opencv入门教程
opencv入门教程
- 图像的读取,显示,与写入
- 摄像头
- 保存视频
- 读取视频
- 画画
- 鼠标操作
-
- event 参数说明
- flags 参数说明
- 轨迹栏
- 图像基本操作
- 图像处理
-
- HSV颜色空间
- 几何变换
-
- 放大缩小
- 平移
- 旋转
- 仿射变换
- 透视变换
- 简单阈值
- 自适应阈值
- Otsu的二值化
- 2D卷积(图像过滤)
- 图像模糊(图像平滑)
-
- 平均
- 高斯模糊
- 中位模糊
- 双边滤波
- 形态学转换
-
- 侵蚀
- 扩张
- 开运算
- 闭运算
- 形态学梯度
- 顶帽
- 黑帽
- 图像梯度
- Canny边缘检测
- 图像金字塔
- 轮廓
图像的读取,显示,与写入
import cv2 as cv
import numpy as np
# imread 读取图像
# 第一个参数是图像的位置
# 第二个参数是读取图像的方式
# cv.IMREAD_COLOR: 加载彩色图像。任何图像的透明度都会被忽视。它是默认标志。
# cv.IMREAD_GRAYSCALE:以灰度模式加载图像
# cv.IMREAD_UNCHANGED:加载图像,包括alpha通道
img = cv.imread('2.jpg',cv.IMREAD_COLOR)
#创建一个窗口
#cv.WINDOW_NORMA 可以调整窗口大小
cv.namedWindow('www',cv.WINDOW_NORMAL)
#显示图像 第一个参数窗口名称 第二个参数显示图像对象
cv.imshow('www',img)
#等待键盘输入,如果没有输入就一直在这卡住
cv.waitKey(0)
#销毁所有窗口
cv.destroyAllWindows()
#把img保存
cv.imwrite("./3.png",img)
摄像头
import numpy as np
import cv2 as cv
#获取摄像头对象
cap = cv.VideoCapture(0)
#如果获取失败
if not cap.isOpened():
print("camera is not open")
exit()
#cap.get(propId)方法访问该视频的某些功能
#下面是修改视频高和宽
cap.set(cv.CAP_PROP_FRAME_WIDTH, 320)
cap.set(cv.CAP_PROP_FRAME_HEIGHT, 240)
while True:
#读取摄像头
ret,frame = cap.read()
#如果读取失败
if not ret:
print("not read")
break
#显示获得的一帧
cv.imshow("hh",frame)
#如果按键q按下
if cv.waitKey(1) == ord('q'):
break
#释放资源
cap.release()
cv.destroyAllWindows()
保存视频
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
#FourCC是用于指定视频编解码器的4字节代码
fourcc = cv.VideoWriter_fourcc(*'XVID')
#创建VideoWriter对象
out = cv.VideoWriter('output2.avi',fourcc,20.0,(640,480))
while cap.isOpened():
ret,frame = cap.read()
if not ret:
print('not read')
break
#反转
frame = cv.flip(frame,0)
out.write(frame)
cv.imshow('frame',frame)
if cv.waitKey(1) == ord("q"):
break
cap.release()
out.release()
cv.destroyAllWindows()
读取视频
import numpy as np
import cv2 as cv
#根摄像头只有这一个差别
cap = cv.VideoCapture('output2.avi')
while cap.isOpened():
ret,frame = cap.read()
if not ret :
print('no ret')
break
cv.imshow('hh',frame)
#播放速度由waitkey决定
if cv.waitKey(25) == ord('q'):
break
cap.release()
cv.destroyAllWindows()
画画
import numpy as np
import cv2 as cv
#创建一个黑色图像
img = np.zeros((512,512,3),np.uint8)
#画一条线 起始坐标,结束坐标,颜色,厚度
cv.line(img,(0,0),(20,20),(0,0,255),5)
2
#画一个矩形 左上角坐标,右下角坐标,颜色,厚度
cv.rectangle(img,(50,50),(200,200),(0,255,0),3)
#画一个圆形 圆心坐标,半径,颜色,是否填充 -1填充 0不填充
cv.circle(img,(225,225),80,(255,0,0),0)
#画一个椭圆 椭圆圆心,长短轴长度,偏转角度,圆弧起始角度,终止角度,颜色,是否填充
cv.ellipse(img,(256,256),(100,50),20,0,360,255,-1)
#顶点的坐标 ROWSx1x2
pts = np.array([[16,0],[50,50],[80,169],[462,500]], np.int32)
pts = pts.reshape((-1,1,2))
#画一个多边形 多边形的顶点,是否封闭,颜色
cv.polylines(img,[pts],True,(255,255,255))
#字体类型
font = cv.FONT_HERSHEY_SIMPLEX
#屏幕写字 内容,起始坐标,字体,字体大小,颜色,粗细,cv2.LINE_AA
cv.putText(img,'ssh',(10,500), font, 5,(255,255,255),10,cv.LINE_AA)
cv.imshow("a",img)
cv.waitKey(0)
鼠标操作
event 参数说明
EVENT_MOUSEMOVE (0) 表示滑动事件。
EVENT_LBUTTONDOWN (1) 表示左键点击事件。
EVENT_RBUTTONDOWN (2) 表示右键点击事件。
EVENT_MBUTTONDOWN (3) 表示中键点击事件。
EVENT_LBUTTONUP (4) 表示左键放开事件。
EVENT_RBUTTONUP (5) 表示右键放开事件。
EVENT_MBUTTONUP (6) 表示中键放开事件。
EVENT_LBUTTONDBLCLK (7) 表示左键双击事件。
EVENT_RBUTTONDBLCLK (8) 表示右键双击事件。
EVENT_MBUTTONDBLCLK (9) 表示中键双击事件。
flags 参数说明
EVENT_FLAG_LBUTTON (1) 表示左键拖曳事件。
EVENT_FLAG_RBUTTON (2) 表示右键拖曳事件。
EVENT_FLAG_MBUTTON (4) 表示中键拖曳事件。
EVENT_FLAG_CTRLKEY (8) 表示(8~15)按 Ctrl 不放。
EVENT_FLAG_SHIFTKEY (16) 表示(16~31)按 Shift 不放。
EVENT_FLAG_ALTKEY (32) 表示(32~39)按 Alt 不放。
import numpy as np
import cv2 as cv
drawing = False # 如果按下鼠标,则为真
mode = True # 如果为真,绘制矩形。按 m 键可以切换到曲线
ix,iy = -1,-1
# 鼠标回调函数
def draw_circle(event,x,y,flags,param):
global ix,iy,drawing,mode
if event == cv.EVENT_LBUTTONDOWN:
drawing = True
ix,iy = x,y
elif event == cv.EVENT_MOUSEMOVE:
if drawing == True:
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
elif event == cv.EVENT_LBUTTONUP:
drawing = False
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
# 创建一个黑色的图像,一个窗口,并绑定到窗口的功能
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
if cv.waitKey(20) & 0xFF == 27:
break
cv.destroyAllWindows()
轨迹栏
import numpy as np
import cv2 as cv
def nothing(x):
pass
# 创建一个黑色的图像,一个窗口
img = np.zeros((300,512,3), np.uint8)
cv.namedWindow('image')
# 创建颜色变化的轨迹栏
cv.createTrackbar('R','image',0,255,nothing)
cv.createTrackbar('G','image',0,255,nothing)
cv.createTrackbar('B','image',0,255,nothing)
# 为 ON/OFF 功能创建开关
switch = '0 : OFF \n1 : ON'
cv.createTrackbar(switch, 'image',0,1,nothing)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == 27:
break
# 得到四条轨迹的当前位置
r = cv.getTrackbarPos('R','image')
g = cv.getTrackbarPos('G','image')
b = cv.getTrackbarPos('B','image')
s = cv.getTrackbarPos(switch,'image')
if s == 0:
img[:] = 0
else:
img[:] = [b,g,r]
cv.destroyAllWindows()
图像基本操作
import numpy as np
import cv2 as cv
img = cv.imread("2.jpg")
print(img.shape)
#只显示蓝色通道
blue = img[:,:,0]
# cv.imshow("a",blue)
# 把一个区域赋值
img[10:200,300:500,1:3] = 255
# cv.imshow("a",img)
#图像融合人
img1 = cv.imread('1.jpg')
img2 = cv.imread('6.jpg')
# dst = cv.addWeighted(img1,0.7,img2,0.3,0)
# cv.imshow('dst',dst)
#按位运算
# 我想把logo放在左上角,所以我创建了ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols ]
# 现在创建logo的掩码,并同时创建其相反掩码
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
#提取图像上由颜色的部分 有颜色为1 无颜色为 0
ret, mask = cv.threshold(img2gray, 150, 255, cv.THRESH_BINARY)
#反转提取的图像
mask_inv = cv.bitwise_not(mask)
# 与运算有下面三个特点:
# 任何数a和0进行按位与运算,都会得到0。
# 任何数a和255进行按位与运算,都会都得这个数a本身。
# 任何数a和自身进行按位与运算,也是会得到这个数a本身。
# 根据与运算的上面特点,我们可以构造掩码图像。
# 掩码图像上的255位置点的像素值就可以来源于原图像;掩码图像上的0位置点的像素值就是0(黑色)。
# 只有mask对应位置元素不为0的部分才输出,否则该位置像素的所有通道分量都设置为0
## 现在将ROI中logo的区域涂黑
img1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)
# 仅从logo图像中提取logo区域
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
# 将logo放入ROI
dst = cv.add(img1_bg,img2_fg)
# 把ROI放入主图像
img1[0:rows, 0:cols ] = dst
cv.imshow('res',dst)
cv.waitKey(0)
cv.destroyAllWindows()
图像处理
HSV颜色空间
import numpy as np
import cv2 as cv
def nothing(x):
pass
cv.namedWindow('image')
# 创建颜色变化的轨迹栏
cv.createTrackbar('lower_h','image',0,255,nothing)
cv.createTrackbar('lower_s','image',0,255,nothing)
cv.createTrackbar('lower_v','image',0,255,nothing)
cv.createTrackbar('upper_h','image',255,255,nothing)
cv.createTrackbar('upper_s','image',255,255,nothing)
cv.createTrackbar('upper_v','image',255,255,nothing)
cap = cv.VideoCapture(0)
while(1):
ret,frame = cap.read()
#bgb -> hsv
hsv = cv.cvtColor(frame,cv.COLOR_BGR2HSV)
#设置阈值范围
lower_h = cv.getTrackbarPos('lower_h','image')
lower_s = cv.getTrackbarPos('lower_s','image')
lower_v = cv.getTrackbarPos('lower_v','image')
upper_h = cv.getTrackbarPos('upper_h','image')
upper_s = cv.getTrackbarPos('upper_s','image')
upper_v = cv.getTrackbarPos('upper_v','image')
#如果要提取多个阈值可以分开提取然后相加
lower_blue = np.array([lower_h,lower_s,lower_v])
upper_blue = np.array([upper_h,upper_s,upper_v])
# 设置HSV的阈值
mask = cv.inRange(hsv,lower_blue,upper_blue)
# 将掩膜和图像逐像素相加
#掩码图像上的255位置点的像素值就可以来源于原图像;掩码图像上的0位置点的像素值就是0(黑色)
#操作只会在掩膜值为非空的像素点上执行,并将其他像素点的值置为0。
res = cv.bitwise_and(frame,frame,mask=mask)
cv.imshow('mask',mask)
cv.imshow('res',res)
k = cv.waitKey(5) & 0xFF
if k == 27:
break
cv.destroyAllWindows()
几何变换
放大缩小
import numpy as np
import cv2 as cv
img = cv.imread('6.jpg')
# res = cv.resize(img,None,fx=0.5,fy=0.5,interpolation=cv.INTER_AREA)
#或者
#或者
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
cv.imshow('res',res)
cv.waitKey(0)
cv.destroyAllWindows()
平移

import numpy as np
import cv2 as cv
img = cv.imread('6.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
#第三个参数是输出图像的大小,其形式应为(width,height)。记住width =列数,height =行数。
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
旋转

import numpy as np
import cv2 as cv
img = cv.imread('6.jpg',0)
rows,cols = img.shape
# 前两个参数是旋转的中心,第三个参数是角度 第四次参数是旋转后的缩放比例
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,0.5)
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
仿射变换
在仿射变换中,原始图像中的所有平行线在输出图像中仍将平行。为了找到变换矩阵,我们需要输入图像中的三个点及其在输出图像中的对应位置。然后cv.getAffineTransform将创建一个2x3矩阵,该矩阵将传递给cv.warpAffine。
import numpy as np
import cv2 as cv
img = cv.imread('6.jpg',0)
rows,cols = img.shape
#房舍变换的三个点
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
#得到矩阵
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
透视变换
对于透视变换,您需要3x3变换矩阵。即使在转换后,直线也将保持直线。要找到此变换矩阵,您需要在输入图像上有4个点,在输出图像上需要相应的点。在这四个点中,其中三个不应共线。然后可以通过函数cv.getPerspectiveTransform找到变换矩阵。然后将cv.warpPerspective应用于此3x3转换矩阵
import numpy as np
import cv2 as cv
img = cv.imread('6.jpg',0)
rows,cols = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
简单阈值
如果像素值小于阈值,则将其设置为0,否则将其设置为最大值。函数cv.threshold用于应用阈值。第一个参数是源图像,它应该是灰度图像。第二个参数是阈值,用于对像素值进行分类。第三个参数是分配给超过阈值的像素值的最大值。OpenCV提供了不同类型的阈值,这由函数的第四个参数给出。通过使用cv.THRESH_BINARY类型。
最大值: 当type指定为THRESH_BINARY或THRESH_BINARY_INV时,才需要设置该值。指的是高于(低于)阈值时赋予的新值。
不同类型的阈值: 指定阈值处理的方法,常用的有:
• cv2.THRESH_BINARY(黑白二值)
• cv2.THRESH_BINARY_INV(黑白二值反转)
• cv2.THRESH_TRUNC (截断阈值化处理)
• cv2.THRESH_TOZERO
• cv2.THRESH_TOZERO_INV
该方法返回两个输出。第一个是使用的阈值,第二个输出是阈值后的图像。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
自适应阈值
如果图像在不同区域具有不同的光照条件。在这种情况下,自适应阈值阈值化可以提供帮助。在此,算法基于像素周围的小区域确定像素的阈值。因此,对于同一图像的不同区域,我们获得了不同的阈值,这为光照度变化的图像提供了更好的结果。
除上述参数外,方法cv.adaptiveThreshold还包含三个输入参数:
该adaptiveMethod决定阈值是如何计算的:
cv.ADAPTIVE_THRESH_MEAN_C::阈值是邻近区域的平均值减去常数C。
cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的高斯加权总和减去常数C。
该BLOCKSIZE确定附近区域的大小,C是从邻域像素的平均或加权总和中减去的一个常数。
下面的代码比较了光照变化的图像的全局阈值和自适应阈值:
import cv2
import numpy as np
import matplotlib.pyplot as plt
computer = cv2.imread('2.jpg', cv2.IMREAD_GRAYSCALE)
t1, thresh_127 = cv2.threshold(computer,127 , 255, cv2.THRESH_BINARY)
adap_mean = cv2.adaptiveThreshold(computer, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 3)
adap_gaussian = cv2.adaptiveThreshold(computer, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 5, 3)
plt.subplot(141), plt.imshow(computer)
plt.subplot(142), plt.imshow(thresh_127)
plt.subplot(143), plt.imshow(adap_mean)
plt.subplot(144), plt.imshow(adap_gaussian)
plt.show()
Otsu的二值化
import cv2
import numpy as np
import matplotlib.pyplot as plt
tiffany = cv2.imread(r'6.jpg')
t1, result_127 = cv2.threshold(tiffany, 127, 255, cv2.THRESH_BINARY) #普通二值化处理
tiffany_gray = cv2.cvtColor(tiffany, cv2.COLOR_BGR2GRAY) #把3通道图像先转换为二维图像,这样才能用自动阈值搜索
t2, result_otsu = cv2.threshold(tiffany_gray, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) #Otsu阈值处理,注意Otsu阈值处理只能处理二维图像,所以三维要转换一下
result_otsu1 = cv2.cvtColor(result_otsu, cv2.COLOR_GRAY2RGB) #为了matplotlib显示得好看,就把色彩空间再转换一下
plt.subplot(131), plt.imshow(tiffany[:,:,::-1])
plt.subplot(132), plt.imshow(result_127)
plt.subplot(133), plt.imshow(result_otsu1)
plt.show()
2D卷积(图像过滤)
OpenCV提供了一个函数cv.filter2D来将内核与图像进行卷积。例如,我们将尝试对图像进行平均滤波。5x5平均滤波器内核如下所示:
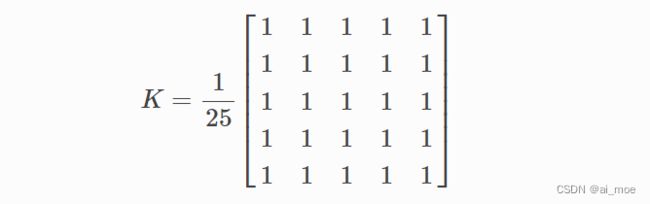
操作如下:保持这个内核在一个像素上,将所有低于这个内核的25个像素相加,取其平均值,然后用新的平均值替换中心像素。它将对图像中的所有像素继续此操作。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('6.jpg')
kernel = np.ones((5,5),np.float32)/25
dst = cv.filter2D(img,-1,kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
图像模糊(图像平滑)
通过将图像与低通滤波器内核进行卷积来实现图像模糊。这对于消除噪音很有用。它实际上从图像中消除了高频部分(例如噪声,边缘)。因此,在此操作中边缘有些模糊。(有一些模糊技术也可以不模糊边缘)。OpenCV主要提供四种类型的模糊技术。
平均
这是通过将图像与归一化框滤镜进行卷积来完成的。它仅获取内核区域下所有像素的平均值,并替换中心元素。这是通过功能 cv.blur()或cv.boxFilter() 完成的。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('2.jpg')
blur = cv.blur(img,(5,5))
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
高斯模糊
使用了高斯核。这是通过功能cv.GaussianBlur() 完成的。我们应指定内核的宽度和高度,该宽度和高度应为正数和奇数。我们还应指定X和Y方向的标准偏差,分别为sigmaX和sigmaY。如果仅指定sigmaX,则将sigmaY与sigmaX相同。如果两个都为零,则根据内核大小进行计算。高斯模糊对于从图像中去除高斯噪声非常有效。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('2.jpg')
blur = cv.GaussianBlur(img,(5,5),0)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
中位模糊
函数cv.medianBlur() 提取内核区域下所有像素的中值,并将中心元素替换为该中值。这对于消除图像中的椒盐噪声非常有效。有趣的是,在上述过滤器中,中心元素是新计算的值,该值可以是图像中的像素值或新值。但是在中值模糊中,中心元素总是被图像中的某些像素值代替。有效降低噪音。其内核大小应为正奇数整数。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('2.jpg')
blur = cv.medianBlur(img,5)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
双边滤波
cv.bilateralFilter() 在去除噪声的同时保持边缘清晰锐利非常有效。但是,与其他过滤器相比,该操作速度较慢。我们已经看到,高斯滤波器采用像素周围的邻域并找到其高斯加权平均值。高斯滤波器仅是空间的函数,也就是说,滤波时会考虑附近的像素。它不考虑像素是否具有几乎相同的强度。它不考虑像素是否是边缘像素。因此它也模糊了边缘,这是我们不想做的。
双边滤波器在空间中也采用高斯滤波器,但是又有一个高斯滤波器,它是像素差的函数。空间的高斯函数确保仅考虑附近像素的模糊,而强度差的高斯函数确保仅考虑强度与中心像素相似的那些像素的模糊。由于边缘的像素强度变化较大,因此可以保留边缘。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('2.jpg')
blur = cv.bilateralFilter(img,9,75,75)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
形态学转换
形态变换是一些基于图像形状的简单操作。通常在二进制图像上执行。它需要两个输入,一个是我们的原始图像,第二个是决定操作性质的结构元素或内核。两种基本的形态学算子是侵蚀和膨胀。然后,它的变体形式(如“打开”,“关闭”,“渐变”等)也开始起作用。

侵蚀
侵蚀的基本思想就像土壤侵蚀一样,它侵蚀前景物体的边界(尽量使前景保持白色)。它是做什么的呢?内核滑动通过图像(在2D卷积中)。原始图像中的一个像素(无论是1还是0)只有当内核下的所有像素都是1时才被认为是1,否则它就会被侵蚀(变成0)。
结果是,根据内核的大小,边界附近的所有像素都会被丢弃。因此,前景物体的厚度或大小减小,或只是图像中的白色区域减小。它有助于去除小的白色噪声,分离两个连接的对象等。
import cv2 as cv
import numpy as np
img = cv.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv.erode(img,kernel,iterations = 1)

扩张
它与侵蚀正好相反。如果内核下的至少一个像素为“ 1”,则像素元素为“ 1”。因此,它会增加图像中的白色区域或增加前景对象的大小。通常,在消除噪音的情况下,腐蚀后会膨胀。因为腐蚀会消除白噪声,但也会缩小物体。因此,我们对其进行了扩展。由于噪音消失了,它们不会回来,但是我们的目标区域增加了。在连接对象的损坏部分时也很有用。
dilation = cv.dilate(img,kernel,iterations = 1)

开运算
侵蚀然后扩张的另一个名称。,它对于消除噪音很有用。
opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel)

闭运算
先扩张然后再侵蚀。在关闭前景对象内部的小孔或对象上的小黑点时很有用。
closing = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel)

形态学梯度
这是图像扩张和侵蚀之间的区别。结果将看起来像对象的轮廓。
gradient = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel)
顶帽
它是输入图像和图像开运算之差。
tophat = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel)

黑帽
输入图像和图像闭运算之差。
blackhat = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel)

在Numpy的帮助下,我们在前面的示例中手动创建了一个结构元素。它是矩形。但是在某些情况下,您可能需要椭圆形/圆形的内核。因此,为此,OpenCV具有一个函数cv.getStructuringElement()。您只需传递内核的形状和大小,即可获得所需的内核。
# 矩形内核
>>> cv.getStructuringElement(cv.MORPH_RECT,(5,5))
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=uint8)
# 椭圆内核
>>> cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
array([[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0]], dtype=uint8)
# 十字内核
>>> cv.getStructuringElement(cv.MORPH_CROSS,(5,5))
array([[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0]], dtype=uint8)
图像梯度
在我们的最后一个示例中,输出数据类型为cv.CV_8U或np.uint8。但这有一个小问题。黑色到白色的过渡被视为正斜率(具有正值),而白色到黑色的过渡被视为负斜率(具有负值)。因此,当您将数据转换为np.uint8时,所有负斜率均设为零。简而言之,您会错过这一边缘信息。
如果要检测两个边缘,更好的选择是将输出数据类型保留为更高的形式,例如cv.CV_16S,cv.CV_64F等,取其绝对值,然后转换回cv.CV_8U。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('6.jpg',0)
laplacian = cv.Laplacian(img,cv.CV_64F)
sobelx = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
sobely = cv.Sobel(img,cv.CV_64F,0,1,ksize=5)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()
Canny边缘检测
第一个参数是我们的输入图像。第二个和第三个参数分别是我们的minVal和maxVal。第三个参数是perture_size。它是用于查找图像渐变的Sobel内核的大小。默认情况下为3。最后一个参数是L2gradient,它指定用于查找梯度幅度的方程式。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('5.jpg',0)
edges = cv.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()
图像金字塔
通常,我们过去使用的是恒定大小的图像。但是在某些情况下,我们需要使用不同分辨率的(相同)图像。例如,当在图像中搜索某些东西(例如人脸)时,我们不确定对象将以多大的尺寸显示在图像中。在这种情况下,我们将需要创建一组具有不同分辨率的相同图像,并在所有图像中搜索对象。这些具有不同分辨率的图像集称为“图像金字塔”(因为当它们堆叠在底部时,最高分辨率的图像位于顶部,最低分辨率的图像位于顶部时,看起来像金字塔)。
两种图像金字塔。1)高斯金字塔**和2)**拉普拉斯金字塔
高斯金字塔中的较高级别(低分辨率)是通过删除较低级别(较高分辨率)图像中的连续行和列而形成的。然后,较高级别的每个像素由基础级别的5个像素的贡献与高斯权重形成。通过这样做,M×N图像变成M/2×N/2图像。因此面积减少到原始面积的四分之一。它称为Octave。当我们在金字塔中越靠上时(即分辨率下降),这种模式就会继续。同样,在扩展时,每个级别的面积变为4倍。我们可以使用cv.pyrDown()和cv.pyrUp()函数找到高斯金字塔。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
iimg = cv.imread('5.jpg')
lower_reso = cv.pyrDown(iimg)
cv.imshow("a",lower_reso)
lower_reso = cv.pyrDown(lower_reso)
cv.imshow("b",lower_reso)
lower_reso = cv.pyrDown(lower_reso)
cv.imshow("c",lower_reso)
lower_reso = cv.pyrDown(lower_reso)
cv.imshow("d",lower_reso)
cv.waitKey(0)
cv.destroyAllWindows()
可以使用cv.pyrUp()函数查看图像金字塔。
higher_reso2 = cv.pyrUp(lower_reso)
拉普拉斯金字塔由高斯金字塔形成。没有专用功能。拉普拉斯金字塔图像仅像边缘图像。它的大多数元素为零。它们用于图像压缩。拉普拉斯金字塔的层由高斯金字塔的层与高斯金字塔的高层的扩展版本之间的差形成。拉普拉斯等级的三个等级如下所示(调整对比度以增强内容):

使用金字塔进行图像融合:
金字塔的一种应用是图像融合。例如,在图像拼接中,您需要将两个图像堆叠在一起,但是由于图像之间的不连续性,可能看起来不太好。在这种情况下,使用金字塔混合图像可以无缝混合,而不会在图像中保留大量数据。一个经典的例子是将两种水果,橙和苹果混合在一起。

import cv2 as cv
import numpy as np,sys
A = cv.imread('apple.jpg')
B = cv.imread('orange.jpg')
# 生成A的高斯金字塔
G = A.copy()
gpA = [G]
for i in xrange(6):
G = cv.pyrDown(G)
gpA.append(G)
# 生成B的高斯金字塔
G = B.copy()
gpB = [G]
for i in xrange(6):
G = cv.pyrDown(G)
gpB.append(G)
# 生成A的拉普拉斯金字塔
lpA = [gpA[5]]
for i in xrange(5,0,-1):
GE = cv.pyrUp(gpA[i])
L = cv.subtract(gpA[i-1],GE)
lpA.append(L)
# 生成B的拉普拉斯金字塔
lpB = [gpB[5]]
for i in xrange(5,0,-1):
GE = cv.pyrUp(gpB[i])
L = cv.subtract(gpB[i-1],GE)
lpB.append(L)
# 现在在每个级别中添加左右两半图像
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# 现在重建
ls_ = LS[0]
for i in xrange(1,6):
ls_ = cv.pyrUp(ls_)
ls_ = cv.add(ls_, LS[i])
# 图像与直接连接的每一半
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv.imwrite('Pyramid_blending2.jpg',ls_)
cv.imwrite('Direct_blending.jpg',real)