从零入门Scarpy【1】:框架、数据流 和 实战案例
目录
一 Scrapy 框架介绍
二 Scrapy 的运作流程
三 Pycharm 中创建 Scrapy 项目
四 制作简单 Scrapy 爬虫
五 运行爬虫
Scrapy英文文档 https://docs.scrapy.org/en/latest
Scrapy1.7中文文档 https://www.osgeo.cn/scrapy/
一 Scrapy 框架介绍

- Scrapy Engine:引擎。负责Scheduler 、Downloader、Spider、ItemPipeline 中间的通讯、信号、数据传递等,是整个框架的核心
- Scheduler:调度器。负责接受Scrapy Engine发送过来的Request请求,并按照一定的方式将其加入队列中,当Scrapy Engine需要时,交还给Scrapy Engine
- Downloader Middlewares:下载器中间件。位于Scrapy Engine和Downloader之间的钩子框架,主要处理Scrapy Engine与Downloader之间的请求及响应。主要功能包括更换代理IP,更换Cookies,更换User-Agent,自动重试等
- Downloader:下载器。负责下载Scrapy Engine发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine,由Scrapy Engine交给Spiders来处理
- Spiders:蜘蛛。它负责从Responses中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给Scrapy Engine,再次进入Scheduler
- Spider Middlewares:蜘蛛中间件。位于Scrapy Engine和Spider之间的钩子框架,主要处理Spider输入的响应和输出的结果及新的请求(比如进入Spider的Responses和从Spider出去的Requests)。一般不用设置
- Item:项目。它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象
- Item Pipeline:项目管道。负责处理由Spider从网页中抽取的项目,它的主要任务是清洗、验证和存储数据
- 另,框架是个宝,多看一遍,多Scrapy的理解就多清晰一些
二 Scrapy 的运作流程
- Engine首先找到处理某网站的Spider,并向该Spider请求第一个要爬取的URL
- Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request的形式调度
- Engine向Scheduler请求下一个要爬取的URL
- Scheduler返回下一个要爬取的URL给Engine,Engine将URL通过Downloader Middlewares转发给Downloader下载
- 一旦页面下载完毕,Downloader生成该页面的Response,并将其通过Downloader Middlewares发送给Engine
- Engine从下载器中接收到Response,并将其通过Spider Middlewares发送给Spider处理
- Spider处理Response,并返回爬取到的Item及新的Request给Engine
- Engine将Spider返回的Item给Item Pipeline,将新的Request给Scheduler
- 重复第二步到最后一步,直到Scheduler中没有更多的Request,Engine关闭该网站,爬取结束
三 Pycharm 中创建 Scrapy 项目
1 创建项目

2 安装Scrapy
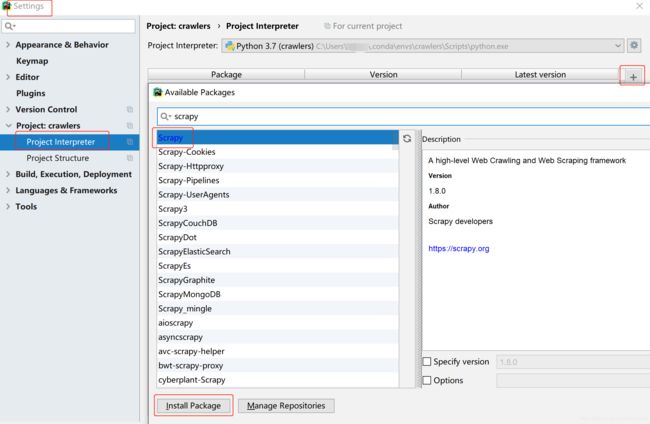
3 创建scrapy项目
# 打开terminal 输入以下命令
# scrapy startproject 爬虫项目名
scrapy startproject crawlers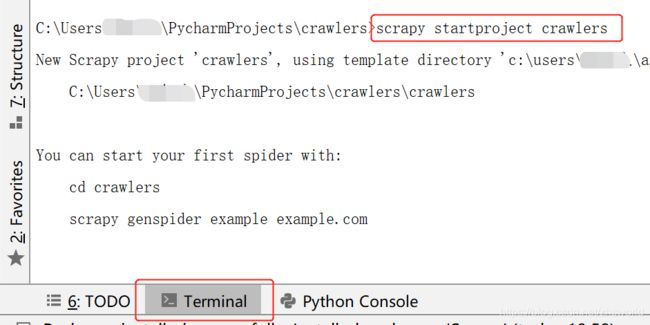
4 创建后的目录如下:
crawlers/
├── crawlers/ # project's Python module,you'll import your code from here
│ ├── spiders/ # a directory where put your spiders
│ │ └── __init__.py
│ ├── __init__.py
│ ├── items.py # 定义爬取的数据结构和字段信息。实现item
│ ├── middlewares.py # 自己定义的中间件。实现Spider Middlewares和Downloader Middlewares
│ ├── pipelines.py # 对spider返回数据的处理。实现Item Pipeline
│ └── settings.py # 项目的全局配置文件
└── scrapy.cfg # Scrapy部署时的配置文件
四 制作简单 Scrapy 爬虫
1 目标:获取易车上的所有品牌
2 具体制作流程:
2.1 设置基础的下载中间件(如随机选择UserAgent、使用ProxyAgent)
2.11 在 settings.py 中编写相应配置,如代理池等
2.12 从 settings.py 导入相应配置,编写 middlewares.py ,并在 settings.py 中开启
2.2 明确抓取的字段(编写 items.py)
2.3 制作具体的爬虫 (创建并编写 spiders/xxspider.py)
2.4 清洗和存储数据 (编写 pipelines.py,并在 settings.py 中开启)
3【settings.py】
# Obey robots.txt rules
# 设置为不遵守robots.txt协议
ROBOTSTXT_OBEY = False
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 罗列了大量UserAgent的网站。http://useragentstring.com/pages/useragentstring.php
# UserAgent池
UserAgent_Pools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
]
# IP代理池,这里用的是xdaili
import requests
import time
def get_proxy():
api_url = "http://api.xdaili.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=xxx&orderno=xxx&returnType=2&count=1"
time.sleep(6)
r = requests.get(api_url).json()
ip = r["RESULT"][0]["ip"]
prot = r["RESULT"][0]["port"]
thisProxy = ip + ":" + prot
print("thisProxy:",thisProxy)
return thisProxy
ProxyAgent = get_proxy()
# Enable or disable downloader middlewares
# 启用的下载中间件均需在这里注册。值越低,优先级越高
DOWNLOADER_MIDDLEWARES = {
'crawlers.middlewares.RandomUserAgent': 101,
'crawlers.middlewares.Proxy': 102,
}
# Configure item pipelines
# 开启pipelines
ITEM_PIPELINES = {'crawlers.pipelines.BrandPipeline': 300}
4 【middlewares.py】
4.1 Downloader Middleware的常用方法
def process_request(self, request, spider)
Called for each request that goes through the downloader middleware.
Should either: return None, return a Response object, return a Request object, or raise IgnoreRequest.
- 如果返回None。Scrapy将继续处理该request,执行其他的下载中间件的process_request方法,直到该request被执行
- 如果返回Response。Scrapy将终止当前流程,也终止继续调用其他process_request方法,将response通过引擎返回给爬虫
- 如果返回Request。Scrapy则终止当前流程,也终止继续调用其他process_request方法,将request返回给调度器,大多数情况是更换新的request请求
- 如果抛出异常。 该异常就会交个process_exception方法进行处理; 如果没有任何一个方法处理该异常,那么该请求就直接被忽略了且不做记录
def process_response(self, request, response, spider):
Should either: return None, return a Response object, return a Request object, or raise IgnoreRequest.
- 如果返回Response。则继续被下一个process_response方法处理
- 如果返回Request。Scrapy则终止当前流程,该request通过引擎返回给调度器
- 如果抛出异常。该请求就被忽略了且不做记录
4.1 Spider Middleware的常用方法(一般不用)
process_spider_input(response, spider)
当 Response 通过 Spider Middleware 时,该方法被调用,处理该 Response。
process_spider_output(response, result, spider)
当 Spider 处理 Response 返回结果时,该方法被调用。
process_spider_exception(response, exception, spider)
当 Spider 或 Spider Middleware 的 process_spider_input() 方法抛出异常时, 该方法被调用
process_start_requests(start_requests, spider)
该方法以 Spider 启动的 Request 为参数被调用,执行的过程类似于 process_spider_output() ,只不过其没有相关联的 Response 并且必须返回 Request。
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from crawlers.crawlers.settings import UserAgent_Pools,ProxyAgent
# 导入的是静态IP对应的变量ProxyAgent;直接导入获取动态IP的get_proxy会报错
import random
# 自定义的类。随机选择UserAgent
class RandomUserAgent(UserAgentMiddleware):
def __init__(self, user_agent):
self.user_agent = user_agent
def process_request(self, request, spider):
# 随机选择UserAgent
current_ua = random.choice(UserAgent_Pools)
# 设置UserAgent
request.headers['User-Agent'] = current_ua
print("当前的UserAgent是:" + str(current_ua))
# 自定义的类。使用IP代理
# request.meta本质是一个Python字典
# 其作用是随着Request的产生传递信息,传递信息的格式必须是字典类型(字典的键值可以是任意类型的,比如值、字符串、列表、字典)
class Proxy(object):
def process_request(self,request,spider):
if request.url.startswith("http://"):
request.meta['proxy']="http://"+ ProxyAgent # http代理
elif request.url.startswith("https://"):
request.meta['proxy']="https://"+ ProxyAgent # https代理
print("当前的Proxy是:" + str(ProxyAgent))其它教程中提到可以利用from_crawler方法读取settings中的信息,尝试之后,发现不能成功,暂未找到原因
class RandomUserAgent(UserAgentMiddleware): def __init__(self, user_agent): self.user_agent = user_agent @classmethod def from_crawler(cls, crawler): return cls(user_agent=crawler.settings.get('UserAgent_Pools')) def process_request(self, request, spider): agent = random.choice(self.user_agent) request.headers['User-Agent'] = agent print("当前的UserAgent是:" + str(agent))
5【items.py】
import scrapy
class BrandItem(scrapy.Item):
brand_id = scrapy.Field()
brand_name_ch = scrapy.Field()
brand_name_spell = scrapy.Field()
brand_dealers_nums = scrapy.Field()6.1 创建爬虫文件
scrapy genspider [-t template]
[-t template] 爬虫文件模板。可选参数有basic、crawl、csvfeed、xmlfeed。默认basic(一般选默认即可)
scrapy genspider yiche_brand bitauto.com6.2 【yiche_brand.py】
parse(response)
This is the default callback used by Scrapy to process downloaded responses, when their requests don’t specify a callback.
The parse method is in charge of processing the response and returning scraped data and/or more URLs to follow.
This method, as well as any other Request callback, must return an iterable of Request and/or dicts or Item objects.
Item传给Item pipline进行处理;Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
class YicheBrandSpider(scrapy.Spider):
name = 'yiche_brand'
allowed_domains = ['bitauto.com']
# custom_settings 会覆盖 settings 中 DEFAULT_REQUEST_HEADERS 的设置
# custom_settings = {'refer': 'https://dealer.bitauto.com/beijing/'}
# 异步加载,在浏览器中呈现的网址是"https://dealer.bitauto.com/beijing/"
start_urls = ['https://apicar.bitauto.com/CarInfo/getlefttreejson.ashx?tagtype=jingxiaoshang&pagetype=masterbrand']
# 一个def里可以有多个yield
def parse(self, response):
item = BrandItem()
data = response.text
# 使用正则提取相应信息
pat_brand_id = 'id:(.*?),name'
pat_brand_name_ch = 'name:"(.*?)",url'
pat_brand_name_en = 'url:"(.*?)",cur'
pat_brand_dealers_nums = 'num:(.*?)}'
brand_id = re.compile(pat_brand_id).findall(data)
brand_name_ch = re.compile(pat_brand_name_ch).findall(data)
brand_name_spell = re.compile(pat_brand_name_en).findall(data)
brand_dealers_nums = re.compile(pat_brand_dealers_nums).findall(data)
# 理论上提取出来的品牌ID、品牌中文名、品牌中文拼音、品牌经销商数的数量是一致的
brand_len = [len(brand_id), len(brand_name_ch), len(brand_name_spell), len(brand_dealers_nums)]
# 利用集合的特性
if len(set(brand_len)) == 1:
print(len(brand_id), len(brand_name_ch), len(brand_name_spell), len(brand_dealers_nums))
for i in range(len(brand_id)):
item['brand_id'] = brand_id[i]
item['brand_name_ch'] = brand_name_ch[i]
item['brand_name_spell'] = brand_name_spell[i]
item['brand_dealers_nums'] = brand_dealers_nums[i]
yield item
else:
print('品牌ID、品牌中文名、品牌中文拼音、品牌经销商数的数量不一致的')6.3【pipeline.py】
process_item(item, spider)
每个Item Pipeline必须实现process_item方法,该方法用来处理每一项由Spider爬取到的数据
其中参数Item是爬取到的一项数据(Item或字典)。Spider是爬取此项数据的Spider对象。
process_item在处理某项item时,如果返回了一项数据(Item或字典),返回的数据会递送给下一级级Item Pipeline(如果有)继续处理;如果抛出(raise)一个DropItem异常(scrapy.exceptions.DropItem),那么该Item既不会被继续处理,也不会被导出。通常,在检测到无效数据或想要过滤掉某些数据的时候使用
open_spider(self, spider)
在spider开启的(数据爬取前)调用该函数,通常用于数据爬取前的某些初始化工作,如打开数据库连接
参数spider就是被开启的Spider对象
close_spider(self, spider)
在spider关闭时(数据爬取后)调用该函数,通常用于数据爬取后的收尾工作,如关闭数据库连接
参数spider就是被关闭的Spider对象
import pymysql
class BrandPipeline(object):
def __init__(self):
# 链接数据库
self.db = pymysql.connect(host="localhost", user="root", password="xxx", port = 3306, database ="crawlers")
# 创建游标
self.cur = self.db.cursor()
def process_item(self, item, spider):
brand_id = item['brand_id']
brand_name_ch = item['brand_name_ch']
brand_name_spell = item['brand_name_spell']
brand_dealers_nums = item['brand_dealers_nums']
val = (brand_id,brand_name_ch,brand_name_spell,brand_dealers_nums)
# 插入数据语句。ignore代表忽略重复值
s_ins = """insert ignore into yiche_brand(brand_id,brand_name_ch,brand_name_spell,brand_dealers_nums)
values (%s, %s, %s, %s)"""
# 执行语句
self.cur.execute(s_ins,val)
# 提交数据
self.db.commit()
# 交给后边的管道Pipeline处理继续处理
# 如果不让后面管道Pipeline,可以抛出异常:raise DropItem("Duplicate item: %s" % item)
return item
def close_spider(self,spider):
# 关闭数据库
self.db.close()五 运行爬虫
scrapy crawl yiche_brand
end