C++语法基础(第一次打卡)
文章目录
- 前言
- 一、编程入门
-
-
- 1.变量
- 2.常量
-
- 二、顺序结构程序设计
-
-
- 1.数据类型
- 2.输入输出
- 3.位运算符与表达式
-
- 三、循环结构程序设计
-
-
- 1.for语句
- 2.while语句
- 3.多重循环
-
- 四、数组
-
-
- 1.一维数组
- 2.多维数组
-
- 五、字符串
-
-
- 1.字符数组
-
- 六、函数与结构体
-
-
- 1.函数
- 2.递归函数
- 3.结构体
-
- 七、总结
前言
这是学习c++课程的第一次打卡,对于这次学习,不仅复习了以前学过的知识,也弥补了我的知识漏洞。
一、编程入门
1.变量
1.变量是专门用来存储数据的容器,会根据数据类型决定容量大小。变量对应着内存中的一个地址,用于计算时数据的存储和读取。
声明方式为 数据类型 变量名称。
2.变量名称也叫做标识符,表示⽤来标记和识别不同变量的不同的符号,有固定的构造规则:
(1)只能由字⺟、数字和下划线组成;特别的;在C++中,标识符中的英文字母是区分大小写的;
(2)数字不可以出现在第一个位置上;
(3)C++的关键字(保留字)不可以⽤做标识符;
2.常量
我们大部分使用字面量以及符号常量这两种常量。
1.
(1)字面量, 就是装在变量里的常量。
(2)字面量就是存放在变量中的数据。
(3)字面量经常会被装到变量中使用,这个操作叫做赋值,一般写法为变量名=字面量。
(4)字面量在程序运行过程中不能够被改变,也不能被赋值。
(5)且字面量有整数字面量和浮点字面量。整数字面量就有十进制,十六进制等。浮点字面量就是小数,指数等。
2.字符字面量-表达字符的常量
(1)字符字面量分为单字符字面量与转义符字面量。
(2)单字符字面量:通过将单个字符括在单引号内来创建字符字面量。
例如:‘a’,‘m’,‘F’,‘2’,’}‘等。
(3)转义符字面量:使用’'开头的转义字符序列来表示一个特殊字符。
二、顺序结构程序设计
1.数据类型
(1)在C++的变量声明中,变量名之前需要指定数据类型
格式: 数据类型 变量名称;
C++中的数据类型分为基本类型和复合类型:
其中基本类型包括了整数、浮点数,我们接下来会详细展开;
复合类型是在基本类型的基础上创建的,包括数组、字符串以及结构体等。
(2)整数类型
整数类型分为数值整数类型和字符类型。
数值整数可以按照占用内存大小分为short、int、long以及long long这四种,占用内存越大的类型能表示的数值范围就更大。
| short | 至少占据2个字节,即16位;一般占用2字节 |
|---|---|
| int | 在现代系统中一般占用4个字节,即32位;类型长度大于等于short类型 |
| long | 长度至少占据4个字节,且大于等于int类型;一般占用4个字节 |
| long long | 长度至少占据8个字节,且大于等于long类型;一般占用8个字节 |
(3)每个类型数据可以分别指定有符号版本和无符号版本.
如果是无符号版本,那么一个8位的内存块可以一一对应到0~255之间的整数;
如果是有符号版本,那么就会考虑负数,这个8位的内存块可以表示一128~127之间的整数。
(4)整数类型-字符整数类型
字符类型char是另一种特殊的整数类型,它专门用来存储计算机中的基本符号:英文字母、数字以及标点等。
(5)浮点类型 即表示精度
C++中的浮点数分为三种类型:float、double以及long double,分别表示不同的精度。
| float | 通常占用4个字节,有效位数为6位 |
|---|---|
| double | 占用的空间是float类型的两倍,即8个字节,有效位数为15位 |
| long double | 一般占用16个字节的空间 |
2.输入输出
(1)C语言格式化输入输出
printf()函数和scanf()函数进行格式化的输出输入。
printf()函数打印数据的指令和待打印数据的类型存在着对应关系。scanf()函数转换说明与printf()函数几乎一一对应。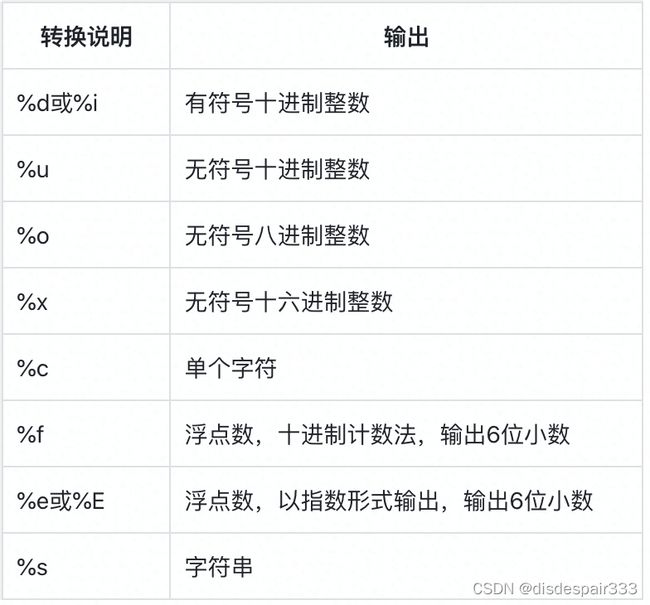
(2)C++形象地将数据输入和输出的传送过程称为流(stream)
C++的标准函数库iostream中提供了输入输出(I/O)功能。需要使用预处理指令include加载对应的头文件,并且使用标准命名空间std。
输入 cin>>内存存储单元1 >> 内存存储单元2 >> …;
输出 cout << 输出内容1 << 输出内容2 <<…;
3.位运算符与表达式
C++中共包含6种按位运算符:
| 按位与运算符 | & |
|---|---|
| 按位或运算符 | |
| 异或运算符 | ^ |
| 按位取反运算符 | ~ |
| 左移运算符 | << |
| 右移运算符 | >> |
按位运算符只能对字符整型以及数值整型数据类型的常量或变量使用,不能对浮点类型数据进行计算。(如何使用不再例举)
三、循环结构程序设计
1.for语句
for 循环语法:
for (循环变量赋初始值;循环条件;更新循环变量) {
循环体
}
首先会给循环变量赋一个初始值
然后判断是否满足循环条件
如果不满足,直接跳出循环;
如果满足,执行循环体,更新循环变量,再跳回去重新判断是否满足循环条件。
使用for循环时,【循环变量赋初始值】,【循环条件】,【更新循环变量】这三个表达式都可以省略,变为for ( ; ; ) ,这表示不用给循环变量赋初始值,也不用在每次执行后更新循环变量,同时循环的条件始终为真,也就是说每次都会选择进入循环体。
举例:1+2+···+n;
#include除了正常的循环之外,循环控制语句可以更改程序执行的正常序列。循环控制语句常用的是 break 和 continue。
break在switch语句中也有用到过,用于停止执行模块内后面的程序语句
通常放在循环体中,当执行到这句语句时,跳出整个循环,也就是说整个循环立即终止
continue通常也是放在循环体中,当执行到这句语句时,跳过当前循环体,强迫进入下一次循环
2.while语句
(1)while循环只关注循环终止的条件和循环体的内容本身。
语法:while (循环成立条件) {循环体}
while 循环执行逻辑:
只要循环成立条件为真,就进入循环体
重复这个步骤,直到循环成立条件为假
(2)do while 循环
无论如何,至少要执行一次猜数字的操作。
语法
do {循环体} while (循环成立条件);
for和while比较: for循环需要清楚循环次数/循环变量的变化范围;while循环只需要知道什么时候停下来就好。
3.多重循环
就是循环的嵌套。
举例 乘法表
for (int i = 1; i <= 9; i++) {
for (int j = 1; j <= i ; j++) {
cout << j << "*" << i << "=" << j*i << "\t";
}
cout << endl;
}
或者
for (int i = 1; i <= 9; i++) {
int j = 1;
while (j <= i) {
cout << j << "*" << i << "=" << j*i << "\t";
j++;
}
cout << endl;
注意事项: 可以任意嵌套,比如for嵌for,for嵌while,while嵌for,while嵌while都可以
如果是for嵌for,内外层的循环变量(比如上述代码的i和j)需要用不一样的变量,否则容易产生混乱
在嵌套操作中都需要使用缩进,以增强代码可读性 可以多层嵌套,但是有时候太多层嵌套容易超时,需要引起注意
四、数组
1.一维数组
(1)C++使用数组来实现一次性声明很多变量的功能,具有以下特性:
1.创建后的数组大小固定
2.同一数组中的元素类型相同
3.是一系列数据顺序集合
在C++中声明数组时,需要指定元素类型、数组名称以及数组长度:
元素类型 数组名称[数组长度];
int sales[6];
便得到了一个名字叫sales的数组
这个数组包含6个元素
数组每个元素都是int类型
(2)初始化
一种初是在声明的同时,使用大括号包含对应数值,直接对整个数组初始化
另一种初始化方式是在声明之后,逐个访问数组元素进行一一初始化赋值。
例:
int sales[6] = {1, 3, 5, 7, 9, 11}。全赋值
int sales[6] = {1, 3}。给出的元素赋值前面,后面补零
int sales[] = {1, 3, 5, 7, 9, 11}。会直接初始化长度为6的数组
通常,会用循环进行赋值
int sales[6];
for (int i = 0; i < 6; i++) {
sales[i] = 2 * i + 1;
}
2.多维数组
定义:对于每一个元素也是数组的数组称为多维数组。
例如,二维数组可以看作是每个元素都是一维数组的数组
声明二维数组需要在命名的同时,指定元素的类型以及每个维度的长度
元素类型 数组名称[数组第一个维度长度][数组第二个维度长度]
也是可以用循环去赋初值
int scores[5][3];
for (int i = 0; i < 5; i++) {
for (int j = 0; j < 3; j++) cin >> scores[i][j];
}
五、字符串
1.字符数组
字符串定义:对于一串字符组成的,我们想把它看成一个整体,即为字符串
C++ 中的字符串常量是用一对双引号括起来,由 ‘\0’ 作为结束符的一组字符,即一个字符串是多占用一个空间的比如"hello",分别就是’h’,‘e’,‘l’,‘l’,‘o’,’\0’六个元素。
并且"a"和’a’是不同的,不能搞混,前者是字符串,两个字节,后者是字符,只有一个字节。
字符数组初始化
char userName[11] = {'h','e','l','l','o'};
或者
char userName[11] = "hello";
字符数组的输入输出
直接cin>>字符数组名。cout<<字符数组名。
输入的时候,使用cin语句,会不断的读入字符串,直到遇到一个空白字符(空格、回车或者制表符)就结束读入。
输出的时候,从字符数组的第一个字符开始输出,直到遇到 ‘\0’(不会输出 ‘\0’)或者如果一个字符数组中包含一个以上’\0’,则遇第一个’\0’时cout输出就结束
六、函数与结构体
1.函数
函数定义:
为了省去时间去编译一些常用的代码,就用到了函数,即用函数把这些常用的功能步骤描述出来并进行封装,以解决这个问题。而函数的根本,就是定义,调用。
函数的声明:
函数的声明是为了告诉编译器如何调用这个函数,形式如下:
返回值类型 函数名(参数1类型 参数1, 参数2类型 参数2, …, 参数n类型 参数n);
返回值类型:一个函数可以返回一个值,返回值类型是函数返回的值的数据类型。
有些函数执行所需的操作而不返回任何值,此时的返回值类型是void
函数名:这是函数的实际名称。
一般会按照函数功能取名。
参数:声明时的参数称为形式参数,类似于占位符。
参数是可选的,函数可能不包含参数,也可以包含很多个参数。
在函数被调用之前,我们并不知道形式参数的值是什么。
比如定义一个比较最大值并返还的函数。
int max(int a,int b)
{
int t;
if (a>b)
t = a;
else
t= b;
cout<<t<<endl;
return 0;
}
定义完成之后就是调用。只有调用了这个函数,才会去执行函数中的代码。即在main函数中调用max函数。
int main()
{
int x,y,z;
cin>>x>>y;
z=max(x,y);
return 0;
}
当然,参数可以用数组参数如int fun(int a[],int n).也可以在函数定义是,给参数设置默认值,如int fun(int a,int b=100),如果只传递一个参数a,那么b默认100,如果传递a,b两个参数,那么b就不是默认值。
2.递归函数
定义:在函数的函数体中又调用了它自己,这就叫做“递归函数”。(即反复调用自己,套娃)
递归函数的两个基本要素:
1.递归关系,就是找到n和n-1之间的关系。
2.递归的终止条件,有了终止条件,函数才能递归停止。
对于递归,最长见的,也就是阶乘问题了。除了阶乘,汉诺塔也是很好玩的一个递归题型。
汉诺塔问题源自印度一个古老的传说,印度教的“创造之神”梵天创造世界时做了 3 根金刚石柱,其中的一根柱子上按照从小到大的顺序摞着 64 个黄金圆盘。梵天命令一个叫婆罗门的门徒将所有的圆盘移动到另一个柱子上,移动过程中必须遵守以下规则:
每次只能移动柱子最顶端的一个圆盘;
每个柱子上,小圆盘永远要位于大圆盘之上;
题目:左到右有A、B、C三根柱子,其中A柱子上面有从小叠到大的n个圆盘,现要求将A柱子上的圆盘移到C柱子上去,期间需要遵循以下原则:
一次只能移到一个盘子且大盘子不能在小盘子上面,求移动的步骤。若将A最上面的盘子移动到B上,则可表示为 “A -> B”。
输入描述:
一行,一个整数n (n <= 20)。
输出描述:
若干行,每行代表一次操作。
比如:
A -> B
示例 1:
输入:
2
输出:
A -> B
A -> C
B -> C
#include 对于递归问题,用的还是不熟练,对于最经典的汉诺塔问题,必须吃透,理解!
3.结构体
应用:用结构体来将一组不同类型的数据聚合成一个整体,以便于去处理这些信息。
格式:
struct 结构体名称 {
数据类型1 变量名1;
数据类型2 变量名2, 变量名3;
…
数据类型n 变量名m;
};
例:
struct Student{
int number, birth_year;
string name;
};//定义一个结构体名称为Student的结构体。有number号码,生日,名字三个变量。
注意:使用struct关键字。大括号后面需要有分号。
定义结构体之后,我们就可以声明结构体类型的变量,作为结构体的实例。并且有两种方法初始化结构体,即用初始化列表或构造函数。
struct Student{
int number, birth_year;
string name;
};
Student zhang_san, li_si, wang_mazi;
或
Student students[500];
或者直接在定义结构体时,声明结构体变量。
(1)
struct Student{
int number, birth_year;
string name;
} zhang_san, li_si, wang_mazi;
(2)
struct Student{
int number, birth_year;
string name;
} students[500];
而初始化就是定义完之后直接
struct Student{
int number, birth_year;
string name;
};
Student zhang_san = {1, 2000, “ZhangSan”};
或者可以先在结构体内部完成一个构造函数,再调用这个构造函数来初始化结构体变量
struct Student{
int number, birth_year;
string name;
Student (int num=0, string n="") {
number = num;
birth_year = 2000;
name = n;
}
};
Student li_si(2, “LiSi”);
对于结构体的访问,就是用结构体变量名.结构体成员变量名的方式访问。
即cout << zhang_san.number << endl;
cout << zhang_san.name << endl;
cout << li_si.birth_year << endl;
结构体作为函数参数
结构体变量也可以通过传值传递和引用传递给函数。
传值传递意味着需要生成整个原始结构的副本并传递给函数。
Tips:因为不希望浪费时间和空间来复制整个结构体,所以传值传递一般在结构很小时采用。
引用传递意味着函数可以访问原始结构的成员变量,从而可能更改它们
如果不想让函数更改任何成员变量值,那么可以将结构体变量作为一个常量引用传递给函数
常量引用传递需要在参数类型前加上const关键字。
对于这一点理解不深很深,便直接附上了解释。
七、总结
通过这五天的学习,和其他人的交流讨论,感觉有了些许提升,并且疫情封校,这次学习让我紧张了起来,不再是那种碌碌无为的状态,有了收获就有了进步,并且在打代码的过程中,我有了开始时的思维,也感受到完成时的喜悦。后面越来越难,也得继续努力。