史上最全云原生全景图解读攻略
带你了解云原生技术图谱
如果你研究过云原生应用程序和相关技术,大概率你遇到过 CNCF 的云原生全景图。这张全景图技术之多、规模之大无疑会让人感到震惊,那么我们该如何去理解这张图呢?
如果把它拆开来,一次只分析一小块内容,你会发现整个全景图没有那么复杂。事实上,该全景图按照功能有序地组织在一起,一旦你了解了每个类别代表的内容,你就可以轻松游走于全景图中。本文我们首先把整个全景图拆解开来,并对整个全景图进行综述,接着聚焦在每一层(or 每一列),对每个类别解决的问题和原理进行了更为详细的解读。

1. 云原生全景图的 4 层
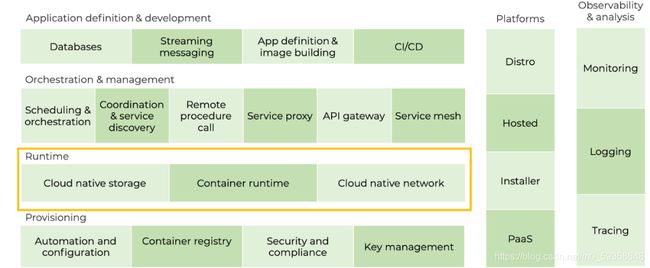
首先,我们剥离掉所有单个的技术,仅查看类别(如下图)。图中有不同的“行”,像建筑的不同层,每层都有自己的子类别。最底层提供了构建云原生基础设施的工具。往上,你可以开始添加运行和管理应用程序所需的工具,比如运行时和调度层。在最上层,有定义和开发应用程序的工具,比如数据库、镜像构建和 CI/CD 工具(我们将在后文讨论)。
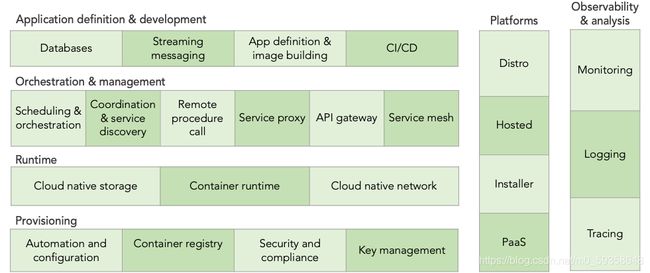
好了,现在你应该记住了云原生全景图始于基础设施,往上的每一层都更接近实际的应用程序。这就是每层代表的意思(后面我们会讨论上图右边的两“列”)。下面我们就从最底层开始,逐层进行解析。
1)供应层 (Provisioning)
供应指的是为云原生应用准备标准基础环境所涉及的工具。它包含了基础设施的创建、管理、配置流程的自动化,以及容器镜像的扫描、签名和存储等。供应层通过提供设置和实施策略,在应用程序和平台中构建身份验证和授权,以及处理密钥分发等等的工具,也拓展到了安全领域。供应层包括:
-
自动化和部署工具:帮助工程师在无需人工干预情况下即可构建计算环境;
-
容器注册表:存储应用程序的可执行文件;
-
不同安全领域的安全和合规框架;密钥管理解决方案:通过加密确保只有授权的用户才能访问特定的应用程序。
-
这些工具使工程师可以编写基础设施参数,使系统可以按需搭建新环境,确保了一致性和安全性。
2)运行时层(Runtime)
接下来是运行时层。这个词可能会让你感到迷惑。像很多 IT 术语一样,运行时没有严格的定义,且可以根据语境有不同的用法。狭义上讲,运行时是特定机器上准备运行应用程序的沙盒——也就是保障应用程序正常运行所需的最低配置。广义上讲,运行时是运行一个应用程序所需的所有工具。在 CNCF 云原生全景图中,运行时保障了容器化应用程序组件的运行和通信, 包括:
-
云原生存储:为容器化应用提供虚拟磁盘或持久化存储;
-
容器运行时:为容器提供隔离、资源和安全;
-
云网络:分布式系统的节点(机器或进程)通过其连接和通信。
3)编排和管理层(Orchestration and Management)
一旦按照安全和合规性标准(供应层)自动化基础设施供应,并安装了应用程序运行所需的工具(运行时层),工程师就需要弄清楚如何编排和管理应用程序。编排和管理层将所有容器化服务(应用程序组件)作为一个群组管理。这些容器化服务需要相互识别和通信,并需要进行协调。这一层可为云原生应用提供自动化和弹性能力,使云原生应用天然具有可扩展性。这一层包含:
-
编排和调度:部署和管理容器集群,确保它们具有弹性伸缩能力,相互之间低耦合,并且可扩展。事实上,编排工具(绝大多数情况下就是 Kubernetes)通过管理容器和操作环境构成了集群;
-
协调和服务发现:使得服务(应用程序组件)之间可以相互定位和通信;
-
远程进程调用(RPC):使跨节点服务间通信的技术;
-
服务代理:服务间通信的中介。服务代理的唯一目的就是对服务之间的通信进行更多控制,而不会对通信本身添加任何内容。服务代理对下面将提到的服务网格(Service Mesh)至关重要。
-
API 网关:一个抽象层,外部应用可通过 API 网关进行通信;
-
Service Mesh:某种程度上类似于 API 网关,它是应用程序进行通信的专用基础架构层,提供基于策略的内部服务间通信。此外,它还可能包含流量加密、服务发现、应用程序监控等内容。
4)应用定义和开发层 (Application Definition and Developement)
现在,我们来到了最顶层。应用定义和开发层,顾名思义,聚集了让工程师构建和运行应用程序的工具。上述所有内容都是关于构建可靠、安全的环境,以及提供全部所需的应用程序依赖。这一层包括:
-
数据库:使应用程序能以有序的方式收集数据;
-
流和消息传递:使应用程序能发送和接收消息(事件和流)。它不是网络层,而是让消息成为队列并处理消息的工具;
-
应用程序定义和镜像构建:用于配置、维护和运行容器镜像(应用程序的可执行文件)的服务;
-
持续集成和持续交付(CI/CD):使开发者可自动测试代码是否与代码库(应用程序的其余部分)兼容。如果团队足够成熟,甚至可以自动部署代码到生产环境。
2. 贯穿所有层的工具
接下来我们将进入到云原生全景图右侧贯穿所有层的两列。可观察性和分析(Observability&analysis)是监控各层的工具,平台则将各层中不同的技术捆绑为一个解决方案。
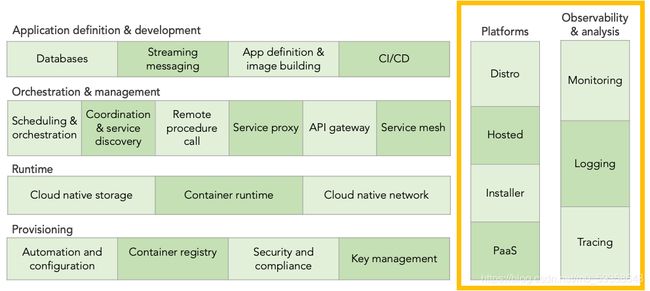
1)可观察性和分析(Observability and Analysis)
为了限制服务中断并降低解决问题的平均时间(MRRT),你需要监控和分析应用层序的方方面面,以便在出现异常时可立即发现并纠正。复杂环境中容易出现故障,这些工具可快速识别并解决故障,从而降低故障带来的影响。由于这一类别贯穿并监控各层,因此它在侧面,而不是嵌入到某一层中。这一类别你将发现:
-
日志工具:收集事件日志(有关进程的信息);
-
监控方案:收集指标(以数字表示的系统参数,例如 RAM 可用性);
-
追踪工具:追踪比监控更进了一步,它们监控用户请求的传播,与服务网格相关。
-
混沌工程(Chaos Engineering):在生产环境中测试软件的工具,可识别缺陷并进行修复,减少其对服务交付的影响。
2)平台类(Platform)
可以看到,图中每一个模块解决一个特定的问题。但我们知道,仅有存储并不能提供应用程序所需的全部功能。你还需要编排工具、容器运行时、服务发现、网络和 API 网关等等。平台覆盖多层,将不同的工具组合在一起,以解决更大的问题。配置和微调不同的模块使其安全可靠,并确保它利用的技术都能及时更新、所有漏洞都打了补丁,这并不是一件容易的事情。使用平台时,用户不用额外担心这些细节问题。你可能会注意到,所有的类别都围绕着 Kubernetes 展开。这是因为 Kubernetes 虽然只是云原生景观图这张拼图中的一块,但它却是云原生技术栈的核心。顺便说一下,CNCF 刚创建时,Kubernetes 就是其中的第一个种子项目,后来才有了其他项目。平台可分为四类:
-
K8s 发行版:采用未经修改的开放源代码(尽管有人对其进行了修改),并根据市场需要增加了其他功能。
-
托管的 K8s:类似于 Kubernetes 发行版,但是由提供商托管。
-
K8s 安装程序:自动执行 Kubernetes 的安装和配置过程。
-
PaaS / 容器服务:类似于托管的 Kubernetes,但是包含了一套更广泛的应用部署工具(通常是来自云原生景观图)。
3. 小结
在每个类别中,针对相同或相似的问题,都有不同的工具可选择。有一些是适用于新现实的预云原生技术,还有一些则是全新的。区别在于它们的实现和设计方法。没有完美的技术符合你的所有需求。大多数情况下,技术受设计和架构选择的限制——始终需要权衡取舍。在选择技术栈时,工程师必须仔细考虑每种能力和需要权衡取舍的地方,以确定最合适的选项。虽然这样会让情况变得更复杂,但在选择应用程序所需的最适合的数据存储、基础设施管理、消息系统等方案时,这样做是最可行的办法。现在,构建一个系统比云原生之前的时代容易多了。如果构建恰当,云原生技术将提供更强大的灵活性。在现如今快速变化的技术生态中,这可能是最重要的能力之一。下面我们来详细介绍云原生全景图的每一层。
供应层
云原生全景图的最底层是供应层(provisioning)。这一层包含构建云原生基础设施的工具,如基础设施的创建、管理、配置流程的自动化,以及容器镜像的扫描、签名和存储等。供应层也跟安全相关,该层中的一些工具可用于设置和实施策略,将身份验证和授权内置到应用程序和平台中,以及处理 secret 分发等。
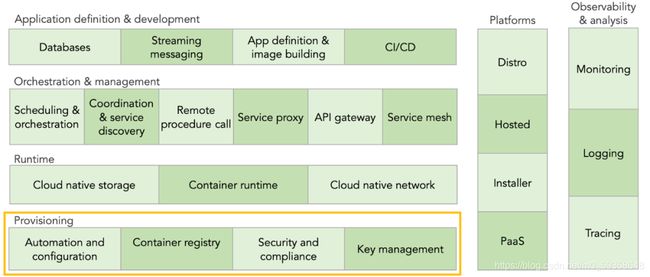
接下来让我们看一下供应层的每个类别,它所扮演的角色以及这些技术如何帮助应用程序适应新的云原生环境。
1. 自动化和配置
1)是什么
自动化和配置工具可加快计算资源(虚拟机、网络、防火墙规则、负载均衡器等)的创建和配置过程。这些工具可以处理基础设施构建过程中不同部分的内容,大多数工具都可与该空间中其他项目和产品集成。
2)解决的问题
传统上,IT 流程依赖高强度的手动发布过程,周期冗长,通常可达 3-6 个月。这些周期伴随着许多人工流程和管控,让生产环境的变更非常缓慢。这种缓慢的发布周期和静态的环境与云原生开发不匹配。为了缩短开发周期,必须动态配置基础设施且无需人工干预。
3)如何解决问题
供应层的这些工具使工程师无需人工干预即可构建计算环境。通过代码化环境设置,只需点击按钮即可实现环境配置。手动设置容易出错,但是一旦进行了编码,环境创建就会与所需的确切状态相匹配,这是一个巨大的优势。尽管不同工具实现的方法不同,但它们都是通过自动化来简化配置资源过程中的人工操作。
4)对应工具
当我们从老式的人工驱动构建方式过渡到云环境所需的按需扩展模式时,会发现以前的模式和工具已经无法满足需求,组织也无法维持一个需要创建、配置和管理服务器的 7×24 员工队伍。Terraform 之类的自动化工具减少了扩展数服务器和相关网络以及防火墙规则所需的工作量。Puppet、Chef 和 Ansible 之类的工具可以在服务器和应用程序启动时以编程方式配置它们,并允许开发人员使用它们。一些工具直接与 AWS 或 vSphere 等平台提供的基础设施 API 进行交互,还有一些工具则侧重于配置单个计算机以使其成为 Kubernetes 集群的一部分。Chef 和 Terraform 这类的工具可以进行互操作以配置环境。OpenStack 这类工具可提供 IaaS 环境让其他工具使用。从根本上讲,在这一层,你需要一个或多个工具来为 Kubernetes 集群搭建计算环境、CPU、内存、存储和网络。此外,你还需要其中的一些工具来创建和管理 Kubernetes 集群本身。在撰写本文时,该领域中有三个 CNCF 项目:KubeEdge(一个沙盒项目)以及 Kubespray 和 Kops(后两个是 Kubernetes 子项目,虽然未在全景图中列出,但它们也属于 CNCF)。此类别中的大多数工具都提供开源和付费版本。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直


2. Container Registry
1)是什么
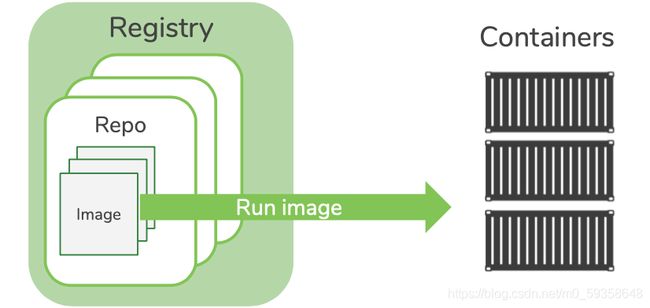
在定义 Container Registry 之前,我们首先讨论三个紧密相关的概念:
-
容器是执行流程的一组技术约束。容器内启动的进程会相信它们正在自己的专用计算机上运行,而不是在与其他进程(类似于虚拟机)共享的计算机上运行。简而言之,容器可以使你在任何环境中都能控制自己的代码运行。
-
镜像是运行容器及其过程所需的一组存档文件。你可以将其视为模板的一种形式,可以在其上创建无限数量的容器。
-
仓库是存储镜像的空间。
回到 Container Registry,这是分类和存储仓库的专用 Web 应用程序。镜像包含执行程序(在容器内)所需的信息,并存储在仓库中,仓库被分类和分组。构建、运行和管理容器的工具需要访问(通过引用仓库)这些镜像。
2)解决的问题
云原生应用程序被打包后以容器的方式运行。Container Registry 负责存储和提供这些容器镜像。
3)如何解决
通过在一个地方集中存储所有容器镜像,这些容器镜像可以很容易地被应用程序的开发者访问。
4)对应工具
Container Registry 要么存储和分发镜像,要么以某种方式增强现有仓库。本质上,它是一种 Web API,允许容器引擎存储和检索镜像。许多 Container Registry 提供接口,使容器扫描/签名工具来增强所存储镜像的安全性。有些 Container Registry 能以特别有效的方式分发或复制图像。任何使用容器的环境都需要使用一个或多个仓库。该空间中的工具可以提供集成功能,以扫描、签名和检查它们存储的镜像。在撰写本文时,Dragonfly 和 Harbor 是该领域中的 CNCF 项目,而 Harbor 最近成为了第一个遵循 OCI 的仓库。主要的云提供商都提供自己的托管仓库,其他仓库可以独立部署,也可以通过 Helm 之类的工具直接部署到 Kubernetes 集群中。

3. 安全和合规
1)是什么
云原生应用程序的目标是快速迭代。为了定期发布代码,必须确保代码和操作环境是安全的,并且只能由获得授权的工程师访问。这一部分的工具和项目可以用安全的方式创建和运行现代应用程序。
2)解决什么问题
这些工具和项目可为平台和应用程序加强、监控和实施安全性。它们使你能在容器和 Kubernetes 环境中设置策略(用于合规性),深入了解存在的漏洞,捕获错误配置,并加固容器和集群。
3)如何解决
为了安全地运行容器,必须对其进行扫描以查找已知漏洞,并对其进行签名以确保它们未被篡改。Kubernetes 默认的访问控制比较宽松,对于想攻击系统的人来说, Kubernetes 集群很容易成为目标。该空间中的工具和项目有助于增强群集,并在系统运行异常时提供工具来检测。
4)对应工具
为了在动态、快速发展的环境中安全运行,我们必须将安全性视为平台和应用程序开发生命周期的一部分。这部分的工具种类繁多,可解决安全领域不同方面的问题。大多数工具属于以下类别:
-
审计和合规
-
生产环境强化工具的路径
-
代码扫描
-
漏洞扫描
-
镜像签名
-
策略制定和执行
-
网络层安全
其中的一些工具和项目很少会被直接使用。例如 Trivy、Claire 和 Notary,它们会被 Registry 或其他扫描工具所利用。还有一些工具是现代应用程序平台的关键强化组件,例如 Falco 或 Open Policy Agent(OPA)。该领域有许多成熟的供应商提供解决方案,也有很多创业公司的业务是把 Kubernetes 原生框架推向市场。在撰写本文时,Falco、Notary/TUF 和 OPA 是该领域中仅有的 CNCF 项目。

4. 密钥和身份管理
1)是什么
在进入到密钥管理之前,我们首先定义一下密钥。密钥是用于加密或签名数据的字符串。和现实中的钥匙一样,密钥锁定(加密)数据,只有拥有正确密钥的人才能解锁(解密)数据。随着应用程序和操作开始适应新的云原生环境,安全工具也在不断发展以满足新的需求。此类别中的工具和项目可用于安全地存储密码和其他 secrets(例如 API 密钥,加密密钥等敏感数据)、从微服务环境中安全删除密码和 secret 等。
2)解决的问题
云原生环境是高度动态的,需要完全编程(无人参与)和自动化的按需 secret 分发。应用程序还必须知道给定的请求是否来自有效来源(身份验证),以及该请求是否有权执行操作(授权)。通常将其称为 AuthN 和 AuthZ。
3)如何解决
每个工具或项目实施的方法不同,但他们都提供:
-
安全分发 secret 或密钥的方法。
-
身份认证或(和)授权的服务或规范。
4)对应的工具
此类别中的工具可以分为两组:
-
一些工具专注于密钥生成、存储、管理和轮转。
-
另一些专注于单点登录和身份管理。
拿 Vault 来说,它是一个通用的密钥管理工具,可管理不同类型的密钥。而 Keycloak 则是一个身份代理工具,可用于管理不同服务的访问密钥。在撰写本文时,SPIFFE/SPIRE 是该领域中唯一的 CNCF 项目。

供应层专注于构建云原生平台和应用程序的基础,其中的工具涉及基础设施供应、容器注册表以及安全性。本章节详细介绍了云原生全景图的最底层。
运行时层
本章节我们将一起了解运行时层(runtime),这一层包含了容器在云原生环境中运行所需的一切。即:启动容器的代码,也叫运行时引擎;使容器获得持久化存储的工具;以及管理容器环境网络的工具。
但是注意,不要将这一层的资源与基础设施和供应层的网络和存储弄混淆,后者的工作是让容器平台运行起来。容器直接使用运行时层的工具来启动或停止,存储数据,以及相互通信。
1. 云原生存储
1)是什么
存储是存放一个应用程序持久数据的地方,也叫做持久卷(persistent volume)。轻松访问持久卷对于应用程序可靠运行至关重要。通常,当我们说持久数据的时候,我们是指数据库、消息之类的,或其他任何在应用重新启动时不会丢失的信息。
2)解决的问题
云原生架构具有高度的灵活性和弹性,这使得重启应用时存储持久数据变得很有挑战性。容器化应用程序在扩容、缩容或自动恢复时,会不断地创建或删除实例,并随着时间改变物理位置。因此,必须以与节点无关的方式提供云原生存储。但是,要存储数据,就需要硬件(具体来说是磁盘)。磁盘和其他硬件一样,受到基础设施的限制。这是第一个大的挑战。第二个挑战是存储接口。该接口在数据中心之间可能会发生很大的变化(在以前,不同的基础设施都有自己的存储解决方案,并带有自己的接口),这使得可移植性变得非常困难。最后,由于云的弹性,存储必须以自动化方式进行配置,因为手动配置和自动扩展不兼容。面临以上这些问题,云原生存储就是为新的云原生环境量身定制的。
3)如何解决
该类别的工具可以:
-
为容器提供云原生存储选项;
-
标准化容器与存储提供者之间的接口;
-
通过备份和还原操作提供数据保护。
云原生存储意味着使用兼容云原生环境的容器存储接口(也就是下一个类别中的工具),并且可以自动配置,通过消除人力瓶颈从而实现了自动扩展和自我恢复。
4)对应工具
容器存储接口(CSI)在很大程度上使云原生存储变成了可能。CSI 允许使用标准 API 向容器提供文件和块存储。该领域中有很多工具,既有开源的也有供应商提供的,都可利用 CSI 为容器提供按需存储。除了这一及其重要的功能,还有一些其他的工具和技术旨在解决云原生空间中的存储问题。Minio 是一个受欢迎的项目,它提供了兼容 S3 的 API 用于对象存储。Velero 之类的工具可帮助简化 Kubernetes 集群本身以及应用程序使用的持久化数据的备份和还原过程。


2. 容器运行时
1)是什么
前面我们提到过,容器是一组用于执行应用程序的技术约束。容器化的应用程序相信自己正在专用计算机上运行,而忽略了它们其实是与其他进程(类似于虚拟机)共享资源。容器运行时是执行容器化(或“隔离”)应用的软件。如果没有运行时,将只有容器镜像——指定容器化应用程序外观的文件。运行时将在容器中启动应用程序,并为其提供所需的资源。
2)解决的问题
容器镜像(带有应用程序规范的文件)必须以标准化、安全和隔离的方式启动:
-
标准化:无论它们在何处运行,都需要标准操作规则;
-
安全:访问权限应该要注意设置;
-
隔离:该应用程序不应影响其他应用程序或受到其他应用程序的影响(例如,位于同一位置的应用程序崩溃)。隔离基本上起到保护作用。
此外,必须为应用程序提供 CPU、存储、内存等资源。
3)如何解决
容器运行时可以完成所有这些工作。它以标准化方式在所有环境中启动应用程序,并设置安全边界。安全边界是运行时和其他工具不同的地方,CRI-O 或 gVisor 等运行时强化了它们的安全性边界。运行时还为容器设置资源限制。没有资源限制,应用程序可能会根据需要消耗资源,这样就有可能占用其他应用程序的资源。因此设置资源限制是很必要的。
4)对应的工具
不是所有此类别中的工具都一样。Containerd(Docker 产品的一部分)和 CRI-O 是标准的容器运行时实现。有一些工具可以将容器的使用扩展到其他技术,例如 Kata,它允许将容器作为 VM 运行。其他工具旨在解决与容器相关的特定问题,例如 gVisor,它在容器和 OS 之间提供了额外的安全层。


3. 云原生网络
1)是什么
容器通过云原生网络实现相互之间及和基础设施层之间的通信。分布式应用程序具有多个组件,这些组件将网络用于不同目的。此类别中的工具将虚拟网络覆盖在现有网络之上,专门用于应用程序进行通信,称为覆盖网络(overlay network)。
2)解决什么问题
通常我们将在容器中运行的代码称为应用程序,但实际上,大多数容器中仅包含大型应用程序的一小部分特定功能。诸如 Netflix 或 Gmail 之类的现代应用程序实际上由许多较小的组件组成,每个组件都在自己的容器中运行。为了使所有这些独立的部分正常运行组成一个完整的应用,容器之间需要相互通信。此类别的工具就提供该专用通信网络。此外,这些容器之间交换的消息可能是私密的、敏感的或者非常重要的。这导致了其他要求:例如为各种组件提供隔离,检查流量以识别网络问题的能力。在某些情况下,可能还需要拓展这些网络及网络策略(如防火墙和访问规则),以便应用程序可以连接到容器网络外部运行的 VM 或服务。
3)如何解决
此类别中的项目和产品使用 CNCF 中的项目——容器网络接口(Container Network Interface, CNI)为容器化应用提供网络功能。某些工具(例如 Flannel)仅为容器提供基本连接。其他工具(如 NSX-T)提供了完整的软件定义网络层,可为每个 Kubernetes 名称空间创建一个隔离的虚拟网络。容器网络至少应该能为 Pod(Kubernetes 中运行容器化应用的地方)分配 IP 地址,以允许其他进程访问。
4)对应工具
CNI 标准化了网络层为 Pod 提供功能的方式,这在很大程度上实现了该领域的多样性和创新性。为 Kubernetes 环境选择网络非常关键,有许多工具可选。Weave Net,Antrea,Calico 和 Flannel 均提供有效的开源网络层,它们的功能各不相同,应根据特定需求进行选择。此外,许多供应商已准备好使用软件定义网络(SDN)工具来支持和扩展 Kubernetes 网络,这些工具可使你深入了解网络流量,执行网络策略,甚至将容器网络和策略扩展到更广泛的数据中心。


本文是对运行时层的概述,该层提供了容器在云原生环境中运行所需的工具,包括:
-
存储:使应用程序轻松快速访问运行所需的数据;
-
容器运行时:执行应用程序代码;
-
网络:确保容器化应用程序之间的通信。
在下一章节中,我们将探索编排和管理层,该层处理的是如何将所有容器化应用程序作为一个组进行管理。
编排和管理层
编排和管理层是 CNCF 云原生全景图的第三层。在使用这一层的工具之前,工程师大概已经按照安全合规标准自动配置了基础设施,并为应用程序设置了运行时(运行时层)。现在,他们必须弄清楚如何将所有应用程序组件作为整体来编排和管理。这些组件必须相互识别以进行通信,并通过协调实现共同的目标。编排和管理层的工具可实现自动化和弹性伸缩,基于此云原生应用程序天然具有可扩展性。
1. 编排和调度
1)是什么
编排和调度是指在集群中运行和管理容器(一种打包和运送应用的新方式)。集群是通过网络连接的一组机器(物理机或虚拟机均可)。容器编排器(和调度器)与电脑上管理所有应用程序(如微软 360、Zoom、Slack 等)的操作系统类似。操作系统执行你想使用的应用程序,并规划哪个应用程序该在何时使用电脑的 CPU 和其他硬件资源。虽然在一台机器上运行所有东西很棒,但如今大多数应用程序的大小远非一台机器所能处理,大多数现代的应用程序都是分布式的,这就需要一种软件能够管理在不同机器上运行的组件。简单来说,你需要一个“集群操作系统”。这就是编排工具。你可能已经注意到了,在本系列的前几篇文章中,容器频繁出现。容器可以让应用程序运行在不同的环境中,这种能力是关键。容器编排器(大多数情况下是指 Kubernetes)也是如此。容器和 Kubernetes 是云原生架构的核心,所以我们总是听到别人提起它们。
2)解决的问题
在云原生架构中,应用程序被分解成很多小的组件或服务,每个组件或服务都放在一个容器里。你可能已经听说过微服务,指的就是这种情况。现在,你拥有的不再是一个大型的应用程序,而是多个小型的服务,每个服务都需要资源、要被监控,在出现问题的时候也需要修复。对单个服务来说手动执行这些操作是可行的,但当你有上百个容器时,你就需要自动化的流程。
3)如何解决
容器编排器自动化了容器管理的过程。这在实际操作中意味着什么?让我们以 Kubernetes 来回答这个问题,因为 Kubernetes 是事实上的容器编排器。Kubernetes 做的事情是“期望状态协调”:将集群中容器的当前状态与期望状态匹配。工程师在文件中指定所需状态,例如:服务 A 的 10 个实例在三个节点(即:机器)上运行,可访问 B 数据库,等等。该状态需持续与实际状态进行比较。如果预期状态与实际状态不匹配,Kubernetes 会通过创建或销毁对象来进行协调(例如:如果某个容器崩溃了,Kubernetes 会启动一个新的容器)。简而言之,Kubernetes 允许你将集群视为一台计算机。它仅关注环境并为你处理实现细节。
4)对应工具
Kubernetes 与其他容器编排器(Docker Swarm,Mesos 等)都是编排调度工具,其基本目的是允许将多个不同的计算机作为一个资源池进行管理,并以声明式的方式管理它们,即不必告诉 Kubernetes 如何做,而是提供要完成的工作的定义。这样可以在一个或多个 YAML 文件中维护所需的状态,并将其应用于其他 Kubernetes 集群。然后,编排器本身会创建缺失的内容或删除无需存在的东西。虽然 Kubernetes 不是 CNCF 托管的唯一编排器(Crossplane 和 Volcano 是另外两个孵化项目),但它是最常用的,项目也有大量积极的维护者。

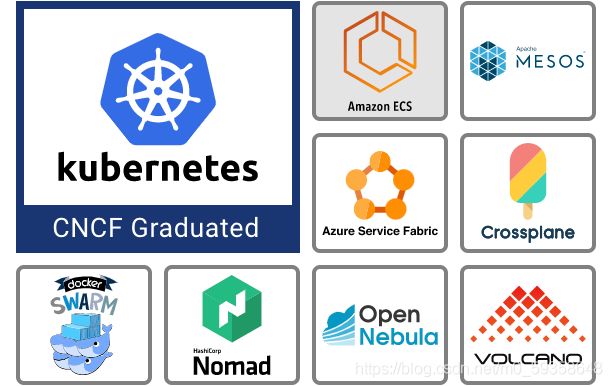
2. 协调和服务发现
1)是什么
现代应用程序由多个单独的服务组成,这些服务之间需要相互协作才能为最终用户提供价值。要进行协作,这些服务通过网络进行通信(我们在运行时层已经讨论过)。要通信,服务需要能相互定位。服务发现就是解决这个问题的。
2)解决的问题
云原生架构是动态的,总是在不断变化。当一个节点上的某个容器崩溃时,一个新的容器会在另一个节点上启动来替代它。或者,当一个应用程序扩展时,它的副本会散布在整个网络中。没有一个地方可以提供特定服务,一切的位置在不断变化。此类别的工具跟踪网络中的服务,以便服务在需要时可以相互查找。
3)如何解决
服务发现工具可提供一个公共的位置来查找和识别单个的服务。该类别中有两种工具:
-
服务发现引擎:类似数据库的工具,存储的信息包括:存在什么哪些服务以及如何定位它们;
-
名称解析工具(如 CoreDNS):接收服务位置请求并返回网络地址信息。
注:在 Kubernetes 中,为了使 Pod 可达,引入了一个称为“Service”的新抽象层。Service 为动态变化的 Pod 组提供了单一稳定的地址。请注意,“Service” 在不同的语境中有不同的含义,可能会造成混淆。“services” 通常指位于容器/Pod 中的服务,是实际应用程序中具有特定功能的应用组件或微服务(例如:iPhone 的面部识别算法)。而 Kubernetes 的 Service 是一种抽象,可帮助 Pod 相互查找和定位。它是服务(功能上的)作为进程或 Pod 的入口点。在 Kubernetes 中,当你创建了一个 Service (抽象),你就创建了一组 Pod,这些 Pod 一起通过单一 endpoint (入口)提供一个服务(功能)。
4)对应工具
随着分布式系统变得越来越普遍,传统的 DNS 流程和负载均衡器已经无法跟上不断变化的 Endpoint 信息,因此有了服务发现工具。它们可用来处理快速对自身进行注册和注销的各个应用程序实例。一些服务发现工具(例如 etcd 和 CoreDNS)是 Kubernetes 原生的,其他一些工具有自定义的库或工具让服务有效运行。CoreDNS 和 etcd 是 CNCF 项目,并且内置在 Kubernetes 中。
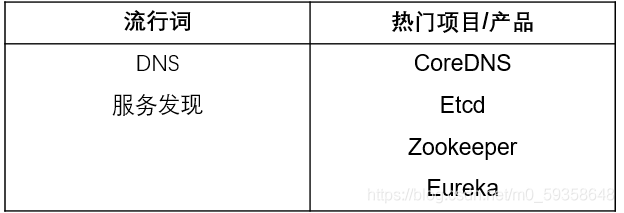

3. 远程进程调用
1)是什么
远程进程调用(RPC,Remote Procedure Call)是一种使应用程序相互通信的特殊技术。它代表了应用程序相互之间构建通信的一种方法。
2)解决的问题
现代应用程序由众多单独的服务组成,这些服务必须通过通信才能进行协作。RPC 是应用程序之间进行通信的一种方法。
3)如何解决
RPC 可以一种紧耦合且高度自觉的方式处理服务之间的通信。它允许带宽高效的通信,并且许多语言支持 RPC 接口实现。RPC 不是解决此问题的唯一方法,也不是最常见的方法。
4)对应工具
RPC 为服务之间的通信提供了高度结构化且紧密耦合的接口。gRPC 是非常流行的 RPC 实现,已被 CNCF 采用。


4. 服务代理
1)是什么
服务代理工具用于拦截进出某个服务的流量,对其应用一些逻辑,然后转发该流量到另一个服务。服务代理的本质是一种“中间人”,收集网络流量的信息并对其应用规则。简单如充当负载均衡器将流量转发到单个应用程序,也可复杂如并排运行的代理网格,由单个的容器化应用程序处理所有网络连接。服务代理本身很有用,尤其是在将流量从更广泛的网络引到 Kubernetes 集群时。服务代理同时也为其他系统(如 API 网关或服务网格)搭建了基础,我们将在下文讨论。
2)解决的问题
应用程序应以受控方式发送和接收网络流量。为了跟踪流量并对其进行转换或重定向,我们需要收集数据。传统上,开启数据收集和网络流量管理的代码嵌入在每个应用程序中。服务代理可以使我们“外部化”该功能,使其无需再存在于应用程序中,而是嵌入到平台层(应用程序运行的地方)。这是非常强大的功能,因为它使开发人员可以完全专注于编写应用程序逻辑,而处理流量的通用任务由平台团队管理(这是平台团队的首要职责)。通过从单个公共位置集中分配和管理全局所需的服务功能(例如路由或 TLS 终止),服务之间的通信将更加可靠,安全和高效。
3)如何解决
代理充当用户和服务之间或不同服务之间的守门员。通过这种独特的定位,他们可以洞悉正在发生的通信类型。根据洞察,他们可以确定将特定请求发送到哪里,甚至完全拒绝该请求。代理收集关键数据,管理路由(在服务之间平均分配流量或在某些服务发生故障时重新路由),加密连接和缓存内容(减少资源消耗)。
4)对应工具
服务代理的工作原理是拦截服务之间的流量,对它们执行一些逻辑,然后可能会允许流量继续前进。通过将一组集中控制的功能放入此代理,管理员可以完成几件事。他们可以收集有关服务间通信的详细指标,防止服务过载,并将其他通用标准应用于服务。服务代理是服务网格等其他工具的基础,因为它们提供了对所有网络流量实施更高级别策略的方法。请注意,CNCF 将负载均衡器和 ingress provider 包括在此类别中。Envoy,Contour 和 BFE 都是 CNCF 项目。
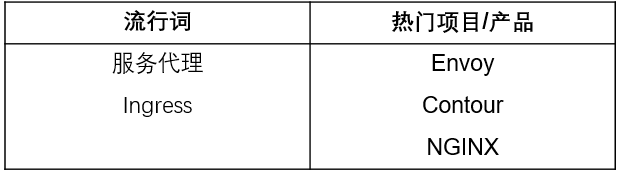

5. API 网关
1)是什么
人们通常通过网页或(桌面)应用程序之类的 GUI(图形用户界面)与计算机程序进行交互,计算机则通过 API(应用程序编程接口)相互进行交互。但是,请勿将 API 与 API 网关混淆。API 网关允许组织将关键功能(例如授权或限制应用程序之间的请求数量)移动到集中管理的位置。它还用作(通常是外部的)API 使用者的通用接口。通过 API 网关,组织可以集中控制(限制或启用)应用程序之间的交互并跟踪它们,从而实现 拒绝请求、身份验证之类的功能,并防止服务被过度使用(也称为速率限制)。
2)解决的问题
尽管大多数容器和核心应用程序都具有 API,但 API 网关不仅仅是 API。API 网关简化了组织管理规则和将规则应用于所有交互的方式。API 网关允许开发人员编写和维护较少的自定义代码。他们还使团队能够查看和控制用户与应用程序本身之间的交互。
3)如何解决
API 网关位于用户和应用程序之间。它充当中介,将来自用户的消息(请求)转发给适当的服务。但是在交出请求之前,它会评估用户的请求是否被允许,并详细记录发出请求的人以及发出的请求数量。简而言之,API 网关为应用程序用户提供了具有通用用户界面的单入口点。它还可以将原本在应用程序中实现的任务移交给网关,从而为开发人员节省时间和金钱。
4)对应工具
像该层中的许多类别一样,API 网关从应用程序中删除自定义代码,并将其带入中央系统。API 网关的工作原理是拦截对后端服务的调用,执行某种增值活动,例如验证授权、收集指标或转换请求,然后执行它认为适当的操作。API 网关是一组下游应用程序的通用入口点,同时为团队提供了可以注入业务逻辑以处理授权,速率限制和拒绝请求的地方。它们使应用开发者可以从客户那里提取对下游 API 的更改,并将添加新客户之类的任务交给网关。
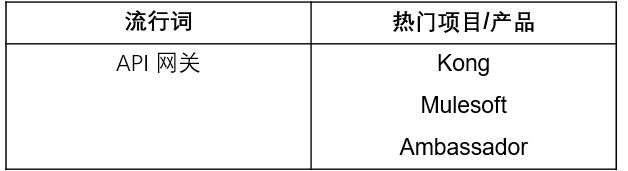

6. 服务网格
1)是什么
如果你已经了解了一些云原生相关的知识,则“服务网格”这个术语可能已经听说过。最近服务网格引起了很多关注。TNS 的长期贡献者 Janakiram MSV 表示,“在 Kubernetes 之后,服务网格技术已成为云原生技术栈中最关键的部分。” 服务网格管理服务之间的流量(即通信)。它们使平台团队能够无需更改任何代码即可在集群内运行的所有服务之间统一添加可靠性,可观察性和安全性功能。
2)解决什么问题
在云原生环境中,我们要处理很多服务,这些服务都需要通信。这意味着在本来不可靠且通常很慢的网络上需要来回传输更多流量。为了应对这些新挑战,工程师必须实施额外的功能。在服务网格之前,必须将该功能编码到每个单独的应用程序中。这些代码通常会成为技术债,并导致失败或漏洞。
3)如何解决
服务网格在平台层的所有服务之间统一增加了可靠性,可观察性和安全性,而无需触及应用程序代码。它们与任何编程语言兼容,使开发团队可以专注于编写业务逻辑。注:传统上必须将这些服务网格功能编码到每个服务中,因此每次发布或更新新服务时,开发人员都必须确保这些功能也能使用,会导致很多人为错误。事实上,开发人员更喜欢专注于业务逻辑(产生价值的功能),而不是建立可靠性,可观察性和安全性功能。但对于平台所有者来说,可靠性、可观察性和安全是核心功能,对于他们所做的一切至关重要。让开发人员负责添加平台所有者需要的功能本身很难。服务网格和 API 网关解决了这个问题,因为它们是由平台所有者实现并普遍应用于所有服务的。
4)对应工具
服务网格通过服务代理将集群上运行的所有服务绑定在一起,从而创建了服务的网格。这些是通过服务网格控制平面进行管理和控制的。服务网格允许平台所有者在不要求开发人员编写自定义逻辑的情况下执行常见操作或在应用程序上收集数据。本质上,服务网格是通过向服务代理的网络或网格提供命令和控制信号来管理服务间通信的基础结构层。它的能力在于无需修改应用程序即可提供关键系统功能。某些服务网格将通用服务代理(请参见上文)用于其数据平面。另外一些则使用专用代理。例如,Linkerd 使用 Linkerd2-proxy “微型代理”来获得性能和资源消耗方面的优势。这些代理通过边车(sidecar) 统一地附加到每个服务上。Sidecar 是指代理在自己的容器中运行但存在于同一个 Pod 中,就像摩托车边车一样,它是一个单独的模块,附着在摩托车上。服务网格提供了许多有用的功能,包括显示详细指标,加密所有流量,限制服务可授权的操作,为其他工具提供额外插件等等。更多详细信息,请查看服务网格接口规范:https://smi-spec.io/。
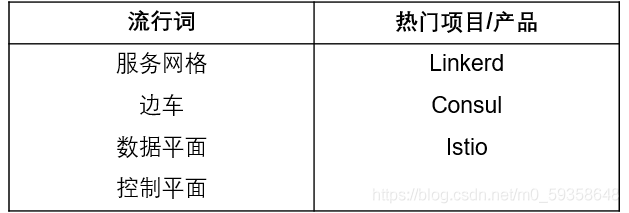

7. 小结
编排和管理层的工具旨在将独立的容器化应用作为一个组进行管理。编排和调度工具可以看作是集群操作系统,用于管理整个集群中的容器化应用程序。协调和服务发现,服务代理和服务网格确保服务可以找到彼此并进行有效通信,彼此协作以成为一个流畅的应用程序。API 网关是一个附加层,可对服务通信加以更多控制,尤其是对外部应用程序之间的通信。在下一章节中,我们将讨论应用程序定义和开发层——CNCF 全景图的最后一层。它涵盖数据库、数据流和消息传递、应用程序定义和镜像构建,以及持续集成和交付。
应用程序定义和开发层
现在我们来到了云原生全景图的最上层。应用程序定义和开发层,顾名思义,聚焦在帮助工程师构建应用程序并使其运行的工具上。本文前面的内容都是关于构建可靠安全的环境以及提供所有必需的应用程序依赖,应用程序定义和开发层则是关于构建软件。
1. 数据库
1)是什么
数据库管理系统是一个应用程序,可帮助其他应用程序高效地存储和检索数据。数据库能保障数据存储,仅授权的用户能访问数据,并且允许用户通过专门的请求来检索数据。尽管数据库类型繁多,但它们的总体目标都是相同的。
2)解决的问题
大多数应用程序都需要有效的方式来存储和检索数据,并且保证数据安全。数据库使用成熟的技术以结构化的方式进行此操作。
3)如何解决
数据库提供存储和检索应用程序数据的通用接口。开发人员使用这些标准接口,并用一种简单的查询语言来存储、查询和检索信息。同时,数据库允许用户连续备份和保存数据以及加密和管理数据访问权限。
4)对应工具
我们已经了解了数据库管理系统是一种用于存储和检索数据的应用程序。它使用一种通用的语言和界面,并且可以被多种语言和框架轻松使用。
常见的两种数据库类型为:结构化查询语言(SQL)数据库和 NoSQL 数据库。应用程序该使用哪种数据库应该由其需求来驱动。Kubernetes 支持有状态的应用程序,近年来使用 Kubernetes 的使用越来越广泛,我们已经看到了利用容器化技术的新一代数据库。这些新的云原生数据库旨在将 Kubernetes 的扩展性和可用性优势引入数据库。YugaByte 和 Couchbase 之类的工具是典型的云原生数据库,Vitess 和 TiKV 是该领域的 CNCF 项目。注意:查看此类别时会发现以 DB 结尾的多个名称(例如 MongoDB、CockroachDB、FaunaDB),你可能会猜测它们代表数据库。还有以 SQL 结尾的各种名称(例如 MySQL 或 MemSQL)。一些是已经适应了云原生环境的“老派”数据库,还有一些是兼容 SQL 的 NoSQL 数据库,例如 YugaByte 和 Vitess。

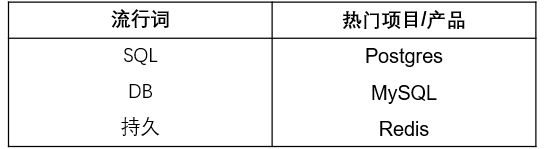
2. 数据流和消息传递
1)是什么
数据流和消息传递工具通过在系统之间传输消息(即事件)来实现服务到服务的通信。单个服务连接到消息传递服务以发布事件和(或)从其他服务读取消息。这种动态变化创造了一个环境,在这个环境中单个应用要么是发布者,即可编写事件;要么是订阅事件的订阅者,或者更可能是两者兼而有之。
2)解决的问题
随着服务激增,应用程序环境变得越来越复杂,应用程序之间的通信编排也更具挑战性。数据流或消息平台提供了一个中心位置来发布和读取系统中发生的所有事件,从而使应用程序可以一起工作,而不必相互了解。
3)如何解决
当一个服务执行其他服务应该知道的事情时,它会将事件“发布”到数据流或消息传递工具。需要了解这些事件类型的服务将订阅并监视数据流或消息传递工具。这就是“发布-订阅”的本质。通过引入管理通信的“中间层”可以使服务彼此解耦。服务只是监视事件、采取行动并发布新事件,这样能建立高度分离的体系结构。在此体系结构中,服务可以协作而无需彼此了解。这种解耦使工程师能够添加新功能,而无需更新下游应用程序(消费者)或发送大量查询。系统的解耦程度越高,更改的灵活性和适应性就越高,而这正是工程师在系统中所追求的。
4)对应工具
数据流和消息传递工具早在云原生技术成为现实之前就已经存在了。为了集中管理关键业务事件,组织建立了大型的企业级服务总线。但是,当我们在云原生环境中谈论数据流和消息传递时,通常是指 NATS、RabbitMQ、Kafka 或云提供的消息队列之类的工具。消息传递和数据流传输系统为编排系统进行通信提供了一个中心位置。消息总线提供了所有应用程序都可以访问的公共位置,应用程序都可以通过发布消息来告诉其服务它们在做什么,或者通过订阅消息来查看正在发生的事情。NATS 和 Cloudevents 项目都是这个领域的孵化项目,NATS 提供了一个成熟的消息传递系统,而 Cloudevents 则致力于标准化系统之间的消息格式。Strimzi,Pravega 和 Tremor 是沙盒项目,每个项目都针对数据流和消息传递的独特用例进行了量身定制。
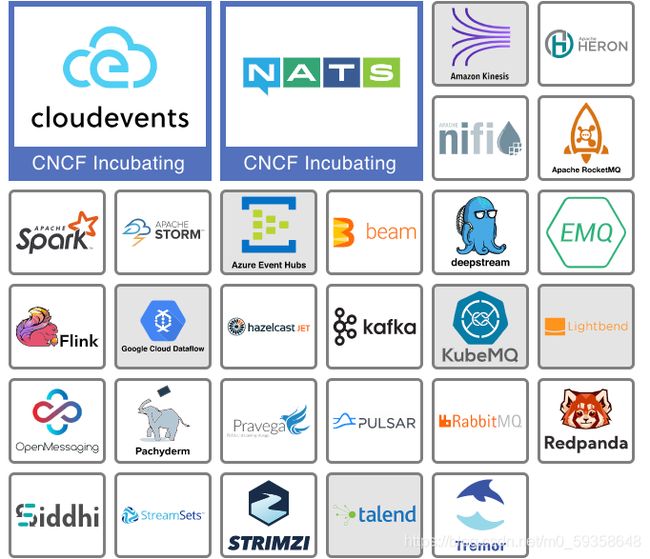

3. 应用程序定义和镜像构建
1)是什么
应用程序定义和镜像构建是一个广泛的类别,可以分为两个主要的子类别:
-
聚焦于开发的工具:可帮助将应用程序代码构建到容器和 Kubernetes 中。
-
聚焦于运维的工具:以标准化的方式部署应用。
无论是加快或简化开发环境,提供标准化的方式来部署第三方应用程序,还是简化编写新的 Kubernetes 扩展的过程,此类别的工具都可以优化 Kubernetes 开发和运维人员的体验。
2)解决的问题
Kubernetes(或者容器化环境)非常灵活且功能强大。这种灵活性也带来了复杂性,主要体现在对于各种新用例有众多配置选项。开发人员必须将代码容器化,并在类生产环境中进行开发。在快速的发布计划周期下,运维人员需要以一种标准化的方法来将应用程序部署到容器环境中。
3)如何解决
该领域的工具旨在解决开发或运维人员面临的一些挑战。对于开发者,有一些工具可以简化扩展 Kubernetes 的过程以构建、部署和连接应用程序。许多项目和产品可以存储或部署预打包的应用程序,使运维人员可以快速部署 Kafka 之类的流服务或安装 Linkerd 之类的服务网格。开发云原生应用程序带来了一系列全新的挑战,因此需要大量多样化的工具来简化应用程序的构建和部署。当你需要解决环境中的开发和运维问题时,可以看看此类别中的工具。
4)对应的工具
应用程序定义和构建工具涵盖了广泛的功能,比如使用 KubeVirt 将 Kubernetes 扩展到虚拟机,或使用 Telepresence 之类的工具将开发环境移植到 Kubernetes 中来加速应用程序开发等。从整体上讲,该领域中的工具可以解决开发人员面临的正确编写、打包、测试或运行自定义应用程序的问题,也可以解决运维人员面临的部署和管理应用程序的问题。Helm 是该类别中唯一一个毕业的项目,为许多应用程序部署模式奠定了基础。Helm 允许 Kubernetes 用户部署和自定义一些流行的第三方应用程序,Artifact Hub(CNCF 沙箱项目)和 Bitnami 等项目已采用 Helm 来提供精选的应用程序目录。Helm 也足够灵活,允许用户自定义自己的应用程序部署。Operator Framework 是一个孵化项目,旨在简化构建和部署 Operator 的过程。Operator 不在本文讨论范围之内,但请注意,它类似于 Helm,有助于部署和管理应用程序。Cloud Native Buildpacks 是另一个孵化项目,旨在简化将应用程序代码构建到容器中的过程。


4. 持续集成和持续交付
1)是什么
持续集成(CI)和持续交付(CD)工具可通过嵌入式质量保证实现快速高效的开发过程。CI 通过立即构建和测试代码来自动化代码变更,确保生成可部署的制品。CD 则更进一步,推动该制品进入部署阶段。成熟的 CI/CD 系统会监视源代码中的变更,自动构建和测试代码,然后将其从开发阶段转移到生产阶段。在此过程中,CI/CD 系统必须通过各种测试或验证来决定该过程是继续还是失败。
2)解决的问题
构建和部署应用程序是一个困难重重且容易出错的过程,特别是当过程中涉及很多人为干预和手动步骤时。如果不将代码集成到代码库中,开发人员在软件上花的时间越长,识别错误所花费的时间就越长,问题修复也就越困难。通过定期集成代码,可以及早发现错误并更轻松地排除故障。毕竟,在几行代码中查找错误比在几百行代码中查找错误要容易得多。尽管 Kubernetes 之类的工具为运行和管理应用程序提供了极大的灵活性,它们也为 CI/CD 工具带来了新的挑战和机遇。云原生 CI/CD 系统能够利用 Kubernetes 本身来构建、运行和管理 CI/CD 流程(通常称为流水线)。Kubernetes 还提供应用程序运行状况的信息,从而使云原生 CI/CD 工具能够更轻松地确定给定的变更是否成功,是否需要回滚。
3)如何解决
CI 工具可确保开发人员引入的任何代码更改或更新都能自动、连续地与其他更改进行构建、验证并集成。开发人员每次添加更新时都会触发自动测试,确保只有良好的代码才能将其导入系统。CD 扩展了 CI,能将 CI 流程的结果推送到类生产和生产环境中。假设开发人员更改了 Web 应用的代码。CI 系统会看到代码更改,然后构建并测试该 Web 应用的新版本。CD 系统获取该新版本,并将其部署到开发、测试、预生产以及最终生产环境中。在流程的每个步骤之后测试已部署的应用程序时,它会执行此操作。这些系统一起构成了该 Web 应用的 CI/CD 管道。
4)对应工具
随着时间的流逝,市面上已经有了许多工具来帮助将代码从存储库移至运行最终应用程序的生产环境。像大多数其他计算领域一样,云原生开发的到来改变了 CI/CD 系统。类似 Jenkins(可能是市场上使用最广泛的 CI 工具)的传统工具已经通过完善迭代,以更好地适应 Kubernetes 生态系统。Flux 和 Argo 等公司率先开发了一种称为 GitOps 的持续交付的新方法。通常,该领域的项目和产品是:
-
CI 系统;
-
CD 系统;
-
帮助 CD 系统确定代码是否准备好投入生产的工具;
-
前三者的合集(Spinnaker 和 Argo 就是如此)。
Argo 和 Brigade 是该领域中仅有的 CNCF 项目,但是你可以找到由持续交付基金会(Continuous Delivery Foundation)托管的更多项目。在此空间中寻找工具,可以帮助组织自动化生产路径。
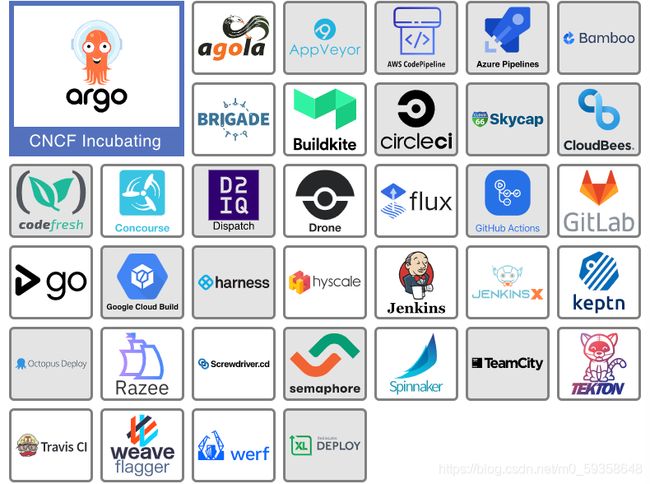
5. 小结
应用程序定义和开发层中的工具使工程师能够构建云原生应用程序。该层的工具包括:
-
数据库:存储和检索数据。
-
数据流和消息传递工具:实现相互分离、精心设计的架构。
-
应用程序定义和镜像构建工具:包含可改善开发人员和操作员体验的多种技术。
-
CI/CD 工具:确保代码处于可部署状态,并帮助工程师及早发现错误,从而确保代码质量。
托管 K8s 和 PaaS 解决的问题
在上面的内容中,我们讨论了 CNCF 云原生全景图的各层:供应层、运行时层、编排管理层以及应用定义和开发层。本章节我们将聚焦在平台层。
正如我们在本文中看到的那样,每个类别都解决了特定的问题。仅仅存储并不能提供管理应用程序所需的全部功能,你还需要编排管理、容器运行时、服务发现、网络、API 网关等工具。平台将来自不同层的工具捆绑在一起,以解决更大的问题。平台里其实没有新的工具。你当然可以构建自己的平台,事实上,许多组织都这样做。但是,可靠、安全地配置和微调不同的模块,同时确保始终更新所有技术并修补漏洞,这不是一件容易的事。你需要一支专门的团队来构建和维护它。如果没有所需的专业知识,那么使用平台可能会更好。对于某些组织,尤其是工程团队规模较小的组织,平台是采用云原生技术的唯一方法。你可能已经注意到了,所有的平台都是围绕 Kubernetes 来演化的,因为 Kubernetes 是云原生技术栈的核心。
1. Kubernetes 发行版
1)是什么
发行版是指供应商以 Kubernetes 为核心(采用未经修改的开源代码,尽管有些人对其进行了修改),并将其打包以进行重新发行。通常这个过程需要查找和验证 Kubernetes 软件,并提供集群安装和升级的机制。许多 Kubernetes 发行版都包含其他闭源或开源的应用程序。
2)解决的问题
开源 Kubernetes 并未指定特定的安装工具,而是将许多设置配置选项提供给用户。此外,有限的社区资源(包括社区论坛、StackOverflow、Slack 或 Discord 等)已经不能解决所有的问题。随着 Kubernetes 的普及,Kubernetes 的使用变得越来越容易,但是查找和使用开源安装程序可能会面临挑战。用户需要了解使用哪个版本,在何处获取,以及特定组件是否能兼容。此外,还需要决定集群上部署什么软件,要使用哪些设置来确保平台的安全性、稳定性和高性能。所有这些都需要丰富的 Kubernetes 专业知识,而这些知识可能并不容易获得。
3)如何解决
Kubernetes 发行版提供了一种安装 Kubernetes 的可靠方式,并提供了合理的默认值以创建更好、更安全的操作环境。
Kubernetes 发行版为供应商和项目提供了所需的掌控度和可预测性,以帮助他们支持客户部署、维护和升级 Kubernetes 集群。这种可预测性使发行版提供商在客户遇到生产问题时可为其提供支持。发行版常常提供经过测试和受支持的升级路径,使用户的 Kubernetes 集群保持最新的版本。此外,发行版通常提供可在 Kubernetes 上部署的软件,从而使其更易于使用。
4)对应的工具
如果你已经安装了 Kubernetes,那你可能已经使用了 kubeadm 之类的工具来启动和运行集群。即便如此,你可能还需要 CNI(容器网络接口)来安装和配置它。然后,你可能已经添加了一些存储类,一个处理日志消息的工具,可能还需要个 ingress controller,以及更多其他的工具。Kubernetes 发行版将自动执行部分或全部设置。它还将根据自己对最佳实践或智能默认值的理解提供配置设置。此外,大多数发行版都将捆绑一些经过测试的扩展或附件,以确保用户可以尽快使用新集群。我们以 Kublr 为例。它以 Kubernetes 为核心,主要捆绑了来自供应层、运行时层、编排管理层的工具。所有模块都预先配置了一些选项并且开箱即用。不同的平台聚焦不同的功能。就 Kublr 而言,重点是在运维方面,而其他平台则可能聚焦在开发工具上。此类别中有很多工具选项。如下图所示,企业可以选择和供应商达成技术合作,比如国外的 Canonical、VMware、Mirantis、SUSE,国内的网易、火山引擎和京东,它们都可以提供出色的开源和商业工具,建议在评估发行版时仔细考虑自己的需求。

2. 托管 Kubernetes
1)是什么
托管 Kubernetes 是由 Amazon Web Services(AWS)、DigitalOcean、Azure 或 Google 等基础设施提供商(云厂商)提供的服务,允许客户按需启动 Kubernetes 集群。云厂商负责管理 Kubernetes 集群的一部分,通常称为控制平面。托管 Kubernetes 服务与发行版相似,但由云厂商在其基础架构上进行管理。
2)解决的问题
托管 Kubernetes 使团队只需在云厂商开设一个账户即可开始使用 Kubernetes。它解决了 Kubernetes 入门五个过程中的“五 W”问题:
-
Who:云厂商
-
What:他们托管的 Kubernetes 产品
-
When:现在
-
Where:云厂商的基础架构上
-
Why:由你决定
3)如何解决
由于 Kuberentes 托管服务提供商负责管理所有细节,因此托管的 Kubernetes 服务是开始云原生之路的最简单方法。用户所需要做的就是开发自己的应用程序并将其部署在托管的 Kubernetes 服务上,这非常方便。托管产品允许用户启动 Kubernetes 集群并立即开始*,同时对集群可用性承担一些责任。值得注意的是,这些服务的额外便利性会造成灵活性的降低:托管的 Kubernetes 服务和云厂商绑定,且用户无法访问 Kubernetes 控制平面,因此某些配置选项会受到限制。注:AWS 的 EKS 略有例外,因为它还要求用户采取一些其他步骤来准备集群。
4)对应的工具
托管 Kubernetes 是由供应商(通常是基础架构托管提供商)提供的按需使用的 Kubernetes 集群,供应商负责配置群集和管理 Kubernetes 控制平面。再次说明,值得注意的例外是 EKS,其上的单个节点配置由客户端决定。托管 Kubernetes 服务使组织可以将基础架构组件管理外包出去,这样可以快速配置新集群并降低运营风险。主要的权衡取舍在于可能需要为控制平面管理付费,并且用户的管理权限有限。与自己搭建 Kubernetes 群集相比,托管服务在配置 Kubernetes 群集方面有更严格的限制。在这个领域中有许多供应商和项目,在撰写本文时,尚无 CNCF 项目。

3. Kubernetes 安装程序
1)是什么
Kubernetes 安装程序可帮助你在机器上安装 Kubernetes,它们可自动化 Kubernetes 的安装和配置过程,甚至可以帮助升级。Kubernetes 安装程序通常与 Kubernetes 发行版或托管 Kubernetes 产品结合使用或由它们使用。
2)解决的问题
与 Kubernetes 发行版相似,Kubernetes 安装程序可简化 Kubernetes 的上手过程。开源的 Kubernetes 依赖于 kubeadm 之类的安装程序。截至本文撰写之时,kubeadm 可用于启动和运行 Kubernetes 集群,是 CKA(Kubernetes 管理员认证) 测试的一部分。
3)如何解决
Kubernetes 安装程序简化了 Kubernetes 的安装过程。像发行版一样,它们为源代码和版本提供经过审核的源。它们还经常自带 Kubernetes 环境配置。像 kind (Docker 中的 Kubernetes)这样的 Kubernetes 安装程序允许通过单个命令获得 Kubernetes 集群。
4)对应的工具
无论是在 Docker 上本地安装 Kubernetes,启动和配置新的虚拟机,还是准备新的物理服务器,都需要一个工具来处理各种 Kubernetes 组件的准备工作。Kubernetes 安装程序可简化该过程。有些处理节点启动,还有一些仅配置已供应的节点。它们都提供不同程度的自动化,并且适合不同的用例。开始使用 Kubernetes 安装程序时,应先了解自己的需求,然后选择可以满足这些需求的安装程序。在撰写本文时,kubeadm 是 Kubernetes 生态系统中至关重要的工具,已包含在 CKA 测试中。Minikube、kind、kops 和 kubespray 都是 CNCF 中的 Kubernetes 安装程序项目。

4. PaaS / 容器服务
1)是什么
PaaS(平台即服务)是一种环境,允许用户运行应用程序而不必了解底层计算资源。此类别中的 PaaS 和容器服务是一种机制,可为开发人员托管 PaaS 或托管他们可以使用的服务。
2)解决的问题
在本篇文章中,我们讨论了有关“云原生”的工具和技术。PaaS 连接了此领域中的许多技术,可为开发人员提供直接价值。它回答了以下问题:
-
我如何在各种环境中运行应用程序?
-
一旦应用程序运行起来,我的团队和用户将如何与它们交互?
3)如何解决
PaaS 为组合运行应用程序所需的开源和闭源工具提供了选择。许多 PaaS 产品包含处理 PaaS 安装和升级的工具,以及将应用程序代码转换为正在运行的应用程序的机制。此外,PaaS 可以处理应用程序实例的运行时需求,包括按需扩展单个组件以及可视化单个应用程序的性能和日志消息。
4)对应的工具
组织正在采用云原生技术来实现特定的业务或目标。与构建自定义应用程序平台相比,PaaS 可快速让组织实现价值。Heroku 或 Cloud Foundry Application Runtime 之类的工具可帮助组织快速启动并运行新的应用程序,它们可提供运行云原生应用程序所需的工具。任何 PaaS 都有自身的限制。大多数只支持一种语言或一部分应用程序类型,其自带的一些工具选项可能并不适合你的需求。无状态应用程序通常在 PaaS 中表现出色,而数据库等有状态应用程序通常不太适合 PaaS。目前在这个领域没有 CNCF 项目,但是大多数产品都是开源的。

5. 小结
如文中所介绍,有多种工具可帮助简化 Kubernetes 的采用。Kubernetes 发行版、托管 Kubernetes 服务、Kubernetes 安装程序以及 PaaS 都承担了一些安装和配置的工作,可进行预打包。每个解决方案都有其自己的特点。在采用上述任何一种方法之前,需要进行一些研究,以确定适合自己需求的最佳解决方案。你可能需要考虑:
-
我会遇到一些需要掌控控制平面的场景吗?如果有,托管解决方案可能不是一个很好的选择。
-
我有没有一个小型团队来管理“标准”工作负载,并需要分流尽可能多的操作任务?如果有,托管解决方案可能非常合适你。
-
便携性对我来说重要吗?
-
生产就绪情况如何?
还有更多问题需要考虑。没有一个“最佳工具”,但是对于你的特定需求,肯定可以选择一个有效工具。希望本文能帮助你将搜索范围缩小到正确的区域。
可观察性和分析
终于我们来到了云原生全景图详解的最后一章节。本章节将向大家介绍云原生全景图中的可观察性和分析这一“列”。
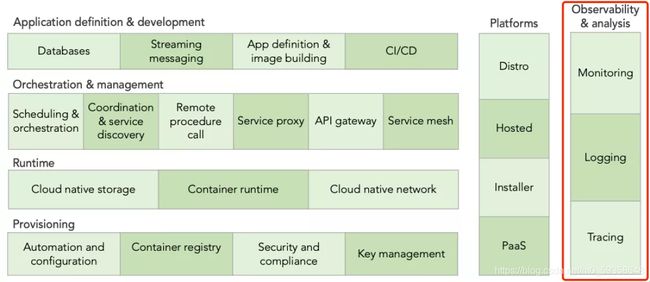
首先我们定义一下可观察性和分析(Observability & analysis)。可观察性是一种系统特性,描述了通过外部输出可以理解系统的程度。通过衡量 CPU 时间、内存、磁盘空间、延迟、error 等指标,可以或多或少地观察到计算机系统的状态。分析则是尝试理解这些可用于观察的数据。为了确保服务不会中断,我们需要观察和分析应用程序的各个方面,以便立即发现并修复异常情况。这就是可观察性和分析这个类别要做的事情。它贯穿并观察所有层,因此在整个全景图的侧面而不是嵌在某一层。此类别中的工具包括日志记录 (logging)、监控 (monitoring)、追踪(tracing) 和混沌工程(chaos engineering)。虽然混沌工程在这里列出,但它更多的是一种可靠性工具,而不是可观察性或分析工具。
1. 日志记录
1)是什么
应用程序会输出稳定的日志消息流,以描述自身在何时做了什么。这些日志消息会捕获系统中发生的各种事件,例如失败或成功的操作、审计信息或运行状况。日志记录工具将收集、存储和分析这些消息,以追溯错误报告和相关数据。日志记录(loging)、度量(metrics)、追踪(tracing) 是可观察性的三大支柱。
2)解决的问题
收集、存储和分析日志是构建现代平台的关键部分,日志记录可帮助执行这其中的某一项或全部任务。一些工具可处理从收集到分析全方位的工作,还有一些工具则专注于单个任务(例如收集)。所有日志记录工具都旨在帮助组织更好地控制日志消息。
3)如何解决
在收集、存储和分析应用程序的日志消息时,我们将了解应用程序在任何给定时间的通信内容。但请注意,日志代表应用程序有意输出的消息,它们不一定能查明给定问题的根本原因。尽管如此,随时收集和保留日志消息是一项非常强大的功能,它将帮助团队诊断问题并满足合规性要求。
4)常用工具
尽管收集、存储和处理日志消息不是什么新鲜事,但云原生模式和 Kubernetes 的出现极大地改变了我们处理日志的方式。适用于虚拟机和物理机的传统日志记录方法(例如将日志写入文件)不适用于容器化的应用程序,因为在这些容器化应用程序中,文件系统的生命周期可能并不会比应用程序持久。在云原生环境中,诸如 Fluentd 之类的日志收集工具与应用程序容器一起运行,并直接从应用程序收集消息,然后将消息转发到中央日志存储以进行汇总和分析。CNCF 中的日志记录工具只有 Fluentd。


2. 监控
1)是什么
监控是指对应用程序进行检测,收集、聚合和分析日志和指标,以增进我们对应用程序行为的理解。日志描述了特定的事件,而指标则是在给定时间点对系统的度量。日志和 metrics 是两种不同的事物,但是要全面了解系统的运行状况,二者都是必需的。监控的内容包括观察磁盘空间、CPU 使用率、单个节点上的内存消耗,以及执行详细的综合事务以查看系统或应用程序是否正确且及时地进行了响应等。有许多不同的方法可用来监控系统和应用程序。
2)解决的问题
在运行应用程序或平台时,我们希望它完成既定的任务,并确保只有被授权的用户才能访问。通过监控,我们可以知道应用程序/平台是否在正常、安全且高效地运行,是否仅有被授权的用户可以访问。
3)如何解决
良好的监控方法使运维人员能够在发生事故时迅速做出响应,甚至可以自动响应。监控可以让我们洞察系统当前运行的状况,监测到问题进行修复。它能跟踪应用程序运行状况、用户行为等内容,是有效运行应用程序的重要组成部分。
4)常用工具
云原生环境中的监控和传统应用程序的监控类似。我们需要跟踪指标、日志和事件以了解应用程序的运行状况。主要区别在于云原生环境中的某些托管对象是临时的,它们可能不会持久,因此将监控系统与自动生成的资源名称联系在一起并不是一个好策略。CNCF 中有许多监控工具,最主要的是 Prometheus(已经从 CNCF 毕业)。


3. 追踪
1)是什么
在微服务架构中,服务之间不断通过网络相互通信。追踪是日志记录的一种专门用法,可以跟踪请求在分布式系统中移动的路径。
2)解决的问题
了解微服务应用程序在某个时间点的行为是一项极具挑战的任务。尽管有许多工具可以提供服务行为相关的洞察,但我们可能难以通过单个服务的行为来理解整个应用程序的运行情况。
3)如何解决
追踪对应用程序发送的消息添加唯一标识符,可解决上述问题。该唯一标识符可以跟随/追踪各个事务在系统中移动的路径,可以通过追踪的信息了解应用程序的运行状况,以及调试有问题的微服务或行为。
4)常用工具
追踪是一种功能强大的调试工具,可以对分布式应用程序的行为进行故障排除和 fine-tune。要实现追踪也需要一些成本,比如需要修改应用程序代码以发出跟踪数据,并且所有 Span 都需要由应用程序数据路径中的基础架构组件传播。CNCF 中的追踪工具有 Jaeger 和 Open Tracing。


4. 混沌工程
1)是什么
混沌工程(chaos engineering)是指有意将故障引入系统以创建更具弹性的应用程序和工程团队的实践。混乱工程工具以一种可控的方式在系统中引入故障,并针对应用程序的特定实例运行特定的实验。
2)解决的问题
复杂的系统会出现故障。故障的原因有多种,给分布式系统带来的后果也很难预测。一些组织已经接受了这一点,他们愿意采用混沌工程技术,不去试图防止故障的发生,而是设法练习从故障中恢复。这被称为优化平均修复时间(MTTR)。
3)如何解决
在云原生环境中,应用程序必须动态适应故障——这是一个相对较新的概念。这意味着当出现故障时,系统不会完全崩溃,而是可以优雅地降级或恢复。混沌工程工具可以在生产环境的系统上进行实验,以确保在发生真正的故障时系统也能应对。简言之,对一个系统进行混沌工程实验,是为了确保该系统可以承受意外情况。使用混沌工程工具,不必等待故障发生后再进行应对,而是可以在可控条件下为系统注入故障,以发现漏洞并在变更覆盖这些漏洞之前加以修复。
4)常用工具
混沌工程工具和实践对于应用程序的高可用至关重要。分布式系统通常过于复杂,而且任何变更过程都无法完全确定其对环境的影响。通过有意引入混沌工程实践,团队可以练习从故障中恢复,并将这个过程自动化。CNCF 中的混沌工程工具有 Chaos Mesh 和 Litmus Chaos。还有一些其他的开源和闭源的混沌工程工具。


5. 小结
可观察性和分析这一列的工具可用于了解系统的运行状况,并确保系统即使在恶劣的条件下也能正常运行。日志记录工具可捕获应用程序发出的事件消息,监控工具可监测日志和指标,追踪工具可跟踪单个请求的路径。结合使用这些工具,理想情况下可以 360 度全方位查看系统中正在发生的事情。混沌工程提供了一种安全的方法来保证系统可以承受意外事件,基本上可以确保系统的健康运行。文章来源:K8sMeetup 社区,点击查看原文。
一站式云原生 PaaS 平台
Erda 作为开源的一站式云原生 PaaS 平台,具备 DevOps、微服务观测治理、多云管理以及快数据治理等平台级能力。点击下方链接即可参与开源,和众多开发者一起探讨、交流,共建开源社区。欢迎大家关注、贡献代码和 Star!
-
Erda Github 地址:https://github.com/erda-project/erda
-
Erda Cloud 官网:https://www.erda.cloud/