js进阶1
-
基本数据类型和引用数据类型有什么区别
-
垃圾回收机制
- 垃圾回收机制是什么
- gc策略是什么
- 如何减少gc开销
- 如何优化gc
- 内存泄漏原因有哪些
-
函数递归是什么
-
谈谈js异步编程?
或问 js事件循环机制是什么?
或问 什么是Event Loop?
js进阶注意事项#
行业敲门砖#
技术为王
web前端岗位竞争对手#
应届毕业生(计算机)自学者(转行)- 社会上的web前端工程师
- 其他机构的学员
核心竞争能力#
- js进阶
- 项目
- 就业辅导
js进阶怎么学#
- 理解
- 背诵(用自己的话来总结) => 关系到待遇的高低
(一) 基本数据类型和引用数据类型的区别#
变量在内存中的存储方式
复习:
- 基本数据类型有哪些
- 数字
- 字符串
- 布尔
- null
- undefined
- 对象
- symbol(es6)
- 引用数据类型有哪些
- 纯对像
- 数组
- 函数
- .......
基本数据类型和引用数据类型数据在内存中的存储
-
基本数据类型存放在 栈区
-
引用数据类型存放在 堆区, 同时在栈区存放数据在堆区的地址(引用)
var num = 100;
var str = 'hello';
var obj = {
age:100,
username: '张三'
}
以上数据在内存中的存储如图所示

练习: 说出下面代码运行的结果, 并说说为什么
var a = 100;
var b = a;
b = 200;
console.log(a); // 100
var obj1 = {
name: '张三',
age: 10
}
var obj2 = obj1;
obj2.name = '李四';
console.log(obj1.name);
console.log(obj2.name);
标题
js垃圾回收机制和内存泄漏
(二) 函数的调用方式#
- 普通调用
- 回调
- 递归调用
- 自调用
// 普通调用(略)
// 回调函数: 函数作为参数
// callback是个函数
function foo(callback) {
callback(100); // callback就是goo(100)
}
function goo(num) {
console.log(num);
}
foo(goo);
// jquery中的回调函数
$.ajax({
type:'get',
url: 'xxxxxx',
dataType:'json',
// 成功时的回调函数
success: function(res) {
console.log(res);
},
// 失败时的回调函数
error: function(err) {
console.log(err);
}
})
// 递归是指函数自己调用自己
function say() {
say();
}
// 不使用for循环进行数字累加
var sum = 0;
function add(i) {
sum = sum + i;
console.log(sum);
++i;
if (i <= 100) {
add(i);
}
}
add(1);
// 自调用:可以避免全局变量污染
(function(c){
var a = 100;
var b = 200;
console.log(c);
})(300);
思考: 如何使用递归函数, 用setTimeout模拟定时器
(三) js垃圾回收机制#
垃圾回收机制是什么#
垃圾回收机制(GC:Garbage Collection),执行环境负责管理代码执行过程中使用的内存。垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。但是这个过程不是实时的,因为其开销比较大,所以垃圾回收器会按照固定的时间间隔周期性的执行。
垃圾回收策略是什么#
2种最为常用:标记清除和引用计数,其中标记清除更为常用。
标记清除(mark-and-sweep):是对于脱离作用域的变量进行回收,当进入作用域时,进行标记,离开作用域时,标记并回收这些变量。到目前为止,IE、Firefox、Opera、Chrome、Safari的js实现使用的都是标记清除的垃圾回收策略或类似的策略,只不过垃圾收集的时间间隔互不相同。 当变量进入环境(例如,在函数中声明一个变量)时,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占的内存,因为只要执行流进入相应的环境,就可能用到它们。而当变量离开环境时,这将其 标记为“离开环境”。
引用计数:引用计数是跟踪记录每个值被引用的次数。就是变量的引用次数,被引用一次则加1,当这个引用计数为0时,被视为准备回收的对象,每当过一段时间开始垃圾回收的时候,就把被引用数为0的变量回收。引用计数方法可能导致循环引用,类似死锁,导致内存泄露。
如何减少垃圾回收开销#
由于每次的垃圾回收开销都相对较大,并且由于机制的一些不完善的地方,可能会导致内存泄露,我们可以利用一些方法减少垃圾回收,并且尽量避免循环引用。
-
在对象结束使用后 ,令obj = null。这样利于解除循环引用,使得无用变量及时被回收;
-
js中开辟空间的操作有new XX() 比如new Date() , [ ], { }, function (){..}。尽量减少此类操作, 最大限度的实现对象的重用;举例:
var arr = [1,2,3,4]; arr = []; // 清空数组-不好的做法 arr.length = 0; // 清空数组,好的做法 -
慎用闭包。闭包容易引起内存泄露。本来在函数返回之后,之前的空间都会被回收。但是由于闭包可能保存着函数内部变量的引用,且闭包在外部环境,就会导致函数内部的变量不能够销毁。
如何优化垃圾回收#
分代回收(Generation GC):与Java回收策略思想是一致的。目的是通过区分“临时”与“持久”对象;多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时。 增量GC:这个方案的思想很简单,就是“每次处理一点,下次再处理一点,如此类推。
常见内存泄露的原因#
- 全局变量滥用引起的内存泄露
- 闭包引起的内存泄露:慎用闭包
- dom清空或删除时,事件未清除导致的内存泄漏
- 循环引用带来的内存泄露
参考连接: 前端面试——JS垃圾回收机制_小木house的博客-CSDN博客_前端垃圾回收机制哪些操作会造成内存泄露 - Kaicy - 博客园
总结:#
- 什么是gc
- gc策略
- 如何减少垃圾回收开销
- gc优化
- 内存泄漏的原因
(四) js异步编程#
(1) 同步和异步(理解)#
js中的同步和异步跟生活中的同步异步意思有些不太一样
js的同步指的是,同一时间只执行一个任务, 当一个任务结束以后才能执行下一个任务。
js的异步指的是,同一时间可以执行多个任务,常见的js异步操作有setTimeout(), setInterval(), ajax请求等。
(2) 单线程和多线程(理解)#
单线程: 同一时间只能做一件事 多线程: 同一时间可以做多件事 JavaScript语言的一大特点就是单线程, 那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。比如java和c#就是多线程的语言。 JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准? 所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
(3) JS中的异步运行机制#
也称js事件循环机制(Event Loop)
JS是单线程的,那么他是如何是实现异步操作的? JS中的异步运行机制(背诵):
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件(事件一般都有对应的回调函数)。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行任务(实际上就是执行任务对应的回调函数)。
(4)主线程不断重复上面的前三步。
举例说明:
以上例子画图如下:
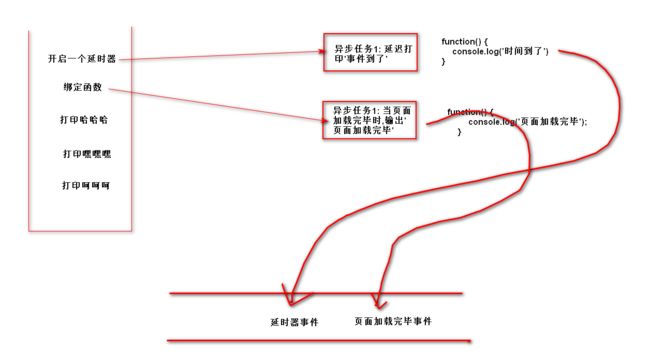
思考问题:
-
把下面例子中的setTimeout 2000改为0, 输出顺序会不会发生改变
答: 不会, 因为setTimeout是异步, 必须要等同步任务执行完, 才开始执行异步任务
-
若setTimeout的延迟设为1秒, 1秒后setTimeout的回调函数一定会执行吗
答: 不一定, 什么时候执行取决于有没有同步任务, 以及同步任务执行所需时间
setTimeout(function () { console.log("时间到"); }, 1000); var count = 0; for(;;){ count++; if (count === 1000000) { break; } }; -
说出以下代码运行的结果, 并解释为什么
for (var i = 0; i < 5; i++) { setTimeout(function () { console.log(i); }, 0) }如和修复此bug?
-
参考链接: JavaScript 运行机制详解:再谈Event Loop - 阮一峰的网络日志
(五) this的指向#
问题:谈谈this的指向(背诵) 或问:解释下JavaScript中this是如何工作
答: this的指向有以下几种情况
注意: this永远指向函数运行时所在的对象,而不是函数被创建时所在的对象。
- 普通的函数调用: 函数被谁调用,this就是谁。
- 匿名函数或不处于任何对象中的函数指向window 。
- 如果是call, apply, bind,this指向了这三者调用函数时传入的第一个参数
- 构造函数中的this, 直接调用函数this的指向同第1点, 使用new操作符, this指向构造函数所创建的实例对象
- 箭头函数的指向: 由于箭头函数不绑定this, 它会捕获其所在(即定义的位置)上下文的this值, 作为自己的this值
(1) 普通的函数调用#
函数被谁调用,this就是谁。
思考
var person = {
name: '张三',
sayName: function() {
console.log('this',this);
}
}
var fn = person.sayName;
fn(); // this指向谁
(2) 匿名函数或不处于任何对象中的函数指向window#
var person = {
name: '张三',
say: function () {
setTimeout(function() {
console.log(this);
},1000);
}
}
person.say();
(3) call, apply, bind的指向#
如果是call, apply, bind,this指向了这三者调用函数时传入的第一个参数, 详看 call, apply, bind下一个知识点: call, apply和bind的区别
(4) 构造函数的this指向#
构造函数的话,如果不用new操作符而直接调用,那即this指向window。用new操作符生成对象实例后,this就指向了新生成的对象。
(5) 箭头函数的this#
由于箭头函数不绑定this, 它会捕获其所在(即定义的位置)上下文的this值, 作为自己的this值: 将在es6新特性里细讲
(六) call, apply和bind的区别#
问题: call, apply和bind有什么区别
三者都会改变this的指向, 区别:
1. call 和 apply 的的使用#
使用call和apply都功能相同, 都能改变this的指向
2. call和apply的区别#
-
call的第一个参数是this要指向的对象, 第二个,第三个....都是调用原函数所需要的参数。
-
apply第一个参数是this要指向的对象, 第二个参数是数组或类数组, 数组是放的是调用原函数所需要的参数。
3. bind 和 call/apply 有一个很重要的区别#
- 一个函数被 call/apply 的时候,会直接调用,但是 bind 会创建一个新函数, 不会直接调用
- 当这个新函数被调用时,bind() 的第一个参数将作为它运行时的 this, 新函数的调用和原来函数的调用一模一样,除了this的指向不一样之外
(七) 闭包及其作用#
(1) 闭包是什么, 闭包形成的原因(背诵)#
**闭包的概念:**闭包是指有权访问另一个函数作用域中的变量的函数,创建闭包最常用的方式就是在一个函数内部创建另一个函数(函数中的函数)。
简单概括: 闭包就是一个能访问另外一个函数内部变量的函数
- 是一个函数
- 能访问另外一个函数的内部变量
**闭包形成的原因:**函数内部的局部变量一般在函数运行结束的时候就会被销毁, 但如果局部变量因为被外部引用而导致没有被销毁, 就形成了闭包
闭包的特性:
闭包可以让我们在函数外部访问函数内部的变量
思考问题(1): 如何在函数外部访问函数内部变量#
// 1.在foo中返回goo函数
function foo() {
var name = "foo";
var desc = 'foo函数';
function goo() {
var name = "goo";
return desc;
}
return goo;
}
// 2.获取goo函数,赋值给fn
var fn = foo(); // fn就是goo
var desc = fn(); // 相当于goo();
// 上面两句也可以合并成一句
// var desc = foo()();
console.log('desc',desc);
思考问题(2): 为什么滥用闭包可能会引起内存泄漏#
- 一般情况下, 函数内部变量会在函数运行结束后被销毁
- 使用闭包的时候, 闭包相关的变量不会被回收, 所以滥用闭包可能会引起内存泄漏
使用闭包解决setTimeout问题#
一下代码的执行结果是5个5
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log(i);
}, 0)
}
使用闭包, 让以上代码输出想要结果0,1,2,4
for (var i = 0; i < 5; i++) {
(function (num) {
setTimeout(function () {
console.log(num);
}, num*1000);
})(i);
}
使用es6解决
for (let i = 0; i < 5; i++) {
setTimeout(function () {
console.log(i);
}, i * 1000);
}
(2) 闭包有哪些作用(背诵)#
或问: 闭包有哪些应用场景
- 封装私有变量(私有属性)
- 模仿块级作用域(ES5中没有块级作用域)
- 实现JS的模块
1.封装私有变量(私有属性)#
私有变量(私有属性)是后台语言经常用的东西, 意思是这个属性是私有的,不能随意更改,要改,必须通过指定的set和get方法进行获取和修改
function getCat() {
var _name = "小花";
// 获取_name
function get() {
return _name;
}
// 修改名字
function set(newName) {
_name = newName;
}
return {
get: get,
set: set,
};
}
var cat = getCat();
console.log(cat);
// 或取名字
var name = cat.get();
console.log('name',name);
// 修改
cat.set('小黑');
var name = cat.get();
console.log('name',name);
2.模仿块级作用域#
ES5中没有块级作用域, 模仿块级作用域的意思就是让变量只在{}内起作用
// 1.js没有块级作用域
// 3.使用闭包模拟块级作用: num只在 {}内有效
for (var i = 0; i < 5; i++) {
(function (num) {
setTimeout(function () {
console.log(num);
}, num*1000);
})(i);
}
3.实现JS的模块(js库)#
js模块, 比如axios.js 就是一个js的模块, axios提供了get,post等方法
(function(window) {
function get(url,data) {
// todo
}
function post(url,data) {
// todo
}
window.httpObj = {
get:get,
post:post
}
})(window);
使用闭包的注意点:#
由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题
(八) 深拷贝和浅拷贝#
概念和定义#
定义: 深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
**浅拷贝:**仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制出来的对象也会相应的改变。
**深拷贝:**在计算机中开辟一块新的内存地址用于存放复制的对象。
TIP
浅拷贝例子
浅拷贝只拷贝了对象的引用(内存地址), 当原对象发生了改变, 新对象也跟着发生改变, 因为它们都是指向了同一个对象
var money = {
bank:'平安银行',
count: 1000000
}
var money2 = money;
money.count = 100;
console.log(money2.count);
TIP
深拷贝: 只拷贝第一层
深拷贝分两种情况
- 只拷贝第一层
- 完全拷贝
1. 深拷贝方法 for in 的方法只能拷贝第一层#
var money = {
bank:'平安银行',
count: 1000000,
}
// 创建一个新对象
var money2 = {};
for(var key in money) {
money2[key] = money[key];
}
money.count = 1000;
console.log(money2.count);
使用for in只能拷贝第一层
var money = {
bank:'平安银行',
count: 1000000,
info: {
name: '张三',
age:20
}
}
// 创建一个新对象
var money2 = {};
for(var key in money) {
if(type of money[key] === 'object')
}
money.info.age = 30;
console.log(money2.info.age); // 修改了money的age,money2的age也发生了改变, 因为只拷贝了第一层

2. 使用es6的扩展运算符得到的对象也是只拷贝第一层#
var money = {
bank:'平安银行',
count: 1000000,
info: {
name: '张三',
age:20
}
}
// 得到一个新对象
var money2 = {
...money
}
money.info.age = 30;
console.log(money2.info.age);
TIP
完全拷贝
3. 使用JSON的提供api#
- JSON.stringify() 将对象转成json字符串
- JSON.parse() 将json字符串转成对象
var money = {
bank: '平安银行',
count: 1000000,
info: {
name: '张三',
age: 20,
addr: {
provice: '省份',
city: '深圳'
}
}
}
// 将对象转成json字符串
var str = JSON.stringify(money);
var money2 = JSON.parse(str);
// 修改money数据
money.info.name = '李四';
// 新对象money2不会发生改变, 因为money2和money完全没有关系
console.log(money2.info.name);
4. 函数递归调用#
for循环深拷贝
使用函数递归, 对所有引用数据类型的值进行复制,一直到到没有值是引用数据类型位置
其它方法:#
js浅拷贝与深拷贝的区别和实现方式 - 简书
(九) 严格模式'use strict'(了解)#
在代码中出现表达式-"use strict"; 意味着代码按照严格模式解析,这种模式使得Javascript在更严格的条件下运行。
好处:
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
坏处:
-
同样的代码,在"严格模式"中,可能会有不一样的运行结果;
普通模式下, this指向window
严格模式, this的值为undefined
-
一些在"正常模式"下可以运行的语句,在"严格模式"下将不能运行。
- 正常模式下声明变量缺少var会变成全局变量
- 严格模式下, 不允许这样做, 下面的代码会报错
"use strict" function say() { var a = 100; b = 200; } say(); console.log(b);
(十) 防抖和节流#
概念#
在前端开发的过程中,我们经常会需要绑定一些持续触发的事件,如滚动、输入等等,但有些时候我们并不希望在事件持续触发的过程中那么频繁地去执行函数,防抖和节流是比较好的解决方案。
(1)所谓防抖,就是指触发事件后在 n 秒内函数只能执行一次,如果在 n 秒内又触发了事件,则会重新计算函数执行时间。使用场景:注册的时候检查用户名是否已经被注册.
(2)所谓节流,就是指连续触发事件但是在 n 秒中只执行一次函数。节流会稀释函数的执行频率。使用场景:监听滚动条是否到了顶部或底部.
(1) 防抖例子#
Document