大数据—Hadoop之HDFS架构
HDFS架构
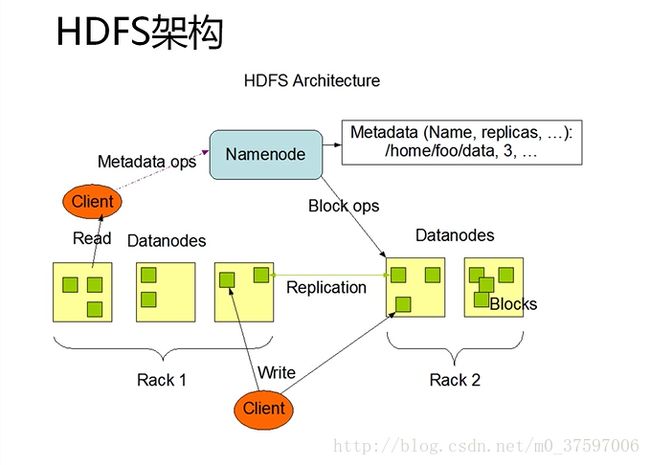
一、HDFS访问流程
读取数据操作:用户进行读取数据请求,首先传入Namenode数据块,Namenode将读写信息传给Client,再由Client根据Namenode所给的信息找到数据所在的Datanode,进行读取。
写入数据操作:用户进行写入数据请求,首先传入Namenode数据块,Namenode根据策略寻找出最合适的Datanode,并利用流返还给Client,再由Client找到Datanode,同时Datanode建立网络流将数据写到其本身,Datanode根据备份数在其他机架上将数据备份,最后将写入记录传给Namenode,Namenode将写入记录备份后,写入数据操作完成。
二、HDFS架构的组成
一个HDFS 文件系统包括一个主控节点NameNode和一组DataNode从节点。
1、Namenode
NameNode是一个主服务器,用来管理整个文件系统的命名空间和元数据,以及处理来自外界的文件访问请求。NameNode保存了文件系统的三种元数据:
1) 命名空间, 即整个分布式文件系统的目录结构;
2 ) 数据块与文件名的映射表;
3) 每个数据块副本的位置信息,每一个数据块默认有3个副本
Namenode作用:
①NameNode是用来管理文件系统命名空间的组件
②一个HDFS集群只有一台NameNode
一个HDFS集群只有一个命名空间,一个根目录
③NameNode上存放了HDFS的元数据
一个HDFS集群只有一份元数据
目前有单点故障的问题
④元数据保存在NameNode的内存当中,以便快速查询
1G内存大致可以存放1,000,000个块对应的元数据信息
按缺省每块64M计算,大致对应64T实际数据
2、Datanode
DataNode 用来实际存储和管理文件的数据块。
Datanode特点:
①文件中的每个数据块默认的大小为64MB。 同时为了防止数据丢失,每个数据块默认有3个副本,且3个副本会分别复制在不同的节点上,以避免一个节点失效造成一个数据块的彻底丢失。
②每个DataNode的数据实际上是存储在每个节点的本地Linux文件系统中。NameNode上可以执行文件操作,比如打开、关闭、重命名等;而NameNode也负责向DataNode分配数据块并建立数据块和DataNode的对应关系。
③DataNode负责处理文件系统用户具体的数据读写请求,同时也可以处理NameNode对数据块的创建、删除副本的指令。
④典型的部署模式采用NameNode单独运行于一台服务器节点上,其余的服务器节点,每一台运行一个DataNode。
Datanode的作用:
①块的实际数据存放在DataNode上。
②每个块会在本地文件系统产生两个文件,一个是实际的数据文件,另一个是块的附加信息文件,其中包括数据的校验和,生成时间。
③DataNode通过心跳包(Heartbeat)与NameNode通讯。
④客户端读取/写入数据的时候直接与DataNode通信。
三、数据块
数据块的描述:
①在传统的块存储介质中,块是读写的最小数据单位 (扇区)。
②传统文件系统基于存储块进行操作。为了节省文件分配表空间,会对物理存进行储块整般合,一般大小为4096字节。
③HDFS也使用了块的概念,但是默认大小设为64M字节。可针对每个文件配置,由客户端指定,每个块有一个自己的全局ID。
④HDFS将一个文件分为一个或数个块来存储。每个块是一个独立的存储单位,并以块为单位在集群服务器上分配存储。
⑤与传统文件系统不同的是,如果实际数据没有达到块大小,则并不实际占用磁盘空间。如果一个文件是200M,则它会被分为4个块: 64+64+64+8。
HDFS为什么使用数据块?
①当一个文件大于集群中任意一个磁盘的时候,文件系统可以充分利用集群中所有的磁盘。
②管理块使底层的存储子系统相对简单。
③块更加适合备份,从而为容错和高可用性的实现带来方便。
④最重要的是,采用块方式,实现了名字与位置的分离,实现了的存储位置的独立性。
四、读写策略
1、数据读取
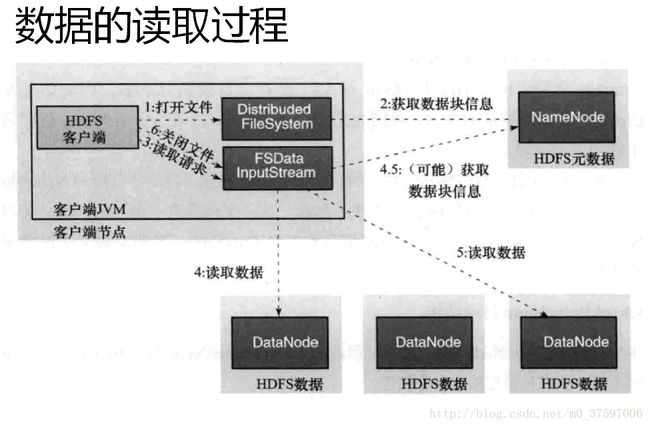
流程:
①客户端调用FileSystem实例的open方法,获得这个文件对应的输入流InputStream。
②通过RPC 远程调用NameNode,获得NameNode中此文件对应的数据块保存位置,包括这个文件的副本的保存位置(主要是各DataNode的地址)。
③获得输入流之后,客户端调用read方法读取数据。选择最近的DataNode建立连接并读取数据。
④如果客户端和其中一个DataNode位于同一机器(比如MapReduce过程中的mapper和reducer),那么就会直接从本地读取数据。
⑤到达数据块末端,关闭与这个DataNode的连接,然后重新查找下一个数据块。
⑥不断执行第2 - 5 步直到数据全部读完。
⑦客户端调用close ,关闭输入流DF S InputStream。
2、数据写入

流程:
①客户端调用FileSystem实例的create方法,创建文件。NameNode通过一些检查,比如文件是否存在,客户端是否拥有创建权限等;通过检查之后,在NameNode添加文件信息。注意,因为此时文件没有数据,所以NameNode上也没有文件数据块的信息。
②创建结束之后, HDFS会返回一个输出流DFSDataOutputStream给客户端。
③客户端调用输出流DFSDataOutputStream的write方法向HDFS中对应的文件写入数据。
④数据首先会被分包,这些分包会写人一个输出流的内部队列Data队列中,接收完数据分包,输出流DFSDataOutputStream会向NameNode申请保存文件和副本数据块的若干个DataNode,这若干个DataNode会形成一个数据传输管道。DFSDataOutputStream将数据传输给距离上最短的DataNode,这个DataNode接收到数据包之后会传给下一个DataNode。数据在各DataNode之间通过管道流动,而不是全部由输出流分发,以减少传输开销。
⑤因为各DataNode位于不同机器上,数据需要通过网络发送,所以,为了保证所有DataNode的数据都是准确的,接收到数据的DataNode要向发送者发送确认包(ACK Packet )。对于某个数据块,只有当DFSDataOutputStream收到了所有DataNode的正确ACK.才能确认传输结束。DFSDataOutputStream内部专门维护了一个等待ACK队列,这一队列保存已经进入管道传输数据、但是并未被完全确认的数据包。
⑥不断执行第3 - 5 步直到数据全部写完,客户端调用close关闭文件。
⑦DFSDataInputStream继续等待直到所有数据写人完毕并被确认,调用complete方法通知NameNode文件写入完成。NameNode接收到complete消息之后,等待相应数量的副本写入完毕后,告知客户端。