Python数据分析7——pandas时间序列
目录
datetime数据类型
datetime操作
datetime.now()
timedelta()
字符串转换为datetime
datetime转换为字符串
时间序列
前言
时间序列基础
时间序列介绍
生成时间序列函数
时间序列的索引及选择数据
含有重复索引的时间序列
移位日期
重采样
重采样介绍
将索引转换为时间序列
pd.to_datetime()
datetime数据类型
datetime操作
datetime.now()
查看当前时间

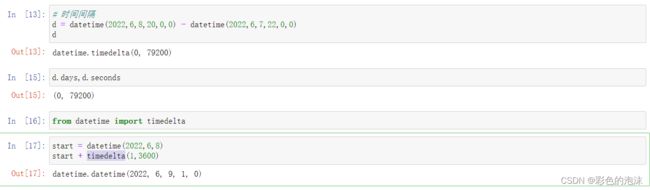
timedelta()
带时间类型数据进行运算操作
字符串转换为datetime

datetime转换为字符串

时间序列
前言
时间序列数据在很多领域都是重要的结构化数据形式,比如:金融,神经科学,生态学,物理学。在多个时间点观测的数据形成了时间序列。时间序列可以是固定频率的,也可以是不规则的。
常见使用
- 时间戳
- 固定的时间区间
- 时间间隔
时间序列基础
时间序列介绍
Pandas中的基础时间序列种类是由时间戳索引的Series,在Pandas外部通常表示为Python字符串或datetime对象。
注意
- datetime对象可作为索引,时间序列DatetimeIndex
- 时间序列里面每个元素为Timestamp对象
生成时间序列函数
- pd.date_range(start=None,end=None,periods=None,freq=None,tz=None,normalize=False)
-
- start 起始时间
- end 结束时间
- periods 固定时期
- freq 日期偏移量(频率)
- normalize 标准化为0的时间戳
d1 = pd.date_range(start="20200101",end="20200201")
d1
d2 = pd.date_range(start="20200101",end="20200201",periods=5)
d2
d3 = pd.date_range(start="20200101",periods=5,freq="10D")
d3
d4 = pd.date_range(start="2020-01-01 12:59:59",periods=5,freq="10D",normalize=True)
d4关于频率设置如下:

具体可参考:Time series / date functionality — pandas 1.4.2 documentation https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases
https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases
时间序列的索引及选择数据
ts = pd.Series(np.random.randint(1,100,size=800),index=pd.date_range("20180101",periods=800))
ts
# 选择2020的数据
ts['2020']
# 选择2020的一月份数据
ts['2020 01']
# 取2020年5月01至5月10的数据
ts['2020 05 01':'2020 05 10']含有重复索引的时间序列
- df.indexis_unique 检查索引是否唯一
移位日期
"移位"指的是将日期按时间向前移动或向后移动。Series和DataFrame都有一个shift方法用于进行简单的前向或后向移位 而不改变索引
ts.shift(2) # 向前移动
ts.shift(-2) # 向后移动重采样
重采样介绍
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
ts = pd.DataFrame(np.random.randint(100,200,size=100),index=pd.date_range(start="20200101",periods=100))
ts
ts.resample("M").mean()将索引转换为时间序列
pd.to_datetime()
我们来看以下常见场景
df = pd.DataFrame(np.random.randint(1000,4000,size=(4,4)),index=[20200101,20200102,20200103,20200104],columns=["北京","上海","广州","深圳"])
df该行索引类型并不是时间序列类型,所以我们想要使用时间序列的特性,就需要将其转为时间序列。通过 pd.to_datetime(),其中的format参数可以调试时间序列的格式,常用如下:

