Spark基础
一、spark基础

1、为什么使用Spark
Ⅰ、MapReduce编程模型的局限性
(1) 繁杂
只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
(2) 处理效率低
Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据 任务调度与启动开销大
(3) 不适合迭代处理、交互式处理和流式处理
Ⅱ、Spark是类Hadoop MapReduce的通用并行框架
(1) Job中间输出结果可以保存在内存,不再需要读写HDFS
(2) 比MapReduce平均快10倍以上
Ⅲ、Spark VS Hadoop
| Hadoop |
Spark |
|
| 类型 |
分布式基础平台,包含计算、存储、调度 |
分布式计算工具 |
| 场景 |
大规模数据集上的批处理 |
迭代计算、交互式计算、流计算 |
| 价格 |
对机器要求低,便宜 |
对内存有要求,相对较贵 |
| 编程范式 |
Map+Reduce,API较为底层,算法适应性差 |
RDD组成DAG有向无环图,API较为顶层,方便使用 |
| 数据存储结构 |
MpaReduce中间计算结果存在HDFS磁盘上,延迟大 |
RDD中间运算结果存在内存中,延迟小 |
| 运行方式 |
Task以进程方式维护,任务启动慢 |
Task以线程方式维护,任务启动快 |
2、Spark简介
诞生于加州大学伯克利分校AMP实验室,是一个基于内存的分布式计算框架
发展历程:
2009年诞生于加州大学伯克利分校AMP实验室
2010年正式开源 2013年6月正式成为Apache孵化项目
2014年2月成为Apache顶级项目
2014年5月正式发布Spark 1.0版本
2014年10月Spark打破MapReduce保持的排序记录
2015年发布了1.3、1.4、1.5版本
2016年发布了1.6、2.x版本
......
Hadoop 之父 Doug Cutting 指出:
Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark
(大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
3、Spark优势
(1)速度快
基于内存数据处理,比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上
(2)易用性
支持Java、Scala、Python、R语言 交互式shell方便开发测试
(3)通用性
一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
(4)多种运行模式
YARN、Mesos、EC2、Kubernetes、Standalone、Local
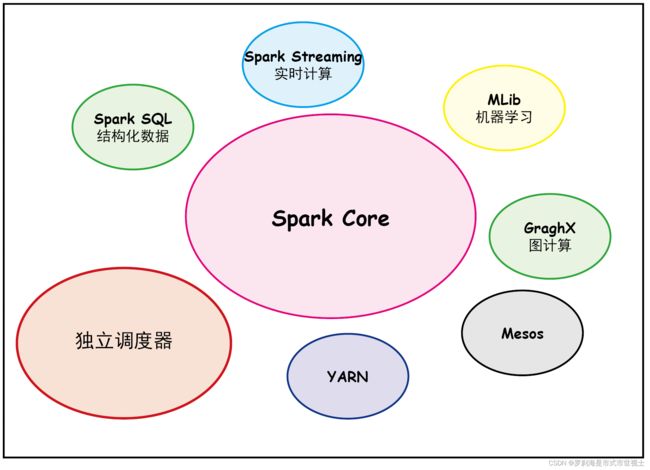
4、Spark技术栈
(1)Spark Core
核心组件,分布式计算引擎。
实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
(2)Spark SQL
高性能的基于Hadoop的SQL解决方案。
Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
(3)Spark Streaming
可以实现高吞吐量、具备容错机制的准实时流处理系统。
Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
(4)Spark GraphX(图计算)
分布式图处理框架。
Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
(5)Spark MLlib
构建在Spark上的分布式机器学习库。
提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
(6)其他
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
二、安装spark
spark下载地址https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
1、通过Xftp上传文件

2、解压文件至指定的安装目录
tar -zxvf /opt/install/scala-2.12.10.tgz -C /opt/soft/
tar -zxvf /opt/install/spark-3.1.2-bin-hadoop3.2.tgz -C /opt/soft/
3、进入安装目录更改名字
mv ./scala-2.12.10.tgz ./scala212
mv ./spark-3.1.2-bin-hadoop3.2.tgz ./spark3124、配置环境变量
#SCALA
export SCALA_HOME=/opt/soft/scala212
export PATH=$SCALA_HOME/bin:$PATH
#SPARK
export SPARK_HOME=/opt/soft/spark312
export PATH=$SPARK_HOME/bin:$PATH
!!! source /etc/profile
5、启动Scala
6、Spark环境部署
(1)进入/opt/soft/spark312/conf拷贝文件
cp ./workers.template ./workers
cp ./spark-env.sh.template ./spark-env.sh
(2)配置workers
# 编辑文件
vim workers
# 配置文件
localhost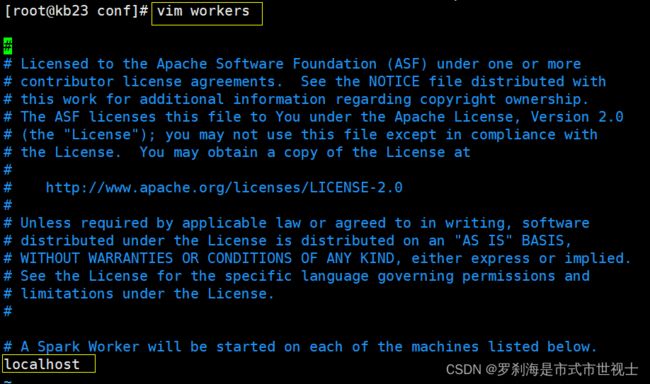
(3)配置spark-env.sh
# 编辑文件
vim ./spark-env.sh
# 配置文件
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=192.168.91.11
export SPARK_DRIVER_MEMORY=2G
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312
# 保存退出
:wq
# 刷新
source
7、启动交互式平台
spark-shell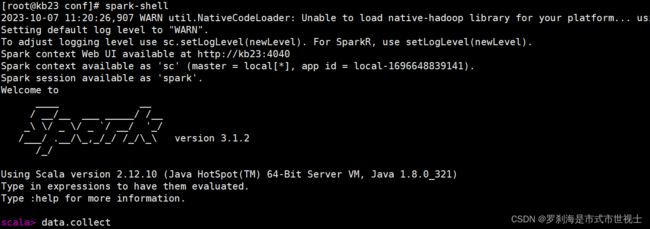
8、Spark运行模式
(1)local 本地模式(单机)
学习测试使用,分为local单线程和local-cluster多线程。
(2)standalone 独立集群模式
学习测试使用,典型的Master/slave。
(3)standalone-HA 高可用模式
生产环境使用,基于standalone模式,使用zk搭建高可用,避免Master是有单点故障的。
(4)on yarn 集群模式
生产环境使用,运行在yarn负责资源管理,Spark负责任务调度和计算。
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
(5)on mesos 集群模式
国内使用较少,运行在mesos资源管理器框架之上,由mesos负责资源管理,Spark负责任务调度和计算。
(6)on cloud 集群模式
中小型公司未来会更多的使用云服务,比如AWS的EC2,使用这个模式能很方便的访问Amazon的S3。