Spark 弹性分布数据集RDD的介绍
一、弹性分布数据集RDD
RDD(Resilient Distributed Dataset)叫做弹性分布数据集,它是整个Spark中最基本的数据抽象,它代表一个不可变,可分区,里面元素可以并行计算集合,RDD具有数据流模型的一些特点:自动容错,位置感知调度可伸缩性,RDD允许用户在执行多查询的时候显示的将工作集缓存在内存中,后续的查询能够重用这个工作集,极大地提高查询效率
1.1 RDD的弹性体现
1.存储的弹性: 内存和磁盘的
2.自动切换容错弹性: 数据可以丢失
3.自动恢复计算弹性:计算出错重试机制
4.分片弹性: 根据需要重新分片
1.2 RDD的五大特征
1.RDD可以看做是一些列的Partition所组成的
2.RDD之间存在依赖关系
3.算子是作用在Partition之上 4分区器是作用在kv形式的RDD上
5.Partition提供是最佳计算位置,利于数据从本地化计算,移动计算不是移动数据
1.3 RDD编程API
RDD的两种算子:转换算子(Transformation)、行动算子(Action)
- Transformation算子
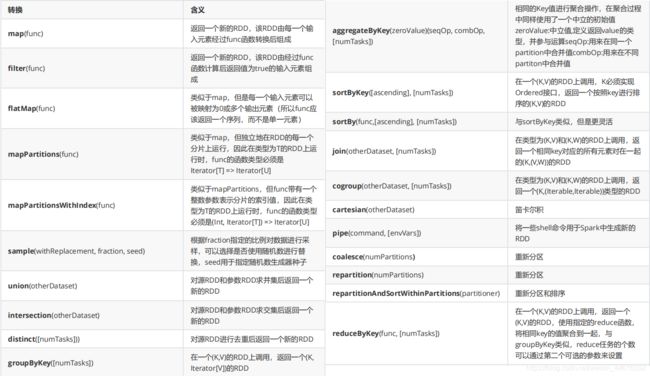
- Action算子

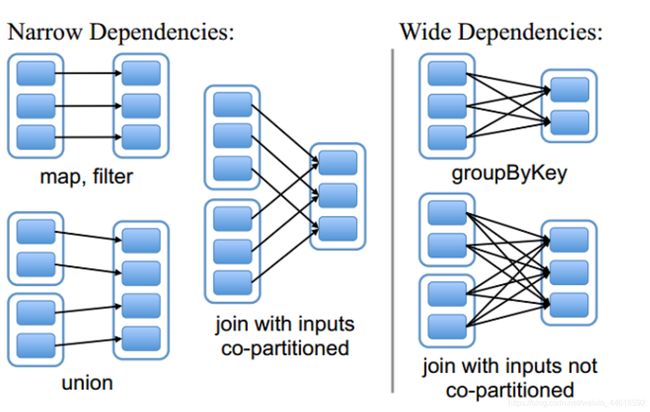
1.4 RDD间的依赖关系
窄依赖 窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
宽依赖 宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,宽依赖会发生shuffle
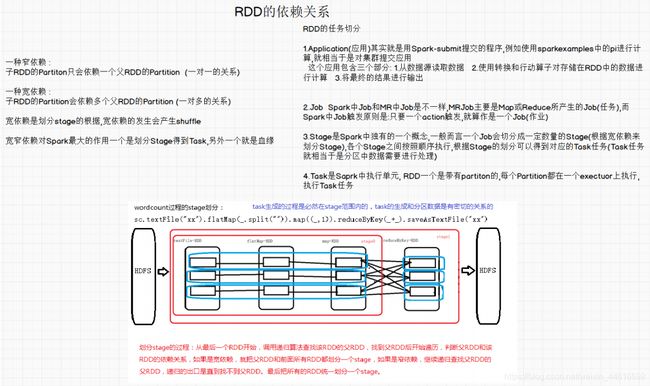
1.5 大数RDD的缓存(持久化)
使用到reduceByKey这个算子时,会发生shuffle,发生shuffle就需要使用大量的资源,如果计算shuffle之后的RDD中分区丢失,此时重新计算的成本就会过大,Spark提供cache即缓存用来解决这类问题
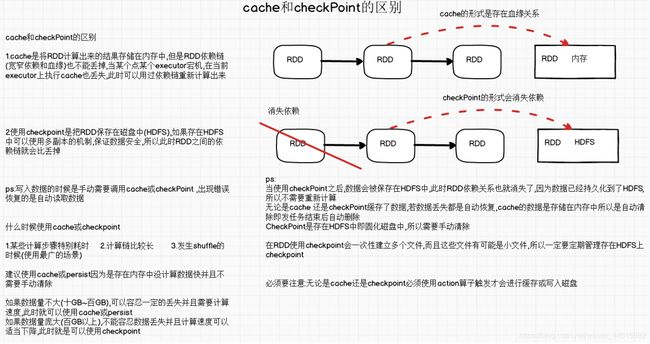
Checkpoint 检查点
Cache缓存
可以将前面计算的结果进行缓存,但是不是这两方法被调用时立即缓存而是用过触发后面行动算子时,该RDD将会被缓存到计算节点的内存中,并提供后续重用
1.6 键值对RDD的分区
HashPartitioner
Spark中非常重要的一个分区器,也是默认分区器,默认90%以上的RDD相关API都是用了这个分区器功能: 依据RDD中key值的Hashcode 跟分区数取余得到当前key值所对应分区值(分区ID)
HashPartitioner支持key值null,此时分区器会将key值为null直接分配给0分区
ps: 分区数是从0开始(0是第一分区) 到 numPartitions-1 结束
RangePartitioner(Range分区是通过水塘抽样的算法来将数据均匀的分配到各个分区中)
主要用于RDD的数据排序相关API中比如sortByKey底层使用的数据分区器就是RangePartitioner
分区器sortByKey底层使用的数据分区器就是RangePartitioner分区器;
该分区器的实现方式主要是通过两个步骤来实现的:
第一步:先重整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;
该分区器要求RDD中的KEY类型必须是可以排序
自定义分区
继承 Partitioner 类,并实现两个方法:
def numPartitions:Int --> 获取到当前的分区个数
def getPartition(key:Any):Int --> 根据传入有key值来获取对应的分区号(分区ID)
Spark内部的分区器不能满足需求,此时就可以提供我们自定义分区了
1.7 累加器
作用:
1.可以作为调试工具,能够观察每个task的信息通过累加器在sparkUI上观察task所处理的记录
2.能够精准的统计数据的各种值:2.1ETL数据清洗,使用累加器进行数据统计(清洗字段的总数)
2.2可以同时浏览userID的记录,在同一个时间段内产生多少次购买
2. Broadcast广播变量
广播变量是用来高效分发较大的数据,向所有的worker发送一个较大的只读值,以提供一个或多个spark进行操作
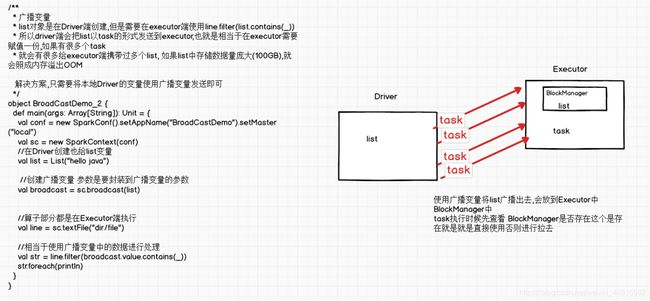
广播变量的过程如下:
- 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
- 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
- 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
RDD、DataFrame & Dataset 的区别与联系
共性:
Ø RDD、DataFrame、Dataset都是spark平台下的分布式弹性数据集
Ø 三者都有惰性机制。在进行创建、转换时,不会立即执行;只有在遇到Action时,才会开始遍历运算。如果代码里面仅有创建、转换,后面没有任何Action算子,代码不会执行;
Ø 三者都有partition的概念,进行缓存操作、还可以进行检查点操作;
Ø 三者有许多相似的函数,如map、filter,排序等;
Ø 在对DataFrame和Dataset进行操作时,很多情况下需要 spark.implicits._ 进行支持;
区别:
Ø DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值;
Ø DataFrame与Dataset均支持spark sql的操作,比如select,groupBy之类,还能注册临时视图,进行sql语句操作;
Ø DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然;
RDD、DataFrame &Dataset(DataFrame 是DateSet的特例)本身是不会存储数据的,真正存储数据的是Excution里的每个分区。DataFrame =DateSet[row]
DataFrame也是懒执行,性能要比RDD要高,主要有两个原因
相关文章:
Spark的运行模式及 Standalone模式的运行流程
Spark的内存模型以及Spark Shuffle的原理
常见的Spark的调优方法
有收获?希望烙铁们来个三连击,让更多的同学看到这篇文章
1、烙铁们,关注我看完保证有所收获,不信你打我。
2、点个赞呗,可以让更多的人看到这篇文章,后续还会有很哇塞的产出。
本文章仅供学习及个人复习使用,如需转载请标明转载出处,如有错漏欢迎指出
务必注明来源(注明: 来源:csdn , 作者:-马什么梅-)