ZooKeeper 应用场景?
ZooKeeper企业级最佳应用实战
文章目录
- 一、ZooKeeper 应用场景?
- 二、发布订阅
- 三、集群管理
- 四、分布式锁
- 五、队列管理
- 六、 分布式选举
一、ZooKeeper 应用场景?
ZooKeeper:分布式协调服务,劝架者,仲裁机构。基于它提供的两大核心功能:可以实现分布式场景中的各种疑难杂症!比如最经典的分布式锁的问题。
1、发布/订阅
2、命名服务
3、配置管理
4、集群管理
5、分布式锁
6、队列管理
7、负载均衡
经典的用法:尽量少往 ZooKeeper 中写数据,写入的数据也不要特别大!ZooKeeper 只适合用来存储少量的关键数据!比如代表一个集群中到底谁是真正 active leader 的信息数据。为什么不适合写入大量数据的原因:
- 1、因为 ZooKeeper 系统内部每个节点都会做数据同步,在执行写请求的时候,事实上就是原子广播。待写入数据越大,原子广播的效率就越低,成功难度也越大。
- 2、所有的请求,都是严格的顺序串行执行, 这个 ZooKeeper 集群在某一个时刻只能执行一个事务,如果上一个事务执行耗时,则会阻塞后面的请求的执行。
- 3、正因为每个节点都会存储一份完整的 ZooKeeper 系统数据,所以如果系统数据过大,甚至超过了单个 Follower 的存储能力了,系统服务大受影响甚至崩溃。
- 4、ZooKeeper 的设计初衷,就不是为了给用户提供一个大规模数据存储服务,而是提供了一个为了解决一些分布式问题而需要进行一些状态存储的数据模型系统。
二、发布订阅
应用服务器集群可能存在两个问题:
- 1、因为集群中有很多机器,当某个通用的配置发生变化后,怎么自动让所有服务器的配置同时生效?配置管理的问题。
- 2、当集群中某个节点宕机,如何让集群中的其他节点感知?集群管理的问题
为了解决这两个问题,ZooKeeper 引入了 Watcher 机制来实现发布/订阅功能,能够让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态发生变化时,会通知所有订阅者。
- 1、订阅者:在 zookeeper 这种架构实现中,其实就是 注册监听的客户端
- 2、发布者:在 zookepeer 这种架构实现中,其实就是 触发事件发生的客户端
数据发布/订阅即所谓的配置中心:发布者将数据发布到 ZooKeeper 的一个或一些列节点上,订阅者进行数据订阅,可以即时得到数据的变化通知。
消息/数据的发送有2种设计模式,推Push & 拉Pull。A 有一条消息,要让 B 知道:要么 A 主动告诉 B,要么 B 不断的来询问有没有新的消息,如果有,B 就能拿到。在推模中,服务端将所有数据更新发给订阅的客户端,而拉是由客户端主动发起请求获取最新数据。通常采用轮寻。比如 MapReduce 中的MapTask 和 ReduceTask 之间的数据传输,采用的就是拉取的方式,大家可以思考一下,这是为什么?
ZooKeeper 采用推拉结合,客户端向服务端注册自己需要关注的节点的事件,一旦该节点数据发生该事件,服务器向客户端发送事件 Watcher 通知,客户端收到消息主动从服务端获取最新数据。这种模式主要用于配置信息获取同步。
三、集群管理
所谓集群管理无在乎两点:是否有机器退出和加入(从节点 管理)、选举 master(主节点 管理)。首先看问题:
- HDFS 中的 DataNode 如果死掉了,那么 NameNode 需要经过至少 630s 的默认时间,才会认为这个节点死掉!
- HBase 中的 HRegionServer 如果死掉了,那么 HMaster 需要经过差不多 1s 的默认时间,才会认为这个节点死掉!
对于第一点,所有机器约定在父目录 GroupMembers 下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与ZooKeeper 的连接断开,其所创建的代表该节点存活状态的临时目录节点被删除,所有其他机器都将收到通知:某个兄弟目录被删除,于是,所有人都知道:有兄弟节点挂掉了。新机器加入也是类似,所有机器收到通知:新兄弟目录加入,又多了个新兄弟节点。
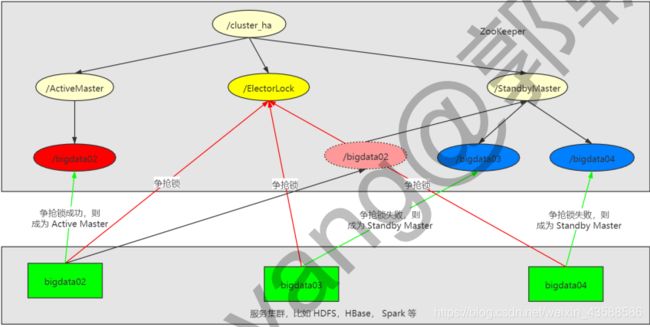
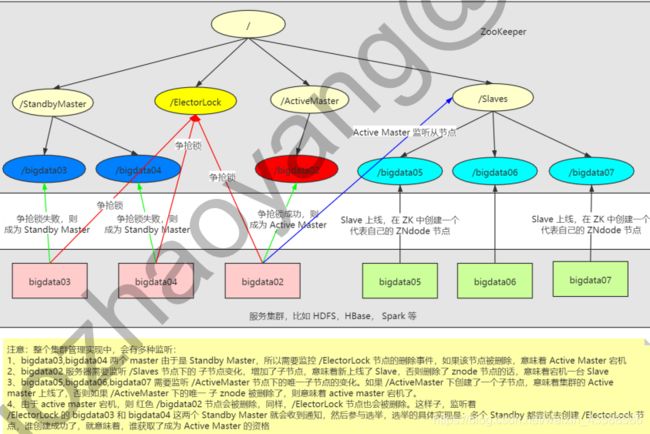
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为 master 就好。当然,这只是其中的一种策略而已,选举策略完全可以由管理员自己制定。在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络 I/O 处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能。
利用 ZooKeeper 的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很轻易的在分布式环境中进行集群选取了。(其实只要实现数据唯一性就可以做到选举,关系型数据库也可以,但是性能不好,设计也复杂)
利用 ZooKeeper 实现 集群管理:包括集群从节点上下线即时感知管理,和 集群主节点选举管理
四、分布式锁
锁:并发编程中保证线程安全(一个 JVM 内部的多个线程的并发执行的安全)的一种机制:针对临界资源直接进行加锁的操作。 谁来操作,都需要先拿到钥匙!拿到操作许可!这个操作许可同时只能一个线程拿到。
分布式锁:分布式环境中,如果多个进程想要访问临界资源,则也需要进行加锁,但是比起单进程中的多线程加锁机制,分布式锁,还要考虑到网络通信的问题。为什么分布式环境中,各种问题会变得复杂,最大的原因,就是网络的不可靠:消息丢失 和 消息延迟。
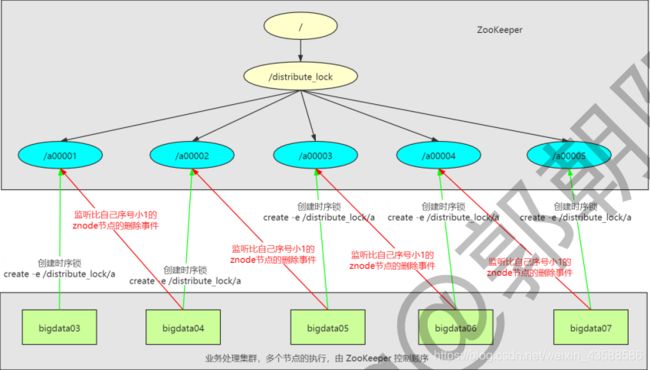
锁服务可以分为两三类: 独占锁,共享锁,时序锁
- 1、独占锁/写锁:对写加锁,保持独占,或者叫做排它锁,独占锁
- 2、共享锁/读锁:对读加锁,可共享访问,释放锁之后才可进行事务操作,也叫共享锁
- 3、时序锁:控制时序
对于第一类(独占锁),我们将 ZooKeeper 上的一个 znode 看作是一把锁,通过 createznode() 的方式来实现。所有客户端都去创建 /distribute_lock节点,最终成功创建的那个客户端代表拥有了这把锁。用完删除掉自己创建的 /distribute_lock 节点就释放出锁。
对于第二类(读写锁),我们在 ZooKeeper 上生成两个 znode,分别是:/lock_read 和 /lock_write,如果有一个客户端过来读取数据,则先判断/lock_write 是否存在,如果不存在,则可以进行读取操作,同时创建一个 /lock_read 下的子节点代表读锁,读取完毕删除掉。如果有一个客户端过来写
数据,则先判断 /lock_write 是否存在,再判断 /lock_read 下是否有读锁,如果都没有,则可以进行写操作。
对于第三类(时序锁),/distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录子节点,和选 Master 一样,编号最小的获得锁,用完删除,依次有序
五、队列管理
两种类型的队列:
- 1、同步队列/分布式屏障/分布式栅栏:当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
- 2、先进先出队列:队列按照 FIFO 方式进行入队和出队操作。和分布式时序锁一样。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。

六、 分布式选举
该分布式选举,所采用的是 分布式锁 的思路来实现的。整体架构思路: