Real-Time Brazilian License Plate Detection and Recognition Using Deep Convolutional Neural Networks
文章:Real-Time Brazilian License Plate Detection and Recognition Using Deep Convolutional Neural Networks
http://sergiomsilva.com/pubs/real-time-brazilian-alpr/
0 摘要
自动车牌识别(ALPR)是智能交通和监控系统中有许多应用的重要任务。与其他计算机视觉任务一样,深度学习(DL)方法最近应用于ALPR,主要针对特定国家的车牌,如美国或欧洲[1],中国[2],印度[3]和韩国[4]。但是,要么它们不是完整的DL-ALPR管道,要么它们是商业的并且使用了缺乏详细信息的私有数据集。在这项工作中,我们基于最先进的卷积神经网络架构,为巴西车牌提出了端到端DL-ALPR系统。使用巴西车牌[5]的公开数据集,系统能够在63.18%的准确率正确检测和识别测试集中的所有七个字符,如果仅考虑至少五个字符时能够正确地识别时(部分匹配),则准确率高达97.39%。考虑对每个字符的单独分割和识别,我们能够分割99%的字符,并正确识别其中的93%。
1 核心思想
传统的ALPR管道通常涉及汽车检测。虽然它可能是某些方法的可选任务,但它在我们的方法中至关重要:数据集中的所有图像都具有高分辨率(1920×1080像素)并且汽车在场景中占用比例不大(它们可能离相机较远)。此外,LP的平均尺寸是整个图像区域的0.26%。因此,在高分辨率图像中对这种小尺寸的目标进行分析所需的计算资源相当高。
由于DL本身计算成本比较高,当我们开发实时应用时,往往应该忽视小目标。对图像进行整体缩放不是一个好的解决方案,因为这样可能会造成车牌变得太小而无法检测到。考虑到可用数据库不提供带标注的汽车标签或边界框这一事实,仅使用其训练信息检测汽车是一项具有挑战性的任务。
我们提出了一种仅基于带标注的LP提取汽车前部的简单方法。基本上,假设LP始终连接到汽车(并且大致水平对齐),我们决定使用它周围的区域来训练检测网络,如第III-A节所述。
我们最关心的问题之一是实现实时的ALPR系统,而无需昂贵的硬件。因此,我们需要使用能够在很短的时间内执行检测和识别的深度网络。为了实现这些目标,我们选择使用基于YOLO的网络[16]。据我们所知,这些是文献中报道的最快的网络 - 甚至比使用区域提议而不需要(高计算量的)图像金字塔和滑动窗口执行对象检测/识别的Faster R-CNN [15]更快。
在我们的测试中,FAST-YOLO网络能够以小于5.5ms或大约180帧/秒(FPS)的速度在800×600图像中执行20类的检测和分类。在VOC [23]数据集中,该网络报告的精确度为57.1%,与其他更深层网络(如YOLO(76.8%)和FasterRCNN(76.4%)相比,这个准确度并不高。但是,YOLO的参数比FAST-YOLO多3倍,这使得它在训练过程中耗时更长且对数据的需求量更大。
我们的目的是解决两类目标(汽车正面视图和车牌)的检测问题而不是二十个,我们认为基于Fast-Yolo网络进行改进已经足够了。具体的网络结构和训练过程如第III-B部分所示。
为了检测和识别字符,我们构建了一个受YOLO架构启发的新网络,基本技术差异可容纳35个类别(0-9,A-Z除了字母O,O与数字0共同检测)并输出具有相同长宽比(宽度是高度的三倍)的LP的特征图。有关详细信息,请参阅第III-C节。
最后,我们执行后处理步骤,以便将高度混乱的字母交换为数字数字或数字交换为字母,因为巴西牌照由正好三个字母后跟四个数字组成。
A:正面视角提取
DL技术的一个问题是它们难以检测小物体[24],这确实发生在我们的实验中。我们训练了一个FAST-YOLO网络只检测LP,结果是82%的召回率(CR后趋于进一步降低)。
YOLO和FAST-YOLO网络具有固定的输入图像尺寸,在两种情况下都定义为416×416。由于在SSIG数据库中所有图像都具有1920×1080像素,因此需要进行图像缩小。当汽车距离摄像机足够远时,该步骤将LP尺寸减小到不可检测的程度。
为了克服这个问题,我们通过缩放和平移带标注的LP边界框来提取LP周围的较大区域,即汽车正面视图(FV)。使用以下过程估算此空间转换的参数:
-
从训练数据集中随机选择一组 N l p N_{lp} Nlp个图像,不包括公共汽车和卡车的图像,因为它们的正向视图太大;
-
用牌照周围的矩形边界框手动标记这些图像,其中每个边界框具有可能包括汽车前灯和轮胎的最小区域(参见图2中的黄色虚线矩形);
-
考虑四维向量 p ⃗ \vec{p} p,其包含标注车牌LP的左上角点 ( p x , p y ) (p_x,p_y) (px,py),宽度 p w p_w pw和高度 p h p_h ph。我们希望找到两个平移参数 ( α x , α y ) (\alpha_x,\alpha_y) (αx,αy),以及两个缩放参数 α w \alpha_w αw和 α h \alpha_h αh,它们将LP边界框 p ⃗ \vec{p} p与FV边界框 v ⃗ \vec{v} v相关联。变换过程表示为:
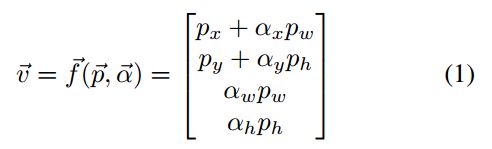
上式中,向量 α ⃗ \vec{\alpha} α包括了缩放和平移参数。 -
为了求解向量 α ⃗ \vec{\alpha} α,我们最大化 N l p N_{lp} Nlp幅标记图像的IOU之和:

-
利用估计的参数 α ∗ ⃗ \vec{\alpha_*} α∗,自动标记数据集中所有剩余图像的FV边界框,生成弱但大的标注集。弱标记过程的一个例子如图2所示。
 尽管在训练中丢弃了公共汽车和卡车图像以估计转换参数,但使用该标签的网络仍然能够检测这些类型的车辆。
尽管在训练中丢弃了公共汽车和卡车图像以估计转换参数,但使用该标签的网络仍然能够检测这些类型的车辆。
相关方法可以在[25],[26]中找到,其中车牌区域用于估计汽车正面视图以识别其模型/制造商。
B:使用CNN进行车辆正面和车牌检测
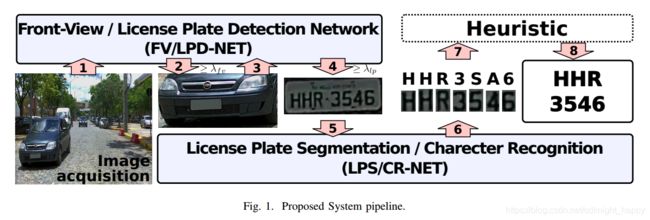
在这项工作中,使用以级联方式排列的单个分类器检测汽车FV及其LP(参见图1):第一层(箭头1和2)从输入图像检测FV。第二层(箭头3和4)从检测到的FV图像中提取LP。
为了在准确率和运行时间之间实现良好的折衷,我们的分类器基于FAST-YOLO网络架构。该网络是为了处理20种不同类别的对象而构建(和训练)的,并在一个好的GPU上以200 FPS运行。因此,我们假设为2个类定制的FAST-YOLO网络以级联方式执行时能够在单个网络中容纳两个任务。
使用的FAST-YOLO架构如表I所示。原始的唯一修改是在第15层进行的,我们将滤波器的数量从125减少到35,以便输出2个类而不是20个(请参考[16]]有关检测层的更多信息)。
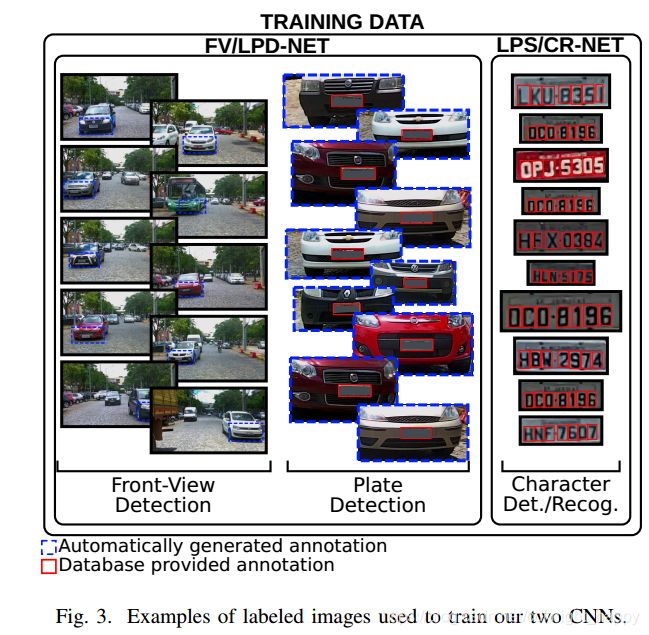
训练:首先,从预训练网络迁移第1层到第14层的权重。然后,我们通过添加带注释的FV和LP图像的样本来微调权重。更准确地说,训练数据是两个子集的组合:(i)使用仅有注释的FV的全分辨率图像(1920×1080),通过第III-A节中描述的弱标记过程获得;(ii)仅描绘FV的裁剪区域,以及SSIG数据库中提供的各自注释的LP。用于训练所提出的FV / LPD-NET的输入图像的示例在图3中示出。我们没有混合验证、训练和测试集来创建集合(ii)。
车牌检测:我们运行相同的网络两次,或者对于级联中的前两个层中的每一个运行一个网络。
过程如下:
- 第一遍涉及整个图像,仅查看FV。发现的任何LP都被丢弃;
- 然后,将检测到的FV裁剪并馈送到同一网络,并且仅使用与LP相关的输出。如果找到多个LP,则仅保留具有最高概率的LP,因为预期每个车辆呈现单个LP。
请注意,如果场景中有N个牌照,则预计网络将运行N + 1次:一个用于检测N个FV,N用于检测LP(每个FV一个)。但是,在几个ALPR应用中,例如停车或收费监控,一次只有一辆车。
C:字符检测和识别
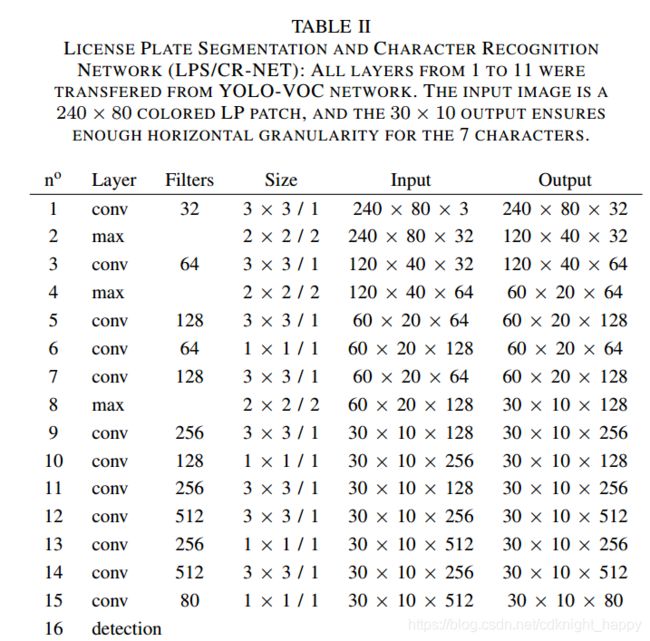
巴西的国家交通委员会(CONTRAN)规定了全国范围内的LP格式。他们的规格很少有例外(例如总统和领事车)不遵循7字符格式。绝大多数LP具有共同的特征:统一的背景颜色,固定的字体大小和LP尺寸,7个字符分为两组:第一组3个字母和第二组4个数字,如图4所示。这对于模式识别来说是很好的特性,因为它比其他国家的牌照具有更小的可变性,使得字符检测和识别问题稍微容易一些。但是,罗马数字和字母在许多字符之间有一些相似之处,例如,由于一些扭曲或遮挡,O / Q,0 / D,1 / I,5 / S,2 / Z,B / 8,C / G,A / 4,常常会混淆[21]。在文本的OCR应用程序中,许多这些混淆可以通过使用邻接信息和语义分析来修复,假设检测到的字符形成了有效的单词。这对于LPR来说更难,因为语义信息是不存在的。

YOLO和FAST-YOLO网络具有固定的输入和输出宽高比和粒度。它们的纵横比为1:1,但它们在纵向和横向图像上都表现出良好的检测性能,如[16]所示。然而,正如我们的测试所示,巴西LP的纵横比约为3:1,对于这些网络来说太宽了。因此,我们更改了网络参数以匹配LP的宽高比。
另一个区别与网络输入和输出粒度有关。我们注意到13×13的YOLO输出密度不足以捕获水平并排的七个大物体(字符)。为了修正这个问题,我们几乎将水平粒度三倍化,让最终的网络输出为30×10。垂直尺寸输出的这种轻微下降不会影响网络性能,因为LP没有要检测的垂直对象序列。
对于输入,我们选择使用240×80图像,这大约是数据库平均车牌尺寸的两倍,并减少丢失重要信息的机会。仅供记录,我们还尝试了不同的输入和输出尺寸,例如144×48 → \rightarrow → 18×6,192×64 → \rightarrow → 24×8和288×96 → \rightarrow → 36×12。前2个网络的表现比选择的差,后者表现与选择的尺寸表现相同,但更复杂。
使用比原始提案更小的输入(240×80对416×416)需要对架构进行一些修改。首先,我们需要将最大池层数从5减少到3,以便通过避免太多维度降低来保持精细输出粒度。其次,为了保持网络深度等于FAST-YOLO并且允许尽可能多地使用迁移学习,我们使用了前十一层YOLO网络,停在第十二层,因为它包含了第四个最大池化层。如果我们对FAST-YOLO同样在第四个最大池化层之前终止,我们最终只会使用七层,从而减少网络深度。最后,增加了四个从头训练的层以改善非线性。
表II中提供了所提出的网络的最终架构。训练程序类似于第III-B节中介绍的FV / LPD-NET,一些训练样本显示在图3的右侧。
D:启发式后处理
基于巴西LP由三个字母后跟四个数字组成的事实,我们使用两个启发式规则来过滤LPS / CR-NET产生的结果:
- 如果检测到超过七个字符,则仅保留七个最可能的字符。
- 假设前三个字符是字母,后面是四个数字。
此假设用于按数字交换字母,反之亦然,具体取决于字符位置。
总之,如果在与数字相关的LP块中识别出字母,则将其与在训练数据获得的混淆矩阵中出现可能性最大的数字交换。如果数字出现在了车牌的字母块中,按相同的方式进行处理。
特定的交换有:
前3个位置(字母)的交换规则:5 → \rightarrow →S,7 → \rightarrow →Z,1 → \rightarrow →I,8 → \rightarrow →B,2 → \rightarrow →Z,4 → \rightarrow →A和6 → \rightarrow →G;
最后4个位置(数字)的交换规则:Q → \rightarrow → 0,D → \rightarrow → 0,Z → \rightarrow → 7,S → \rightarrow → 5,J → \rightarrow → 1,I → \rightarrow → 1,A → \rightarrow → 4和B → \rightarrow → 8。
最后一个启发式算法仅在网络输出正好七个字符时应用。否则,LP无论如何都是错误的,通过交换正确识别的字符,可能会使识别结果更差。
2 实验结果