Go基础之变量和常量
Go基础之变量和常量
文章目录
- Go基础之变量和常量
-
- 一. 标识符、关键字、内置类型和函数
-
- 1.1 标识符
- 1.2 关键字
- 1.3 保留字
- 1.4 内置类型
- 1.4.1 值类型:
- 1.4.2 引用类型:(指针类型)
- 1.5 内置函数
- 1.6 内置接口error
- 二.Go变量命名规范
-
- 2.1 采用驼峰体命名
- 2.2 简单、短小为首要原则
- 2.3 变量名字中不要带有类型信息
- 2.4 保持简短命名变量含义上的一致性
- 2.5 常量命名规则
- 三、变量
-
- 3.1 变量的来历
- 3.2 声明变量
- 3.3 标准声明(声明单个变量)
- 3.4 默认初始值
- 3.5 声明多个变量
- 3.6 变量声明的“语法糖”
-
- 3.6.1 短变量声明
- 3.6.2 省略类型信息的声明
- 3.7 匿名变量
- 四、包级变量声明
-
- 4.1 包级变量介绍
- 4.2 包级变量的声明形式分类
-
- 4.2.1 第一类:声明并同时显式初始化
- 4.2.2 第二类:声明但延迟初始化
- 五、局部变量声明
-
- 5.1 局部变量介绍
- 5.2 局部变量声明形式分类
-
- 5.2.1 第一类:对于延迟初始化的局部变量声明,我们采用通用的变量声明形式
- 5.2.2 第二类:对于声明且显式初始化的局部变量,建议使用短变量声明形式
- 六、变量声明小结
- 七、常量
-
- 7.1 常量定义
- 7.2 声明多个常量
- 7.3 常量的创新点
-
- 7.3.1 无类型常量
- 7.3.2 隐式转型
- 7.3.3 实现枚举
-
- iota 介绍
- 几个常见的`iota`示例:
一. 标识符、关键字、内置类型和函数
1.1 标识符
在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc, _, _123, a123。
1.2 关键字
Go语言中关键字有25个;关键字不能用于自定义名字,只能再特定语法结构中使用。
Go语言中有25个关键字:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
1.3 保留字
此外,Go语言中还有37个保留字
- 保留字:主要对应内建的常量、类型和函数
Constants: true false iota nil
内建函数
Types: int int8 int16 int32 int64
内建类型 uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
Functions: make len cap new append copy close delete
内建函数 complex real imag
panic recover
1.4 内置类型
1.4.1 值类型:
bool
int(32 or 64), int8, int16, int32, int64
uint(32 or 64), uint8(byte), uint16, uint32, uint64
float32, float64
string
complex64, complex128
array -- 固定长度的数组
1.4.2 引用类型:(指针类型)
slice -- 序列数组(最常用)
map -- 映射
chan -- 管道
1.5 内置函数
Go 语言拥有一些不需要进行导入操作就可以使用的内置函数。它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因此,它们需要直接获得编译器的支持。
append -- 用来追加元素到数组、slice中,返回修改后的数组、slice
close -- 主要用来关闭channel
delete -- 从map中删除key对应的value
panic -- 停止常规的goroutine (panic和recover:用来做错误处理)
recover -- 允许程序定义goroutine的panic动作
real -- 返回complex的实部 (complex、real imag:用于创建和操作复数)
imag -- 返回complex的虚部
make -- 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new -- 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap -- capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy -- 用于复制和连接slice,返回复制的数目
len -- 来求长度,比如string、array、slice、map、channel ,返回长度
print、println -- 底层打印函数,在部署环境中建议使用 fmt 包
1.6 内置接口error
type error interface { //只要实现了Error()函数,返回值为String的都实现了err接口
Error() String
}
二.Go变量命名规范
Go语言中的函数、变量、常量、类型、方法所有的命名,都遵循一个简单的命名规则:
2.1 采用驼峰体命名
采用CamelCase驼峰命名法**(官方推荐)**
- 如果只在包内可用,就采用小驼峰命名,即:
lowerCamelCase - 如果要在包外可见,就采用大驼峰命名,即:
UpperCamelCase
2.2 简单、短小为首要原则
为变量、类型、函数和方法命名时依然要以简单、短小为首要原则。我们对Go标准库(Go 1.12版本)中标识符名称进行统计的结果如下(去除Go关键字和builtin函数):
// 在$GOROOT/src下
$cat $(find . -name '*.go') | indents | sort | uniq -c | sort -nr | sed 30q
105896 v
71894 err
54512 Args
49472 t
44090 _
43881 x
43322 b
36019 i
34432 p
32011 s
28435 AddArg
26185 c
25518 n
25242 e1
23881 r
21681 AuxInt
20700 y
...”
我们看到了大量单字母的标识符命名,这是Go在命名上的一个惯例。一般来说,Go标识符仍以单个单词作为命名首选。从Go标准库代码的不完全统计结果来看,不同类别标识符的命名呈现出以下特征:
- 函数、变量、常量、类型、方法命名遵循简单、短小为首要原则
- 函数/方法的参数和返回值变量以单个单词或单个字母为主;
- 由于方法在调用时会绑定类型信息,因此方法的命名以单个单词为主;
- 函数多以多单词的复合词进行命名;类型多以多单词的复合词进行命名。
- 条件、循环变量可以是单个字母或单个单词,Go倾向于使用单个字母。Go建议使用更短小
- 包以小写单个单词命名,包名应该和导入路径的最后一段路径保持一致
- 接口优先采用单个单词命名,一般加er后缀。Go语言推荐尽量定义小接口,接口也可以组合
- 命名要简短有意义,关键字和保留字都不建议用作变量名
package main
import "fmt"
func main() {
cityName := "北京" // 驼峰式命名(官方推荐)
city_name := "上海" //下划线式
fmt.Println(studentNameIsASheng, student_name_is_A_lian)
}
2.3 变量名字中不要带有类型信息
比如以下命名:
userSlice []*User users []*User
[bad] [good]
带有类型信息的命名只是让变量看起来更长,并没有给开发者阅 读代码带来任何好处。
不过有些开发者会认为:userSlice中的类型信息可以告诉我们变 量所代表的底层存储是一个切片,这样便可以在userSlice上应用切片 的各种操作了。提出这样质疑的开发者显然忘记了一条编程语言命名的惯例:保持变量声明与使用之间的距离越近越好,或者在第一次使 用变量之前声明该变量。这个惯例与Go核心团队的Andrew Gerrard曾 说的“一个名字的声明和使用之间的距离越大,这个名字的长度就越 长”异曲同工。如果在一屏之内能看到users的声明,那么-Slice这个类 型信息显然不必放在变量的名称中了。
2.4 保持简短命名变量含义上的一致性
从上面的统计可以看到,Go语言中有大量单字母、单个词或缩写 命名的简短命名变量。有人可能会认为简短命名变量会降低代码的可读性。Go语言建议通过保持一致性来维持可读性。一致意味着代码中相同或相似的命名所传达的含义是相同或相似的,这样便于代码阅读者或维护者猜测出变量的用途。
这里大致分析一下Go标准库中常见短变量名字所代表的含义,这 些含义在整个标准库范畴内的一致性保持得很好。
变量v、k、i 的常用含义:
// 循环语句中的变量
for i, v := range s {
// i 通常用作下标变量; v 通常用作元素值
// 在这里执行你的循环逻辑
}
for k, v := range m {
// k 通常用作键(key)变量; v 通常用作元素值
// 在这里执行你的循环逻辑
}
for v := range r {
// v 通常用作元素值
// 在这里执行你的循环逻辑,这通常用于接收 channel 中的值
}
// 在 if 语句中使用变量 v
if v := mimeTypes[ext]; v != "" {
// v 通常用作元素值
// 在这里执行你的条件逻辑
}
// 在 switch/case 语句中使用变量 v
switch v := ptr.Elem(); v.Kind() {
case reflect.Int:
// v 通常用作元素值
// 在这里执行你的条件逻辑
}
// 在 select 语句的 case 中使用变量 v
select {
case v := <-c:
// v 通常用作元素值
// 在这里执行你的条件逻辑
}
// 创建反射值 v
v := reflect.ValueOf(x)
变量 t 的常用含义
t := time.Now() // 通常用于表示时间
t := &time.Timer{} // 通常用于表示定时器
if t := md.typemap[off]; t != nil {
// 通常用于表示类型
}
变量 b 的常用含义
b := make([]byte, n) // 通常用于表示 byte 切片
b := new(bytes.Buffer) // 通常用于表示 byte 缓冲
2.5 常量命名规则
以下是一些常见的Go常量命名约定:
- 常量名:通常使用驼峰命名法(CamelCase)来命名常量。
- 全大写:虽然Go中不要求常量名全部大写,但在实际编码中,全大写的常量名仍然是一种常见的约定,特别是对于导出的常量(首字母大写的常量,可在包外部访问)。
- 类型信息:Go中的数值型常量通常不需要显式赋予类型信息,因为Go会根据上下文进行类型推断。因此,常量的名字通常不包含类型信息。
- 多单词组合:常量名通常会使用多个单词组合以传达更准确的含义,这有助于提高代码的可读性。例如,
defaultMaxMemory和deleteHostHeader。 - 不同包内的常量:对于导出的常量,可以考虑使用全大写的常量名以确保在其他包中能够访问。
下面是标准库中的例子经过格式化的代码:
// $GOROOT/src/net/http/request.go
const (
defaultMaxMemory = 32 << 20 // 32 MB
)
const (
deleteHostHeader = true
keepHostHeader = false
)
// $GOROOT/src/math/sin.go
const (
PI4A = 7.85398125648498535156E-1 // 0x3fe921fb40000000,
PI4B = 3.77489470793079817668E-8 // 0x3e64442d00000000,
PI4C = 2.69515142907905952645E-15 // 0x3ce8469898cc5170,
)
// $GOROOT/src/syscall/zerrors_linux_amd64.go
// 错误码
const (
E2BIG = Errno(0x7)
EACCES = Errno(0xd)
EADDRINUSE = Errno(0x62)
EADDRNOTAVAIL = Errno(0x63)
EADV = Errno(0x44)
)
// 信号
const (
SIGABRT = Signal(0x6)
SIGALRM = Signal(0xe)
SIGBUS = Signal(0x7)
SIGCHLD = Signal(0x11)
)
三、变量
3.1 变量的来历
在编程语言中,为了方便操作内存特定位置的数据,我们用一个特定的名字与位于特定位置的内存块绑定在一起,这个名字被称为变量。
但这并不代表我们可以通过变量随意引用或修改内存,变量所绑定的内存区域是要有一个明确的边界的。也就是说,通过这样一个变量,我们究竟可以操作 4 个字节内存还是 8 个字节内存,又或是 256 个字节内存,编程语言的编译器或解释器需要明确地知道。综上:变量就是指定了某存储单元(Memory Location)的名称,该存储单元会存储特定类型的值。
那么,编程语言的编译器或解释器是如何知道一个变量所能引用的内存区域边界呢?
其实,动态语言和静态语言有不同的处理方式。动态语言(比如 Python、Ruby 等)的解释器可以在运行时通过对变量赋值的分析,自动确定变量的边界。并且在动态语言中,一个变量可以在运行时被赋予大小不同的边界。
而静态编程语言在这方面的“体验略差”。静态类型语言编译器必须明确知道一个变量的边界才允许使用这个变量,但静态语言编译器又没能力自动提供这个信息,这个边界信息必须由这门语言的使用者提供,于是就有了“变量声明”。通过变量声明,语言使用者可以显式告知编译器一个变量的边界信息。在具体实现层面呢,这个边界信息由变量的类型属性赋予。
作为身处静态编程语言阵营的 Go 语言,它沿袭了静态语言的这一要求:使用变量之前需要先进行变量声明。
3.2 声明变量
Go语言中的变量必须声明后才能使用,同一作用域内不支持重复声明。 并且Go语言的变量声明后必须使用。
3.3 标准声明(声明单个变量)
在 Go 语言中,有一个通用的变量声明方法是这样的:
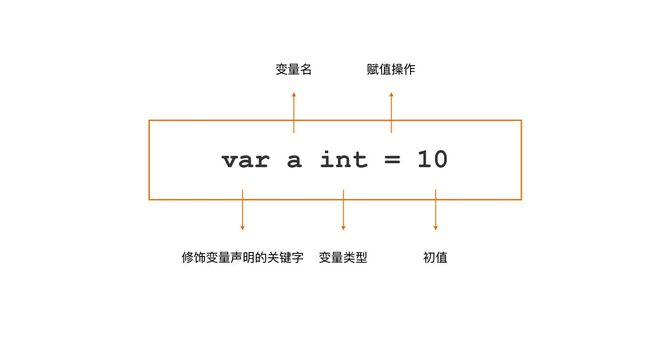
这个变量声明分为四个部分:
- var 是修饰变量声明的关键字;
- a 为变量名;
- int 为该变量的类型;
- 10 是变量的初值。
3.4 默认初始值
如果你没有显式为变量赋予初值,Go 编译器会为变量赋予这个类型的零值:
var a int // a的初值为int类型的零值:0
什么是类型的零值呢?Go 语言的每种原生类型都有它的默认值,这个默认值就是这个类型的零值。以下是内置原生类型的默认值(即零值):
| 内置原生类型 | 默认值(零值) |
|---|---|
| 所有整型类型 | 0 |
| 浮点类型 | 0.0 |
| 布尔类型 | false |
| 字符串类型 | “” |
| 指针、接口、切片、channel、 map和函数类型 | nil |
3.5 声明多个变量
每声明一个变量就需要写var关键字会比较繁琐,go语言中还支持批量变量声明:
var (
a int = 128
b int8 = 6
s string = "hello"
c rune = 'A'
t bool = true
)
Go 语言还支持在一行变量声明中同时声明多个变量:
var a, b, c int = 5, 6, 7
这样的多变量声明同样也可以用在变量声明块中,像下面这样:
var (
a, b, c int = 5, 6, 7
c, d, e rune = 'C', 'D', 'E'
)
简单示例:
package main
import "fmt"
func main() {
var (
name string = "jarvis"
age int = 18
height int = 168
)
fmt.Println("my name is", name, ", age is", age, "and height is", height)
}
3.6 变量声明的“语法糖”
3.6.1 短变量声明
在函数内部,可以使用更简略的 := 方式声明并初始化变量。标准范式如下:
varName := initExpression
简单示例:
package main
import "fmt"
func main() {
name, age := "naveen", 29 // 简短声明
fmt.Println("my name is", name, "age is", age)
}
运行上面的程序,可以看到输出为 my name is naveen age is 29。
简短声明要求 := 操作符左边的所有变量都有初始值。下面程序将会抛出错误 cannot assign 1 values to 2 variables,这是因为 age 没有被赋值。
package main
import "fmt"
func main() {
name, age := "naveen" //error
fmt.Println("my name is", name, "age is", age)
}
3.6.2 省略类型信息的声明
Go 编译器允许我们省略变量声明中的类型信息,标准范式如下:
var varName = initExpression
比如下面就是一个省略了类型信息的变量声明:
var b = 13
那么 Go 编译器在遇到这样的变量声明后是如何确定变量的类型信息呢?
其实很简单,Go 编译器会根据右侧变量初值自动推导出变量的类型,并给这个变量赋予初值所对应的默认类型。比如,整型值的默认类型 int,浮点值的默认类型为 float64,复数值的默认类型为 complex128。其他类型值的默认类型就更好分辨了,在 Go 语言中仅有唯一与之对应的类型,比如布尔值的默认类型只能是 bool,字符值默认类型只能是 rune,字符串值的默认类型只能是 string 等。
如果我们不接受默认类型,而是要显式地为变量指定类型,除了通用的声明形式,我们还可以通过显式类型转型达到我们的目的:
var b = int32(13)
显然这种省略类型信息声明的“语法糖”仅适用于在变量声明的同时显式赋予变量初值的情况,下面这种没有初值的声明形式是不被允许的:
var b
结合多变量声明,我们可以使用这种变量声明“语法糖”声明多个不同类型的变量:
package main
import "fmt"
func main() {
var a, b, c = 12, 'A', "hello"
fmt.Printf("a type: %T\n", a)
fmt.Printf("b type: %T\n", b)
fmt.Printf("c type: %T\n", c)
}
// 输出
a type: int
b type: int32
c type: string
在这个变量声明中,我们声明了三个变量 a、b 和 c,但它们分别具有不同的类型,分别为 int、rune 和 string。在这种变量声明语法糖中,我们省去了变量类型信息,但 Go 编译器会为我们自动推导出类型信息。
3.7 匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示,例如:
func foo() (int, string) {
return 10, "babyboy"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。 (在Lua等编程语言里,匿名变量也被叫做哑元变量。)
注意事项:
- 函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外。_多用于占位,表示忽略值。
四、包级变量声明
4.1 包级变量介绍
- 包级变量 (package varible),也就是在包级别可见的变量。如果是导出变量(大写字母开头),那么这个包级变量也可以被视为全局变量
- 包级变量只能使用带有 var 关键字的变量声明形式,不能使用短变量声明形式,但在形式细节上可以有一定灵活度。
4.2 包级变量的声明形式分类
4.2.1 第一类:声明并同时显式初始化
先看看这个代码:
// $GOROOT/src/io/io.go
var ErrShortWrite = errors.New("short write")
var ErrShortBuffer = errors.New("short buffer")
var EOF = errors.New("EOF")
我们可以看到,这个代码块里声明的变量都是 io 包的包级变量。在 Go 标准库中,对于变量声明的同时进行显式初始化的这类包级变量,实践中多使用这种省略类型信息的“语法糖”格式:
var varName = initExpression
就像我们前面说过的那样,Go 编译器会自动根据等号右侧 InitExpression 结果值的类型,来确定左侧声明的变量的类型,这个类型会是结果值对应类型的默认类型。
当然,如果我们不接受默认类型,而是要显式地为包级变量指定类型,那么我们有两种方式,我这里给出了两种包级变量的声明形式的对比示例。
//第一种:
plain
var a = 13 // 使用默认类型
var b int32 = 17 // 显式指定类型
var f float32 = 3.14 // 显式指定类型
//第二种:
var a = 13 // 使用默认类型
var b = int32(17) // 显式指定类型
var f = float32(3.14) // 显式指定类型
虽然这两种方式都是可以使用的,但从声明一致性的角度出发,Go 更推荐我们使用后者,这样能统一接受默认类型和显式指定类型这两种声明形式,尤其是在将这些变量放在一个 var 块中声明时,你会更明显地看到这一点。
所以我们更青睐下面这样的形式:
var (
a = 13
b = int32(17)
f = float32(3.14)
)
4.2.2 第二类:声明但延迟初始化
对于声明时并不立即显式初始化的包级变量,我们可以使用下面这种通用变量声明形式:
var a int32
var f float64
我们知道,虽然没有显式初始化,Go 语言也会让这些变量拥有初始的“零值”。如果是自定义的类型,我也建议你尽量保证它的零值是可用的。
这里还有一个注意事项,就是声明聚类与就近原则。
正好,Go 语言提供了变量声明块用来把多个的变量声明放在一起,并且在语法上也不会限制放置在 var 块中的声明类型,那我们就应该学会充分利用 var 变量声明块,让我们变量声明更规整,更具可读性,现在我们就来试试看。
通常,我们会将同一类的变量声明放在一个 var 变量声明块中,不同类的声明放在不同的 var 声明块中,比如下面就是我从标准库 net 包中摘取的两段变量声明代码:
// $GOROOT/src/net/net.go
var (
netGo bool
netCgo bool
)
var (
aLongTimeAgo = time.Unix(1, 0)
noDeadline = time.Time{}
noCancel = (chan struct{})(nil)
)
我们可以看到,上面这两个 var 声明块各自声明了一类特定用途的包级变量。那我就要问了,你还能从中看出什么包级变量声明的原则吗?
其实,我们可以将延迟初始化的变量声明放在一个 var 声明块 (比如上面的第一个 var 声明块),然后将声明且显式初始化的变量放在另一个 var 块中(比如上面的第二个 var 声明块),这里我称这种方式为“声明聚类”,声明聚类可以提升代码可读性。
到这里,你可能还会有一个问题:我们是否应该将包级变量的声明全部集中放在源文件头部呢?答案不能一概而论。
使用静态编程语言的开发人员都知道,变量声明最佳实践中还有一条:就近原则。也就是说我们尽可能在靠近第一次使用变量的位置声明这个变量。就近原则实际上也是对变量的作用域最小化的一种实现手段。在 Go 标准库中我们也很容易找到符合就近原则的变量声明的例子,比如下面这段标准库 http 包中的代码就是这样:
// $GOROOT/src/net/http/request.go
var ErrNoCookie = errors.New("http: named cookie not present")
func (r *Request) Cookie(name string) (*Cookie, error) {
for _, c := range readCookies(r.Header, name) {
return c, nil
}
return nil, ErrNoCookie
}
在这个代码块里,ErrNoCookie 这个变量在整个包中仅仅被用在了 Cookie 方法中,因此它被声明在紧邻 Cookie 方法定义的地方。当然了,如果一个包级变量在包内部被多处使用,那么这个变量还是放在源文件头部声明比较适合的。
五、局部变量声明
5.1 局部变量介绍
- 局部变量 (local varible),也就是 Go 函数或方法体内声明的变量,仅在函数或方法体内可见
- 它们的生命周期仅限于函数执行期间。
5.2 局部变量声明形式分类
5.2.1 第一类:对于延迟初始化的局部变量声明,我们采用通用的变量声明形式
其实,我们之前讲过的省略类型信息的声明和短变量声明这两种“语法糖”变量声明形式都不支持变量的延迟初始化,因此对于这类局部变量,和包级变量一样,我们只能采用通用的变量声明形式:
var err error
5.2.2 第二类:对于声明且显式初始化的局部变量,建议使用短变量声明形式
短变量声明形式是局部变量最常用的声明形式,它遍布在 Go 标准库代码中。对于接受默认类型的变量,我们使用下面这种形式:
a := 17
f := 3.14
s := "hello, gopher!"
对于不接受默认类型的变量,我们依然可以使用短变量声明形式,只是在":="右侧要做一个显式转型,以保持声明的一致性:
a := int32(17)
f := float32(3.14)
s := []byte("hello, gopher!")
这里我们还要注意:尽量在分支控制时使用短变量声明形式。
分支控制应该是 Go 中短变量声明形式应用得最广泛的场景了。在编写 Go 代码时,我们很少单独声明用于分支控制语句中的变量,而是将它与 if、for 等控制语句通过短变量声明形式融合在一起,即在控制语句中直接声明用于控制语句代码块中的变量。
你看一下下面这个我摘自 Go 标准库中的代码,strings 包的 LastIndexAny 方法为我们很好地诠释了如何将短变量声明形式与分支控制语句融合在一起使用:
// $GOROOT/src/strings/strings.go
func LastIndexAny(s, chars string) int {
if chars == "" {
// Avoid scanning all of s.
return -1
}
if len(s) > 8 {
// 作者注:在if条件控制语句中使用短变量声明形式声明了if代码块中要使用的变量as和isASCII
if as, isASCII := makeASCIISet(chars); isASCII {
for i := len(s) - 1; i >= 0; i-- {
if as.contains(s[i]) {
return i
}
}
return -1
}
}
for i := len(s); i > 0; {
// 作者注:在for循环控制语句中使用短变量声明形式声明了for代码块中要使用的变量c
r, size := utf8.DecodeLastRuneInString(s[:i])
i -= size
for _, c := range chars {
if r == c {
return i
}
}
}
return -1
}
而且,短变量声明的这种融合的使用方式也体现出“就近”原则,让变量的作用域最小化。
另外,虽然良好的函数 / 方法设计都讲究“单一职责”,所以每个函数 / 方法规模都不大,很少需要应用 var 块来聚类声明局部变量,但是如果你在声明局部变量时遇到了适合聚类的应用场景,你也应该毫不犹豫地使用 var 声明块来声明多于一个的局部变量,具体写法你可以参考 Go 标准库 net 包中 resolveAddrList 方法:
// $GOROOT/src/net/dial.go
func (r *Resolver) resolveAddrList(ctx context.Context, op, network,
addr string, hint Addr) (addrList, error) {
... ...
var (
tcp *TCPAddr
udp *UDPAddr
ip *IPAddr
wildcard bool
)
... ...
}
六、变量声明小结
以下是变量声明形象化的一副小图:

你可以看到,良好的变量声明实践需要我们考虑多方面因素,包括明确要声明的变量是包级变量还是局部变量、是否要延迟初始化、是否接受默认类型、是否是分支控制变量并结合聚类和就近原则等。
七、常量
7.1 常量定义
相对于变量,常量是恒定不变的值,多用于定义程序运行期间不会改变的那些值。 常量的声明和变量声明非常类似,只是把var换成了const,常量在定义的时候必须赋值。
const Pi float64 = 3.14159265358979323846 // 单行常量声明
声明了pi常量之后,在整个程序运行期间它们的值都不能再发生变化了。
所以,常量不能再重新赋值为其他的值。因此下面的程序将不能正常工作,它将出现一个编译错误: cannot assign to a.
package main
func main() {
const a = 55 // 允许
a = 89 // 不允许重新赋值
}
7.2 声明多个常量
多个常量也可以一起声明:
// 以const代码块形式声明常量
const (
size int64 = 4096
i, j, s = 13, 14, "bar" // 单行声明多个常量
)
const同时声明多个常量时,如果省略了值则表示和上面一行的值相同。 例如:
const (
n1 = 100
n2
n3
)
上面示例中,常量n1、n2、n3的值都是100。
7.3 常量的创新点
7.3.1 无类型常量
Go 语言对类型安全是有严格要求的:即便两个类型拥有着相同的底层类型,但它们仍然是不同的数据类型,不可以被相互比较或混在一个表达式中进行运算。这一要求不仅仅适用于变量,也同样适用于有类型常量(Typed Constant)中,你可以在下面代码中看出这一点:
type myInt int
const n myInt = 13
const m int = n + 5 // 编译器报错:cannot use n + 5 (type myInt) as type int in const initializer
func main() {
var a int = 5
fmt.Println(a + n) // 编译器报错:invalid operation: a + n (mismatched types int and myInt)
}
那么在 Go 语言中,只有这一种方法能让上面代码编译通过、正常运行吗 ?当然不是,我们也可以使用 Go 中的无类型常量来实现,你可以看看这段代码:
type myInt int
const n = 13
func main() {
var a myInt = 5
fmt.Println(a + n) // 输出:18
}
你可以看到,在这个代码中,常量 n 在声明时并没有显式地被赋予类型,在 Go 中,这样的常量就被称为无类型常量(Untyped Constant),即不带有明确类型的字面常量
不过,无类型常量也不是说就真的没有类型,它也有自己的默认类型,不过它的默认类型是根据它的初值形式来决定的。像上面代码中的常量 n 的初值为整数形式,所以它的默认类型为 int。
7.3.2 隐式转型
隐式转型说的就是,对于无类型常量参与的表达式求值,Go 编译器会根据上下文中的类型信息,把无类型常量自动转换为相应的类型后,再参与求值计算,这一转型动作是隐式进行的。但由于转型的对象是一个常量,所以这并不会引发类型安全问题,Go 编译器会保证这一转型的安全性。
继续以上面代码为例来分析一下,Go 编译器会自动将 a+n 这个表达式中的常量 n 转型为 myInt 类型,再与变量 a 相加。由于变量 a 的类型 myInt 的底层类型也是 int,所以这个隐式转型不会有任何问题。
不过,如果 Go 编译器在做隐式转型时,发现无法将常量转换为目标类型,Go 编译器也会报错,比如下面的代码就是这样:
const m = 1333333333
var k int8 = 1
j := k + m // 编译器报错:constant 1333333333 overflows int8
这个代码中常量 m 的值 1333333333 已经超出了 int8 类型可以表示的范围,所以我们将它转换为 int8 类型时,就会导致编译器报溢出错误。
从前面这些分析中,我们可以看到,无类型常量与常量隐式转型的“珠联璧合”使得在 Go 这样的具有强类型系统的语言,在处理表达式混合数据类型运算的时候具有比较大的灵活性,代码编写也得到了一定程度的简化。也就是说,我们不需要在求值表达式中做任何显式转型了。所以说,在 Go 中,使用无类型常量是一种惯用法,你可以多多熟悉这种形式。
7.3.3 实现枚举
Go 语言其实并没有原生提供枚举类型,但是我们可以使用 const 代码块定义的常量集合,来实现枚举。这是因为,枚举类型本质上就是一个由有限数量常量所构成的集合。不过,用 Go 常量实现枚举可不是我们的临时起意,而是 Go 设计者们的原创,他们在语言设计之初就希望将枚举类型与常量合二为一,这样就不需要再单独提供枚举类型了。
使用Go 实现枚举,分解成了 Go 中的两个特性:自动重复上一行,以及引入 const 块中的行偏移量指示器 iota,这样它们就可以分别独立使用了。
接下来我们逐一看看这两个特性。首先,**Go 的 const 语法提供了“隐式重复前一个非空表达式”的机制,**比如下面代码:
const (
Apple, Banana = 11, 22
Strawberry, Grape
Pear, Watermelon
)
这个代码里,常量定义的后两行并没有被显式地赋予初始值,所以 Go 编译器就为它们自动使用上一行的表达式,也就获得了下面这个等价的代码:
const (
Apple, Banana = 11, 22
Strawberry, Grape = 11, 22 // 使用上一行的初始化表达式
Pear, Watermelon = 11, 22 // 使用上一行的初始化表达式
)
不过,仅仅是重复上一行显然无法满足“枚举”的要求,因为枚举类型中的每个枚举常量的值都是唯一的。所以,Go 在这个特性的基础上又提供了“神器”:iota,有了 iota,我们就可以定义满足各种场景的枚举常量了。
iota 介绍
iota是Go 语言的一个预定义标识符-常量计数器,只能在常量的表达式中使用。
iota 表示的是 const 声明块(包括单行声明)中,每个常量所处位置在块中的偏移值(从零开始)。同时,每一行中的 iota 自身也是一个无类型常量,可以像前面我们提到的无类型常量那样,自动参与到不同类型的求值过程中来,不需要我们再对它进行显式转型操作。
可以看看下面这个 Go 标准库中 sync/mutex.go 中的一段基于 iota 的枚举常量的定义:
// $GOROOT/src/sync/mutex.go
const (
mutexLocked = 1 << iota
mutexWoken
mutexStarving
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)
首先,这个 const 声明块的第一行是 mutexLocked = 1 << iota ,iota 的值是这行在 const 块中的偏移,因此 iota 的值为 0,我们得到 mutexLocked 这个常量的值为 1 << 0,也就是 1。
接着,第二行:mutexWorken 。因为这个 const 声明块中并没有显式的常量初始化表达式,所以我们根据 const 声明块里“隐式重复前一个非空表达式”的机制,这一行就等价于 mutexWorken = 1 << iota。而且,又因为这一行是 const 块中的第二行,所以它的偏移量 iota 的值为 1,我们得到 mutexWorken 这个常量的值为 1 << 1,也就是 2。
然后是 mutexStarving。这个常量同 mutexWorken 一样,这一行等价于 mutexStarving = 1 << iota。而且,也因为这行的 iota 的值为 2,我们可以得到 mutexStarving 这个常量的值为 1 << 2,也就是 4;
再然后我们看 mutexWaiterShift = iota 这一行,这一行为常量 mutexWaiterShift 做了显式初始化,这样就不用再重复前一行了。由于这一行是第四行,而且作为行偏移值的 iota 的值为 3,因此 mutexWaiterShift 的值就为 3。
而最后一行,代码中直接用了一个具体值 1e6 给常量 starvationThresholdNs 进行了赋值,那么这个常量值就是 1e6 本身了。
看完这个例子的分析,我相信你对于 iota 就会有更深的理解了。不过我还要提醒你的是,位于同一行的 iota 即便出现多次,多个 iota 的值也是一样的,比如下面代码:
const (
Apple, Banana = iota, iota + 10 // 0, 10 (iota = 0)
Strawberry, Grape // 1, 11 (iota = 1)
Pear, Watermelon // 2, 12 (iota = 2)
)
我们以第一组常量 Apple 与 Banana 为例分析一下,它们分为被赋值为 iota 与 iota+10,而且由于这是 const 常量声明块的第一行,因此两个 iota 的值都为 0,于是就有了“Apple=0, Banana=10”的结果。下面两组变量分析过程也是类似的,你可以自己试一下。
如果我们要略过 iota = 0,从 iota = 1 开始正式定义枚举常量,我们可以效仿下面标准库中的代码:
// $GOROOT/src/syscall/net_js.go
const (
_ = iota
IPV6_V6ONLY // 1
SOMAXCONN // 2
SO_ERROR // 3
)
在这个代码里,我们使用了空白标识符作为第一个枚举常量,它的值就是 iota。虽然它本身没有实际意义,但后面的常量值都会重复它的初值表达式(这里是 iota),于是我们真正的枚举常量值就从 1 开始了。
那如果我们的枚举常量值并不连续,而是要略过某一个或几个值,又要怎么办呢?我们也可以借助空白标识符来实现,如下面这个代码:
const (
_ = iota // 0
Pin1
Pin2
Pin3
_
Pin5 // 5
)
以看到,在上面这个枚举定义中,枚举常量集合中没有 Pin4。为了略过 Pin4,我们在它的位置上使用了空白标识符。
这样,Pin5 就会重复 Pin3,也就是向上数首个不为空的常量标识符的值,这里就是 iota,而且由于它所在行的偏移值为 5,因此 Pin5 的值也为 5,这样我们成功略过了 Pin4 这个枚举常量以及 4 这个枚举值。
而且,iota 特性让我们维护枚举常量列表变得更加容易。比如我们使用传统的枚举常量声明方式,来声明一组按首字母排序的“颜色”常量,也就是这样:
const (
Black = 1
Red = 2
Yellow = 3
)
假如这个时候,我们要增加一个新颜色 Blue。那根据字母序,这个新常量应该放在 Red 的前面呀。但这样一来,我们就需要像下面代码这样将 Red 到 Yellow 的常量值都手动加 1,十分费力。
const (
Blue = 1
Black = 2
Red = 3
Yellow = 4
)
那如果我们使用 iota 重新定义这组“颜色”枚举常量是不是可以更方便呢?我们可以像下面代码这样试试看:
const (
_ = iota
Blue
Red
Yellow
)
这样,无论后期我们需要增加多少种颜色,我们只需将常量名插入到对应位置就可以,其他就不需要再做任何手工调整了。
而且,如果一个 Go 源文件中有多个 const 代码块定义的不同枚举,每个 const 代码块中的 iota 也是独立变化的,也就是说,每个 const 代码块都拥有属于自己的 iota,如下面代码所示:
const (
a = iota + 1 // 1, iota = 0
b // 2, iota = 1
c // 3, iota = 2
)
const (
i = iota << 1 // 0, iota = 0
j // 2, iota = 1
k // 4, iota = 2
)
你可以看到,每个 iota 的生命周期都始于一个 const 代码块的开始,在该 const 代码块结束时结束。
几个常见的iota示例:
使用_跳过某些值
const (
n1 = iota //0
n2 //1
_
n4 //3
)
iota声明中间插队
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0
定义数量级 (这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。)
const (
_ = iota
KB = 1 << (10 * iota) // i<<10
MB = 1 << (10 * iota) // i<<20
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
多个iota定义在一行
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)