深度学习必备:随机梯度下降(SGD)优化算法及可视化
原文链接
https://ruder.io/optimizing-gradient-descent/
中文翻译连接
https://blog.csdn.net/google19890102/article/details/69942970
可视化源代码
http://louistiao.me/notes/visualizing-and-animating-optimization-algorithms-with-matplotlib/
【新智元导读】梯度下降算法是机器学习中使用非常广泛的优化算法,也是众多机器学习算法中最常用的优化方法。几乎当前每一个先进的(state-of-the-art)机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现。但是,它们就像一个黑盒优化器,很难得到它们优缺点的实际解释。这篇文章旨在提供梯度下降算法中的不同变种的介绍,帮助使用者根据具体需要进行使用。
这篇文章首先介绍梯度下降算法的三种框架,然后介绍它们所存在的问题与挑战,接着介绍一些如何进行改进来解决这些问题,随后,介绍如何在并行环境中或者分布式环境中使用梯度下降算法。最后,指出一些有利于梯度下降的策略。
目录
三种梯度下降优化框架
批量梯度下降
随机梯度下降
小批量梯度下降
问题与挑战
梯度下降优化算法
Momentum
Nesterov accelerated gradient
Adagrad
Adadelta
RMSprop
Adam
算法的可视化
选择哪种优化算法?
并行与分布式SDG
Hogwild!
Downpour SGD
Delay-tolerant Algorithms for SGD
TensorFlow
Elastic Averaging SGD
更多的SDG优化策略
训练集随机洗牌与课程学习
批规范化
Early Stopping
Gradient noise
总结
引用
三种梯度下降优化框架
梯度下降算法是通过沿着目标函数J(θ)参数θ∈R的梯度(一阶导数)相反方向−∇θJ(θ)来不断更新模型参数来到达目标函数的极小值点(收敛),更新步长为η。
有三种梯度下降算法框架,它们不同之处在于每次学习(更新模型参数)使用的样本个数,每次更新使用不同的样本会导致每次学习的准确性和学习时间不同。
批量梯度下降(Batch gradient descent)
每次使用全量的训练集样本来更新模型参数,即: θ=θ−η⋅∇θJ(θ)
其代码如下:

epochs 是用户输入的最大迭代次数。通过上诉代码可以看出,每次使用全部训练集样本计算损失函数 loss_function 的梯度 params_grad,然后使用学习速率 learning_rate 朝着梯度相反方向去更新模型的每个参数params。一般各现有的一些机器学习库都提供了梯度计算api。如果想自己亲手写代码计算,那么需要在程序调试过程中验证梯度计算是否正确。
批量梯度下降每次学习都使用整个训练集,因此其优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点),但是其缺点在于每次学习时间过长,并且如果训练集很大以至于需要消耗大量的内存,并且全量梯度下降不能进行在线模型参数更新。
随机梯度下降(Stochastic gradient descent)
随机梯度下降算法每次从训练集中随机选择一个样本来进行学习,即: θ=θ−η⋅∇θJ(θ;xi;yi)
批量梯度下降算法每次都会使用全部训练样本,因此这些计算是冗余的,因为每次都使用完全相同的样本集。而随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
其代码如下:

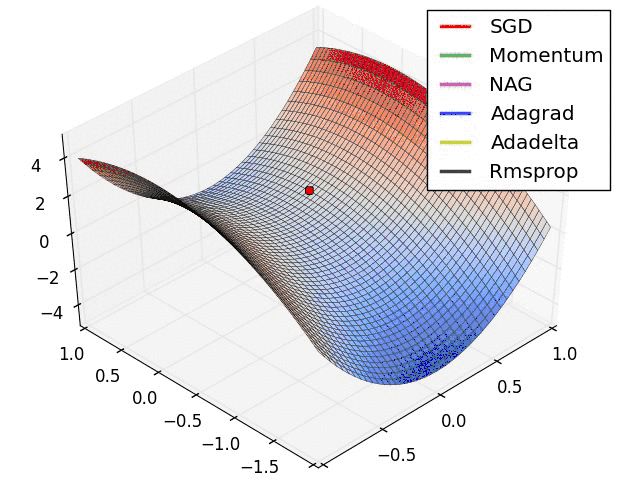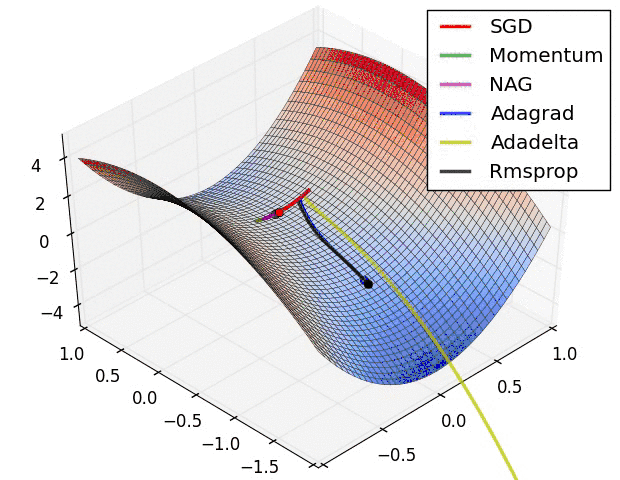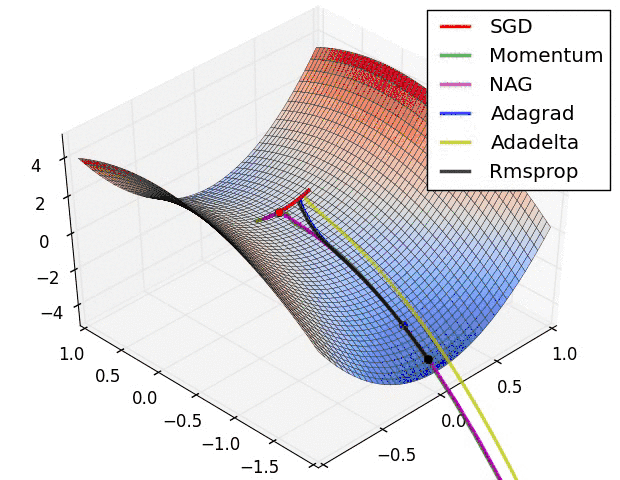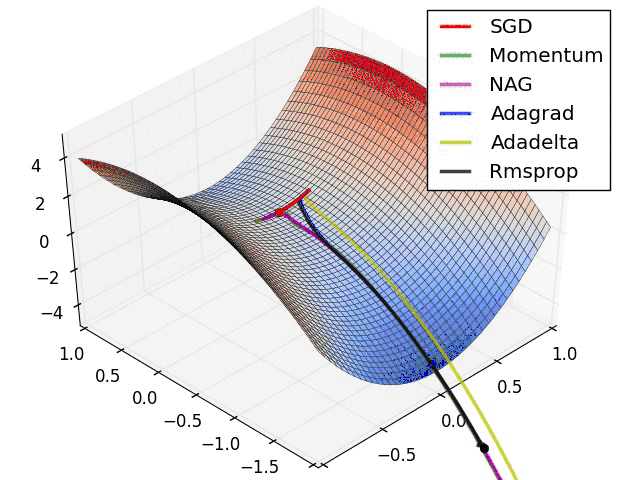
随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动),如下图:
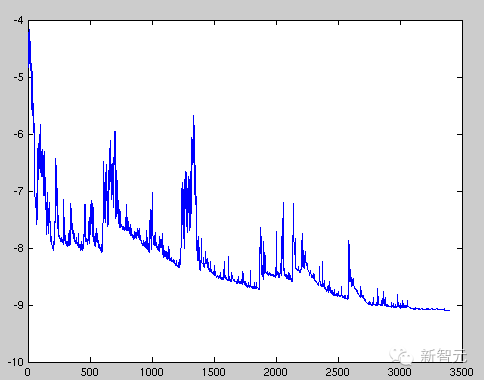
图1 SGD扰动
不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
由于波动,因此会使得迭代次数(学习次数)增多,即收敛速度变慢。不过最终其会和全量梯度下降算法一样,具有相同的收敛性,即凸函数收敛于全局极值点,非凸损失函数收敛于局部极值点。
小批量梯度下降(Mini-batch gradient descent)
Mini-batch 梯度下降综合了 batch 梯度下降与 stochastic 梯度下降,在每次更新速度与更新次数中间取得一个平衡,其每次更新从训练集中随机选择 m,m θ=θ−η⋅∇θJ(θ;xi:i+m;yi:i+m) 其代码如下: 相对于随机梯度下降,Mini-batch梯度下降降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定。相对于全量梯度下降,其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。一般而言每次更新随机选择[50,256]个样本进行学习,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个更新速度与更次次数都较适合的样本数。mini-batch梯度下降可以保证收敛性,常用于神经网络中。 问题与挑战 虽然梯度下降算法效果很好,并且广泛使用,但同时其也存在一些挑战与问题需要解决: 选择一个合理的学习速率很难。如果学习速率过小,则会导致收敛速度很慢。如果学习速率过大,那么其会阻碍收敛,即在极值点附近会振荡。 学习速率调整(又称学习速率调度,Learning rate schedules)[11]试图在每次更新过程中,改变学习速率,如退火。一般使用某种事先设定的策略或者在每次迭代中衰减一个较小的阈值。无论哪种调整方法,都需要事先进行固定设置,这边便无法自适应每次学习的数据集特点[10]。 模型所有的参数每次更新都是使用相同的学习速率。如果数据特征是稀疏的或者每个特征有着不同的取值统计特征与空间,那么便不能在每次更新中每个参数使用相同的学习速率,那些很少出现的特征应该使用一个相对较大的学习速率。 对于非凸目标函数,容易陷入那些次优的局部极值点中,如在神经网路中。那么如何避免呢。Dauphin[19]指出更严重的问题不是局部极值点,而是鞍点。 梯度下降优化算法 下面将讨论一些在深度学习社区中经常使用用来解决上诉问题的一些梯度优化方法,不过并不包括在高维数据中不可行的算法,如牛顿法。 Momentum 如果在峡谷地区(某些方向较另一些方向上陡峭得多,常见于局部极值点)[1],SGD会在这些地方附近振荡,从而导致收敛速度慢。这种情况下,动量(Momentum)便可以解决[2]。 动量在参数更新项中加上一次更新量(即动量项),即: νt=γνt−1+η ∇θJ(θ),θ=θ−νt 其中动量项超参数γ<1一般是小于等于0.9。 其作用如下图所示: 图2 没有动量 图3 加上动量 加上动量项就像从山顶滚下一个球,求往下滚的时候累积了前面的动量(动量不断增加),因此速度变得越来越快,直到到达终点。同理,在更新模型参数时,对于那些当前的梯度方向与上一次梯度方向相同的参数,那么进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的参数,那么进行削减,即这些方向上减慢了。因此可以获得更快的收敛速度与减少振荡。 Nesterov accelerated gradient(NAG) 从山顶往下滚的球会盲目地选择斜坡。更好的方式应该是在遇到倾斜向上之前应该减慢速度。 Nesterov accelerated gradient(NAG,涅斯捷罗夫梯度加速)不仅增加了动量项,并且在计算参数的梯度时,在损失函数中减去了动量项,即计算∇θJ(θ−γνt−1),这种方式预估了下一次参数所在的位置。即: νt=γνt−1+η⋅∇θJ(θ−γνt−1),θ=θ−νt 如下图所示: 图4 NAG更新 详细介绍可以参见Ilya Sutskever的PhD论文[9]。假设动量因子参数γ=0.9,首先计算当前梯度项,如上图小蓝色向量,然后加上动量项,这样便得到了大的跳跃,如上图大蓝色的向量。这便是只包含动量项的更新。而NAG首先来一个大的跳跃(动量项),然后加上一个小的使用了动量计算的当前梯度(上图红色向量)进行修正得到上图绿色的向量。这样可以阻止过快更新来提高响应性,如在RNNs中[8]。 通过上面的两种方法,可以做到每次学习过程中能够根据损失函数的斜率做到自适应更新来加速SGD的收敛。下一步便需要对每个参数根据参数的重要性进行各自自适应更新。 Adagrad Adagrad[3]也是一种基于梯度的优化算法,它能够对每个参数自适应不同的学习速率,对稀疏特征,得到大的学习更新,对非稀疏特征,得到较小的学习更新,因此该优化算法适合处理稀疏特征数据。Dean等[4]发现Adagrad能够很好的提高SGD的鲁棒性,google便用起来训练大规模神经网络(看片识猫:recognize cats in Youtube videos)。Pennington等[5]在GloVe中便使用Adagrad来训练得到词向量(Word Embeddings), 频繁出现的单词赋予较小的更新,不经常出现的单词则赋予较大的更新。 Adagrad主要优势在于它能够为每个参数自适应不同的学习速率,而一般的人工都是设定为0.01。同时其缺点在于需要计算参数梯度序列平方和,并且学习速率趋势是不断衰减最终达到一个非常小的值。下文中的Adadelta便是用来解决该问题的。 Adam Adaptive Moment Estimation (Adam) 也是一种不同参数自适应不同学习速率方法,与Adadelta与RMSprop区别在于,它计算历史梯度衰减方式不同,不使用历史平方衰减,其衰减方式类似动量,如下: mt=β1mt−1+(1−β1)gt vt=β2vt−1+(1−beta2)g2t mt与vt分别是梯度的带权平均和带权有偏方差,初始为0向量,Adam的作者发现他们倾向于0向量(接近于0向量),特别是在衰减因子(衰减率)β1,β2接近于1时。为了改进这个问题, 对mt与vt进行偏差修正(bias-corrected): mt^=mt1−betat1 vt^=vt1−betat2 最终,Adam的更新方程为: θt+1=θt−ηvt^−−√+ϵmt^ 论文中建议默认值:β1=0.9,β2=0.999,ϵ=10−8。论文中将Adam与其它的几个自适应学习速率进行了比较,效果均要好。 算法的可视化 下面两幅图可视化形象地比较上述各优化方法,如图: 图5 SGD各优化方法在损失曲面上的表现 从上图可以看出, Adagrad、Adadelta与RMSprop在损失曲面上能够立即转移到正确的移动方向上达到快速的收敛。而Momentum 与NAG会导致偏离(off-track)。同时NAG能够在偏离之后快速修正其路线,因为其根据梯度修正来提高响应性。 图6 SGD各优化方法在损失曲面鞍点处上的表现 从上图可以看出,在鞍点(saddle points)处(即某些维度上梯度为零,某些维度上梯度不为零),SGD、Momentum与NAG一直在鞍点梯度为零的方向上振荡,很难打破鞍点位置的对称性;Adagrad、RMSprop与Adadelta能够很快地向梯度不为零的方向上转移。 从上面两幅图可以看出,自适应学习速率方法(Adagrad、Adadelta、RMSprop与Adam)在这些场景下具有更好的收敛速度与收敛性。 如何选择SGD优化器 如果你的数据特征是稀疏的,那么你最好使用自适应学习速率SGD优化方法(Adagrad、Adadelta、RMSprop与Adam),因为你不需要在迭代过程中对学习速率进行人工调整。 RMSprop是Adagrad的一种扩展,与Adadelta类似,但是改进版的Adadelta使用RMS去自动更新学习速率,并且不需要设置初始学习速率。而Adam是在RMSprop基础上使用动量与偏差修正。RMSprop、Adadelta与Adam在类似的情形下的表现差不多。Kingma[15]指出收益于偏差修正,Adam略优于RMSprop,因为其在接近收敛时梯度变得更加稀疏。因此,Adam可能是目前最好的SGD优化方法。 有趣的是,最近很多论文都是使用原始的SGD梯度下降算法,并且使用简单的学习速率退火调整(无动量项)。现有的已经表明:SGD能够收敛于最小值点,但是相对于其他的SGD,它可能花费的时间更长,并且依赖于鲁棒的初始值以及学习速率退火调整策略,并且容易陷入局部极小值点,甚至鞍点。因此,如果你在意收敛速度或者训练一个深度或者复杂的网络,你应该选择一个自适应学习速率的SGD优化方法。 并行与分布式SGD 如果你处理的数据集非常大,并且有机器集群可以利用,那么并行或分布式SGD是一个非常好的选择,因为可以大大地提高速度。SGD算法的本质决定其是串行的(step-by-step)。因此如何进行异步处理便是一个问题。虽然串行能够保证收敛,但是如果训练集大,速度便是一个瓶颈。如果进行异步更新,那么可能会导致不收敛。下面将讨论如何进行并行或分布式SGD,并行一般是指在同一机器上进行多核并行,分布式是指集群处理。 Hogwild Niu[23]提出了被称为Hogwild的并行SGD方法。该方法在多个CPU时间进行并行。处理器通过共享内存来访问参数,并且这些参数不进行加锁。它为每一个cpu分配不重叠的一部分参数(分配互斥),每个cpu只更新其负责的参数。该方法只适合处理数据特征是稀疏的。该方法几乎可以达到一个最优的收敛速度,因为cpu之间不会进行相同信息重写。 Downpour SGD Downpour SGD是Dean[4]提出的在DistBelief(Google TensorFlow的前身)使用的SGD的一个异步变种。它在训练子集上训练同时多个模型副本。这些副本将各自的更新发送到参数服务器(PS,parameter server),每个参数服务器只更新互斥的一部分参数,副本之间不会进行通信。因此可能会导致参数发散而不利于收敛。 Delay-tolerant Algorithms for SGD McMahan与Streeter[12]扩展AdaGrad,通过开发延迟容忍算法(delay-tolerant algorithms),该算法不仅自适应过去梯度,并且会更新延迟。该方法已经在实践中表明是有效的。 TensorFlow TensorFlow[13]是Google开源的一个大规模机器学习库,它的前身是DistBelief。它已经在大量移动设备上或者大规模分布式集群中使用了,已经经过了实践检验。其分布式实现是基于图计算,它将图分割成多个子图,每个计算实体作为图中的一个计算节点,他们通过Rend/Receive来进行通信。 Elastic Averaging SGD Zhang等[14]提出Elastic Averaging SGD(EASGD),它通过一个elastic force(存储参数的参数服务器中心)来连接每个work来进行参数异步更新。 更多的SGD优化策略 接下来介绍更多的SGD优化策略来进一步提高SGD的性能。另外还有众多其它的优化策略,可以参见[22]。 Shuffling and Curriculum Learning 为了使得学习过程更加无偏,应该在每次迭代中随机打乱训练集中的样本。 另一方面,在很多情况下,我们是逐步解决问题的,而将训练集按照某个有意义的顺序排列会提高模型的性能和SGD的收敛性,如何将训练集建立一个有意义的排列被称为Curriculum Learning[16]。 Zaremba与Sutskever[17]在使用Curriculum Learning来训练LSTMs以解决一些简单的问题中,表明一个相结合的策略或者混合策略比对训练集按照按照训练难度进行递增排序要好。 Batch normalization 为了方便训练,我们通常会对参数按照0均值1方差进行初始化,随着不断训练,参数得到不同程度的更新,这样这些参数会失去0均值1方差的分布属性,这样会降低训练速度和放大参数变化随着网络结构的加深。 Batch normalization[18]在每次mini-batch反向传播之后重新对参数进行0均值1方差标准化。这样可以使用更大的学习速率,以及花费更少的精力在参数初始化点上。Batch normalization充当着正则化、减少甚至消除掉Dropout的必要性。 Early stopping 在验证集上如果连续的多次迭代过程中损失函数不再显著地降低,那么应该提前结束训练,详细参见NIPS 2015 Tutorial slides,或者参见防止过拟合的一些方法。 Gradient noise Gradient noise[21]即在每次迭代计算梯度中加上一个高斯分布N(0,σ2t)的随机误差,即 gt,i=gt,i+N(0,σ2t) 高斯误差的方差需要进行退火: σ2t=η(1+t)γ 对梯度增加随机误差会增加模型的鲁棒性,即使初始参数值选择地不好,并适合对特别深层次的负责的网络进行训练。其原因在于增加随机噪声会有更多的可能性跳过局部极值点并去寻找一个更好的局部极值点,这种可能性在深层次的网络中更常见。 总结 在这篇博客文章中,我们初步研究了梯度下降的三个变形形式,其中,小批量梯度下降是最受欢迎的。 然后我们研究了最常用于优化SGD的算法:动量法,Nesterov加速梯度,Adagrad,Adadelta,RMSprop,Adam以及不同的优化异步SGD的算法。 最后,我们已经考虑其他一些改善SGD的策略,如洗牌和课程学习,批量归一化和early stopping。 原文链接 参考文献 可视化源代码及说明: %matplotlib inline from mpl_toolkits.mplot3d import Axes3D from autograd import elementwise_grad, value_and_grad The Wikipedia article on Test functions for optimization has a few functions that are useful for evaluating optimization algorithms. In particular, we shall look at Beale’s function: f(x,y)=(1.5−x+xy)2+(2.25−x+xy2)2+(2.625−x+xy3)2 ax.plot_surface(x, y, z, norm=LogNorm(), rstride=1, cstride=1, ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) plt.show() 2D Contour Plot and Gradient Vector Field dz_dx = elementwise_grad(f, argnum=0)(x, y) ax.contour(x, y, z, levels=np.logspace(0, 5, 35), norm=LogNorm(), cmap=plt.cm.jet) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) plt.show() Gradient-based Optimization We set the starting point as (3,4), since it is challenging for algorithms with a little too much momentum in the gradient descent update rule, as they may overshoot and end up in some local minima. x0 = np.array([3., 4.]) func = value_and_grad(lambda args: f(*args)) res = minimize(func, x0=x0, method=‘Newton-CG’, def make_minimize_cb(path=[]): We initialize the list with the starting value. path_ = [x0] path = np.array(path_).T fig, ax = plt.subplots(figsize=(10, 6)) ax.contour(x, y, z, levels=np.logspace(0, 5, 35), norm=LogNorm(), cmap=plt.cm.jet) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) Static Quiver Plot of Path on 3D Surface Plot fig = plt.figure(figsize=(8, 5)) ax.plot_surface(x, y, z, norm=LogNorm(), rstride=1, cstride=1, edgecolor=‘none’, alpha=.8, cmap=plt.cm.jet) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) Animating Single Path on 2D Contour Plot fig, ax = plt.subplots(figsize=(10, 6)) ax.contour(x, y, z, levels=np.logspace(0, 5, 35), norm=LogNorm(), cmap=plt.cm.jet) line, = ax.plot([], [], ‘b’, label=‘Newton-CG’, lw=2) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) ax.legend(loc=‘upper left’) def init(): def animate(i): anim = animation.FuncAnimation(fig, animate, init_func=init, HTML(anim.to_html5_video()) fig = plt.figure(figsize=(8, 5)) ax.plot_surface(x, y, z, norm=LogNorm(), rstride=1, cstride=1, edgecolor=‘none’, alpha=.8, cmap=plt.cm.jet) line, = ax.plot([], [], [], ‘b’, label=‘Newton-CG’, lw=2) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) We just have to make use of the set_3d_properties method for Line3D objects to set the height of the points on the path. def init(): Or better yet, we could just create subclass of FuncAnimation that is initialized with a variable number of paths to plot. In the initialization method, we just create and save the list of Line2D objects as attributes, and define animation callback methods that use these attributes. class TrajectoryAnimation(animation.FuncAnimation): We can extend this to 3-dimensions quite easily: class TrajectoryAnimation3D(animation.FuncAnimation): Note that TrajectoryAnimation3D is defined as an altogether different subclass of FuncAnimation here. A more elegant approach would be to subclass the TrajectoryAnimation class defined above, but this would make this exposition much less readable. Additionally, note that we don’t plot the leading point marker here, since this tends to clutter up the visualization on the 3D surface plots. SciPy’ Gradient-based Optimization Algorithms methods = [ ] minimize_ = partial(minimize, fun=func, x0=x0, jac=True, bounds=[(xmin, xmax), (ymin, ymax)], tol=1e-20) paths_ = defaultdict(list) results = {method: minimize_(method=method, callback=make_minimize_cb(paths_[method])) for method in methods} ax.contour(x, y, z, levels=np.logspace(0, 5, 35), norm=LogNorm(), cmap=plt.cm.jet) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) anim = TrajectoryAnimation(*paths, labels=methods, ax=ax) ax.legend(loc=‘upper left’) HTML(anim.to_html5_video()) ax.plot_surface(x, y, z, norm=LogNorm(), rstride=1, cstride=1, edgecolor=‘none’, alpha=.8, cmap=plt.cm.jet) ax.set_xlabel(’ x x x’) ax.set_xlim((xmin, xmax)) anim = TrajectoryAnimation3D(*paths, zpaths=zpaths, labels=methods, ax=ax) ax.legend(loc=‘upper left’) HTML(anim.to_html5_video()) Having the TrajectoryAnimation class at our disposal makes it incredibly simple to not only visualize, but animate optimization procedures, and allows us to better understand and be able to visually debug the optimization problems and algorithms we are working with. Furthermore, the fact that TrajectoryAnimation is a subclass of FunAnimation means we have the flexibility of exporting and presenting these animations in a variety of formats, e.g. exporting as GIFs, embedding them in Jupyter Notebooks as HTML5 videos. This can make our presentations far more compelling. In future posts in this series, we will demonstrate these methods on other objective functions, other optimization algorithms in other libraries such as TensorFlow, and generalize to higher-dimensional problems.



https://ruder.io/optimizing-gradient-descent/
中文翻译连接
https://blog.csdn.net/google19890102/article/details/69942970
可视化源代码
http://louistiao.me/notes/visualizing-and-animating-optimization-algorithms-with-matplotlib/
[1] Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., … Zheng, X. (2015). TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems.
[2] Bengio, Y., Boulanger-Lewandowski, N., & Pascanu, R. (2012). Advances in Optimizing Recurrent Networks. Retrieved from http://arxiv.org/abs/1212.0901
[3] Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009). Curriculum learning. Proceedings of the 26th Annual International Conference on Machine Learning, 41–48. http://doi.org/10.1145/1553374.1553380
[4] Darken, C., Chang, J., & Moody, J. (1992). Learning rate schedules for faster stochastic gradient search. Neural Networks for Signal Processing II Proceedings of the 1992 IEEE Workshop, (September), 1–11. http://doi.org/10.1109/NNSP.1992.253713
[5] Dauphin, Y., Pascanu, R., Gulcehre, C., Cho, K., Ganguli, S., & Bengio, Y. (2014). Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. arXiv, 1–14. Retrieved from http://arxiv.org/abs/1406.2572
[6] Dean, J., Corrado, G. S., Monga, R., Chen, K., Devin, M., Le, Q. V, … Ng, A. Y. (2012). Large Scale Distributed Deep Networks. NIPS 2012: Neural Information Processing Systems, 1–11. http://doi.org/10.1109/ICDAR.2011.95
[7] Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121–2159. Retrieved from http://jmlr.org/papers/v12/duchi11a.html
[8] Ioffe, S., & Szegedy, C. (2015). Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv Preprint arXiv:1502.03167v3
[9] Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13.
[10] LeCun, Y., Bottou, L., Orr, G. B., & Müller, K. R. (1998). Efficient BackProp. Neural Networks: Tricks of the Trade, 1524, 9–50. http://doi.org/10.1007/3-540-49430-8_2
[11] Mcmahan, H. B., & Streeter, M. (2014). Delay-Tolerant Algorithms for Asynchronous Distributed Online Learning. Advances in Neural Information Processing Systems (Proceedings of NIPS), 1–9. Retrieved from http://papers.nips.cc/paper/5242-delay-tolerant-algorithms-for-asynchronous-distributed-online-learning.pdf
[12] Neelakantan, A., Vilnis, L., Le, Q. V., Sutskever, I., Kaiser, L., Kurach, K., & Martens, J. (2015). Adding Gradient Noise Improves Learning for Very Deep Networks, 1–11. Retrieved from http://arxiv.org/abs/1511.06807
[13] Nesterov, Y. (1983). A method for unconstrained convex minimization problem with the rate of convergence o(1/k2). Doklady ANSSSR (translated as Soviet.Math.Docl.), vol. 269, pp. 543– 547.
[14] Niu, F., Recht, B., Christopher, R., & Wright, S. J. (2011). Hogwild! : A Lock-Free Approach to Parallelizing Stochastic Gradient Descent, 1–22.
[15] Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543. http://doi.org/10.3115/v1/D14-1162
[16] Qian, N. (1999). On the momentum term in gradient descent learning algorithms. Neural Networks : The Official Journal of the International Neural Network Society, 12(1), 145–151. http://doi.org/10.1016/S0893-6080(98)00116-6
[17] H. Robinds and S. Monro, “A stochastic approximation method,” Annals of Mathematical Statistics, vol. 22, pp. 400–407, 1951.
[18] Sutskever, I. (2013). Training Recurrent neural Networks. PhD Thesis.
[19] Sutton, R. S. (1986). Two problems with backpropagation and other steepest-descent learning procedures for networks. Proc. 8th Annual Conf. Cognitive Science Society.
[20] Zaremba, W., & Sutskever, I. (2014). Learning to Execute, 1–25. Retrieved from http://arxiv.org/abs/1410.4615
[21] Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method. Retrieved from http://arxiv.org/abs/1212.5701
[22] Zhang, S., Choromanska, A., & LeCun, Y. (2015). Deep learning with Elastic Averaging SGD. Neural Information Processing Systems Conference (NIPS 2015), 1–24. Retrieved from http://arxiv.org/abs/1412.6651
import matplotlib.pyplot as plt
import autograd.numpy as np
from matplotlib.colors import LogNorm
from matplotlib import animation
from IPython.display import HTML
from scipy.optimize import minimize
from collections import defaultdict
from itertools import zip_longest
from functools import partial
We shall restrict our attention to 3-dimensional problems for right now (i.e. optimizing over only 2 parameters), though what follows can be extended to higher dimensions by plotting all pairs of parameters against each other, effectively projecting the problem to 3-dimensions.
f = lambda x, y: (1.5 - x + xy)**2 + (2.25 - x + xy**2)2 + (2.625 - x + x*y3)**2
xmin, xmax, xstep = -4.5, 4.5, .2
ymin, ymax, ystep = -4.5, 4.5, .2
x, y = np.meshgrid(np.arange(xmin, xmax + xstep, xstep), np.arange(ymin, ymax + ystep, ystep))
z = f(x, y)
We know the global minima is at (3,0.5)
minima = np.array([3., .5])
f(*minima)
0.0
minima_ = minima.reshape(-1, 1)
minima_
array([[ 3. ],
[ 0.5]])
f(*minima_)
array([ 0.])
3D Surface Plot
fig = plt.figure(figsize=(8, 5))
ax = plt.axes(projection=‘3d’, elev=50, azim=-50)
edgecolor=‘none’, alpha=.8, cmap=plt.cm.jet)
ax.plot(*minima_, f(minima_), 'r’, markersize=10)
ax.set_ylabel(’ y y y’)
ax.set_zlabel(’ z z z’)
ax.set_ylim((ymin, ymax))
We use autograd to compute the gradient vector field, and plot it with Matplotlib’s quiver method.
dz_dy = elementwise_grad(f, argnum=1)(x, y)
fig, ax = plt.subplots(figsize=(10, 6))
ax.quiver(x, y, x - dz_dx, y - dz_dy, alpha=.5)
ax.plot(minima_, 'r’, markersize=18)
ax.set_ylabel(’ y y y’)
ax.set_ylim((ymin, ymax))
For the purposes of this demonstration, we use SciPy’s optimization methods. It goes without saying that the code and patterns for producing these visualizations generalizes easily to other optimization tools and libraries.
Again, we use autograd to compute the gradients, and augment the function slightly to adhere to Scipy’s optimization interface.
The method we use first is Newton-CG, and set the callback simply as print. Note that we can only do this in Python 3, where print is an actual function.
jac=True, tol=1e-20, callback=print)
[ 2.71113991 3.35161828]
[ 2.48008912 2.78955116]
[ 2.29965866 2.30123678]
[ 2.16373347 1.8756312 ]
[ 2.06741079 1.50235414]
[ 2.00766238 1.17079384]
[ 1.98485905 0.86972447]
[ 2.00511126 0.59071489]
[ 2.07692544 0.34891823]
[ 2.17857778 0.21644485]
[ 2.55966682 0.38003383]
[ 2.80228089 0.44954972]
[ 2.94477854 0.48765376]
[ 2.94564749 0.48601427]
[ 2.95359059 0.48810805]
[ 2.97113927 0.49269804]
[ 2.99870879 0.49976069]
[ 2.99999481 0.49999876]
[ 3.00000001 0.49999999]
[ 3. 0.5]
[ 3. 0.5]
dict(res)
{‘fun’: 2.5770606809684326e-18,
‘jac’: array([ 8.13600382e-10, 1.86117137e-09]),
‘message’: ‘Optimization terminated successfully.’,
‘nfev’: 22,
‘nhev’: 0,
‘nit’: 21,
‘njev’: 104,
‘status’: 0,
‘success’: True,
‘x’: array([ 3. , 0.5])}
The results look plausibly good, but would be more convincing with some visualization. Let us define a new callback function that appends the intermediate values to a list instead of simply printing it.def minimize_cb(xk):
# note that we make a deep copy of xk
path.append(np.copy(xk))
return minimize_cb
res = minimize(func, x0=x0, method=‘Newton-CG’,
jac=True, tol=1e-20, callback=make_minimize_cb(path_))
dict(res)
{‘fun’: 2.5770606809684326e-18,
‘jac’: array([ 8.13600382e-10, 1.86117137e-09]),
‘message’: ‘Optimization terminated successfully.’,
‘nfev’: 22,
‘nhev’: 0,
‘nit’: 21,
‘njev’: 104,
‘status’: 0,
‘success’: True,
‘x’: array([ 3. , 0.5])}
We cast the list to a NumPy array and transpose it so it’s easier and more natural to work with.
path.shape
(2, 22)
Static Quiver Plot of Path on 2D Contour Plot
Again, using the quiver method, but in a slightly different way than before, we can represent each step, it’s length and direction, using the arrows.
ax.quiver(path[0,:-1], path[1,:-1], path[0,1:]-path[0,:-1], path[1,1:]-path[1,:-1], scale_units=‘xy’, angles=‘xy’, scale=1, color=‘k’)
ax.plot(minima_, 'r’, markersize=18)
ax.set_ylabel(’ y y y’)
ax.set_ylim((ymin, ymax))
(-4.5, 4.5)
However, this is slightly less useful when plotted against a 3D surface plot…
ax = plt.axes(projection=‘3d’, elev=50, azim=-50)
ax.quiver(path[0,:-1], path[1,:-1], f(path[::,:-1]),
path[0,1:]-path[0,:-1], path[1,1:]-path[1,:-1], f((path[::,1:]-path[::,:-1])),
color=‘k’)
ax.plot(*minima_, f(minima_), 'r’, markersize=10)
ax.set_ylabel(’ y y y’)
ax.set_zlabel(’ z z z’)
ax.set_ylim((ymin, ymax))
(-4.5, 4.5)
We can also animate the trajectory of the optimization algorithm using the excellent FuncAnimation class. First we draw the 2D contour plot as we did before, and initialize the line and point (which are Line2D objects). Guides on how to use the FuncAnimation class can be found in tutorials such as Jake Vanderplas’ Matplotlib Animation Tutorial, so we will not go into too much detail here.
ax.plot(minima_, 'r’, markersize=18)
point, = ax.plot([], [], ‘bo’)
ax.set_ylabel(’ y y y’)
ax.set_ylim((ymin, ymax))
line.set_data([], [])
point.set_data([], [])
return line, point
We define our animation to draw the path up to ith intermediate point on the ith frame.
line.set_data(*path[::,:i])
point.set_data(*path[::,i-1:i])
return line, point
We define the total number of frames to be the total number of steps taken in the optimization and using blitting so as to only redraw the parts of the animation that have changed.
frames=path.shape[1], interval=60,
repeat_delay=5, blit=True)
We can embed the animation directly inside this notebook, as discussed in my previous post.
Animating Single Path on 3D Surface Plot
Extending the above to 3-dimensions is quite trivial.
ax = plt.axes(projection=‘3d’, elev=50, azim=-50)
ax.plot(*minima_, f(minima_), 'r’, markersize=10)
point, = ax.plot([], [], [], ‘bo’)
ax.set_ylabel(’ y y y’)
ax.set_zlabel(’ z z z’)
ax.set_ylim((ymin, ymax))
(-4.5, 4.5)
line.set_data([], [])
line.set_3d_properties([])
point.set_data([], [])
point.set_3d_properties([])
return line, point
def animate(i):
line.set_data(path[0,:i], path[1,:i])
line.set_3d_properties(f(*path[::,:i]))
point.set_data(path[0,i-1:i], path[1,i-1:i])
point.set_3d_properties(f(*path[::,i-1:i]))
return line, point
anim = animation.FuncAnimation(fig, animate, init_func=init,
frames=path.shape[1], interval=60,
repeat_delay=5, blit=True)
HTML(anim.to_html5_video())
Modularizing and Generalizing to Animate Multiple Paths Simultaneously
Instead of initializing the line and point in the global scope, and defining the animation callback functions to use those global variables, we can encapsulate everything in a closure.def __init__(self, *paths, labels=[], fig=None, ax=None, frames=None,
interval=60, repeat_delay=5, blit=True, **kwargs):
if fig is None:
if ax is None:
fig, ax = plt.subplots()
else:
fig = ax.get_figure()
else:
if ax is None:
ax = fig.gca()
self.fig = fig
self.ax = ax
self.paths = paths
if frames is None:
frames = max(path.shape[1] for path in paths)
self.lines = [ax.plot([], [], label=label, lw=2)[0]
for _, label in zip_longest(paths, labels)]
self.points = [ax.plot([], [], 'o', color=line.get_color())[0]
for line in self.lines]
super(TrajectoryAnimation, self).__init__(fig, self.animate, init_func=self.init_anim,
frames=frames, interval=interval, blit=blit,
repeat_delay=repeat_delay, **kwargs)
def init_anim(self):
for line, point in zip(self.lines, self.points):
line.set_data([], [])
point.set_data([], [])
return self.lines + self.points
def animate(self, i):
for line, point, path in zip(self.lines, self.points, self.paths):
line.set_data(*path[::,:i])
point.set_data(*path[::,i-1:i])
return self.lines + self.points
def __init__(self, *paths, zpaths, labels=[], fig=None, ax=None, frames=None,
interval=60, repeat_delay=5, blit=True, **kwargs):
if fig is None:
if ax is None:
fig, ax = plt.subplots()
else:
fig = ax.get_figure()
else:
if ax is None:
ax = fig.gca()
self.fig = fig
self.ax = ax
self.paths = paths
self.zpaths = zpaths
if frames is None:
frames = max(path.shape[1] for path in paths)
self.lines = [ax.plot([], [], [], label=label, lw=2)[0]
for _, label in zip_longest(paths, labels)]
super(TrajectoryAnimation3D, self).__init__(fig, self.animate, init_func=self.init_anim,
frames=frames, interval=interval, blit=blit,
repeat_delay=repeat_delay, **kwargs)
def init_anim(self):
for line in self.lines:
line.set_data([], [])
line.set_3d_properties([])
return self.lines
def animate(self, i):
for line, path, zpath in zip(self.lines, self.paths, self.zpaths):
line.set_data(*path[::,:i])
line.set_3d_properties(zpath[:i])
return self.lines
Now let’s take these newly defined classes out for a spin! Let us simultaneously animate SciPy’s gradient-based optimization algorithms.
“CG”,“BFGS”,
"Newton-CG",
"L-BFGS-B",
"TNC",
"SLSQP",
“dogleg”,
“trust-ncg”
We do some partial function application here to reduce the amount of code required…
Initialize the trajectories
for method in methods:
paths_[method].append(x0)
We expected these warnings, and can safely ignore them here.
/Users/tiao/.virtualenvs/tf/lib/python3.5/site-packages/scipy/optimize/_minimize.py:394: RuntimeWarning: Method CG cannot handle constraints nor bounds.
RuntimeWarning)
/Users/tiao/.virtualenvs/tf/lib/python3.5/site-packages/scipy/optimize/minimize.py:394: RuntimeWarning: Method Newton-CG cannot handle constraints nor bounds.
RuntimeWarning)
paths = [np.array(paths[method]).T for method in methods]
zpaths = [f(*path) for path in paths]
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(minima_, 'r’, markersize=10)
ax.set_ylabel(’ y y y’)
ax.set_ylim((ymin, ymax))
fig = plt.figure(figsize=(8, 5))
ax = plt.axes(projection=‘3d’, elev=50, azim=-50)
ax.plot(*minima_, f(minima_), 'r’, markersize=10)
ax.set_ylabel(’ y y y’)
ax.set_zlabel(’ z z z’)
ax.set_ylim((ymin, ymax))