2,...,T 中采样得来的
- ϵ θ ( x t , x ) \epsilon_{\theta}(x_t,x) ϵθ(xt,x) 是去噪自编码器,用于预测输入 x t x_t xt 去噪后的结果
- x t x_t xt 是 x x x 在 t t t 时刻加噪声的结果
2、潜在表达的生成式建模
训练得到的感知压缩模型包括两部分:
- 编码器 ε \varepsilon ε
- 解码器 D D D
训练之后可以得到一个低维的、高效的潜在空间,该潜在空间中不包括高频的细节信息。
这种低维的空间更适合于基于概率的生成模型,因为其有两个好处:
- 其一,更关注数据中的重要的语义信息
- 其二,能够在低维且高效的空间中进行训练
潜在扩散模型的损失如下:
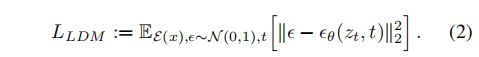
- 使用 UNet 作为 backbone
2.3 条件机制
扩散模型是能够建模成 p ( z ∣ y ) p(z|y) p(z∣y) 形式的条件分布
可以使用一个条件去噪自编码器 ϵ θ ( z t , t , y ) \epsilon_{\theta}(z_t,t,y) ϵθ(zt,t,y),并通过输入 y y y 来控制图像合成过程, y y y 可以是文本、语义特征图等
作者通过 cross-attention 机制增强了 UNet backbone,将 DM 转换成更灵活的图像生成器。能够适应于学习各种输入模式的 attention-based 模型。
作者为了能够预处理来自不同模式的输入 y y y,引入了一个 domain-specific encoder τ θ \tau_{\theta} τθ,可以将 y y y 投影到中间表示 τ θ ( y ) \tau_{\theta}(y) τθ(y),然后通过 cross-attention 将这些信息引入到 UNet 的中间层。
cross-attention 公式如下:
![]()
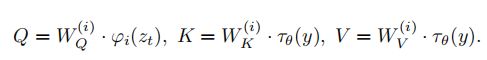
- ϕ \phi ϕ 表示 U-Net 实现 ϵ θ \epsilon_{\theta} ϵθ 的 flattened 中间层表示
最终的损失函数:
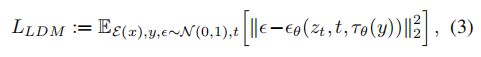
- τ θ \tau_{\theta} τθ (domain-space encoder)和 ϵ θ \epsilon_{\theta} ϵθ 在这里同时被优化
- y y y 是任意形式的输入
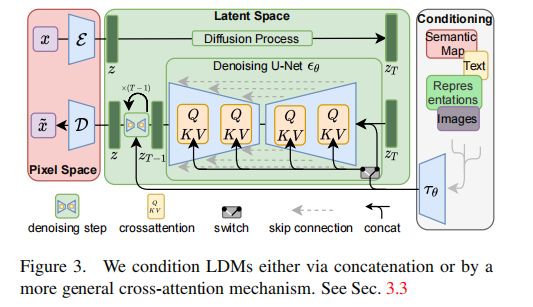
- 首先,看最左侧的粉色框,将像素空间编码到潜在空间,然后在潜在空间中进行前向扩散,得到扩散后的 z T z_T zT
- 之后,看最右侧的黑线框,其中就展示的不同的输入,包括语义图、文本、图像等等,经过 domain-space 的编码器 τ θ \tau_{\theta} τθ 的处理后,输入去噪网络
- 接着,在去噪网络中,级联了多个 U-Net 网络,具体数量取决于 T T T 的值,在每个时刻都使用 U-Net 的结构,U-Net 的每个中间层的输入都是 τ θ ( y ) \tau_{\theta}(y) τθ(y) 和 z T z_T zT,
三、实验
1、关于感知压缩的权衡
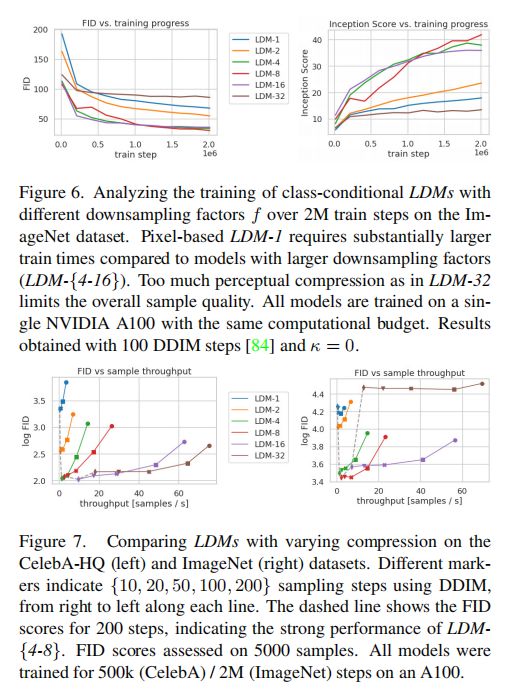
通过分析对 encoder 使用不同的下采样比例 f ∈ { 1 , 2 , 4 , 8 , 16 , 32 } f \in \{1,2,4,8,16,32\} f∈{1,2,4,8,16,32} 对 LDM 造成的影响:
- 如图 6 所示,{1, 2} 的小降采样会让训练缓慢
- {32} 的过大降采样会导致保真度停滞,这是由于压缩的太多导致信息丢失,限制了恢复的效果
- {4-16} 的降采样在效率和保真上实现了平衡
通过图 7 可以看出:
- LDM-4 和 LDM-8 为更好的合成结果提供了最佳的条件
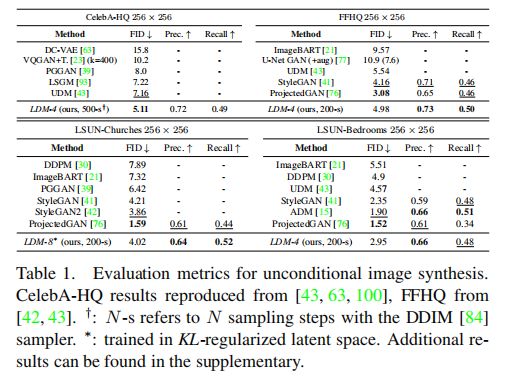
2、使用潜在扩散实现图像生成
在 25 6 2 256^2 2562 的 CelebA-HQ [39], FFHQ [41], LSUN-Churches and Bedrooms [102] 的数据集上验证了 FID 和 PR
CelebA-HQ 上达到了 SOTA FID 5.11

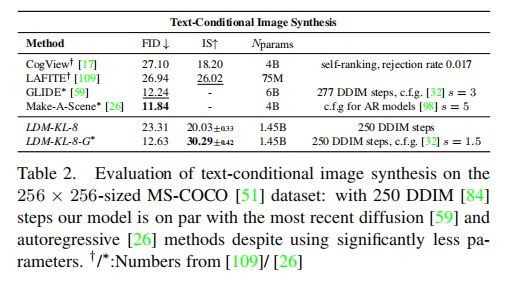
Text-to-Image 图像生成:

使用 layout 来指导图像生成:

使用语义像素图来生成更大分辨率的真实图像:

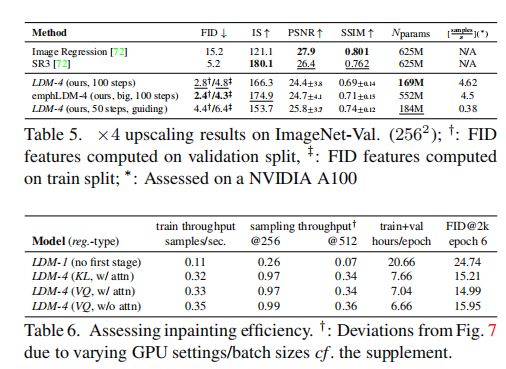
从 64x64 px 超分辨重建 256x256px 的图像:


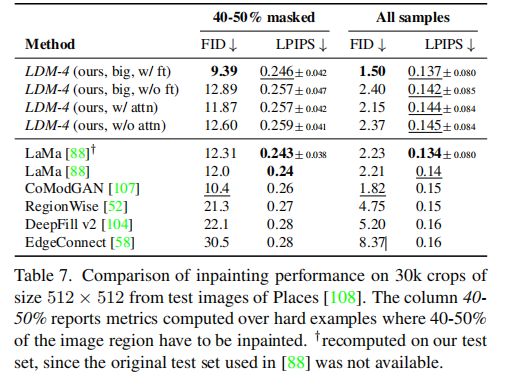
移除目标的效果: