mysql-执行计划
1. 执行计划表概述
id相同表示加载表的顺序是从上到下。
id不同id值越大,优先级越高,越先被执行。id有相同,也有不同,同时存在。
id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
ID为NULL、最后执行【一般出现在UNION场景】

1.1 Explain 执行计划表TYPE列
表的关联类型、比如索引扫描、全表扫描
TYPE列的枚举类型的效率:system > const > eq_ref > ref > rang > index > all
PS:如果你的SQL 查询范围 rang 的时候,已经是红线
交易型系统,到了ref就是红线。
1.2 TYPE列的枚举类型
system 表里只有一条匹配的数据 、代表系统表,一般不怎么出现
const 表里只有一条匹配的数据 、性能非常高。(主键索引和唯一键索引的常量等于查询)
eq_ref 最多只返回一条符合的记录,主键索引和唯一键索引所有关键字被连接使用
ref 普通索引的等值查询、唯一索引的部分前缀查询。可能找到多个符合条件的结果
rang 索引的范围查询、使用一个索引来检索给定的范围行
index 全索引扫描
all 全表扫描
1.3 Explain 执行计划表POSSIBLE_KEYS列
查询可能使用哪些索引
POSSIBLE_KEYS为NULL是如何处理
KEY 列有索引 实际使用的索引是以KEY列为准的 (可以不处理)
KEY 列为NULL
表的数据量很少、全表扫描 (可以不处理)
表的数据量很多、全表扫描(索引优化、SQL优化)
1.4 Explain 执行计划表KEY列
MySQL 查询实际使用的索引
如果MySQL没有使用索引,这一列为NULL。
在实际的MySQL 生产调优过程中,尽量不要使用 force index ignore index
原因1 :高耦合的编程方式、数据库索引出现变更会引发未知的错误。
原因2: 数据库表的数据是实时变化的,强制索引可能在数据量变更阶段出现非最优情况。
例:
1 -- 显示orders表所有的索引
2 show index from orders ;
3 -- force index 强制使用某个索引
4 explain select order_id from orders force index(xxx);
5 -- ignore index忽略某个索引
6 explain select order_id from orders ignore index(xxx);
1.5 Explain 执行计划表KEY-LEN列
MySQL 查询使用了索引的字节数。可以通过字节数判断使用了索引的那些列。
1 -- KEY-LEN = 16 代表16个字节
2 -- 8bit = 一个字节
3 -- 8个字节 = 64bit = 64位
字符串类型
char(n) :n字节长度
varchar(n) :2字节字符的长度。UTF-8编码 3n+2
整形
int 4字节
bigint 8字节
smallint 2字节
tinyint 1字节
时间类型
date 3字节
datatime 8字节
timestamp 4字节
NULL 1字节
1.6 Explain 执行计划表REF列
该列显示哪些列将与列中命名的索引进行比较
查询索引对应的列。常见的值 NULL、表的列名。
1.7 rows
该列表示MySQL认为执行查询必须检查的行数
1.8 filtered
该列指示按表条件筛选的表行的估计百分比。最大值是100,这意味着没有对行进行过滤
1.9 Explain 执行计划表EXTRA列
这一列包含关于MySQL如何解析查询的附加信息。对于不同值的描述
1) Using Index
-- 使用了覆盖索引 【索引列包含了查询的所有字段】
-- 不需要回表
2) Using Where 使用where条件过滤
-- 情况一 全表扫描 比如Where条件是非索引列
-- 情况二 Where条件是索引的前导列范围查询 + 一般返回的结果集非常大
-3) Using Where Using Index
-- 不需要回表
-- 使用了覆盖索引 【索引列包含了查询的所有字段】
-- 情况一 Where条件是索引列之一,但是非索引的前导列
-- 情况二 Where条件是索引的前导列范围查询 + 一般返回的结果集非常大
4) -- Using Index Condition
-- 使用了索引查询、需要回表
-- 查询列无索引覆盖,Where条件是索引的前导列范围查询 数据量要少
-- 如果数据量多了,会退化为Using Where
5) -- Using Temporary 使用临时表来处理查询 【优化点 索引的优化】
6) Using filesort 使用外部索引对查询排序 【优化点 索引的优化】
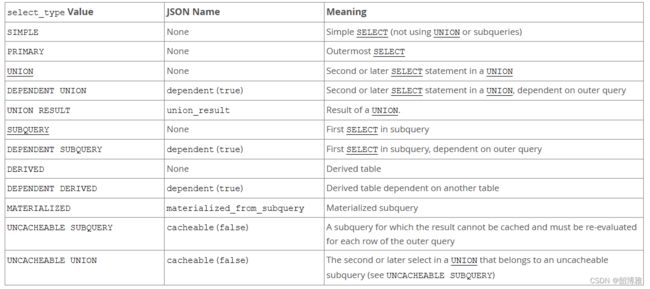
2. select_type
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
3. mysql索引优化
3.1 全值匹配
1 -- 全值匹配 使用等于号
2 -- 希望全值匹配可以走索引 减少全表扫描
PS: show index from index_name查看索引列
3.2 最左前缀匹配
在复合索引(多个列的索引),查询条件使用索引列从左到右的顺序进行查询。
比如索引三列 (a , b , c )。
select * from t where a = ? -- 使用索引
select * from t where a = ? and b = ? -- 使用索引
select * from t where b = ? and a = ? -- 使用索引
select * from t where a = ? and b = ? and c = ? -- 使用索引
select * from t where b = ? and c = ? -- 不使用索引
select * from t where c = ? -- 不使用索引
最左前缀匹配的原因 ·(关键字)是按照创建索引的列的顺序排布的。
3.3 函数操作
查询条件列进行函数处理会导致索引的失效
查询条件的索引列禁止使用函数建议通过转化的方式来进行优化
比如 取整=1 的操作 可以化为 1<= 索引列 < 2
字符串函数 列的截取、计算列的字符串长度取整、取模操作时间、日期格式转成字符串
3.4 覆盖索引
索引列包含了查询列称作覆盖索引。使用覆盖索引可以避免回表。
第一 建议使用覆盖索引来优化查询
第二 不能为了覆盖索引而创建多列索引 【组合索引的列不要超过三列】
不要创建全表列的索引 , 全表列索引属于无效索引,和表几乎等价,浪费写入性能全表列索引等价于 select distinct * from orders;
3.5 不等于匹配
-- 不等于匹配效率很低,有可能退化为全表扫描
-- 避免使用不等于匹配
-- 业务系统需要考虑下
3.6 空匹配
-- key is null 不会使用索引
-- key is not null 不会使用索引
-- 建表的标准 所有的表字段非空
-- 避免使用空值匹配
3.7 LIKE匹配
1 -- 模糊匹配原则 左前缀使用索引(退化为索引的范围查询或全表扫描),其它的匹配方式索引失效(退化为全表扫描)
2 -- sql模糊匹配 符号$ * %
3.8 类型转换
1 --查询条件使用的类型和索引列原类型不一样,存在隐式类型转换。有可能导致索引失效。
-- 优化原则
-- 要求条件查询列的类型和索引列的类型一致。
-- 如果不一致,不要转化索引列,而要将查询条件的类型转化为和索引列一致的类型
MySQL索引优化小结
索引列的数据长度越少越好
索引的数量不是越多越好(写入性能差)、越全越好(索引和表几乎等价)
条件查询推荐使用全值匹配
多列索引推荐使用最左前缀匹配
避免在索引列使用函数操作,会导致索引失效
建议指定查询列(优先使用覆盖索引),禁止使用 SELECT *
避免使用不等于匹配、避免使用or连接条件、避免在Where 条件中使用 NOT IN
避免使用NULL、NOT NULL 匹配、推荐所有的表列是非空的
LIKE 模糊匹配建议使用最左前缀匹配 (like 'ABC%')
推荐查询条件列的类型和索引列的类型一致,避免对索引列进行类型转换
排序的时候,优先使用索引列排序【索引列天然是排序的、排序遵循最左前缀匹配原则order by a】