宽度学习系统相关变体
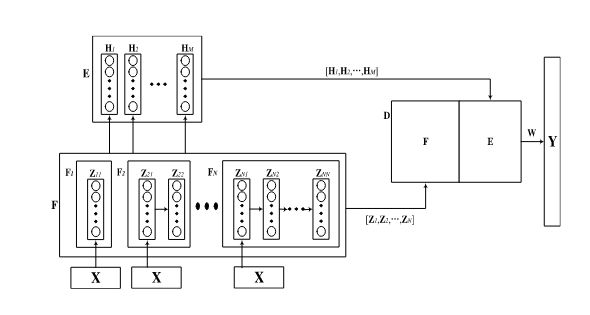
**1.Cascade of Feature Nodes in Pyramid Structure (CFBLSPyramid):**从不同深度提取的特征具有独特的语义信息,通过组合不同的特征可以获得更全面的结果。它不仅提取不同级别的特征,而且引入了输入数据的多特征提取,以减少随机误差。
在结构的第一层中,仅使用一组特征节点。然后,在每个后续层中,特征节点的数量都会增加。该结构的每一层都将一组特征节点一个接一个地级联。
特征节点 Z i j Z_{ij} Zij可以表示为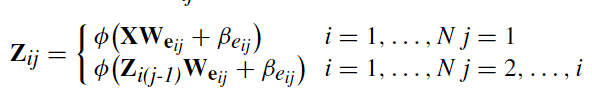
其中i表示金字塔的第i层,j表示第i层的第j个节点
所有特征节点 Z N ‘ = [ Z 11 , Z 21 , Z 22 , … , Z N N ] Z^{N^`}=[Z_{11},Z_{21},Z_{22},…,Z_{NN}] ZN‘=[Z11,Z21,Z22,…,ZNN],其中 N 丶 = N ( N + 1 ) / 2 N^丶=N(N+1)/2 N丶=N(N+1)/2可以被送到激活函数ζ中生成增强节点 H m = [ H 1 , H 2 , … , H m ] H^m=[H_1,H_2,…,H_m] Hm=[H1,H2,…,Hm],其中 H k = ζ ( Z N 丶 W h k + β h k ) H_k=ζ(Z^{N^丶}Wh_k+βh_k) Hk=ζ(ZN丶Whk+βhk),k=1,2,…,M。
最后,金字塔结构中特征节点级联的系统模型可以总结为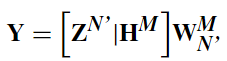
2.Cascade of Enhancement Nodes With Dropout (CEBLSDropout):
过度拟合是一个具有挑战性的问题,它使训练过程过于复杂,并在数据不足或噪声过大时导致较差的结果。不可避免的是,由于线性空间中由于扩展而产生的冗余,BLS可能会加剧过拟合。
”EEG emotion recognition using dynamical graph convolutional neural networks“提出了一种workout的技术,它可以有效地缓解过度拟合,并在深度学习研究中得到了广泛应用。
"Universal approximation capability of broad learning system and its structural variations“中提到的CEBLS比基线BLS网络性能更好。由于CEBLS是一个深级联结构网络,过拟合在这种结构中是不可避免的。因此,我们在CEBLS中引入dropout,以减轻过拟合造成的不利影响。
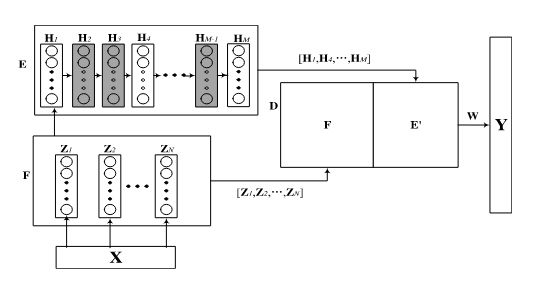
如图所示,并不是所有的增强节点都与输出连接,我们将少数增强节点的值设置为零。该网络的公式如下:
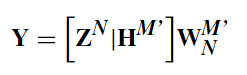
其中 Z N = [ Z 1 , Z 2 , … , Z N ] , H M = [ H 1 , H 2 , … , H M ] Z^N=[Z_1,Z_2,…,Z_N],H^M=[H_1,H_2,…,H_M] ZN=[Z1,Z2,…,ZN],HM=[H1,H2,…,HM]
3.Cascade of Feature Nodes With Dense Connection (CFBLSDense):
在该架构中,采用密集连接可以为每个特征节点提供由前一个节点提取的所有特征表示。
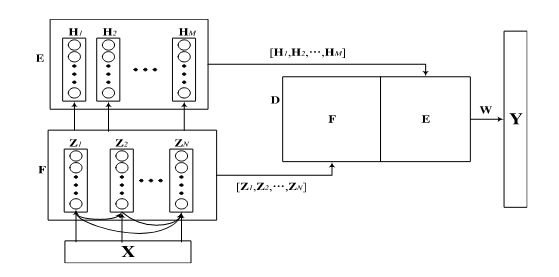
第一个特征节点与输入数据X连接
然后,第二特征节点与输入数据X和第一特征节点 Z 1 Z_1 Z1连接
第i特征节点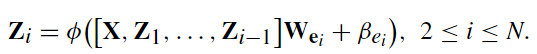
所以有增强节点的一般表示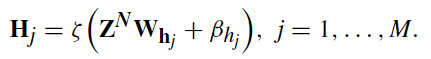
上述公式中 W h 和 β h W_h和β_h Wh和βh都是随机生成,所以节点 Z N = [ Z 1 , Z 2 , … , Z N ] , H M = [ H 1 , H 2 , … , H M ] Z^N=[Z_1,Z_2,…,Z_N],H^M=[H_1,H_2,…,H_M] ZN=[Z1,Z2,…,ZN],HM=[H1,H2,…,HM]与输出相连。
4.Cascade of Enhancement Nodes With Dense Connection (CEBLS-Dense):
与CFBLS密集节点一样,CEBLS密集中的增强节点也采用密集连接。我们将CEBLS密集中的增强节点划分为M个模块,每个模块包含M个增强节点。每个模块的第一个增强节点的输入由之前模块中的所有特征节点和最后一个增强节点组成,这种结构将增强节点的模块一个接一个地级联。此外,只有每个模块的最后一个节点被馈送到输出中。显然,冗余通常发生在BLS的增强部分,因此CEBLS密集可以有效地避免过拟合。

如图所示,特征节点与输入X相连,它们由以下方程生成:
![]()
对于增强节点, H i j H_{ij} Hij可以表示为

W h 和 β h W_h和β_h Wh和βh都是随机生成
为了避免过拟合,并非所有增强节点都与输出相连接。在该模型中,我们为每个模块选择一个增强节点。因此,输出数据与特征节点和M个增强节点相连。与输出相连的增强节点可以表示为 H M = [ H 1 m , H 2 m , … , H M m ] H^M=[H_{1m},H_{2m},…,H_{Mm}] HM=[H1m,H2m,…,HMm]
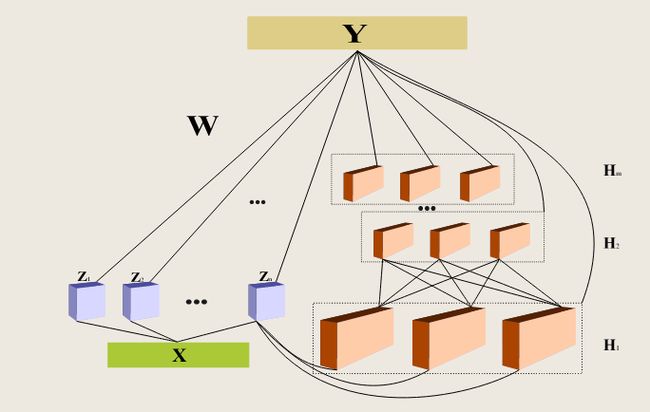
5.Broad Learning Systems: Cascade of Feature Mapping Nodes (CFBLS):
该体系结构将一组特征映射节点级联在一起。如图所示,特征映射节点 Z 1 , Z 2 , … , Z n Z_1,Z_2,…,Z_n Z1,Z2,…,Zn形成级联连接。

因此,对于输入数据X,第一组特征映射节点 Z 1 Z_1 Z1表示为
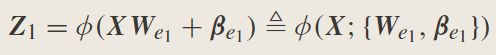
对于第二组,特征映射节点, Z 2 Z_2 Z2是使用 Z 1 Z_1 Z1个节点的输出来建立的;因此, Z 2 Z_2 Z2表示为
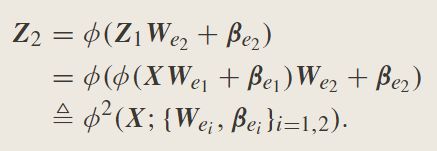
连续使用相同的过程,所有n组特征映射节点被公式化为
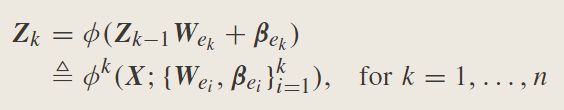
Z N = [ Z 1 , Z 2 , … , Z N ] Z^N=[Z_1,Z_2,…,Z_N] ZN=[Z1,Z2,…,ZN],增强节点可以表示为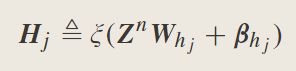
最后,假设网络由n组特征节点和m组增强节点组成,该特征节点BLS级联的系统模型总结如下:

其中 H M = [ H 1 , H 2 , … , H M ] , W n m H^M=[H_1,H_2,…,H_M],W_n^m HM=[H1,H2,…,HM],Wnm是通过 [ Z n ∣ H m ] [Z^n|H^m] [Zn∣Hm]的伪逆计算得来。
6.Broad Learning Systems: Cascade of Feature Mapping Nodes With Its Last Group Connects to the Enhancement Nodes (LCFBLS) or Recurrent Feature Nodes:
仅将最后一组特征映射节点与增强节点连接。


通常,特征映射的级联类似于递归系统的定义,它在对序列数据建模时非常有效。递归结构非常适合本文档理解和处理输入中的时序信息的时间序列处理。
递归信息可以在特征节点中建模为如下的递归特征节点,以便学习顺序信息


在递归模型中,每个 Z k Z_k Zk都是在先前的特征 Z k − 1 Z_{k-1} Zk−1和输入X下同时计算的。基于该变体,可以构建复发性BLS和长短期记忆BLS。
7.Broad Learning Systems: Cascade of Enhancement Nodes (CEBLS) or Recurrent Enhancement Nodes:
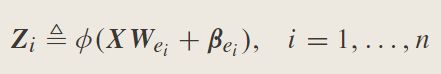
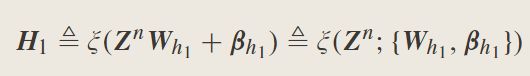
其中, Z N = [ Z 1 , Z 2 , … , Z N ] Z^N=[Z_1,Z_2,…,Z_N] ZN=[Z1,Z2,…,ZN]
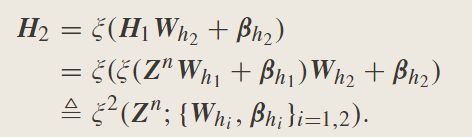
此外,前m组增强节点是
因此,节点 Z n Z^n Zn和 H M = [ H 1 , H 2 , … , H M ] H^M=[H_1,H_2,…,H_M] HM=[H1,H2,…,HM]与输出直接连接,并且修改后的BLS为
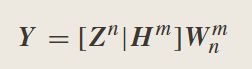
W n m W_n^m Wnm是通过 [ Z n ∣ H m ] [Z^n|H^m] [Zn∣Hm]的伪逆计算得来。
8.Broad Learning Systems: Cascade of Feature Mapping Nodes and Enhancement Nodes (CFEBLS):

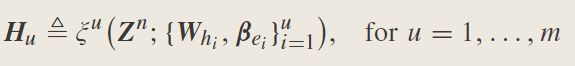
网络公式化
其中

9.Broad Learning Systems: Composite Model Versus Wide and Deep Learning:
10.Broad Learning Systems: Cascade of Convolution Feature Mapping Nodes (CCFBLS):

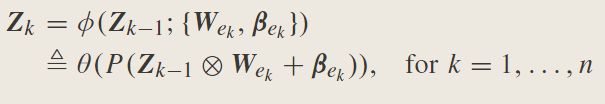

Fuzzy Model in the Feature Nodes: Fuzzy Broad Learning System:
Takagi-Sugeno(TS)模糊系统可以合并到BLS中,形成模糊BLS。模糊BLS将BLS的特征节点替换为一组TS模糊子系统。特征节点中每个模糊子系统产生的模糊规则的输出被发送到增强层进行进一步的非线性变换,以保持输入的特性。模糊BLS的详细信息可以在文献[24]中找到。