RocketMQ 是如何使用dledger 模式保证故障自动恢复的
目录
前言:
RocketMQ dledger 集群架构
RocketMQ leader选举
RocketMQ 如何使用心跳维护leader地位
RocketMQ 故障恢复
总结
前言:
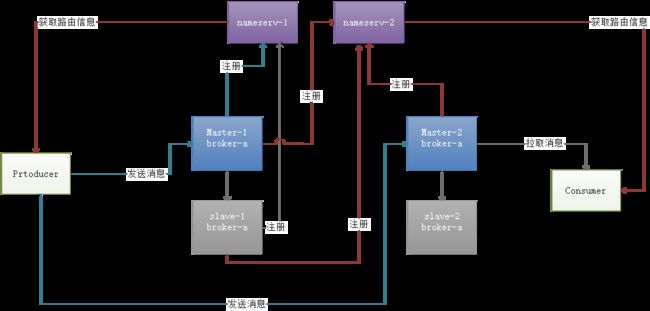
在RocketMQ 4.5之前,RocketMQ 都是采用master-slave主从架构部署,如下图,master节点负责写入消息,slave节点负责同步master节点消息。假设master-1节点有个topic-A,假设此时master节点宕机无法提供服务了,此时我们是无法写入topic-A消息的,这个时候RocketMQ 对于我们producer服务来说来说是不可用的,只有手动让slave-1节点升级生master节点,或者重启恢复master-1节点,RocketMQ 集群才能恢复正常。
那么有没有一种办法可以让slave-1从节点自动升级为master对外提供服务呢?当然,那就是RocketMQ 4.5版本提供的dledger集群模式,接下来我们就会介绍一下RocketMQ dledger 集群模式。
RocketMQ dledger 集群架构
我们还是先简单介绍一下rocketmq dledger集群架构原理吧,如下图:
1. 一个RocketMQ集群至少需要部署三个节点,其中一个leader节点,其余两个follower节点。
2.leader节点负责写入消息,当消息写入leader节点内存之后,leader会将消息同步到follower节点,当集群过半数(节点数/2 +1)节点都写入了消息,leader节点则提交这个消息,这样一条消息就算是写成功了。RocketMQ这种类似2pc写入方式保证了主从最终一致性。
3.如果leader节点挂了,RocketMQ集群会触发leader选举,重新选举一个新的leader节点负责写入数据,选举过程中整个RocketMQ集群是不可用状态。
4.和之前主从集群架构一样,RocketMQ dledger集群的每个节点也都会向namesrv所有的节点进行注册,没有任何区别。
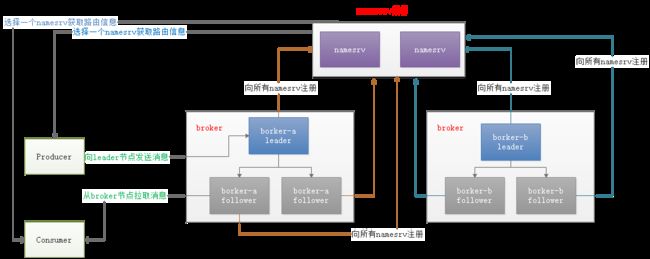
在这里大家会有一个疑问,dledger是如何进行leader选举的,leader节点挂掉了又如何自动故障恢复的呢?其实dledger 底层使用使用Raft一致性协议实现了集群的高可用和一致性,接下来,我会用大白话详细讲解,RockeMQ的dledger集群模式是如何结合Raft协议进行leader选举和故障恢复的。
RocketMQ leader选举
上面也说了, dledger底层使用的是Raft协议,如果你之前对Raft协议有一定的了解,那就很容易理解dledger的集群架构底层实现原理。dledger把mq集群中的broker节点分为三个角色,每个角色有着不同的处理业务逻辑:
Leader角色 :负责写入数据,将数据同步到follower节点,保证主从数据一致性,同时使用心跳机制维护自己领导者地位;
Follower角色:负责接受leader节点数据并保存到本地;响应leader节点心跳;
Candidate角色:该角色进行leader选举。
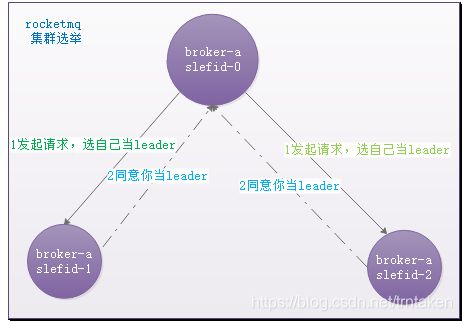
当RocketMQ 三个节点刚启动或者leader节点故障挂断的时候,这个时候集群全部节点都是candidate 状态,此时会触发leader选举,选举步骤入下:
1.首先启动三个RocketMQ broker节点,节点id依次为selfid-0,selfid-1,selfid-2;
2.三个broekr节点刚启动时全都是candidate状态;
3.假设selfid-0 broker节点首先发起选举,它会投自己一票,然后再向selfid-1,2节点分别发起选举请求,;
4.由于selfid-1,2节点还没有发起选举请求,此时这两个节点都会同意selfid-0发来的选举请求,然后给selfid-0节点一个ack回复;
5.selfid-0节点收到selfid-1,2节点ack回复,计算自己得到的投票数超过半数节点,将自己的状态更新为leader,则当选为leader。
RocketMQ 如何使用心跳维护leader地位
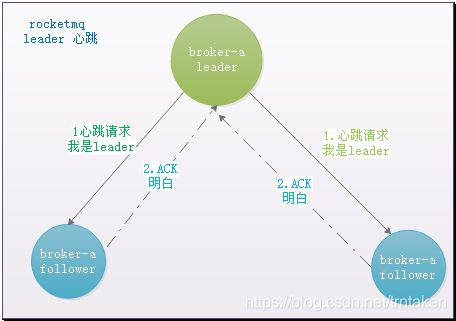
selfid-0节点当选为leader之后,首选要维护自己的leader者地位。他要告诉集群其他节点,我是集群中的leader,你们要成为我的follower,负责同步我的数据;并且保证只要我还活着,你们就不要妄想重新进行选举。具体步骤如下:
1.每隔几秒钟leader节点会向所有follower节点发送心跳请求;
2.follower收到心跳请求之后,更新本地倒计时时间,同时给leader节点一个确认回复;
3.leader节点收到过半数follower节点的回复,则说明自己还是leader。
如果没收到过半数follower节点回复,则会变更为candidate状态,重新触发选举;同样的,如果follower节点一直没收到
leader节点的心跳请求,follower节点也会变更为candidate状态,触发leader选举。
RocketMQ 故障恢复
了解了dledger的心跳原理之后,就很容易明白故障恢复机制。看上面这张图,假设此时leader节点故障挂掉,
follower节点收不到leader节点的心跳请求,那么follower节点就会触发leader选举,选举自己为leader节点,这样Rokcetmq 集群又可以正常提供服务了。
总结
RocketMQ dledger 使用了Raft 协议,保证所有节点数据最终一致性,同时保证了集群的可用性。有兴趣的同学可以从github上下载dledger的源码看一下,对我们掌握Raft协议有很好的帮助