零基础边缘端智慧社区训练营 | Lesson 4
5个课时完成智慧社区AI实战项目!
欢迎大家来到AidLux零基础边缘端智慧社区训练营~
在上一节课程中,我们对车牌检测和识别模型进行了数据的预处理、模型训练、检测推理等操作。
本节课中,我们继续上节课的内容,将车牌检测和识别移植到android端,完成算法的移动端部署。
在开始这次课程之前,我们先了解下本节课的内容框架:
1 车牌检测+识别模型的onnx序列化
2 车牌检测+识别模型的tflite的轻量化
3 车牌+识别的Andorid端部署
4 大作业
智慧社区第四课演示视频
1. 车牌检测+识别模型的onnx序列化
Onnx模型是基于Protobuf二进制格式,初始由微软和Facebook推出,后面得到了各大厂商和框架的支持。所以本节课,我们首先将车牌检测+识别模型导出成onnx模型。
1.1 车牌检测onnx导出
在第三节课中,车牌检测使用的是yolov5算法,其代码中自带导出代码,修改export_yolov5.py中的配置代码:

修改里面的权重文件路径,运行export_yolov5.py ,生成onnx 在weights权重中:
![]()
使用netron打开onnx模型,如果大家没有netron软件,可以看
网络可视化工具netron详细安装流程_江大白*的博客-CSDN博客_nerton安装教程。

因为yolov5已经相对成熟,所以这里不做单独的onnx的前向推理校验了。
1.2 车牌识别模型的onnx导出
第二步是导出车牌识别的onnx 模型,这里大刀带大家一起搭载导出模型。
导出onnx模型的主要步骤是:搭建算法网络→导入算法模型→确认输入输出维度→通过torch.onnx.export导出。
如下:车牌识别onnx导出的代码,即export_lprnet.py。将以下模型的地址修改成自己对应的地址即可。

运行export_lprnet.py:

导出的模型,自动生成,放在model/LPRNET_Simplified.onnx。
完成后,我们将onnx模型与pytorch模型对同一个图片的输出结果对比下,onnx模型是对pytorch模型的转写,所以按理说他们对同一张图片的输出结果相同。运行python diff_pytorch_onnx.py :

其中23行中的画横线的部分即模型的输入和输出名字,其中["139"]对应着输出名字,["input.1"]对应着输入名字,需要通过netron软件打开对应的onnx模型来对应,大家在自己的模型转换后,记得要对应上,不然会报错:

将pth模型和onnx模型路径改成对应的路径后,运行python diff_onnx_pytorch.py 文件,会报错:

显示lprnet网络中的maxpool有问题,发现官方的maxpool3d不支持,这里将maxpool3d用两个maxpool2d去实现(给大家的代码code_plate_detection_recognition 里面已经给大家改过):

再使用上述的模型转换,再运行一次python diff_onnx_pytorch.py,结果显示onnx模型推理和pytorch模型推理结果基本相等,则说明onnx模型转换的没有问题。

1.3 onnx模型的前向推理
至此,我们的车牌识别转换成onnx模型已经完成,下面通过对两个onnx模型的pipeline前向推理,完成onnx模型的验证。
这里onnx相对于pt模型推理的pipeline搭建,主要修改两个点:
1是模型的加载,之前的torch.load方式加载,这里是onnxruntime来加载;
2是为了剥离torch框架,需要将图像的前处理和结果的后处理部分中涉及到的torch部分都改成np的实现,detect_torch_pipeline.py中:

改成detect_onnx_inference.py:

改完后,整个onnx的代码框架则不依赖torch,运行python detect_onnx_pipeline.py,打开保存的结果如下,汉字部分因为字体的原因无法显示,大家可以换下字体。

同时用通过 detect_torch_pipeline.py 和detect_onnx_pipeline.py 运行同一张图片,结果显示如下:结果一致。

2. 车牌检测+识别模型的tflite的轻量化
因为模型需要部署在移动端,所以还需要将模型轻量化,同时考虑后面我们使用的aidlux对tflite的支持,所以选用tflite框架,对模型轻量化。
在模型转换之前,需要对tflite的环境提前安装:

2.1 车辆检测模型的tflite轻量化
Yolov5对tflite的转换比较成熟:修改对应的路径, 运行python export_tflite.py:
得到模型:
![]()
2.2 车牌识别模型的tflite轻量化
同理车牌识别模型,修改对应的路径,运行python export_tflite.py:

得到tflite模型:
![]()
2.3 车牌识别tflite的前向推理
基于onnx的pipeline推理代码,修改tflite的代码,其主要修改的点在于模型的加载,由onnx模型加载改成tflite模型的加载:

以及inference时:

并修改对应的配置参数如下:

运行 python detect_tflite_pipeline.py,成功,输出结果图片:

检测结果不对,而onnx 的模型输出没有问题,这种框不准的问题一般是后处理过程中的anchor对应的问题,打开yolov5.tflite模型,发现输出output的顺序是40,20,80:

而onnx模型的顺序20,40,80:
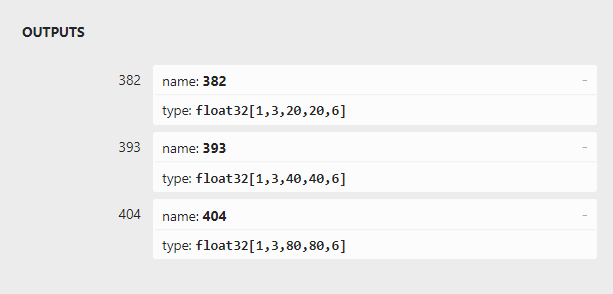
而anchor尺寸对应是和onnx模型移植的,这样tflite模型在后处理时与anchor尺寸则对应不起来。修改tflite输出的代码,将顺序重排:

再运行python detect_tflite_pipeline.py,查看结果:

以上我们就在pc端完成了轻量化模型tflite的前向推理的验证,下一步则是将模型移植到Android端。
3 AidLux端模型的推理和测试
AidLux的使用,在第二节课中已经有介绍,这里不做赘述,假设大家对AidLux和vscode的使用已经有所了解,不了解的小伙伴可以去看第二节课的内容。
根据在PC端的tflite推理,修改在Android端的推理,主要的变动在于模型的初始化和模型的推理两个方面。
首先是通过netron打开tflite模型,确定输入和输出size修改模型初始化的部分:
3.1 车牌检测部分

在aidlux/detect_aidlux_inference.py文件下,修改模型路径,同时in_shape 和out_shape 要与netron中的输入输出保持一致。

3.2 车牌识别部分
根据LPRNet的tflite修改初始化部分:


在aidlux/detect_recog_aidlux_inference.py文件下,修改模型路径,同时inShape1 和outShape1 要与netron中的输入输出保持一致。
这里需要注意的是aidlite.ANNModel的api中最后一个参数为模式设置,1为gpu模式,2为dsp模式,-1为cpu模式。比如我们的LPRNet中有个算子ReduceMean_3,GPU不支持,则不能设置为1,如果要用gpu推理,则需要对这个算子优化。
3.3 模型控制
同时因为一个代码中加载了两个模型,需要aidlite.set_g_index()对模型进行控制:
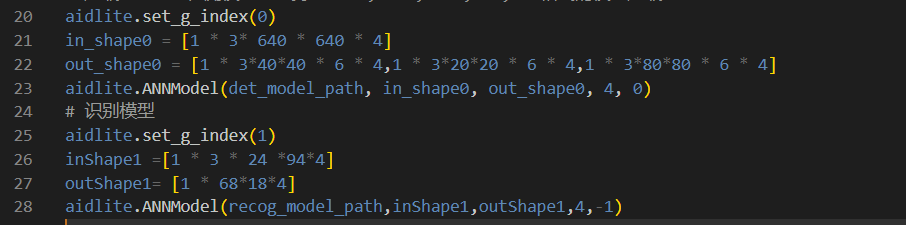
在推理时,当设置为0时,为调用检测模型,设置为1时,调用车牌识别模型。
3.4 模型推理
模型推理时,第一需要将输入设置成float32格式,同时将框架设置成推理模式:

同理车牌识别模型:

3.5 模型后处理
模型后处理部分基本上同在pc端的后处理,唯一的区别在于在移动端的模型输出shape需要reshape回pc端对应的shape:
车牌检测:

车牌识别:

这样整个推理pipeline在aidlux上则完成了,运行python aidlux/det_recog_aidlux_inference.py:

手机端弹出页面,大功告成,同时上面的显示中的中文显示乱码,这里修改下字体设置即可。
4 大作业
以上就是车牌识别项目,从车牌检测到识别的部分在手机移动端做迁移的整体流程,希望对大家在做其他项目时有帮助。
同时给大家布置个大作业,以上的pipeline都是以图片级别实现的,大家可以尝试将其改成视频读取的方式,并拍个路边车牌的视频,或者找个车辆行驶的视频,使用我们的pipeline实现视频的车牌识别功能。
参考作品参考模板,将项目实现过程形成文章(内含视频demo),发布到AidLux开发者社区、知乎、B站、csdn、掘金等网站。
完成大作业的同学即可成为AidLux认证开发者,在AidLux官网、社区进行形象和作品展示,有机会获得周边产品等福利;
完成训练营作业成为认证开发者之后,再提交一个AI应用作品,即可获得7T算力的边缘智能设备一台(基于高通855芯片模组,不重复赠送);
大家还可以参加AidLux AI应用案例悬赏征集活动。开发者可以基于选题库提供的选题,结合自己的专业开发能力,将选题内容实现,并成功部署运行在使用AidLux的设备上。
按照规范提交效果展示视频(录屏)和项目代码包并通过检验即可获得最高千元以上现金奖励!
本次智慧社区训练营的全部课程到此结束了,感谢大家的学习,也期待大家的作品。
大家可以在AidLux公众号后台回复”训练营“,获取本次(智慧社区)训练营所需物料资源包,以及智慧安防、智慧交通训练营全部课程内容及对应资源包。
用AidLux,每个人都能轻松落地AI应用。