星环TDH产品详解
星环TDH产品详解
- 一、简介
-
- 1.1 Transwarp Dta Hub介绍
- 二、环境要求
-
- 2.1 硬件环境要求
-
- 2.1.1 服务器的RAID配置
- 三、安装前的检查
-
- 3.1 系统磁盘分区要求
-
- 3.1.1 Redhat/CentOS
- 3.1.2 SUSE
- 3.2 磁盘目录规划要求
- 3.3 内存容量要求
- 3.4 网络设置
- 3.5 集群和网络拓扑要求
- 3.6 NTP服务设置
- 3.7 安全设置
- 3.8 系统的推荐设置
- 四、TDH服务的角色
-
- 4.1 Transwarp_License_Cluster角色
- 4.2 TCOS角色
- 4.3 Flannel角色
- 4.4 Zookeeper角色
- 4.5 HDFS角色
- 4.6 YARN角色
- 4.7 Search角色
- 4.8 Hyperbase角色
- 4.9 TxSQL角色
- 4.10 TDDMS角色
- 4.11 Inceptor角色
- 4.12 Pilot角色
- 4.13 EventStore角色
- 4.14 Notification角色
- 4.15 Governor角色
- 4.16 KMS角色
- 4.17 Transporter角色
- 4.18 Workflow角色
- 4.19 Rubik角色
- 4.20 KeyByte角色
- 4.21 QuarkGateway角色
- 4.22 日志分析组件角色
- 4.23 Discover角色
- 4.24 Slipstream角色
- 4.25 Slipboard角色
- 五、安装准备
-
- 5.1 操作系统安装
- 5.2 安装前系统配置改动
- 5.3 安装介质
-
- 5.3.1 安装介质获取方式
- 5.3.2 安装介质使用说明
- 六、安装Manager
-
- 6.1 安装Manager
- 6.2 升级Manager
- 七、配置集群
-
- 7.1 全局设定
-
- 7.1.1 DNS配置
- 7.1.2 NTP配置
- 7.2 添加/刪除集群服务器
- 八、安装服务
-
- 8.1 上传产品包
- 8.2 选择服务
- 8.3 服务角色的分配
-
- 8.3.1 部署角色多实例
- 8.3.2 角色属性配置
- 8.4 配置安全
- 8.5 服务的配置
-
- 8.5.1 服务的可配置项
- 8.5.2 特殊配置要求
- 8.6 服务的安装
- 8.7 安装TDH客户端
-
- 8.7.1 安裝步驟
- 九、向集群添加服务
- 十、集群扩容指导
-
- 10.1 扩容前节点检查
- 10.2 扩容节点操作
-
- 10.2.1 添加节点
-
- 10.2.1.1 选择集群
- 10.2.1.2 全局设定
- 10.2.1.3 编辑机柜
- 10.2.1.4 配置仓库
- 10.2.1.5 节点分配
- 10.2.2 扩容角色
-
- 10.2.2.1 分配角色
- 10.2.2.2 配置服务
- 10.2.2.3 应用修改
- 十一、管理面与业务面隔离场景安装部署说明
-
- 11.1 安装Manager服务
- 11.2 双平面隔离配置
-
- 11.2.1 修改manager配置文件。
- 11.2.2 修改Aquila配置,保证管理面正常访问aquila服务
- 11.2.3 修改集群机器yum repo源配置
- 十二、 许可证的激活与认证
-
- 12.1 许可证管理
- 12.2 许可证激活和使用
- 12.3 查看许可证授权管理
- 12.4 许可证过期预警
- 十三、安装和设置问题及回答
一、简介
1.1 Transwarp Dta Hub介绍
2006年Hadoop技术的出现标志着大数据技术时代的开始,经过10多年的蓬勃发展,大数据技术已经真正承托起一大批 企业的数据基础架构。经过4年的快速演进,Transwarp Data Hub(简称TDH)已成为国际一流的大数据平台。从2016年起,TDH正式成为Gartner认可的Hadoop国际主流发行版本。
TDH是国内外领先的高性能平台,比开源基于Hadoop MapReduce计算框架的版本快10x~100x倍。TDH应用范围覆盖各种规模和不同数据量的企业,通过内存计算、高效索引、执行优化和高度容错的技术,使得一个平台能够处理GB级到PB级的数据,并且在每个数量级上,都能比现有技术提供更快的性能;企业客户不再需要混合架构,TDH可以伴随企业客户的数据增长,动态不停机扩容,避免MPP或混合架构数据迁移的棘手问题。
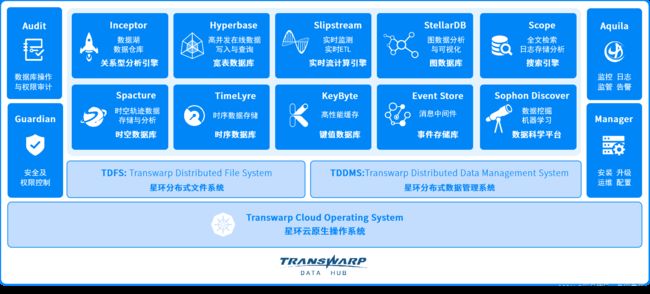
TDH主要提供5款核心产品:Transwarp Inceptor是大数据分析数据库,Transwarp Slipstream是实时计算引擎,Transwarp Discover专注于利用机器学习从数据中提取价值内容,Transwarp Hyperbase用于处理非结构化数据,Transwarp Scope用于构建企业搜索引擎。通过使用TDH,企业能够更有效的利用数据构建核心商业系统,加速商业创新。
TDH产品的主要技术优势包括以下几个方面:
1.极致的性能与可扩展性
TDH的批处理速度是开源Hadoop的10-100倍,是MPP的5-10倍,可以对从GB到PB级的数据量实现复杂的查询和分析。TDH具有高可扩展性,用户可以通过增加集群节点数量,线性提高系统的处理能力。
2.容器技术与大数据平台
TDH支持部署于TCOS之上。TCOS是为大数据应用量身订做的云操作系统,基于Docker和Kubernetes,支持一键部署TDH、扩容、缩容,同时支持基于优先级的抢占式资源调度和细粒度资源分配。
3.完整的SQL和ACID支持
Transwarp Inceptor是第一个实现完整SQL支持的Hadoop发行产品。它不仅支持SQL 2003,Oracle PL/SQL以及DB2 SQL PL,还实现了完整的ACID和CRUD功能。TDH提供JDBC和ODBC驱动连接,方便第三方工具运行于TDH之上。
4.低延迟的流处理 Transwarp Slipstream是同时支持事件驱动和微批处理的流处理引擎,计算延迟最低可至5ms。它提供标准的SQL编程接口,还支持高可用性(HA)和Exactly-Once的语义,从而支持7x24小时的生产业务。
5.丰富的机器学习和深度学习功能
Transwarp Discover支持用户通过R语言和Python开发机器学习项目,也可以用图形化的工具做分析。
6.大数据上的全文搜索
Transwarp Search支持通过SQL实现大数据上的秒级全文搜索,它利用层次化存储、堆外内存管理等创新性技术,极大的提高了系统的可用性。此外,Search还可以结合Inceptor提供较强的数据分析能力。
7.图形化的大数据开发工具套件
Transwarp Studio是TDH中的大数据开发工具集,包括元数据管理Governor、工作流Workflow、数据整合工具Transporter,Cube设计工具Rubik以及报表工具Pilot。用户可以使用这些图形化工具来提高大数据的开发效率,降低技术门槛。
8.多样化的数据处理功能
Transwarp Hyperbase用于存储和计算结构化或非结构化数据,包括日志记录、JSON/XML文件以及二进制数据(如图像和视频)。Hyperbase底层是KV的数据库,因此其非常适合高频次的数据入库、高并发精确检索等业务。
9.简易的操作和管理
Transwarp Manager是专门用于部署、管理和运维TDH集群的组件。它支持产品一键安装、一键升级和图形化运维,并提供了健康检测功能,帮助用户简化运维过程。
10.统一的安全/多租户管理
Transwarp Guardian是TDH平台中实现安全控制和资源管理的中央服务平台,它支持Kerberos和LDAP认证,可以做细粒度的权限控制,并且提供租户管理功能。
二、环境要求
2.1 硬件环境要求
Transwarp Data Hub(简称TDH)提供集群服务来保证服务的高可用性,因此集群系统必须是3台以上物理服务器组成,每台服务器必须具备以下最低配置:
- 2颗6核心或以上带超线程x86指令集CPU的服务器
- 64GB以上内存
- 2个300G以上的硬盘做RAID1,作为系统盘
- 4个以上的300GB容量以上的 硬盘作为数据存放硬盘
- 2个千兆以上网卡
为实现较好的性能并实现最高的性价比,TDH针对集群内不同的模块有不同的推荐配置,Namenode和Transwarp Manager推荐使用以下配置:
- 2颗6核带超线程的x86指令集CPU服务器(比如Intel® Xeon® Gold-5218 Processor)
- 128GB以上内存
- 6个600G以上的硬盘做RAID1作为系统盘和管理数据
- 2个千兆以上网口的网卡
数据节点(Datanode)的硬件配置应该根据不同应用的特点进行选配,使用Inceptor,Discover和Slipstream配置的用户需要比较高的计算能力的服务器,其数据节点的推荐配置如下:
- 2颗8核心或以上带超线程x86指令集CPU的服务器(比如Intel® Xeon® Gold-5218 Processor)
- 128GB以上内存
- 2个300G以上的硬盘做RAID1,作为系统盘
- 10个以上的2TB容量以上的硬盘作为数据存放硬盘
- 2个千兆以上网卡
TDH主要提供5款核心产品:Transwarp Inceptor是大数据分析数据库,Transwarp Slipstream是实时计算引擎,Transwarp Discover专注于利用机器学习从数据中提取价值内容,Transwarp Hyperbase用于处理非结构化数据,Transwarp Search用于构建企业搜索引擎。通过使用TDH,企业能够更有效的利用数据构建核心商业系统,加速商业创新。
- 系统盘可以做RAID1。数据盘若需要RAID,请做RAID0。
2.1.1 服务器的RAID配置
为了优化系统的性能和稳定性,星环科技要求对服务器做以下RAID配置:
- 对于新部署的集群(没有数据),服务器如果有RAID卡但没有开启,需要开启RAID卡,并给每块磁盘单独做RAID0;
- 对于正在使用的集群(有存量数据),如果服务器配置了RAID卡但没有开启,需要给NameNode,JournalNode,TCOS
Master的etcd,TxSQL,Guardian ApacheDS,ZooKeeper等服务对应的磁盘单独做RAID0; - 如果没有RAID卡,建议采购,并至少给NameNode,JournalNode,TCOS
Master的etcd,TxSQL,Guardian ApacheDS,ZooKeeper等服务对应的磁盘单独做RAID0。
三、安装前的检查
3.1 系统磁盘分区要求
系统安装和运行需要占用硬盘空间,在安装前操作系统硬盘必须留出300GB空间。对磁盘进行分区时需要遵守以下几点要求:
- 至少要分出swap和加载于“/”的系统分区。
- 推荐系统分区大小为200GB~300GB,并将该分区挂载到/目录。
- 请在某数据盘上为TxSQL预留不小于200GB的空间,并将TxSQL的data dir设置为该数据盘的某个目录(例如
/mnt/disk1/txsqldata/)。 - 推荐把每个物理磁盘挂载在 /mnt/disknn(nn为1至2位的数字)
上不同的挂载点。建议使用EXT4文件系统。每个这样的目录会被管理节点自动配置为HDFS DataNode的数据目录。 - HDFS DataNode的数据目录不能放在系统分区,以避免空间不足和IO竞争。同时也建议不要将数据分区和系统分区放在同一块磁盘上以避免IO竞争。除非整个HDFS规划空间不足,否则不要在系统分区所在磁盘上创建数据分区。
- 为了保证Docker运行的稳定性,需要专门给Docker分配一个磁盘分区,推荐分区大小为100~300GB。同时为了保障高可用,推荐在非Docker所在磁盘预留一个同样大小的空分区作为备用分区,以便在Docker所在磁盘发生故障时快速恢复服务。
- 为了保证流畅运行,请尽量把Docker卷组划分在数据盘下。如果数据盘较多且存储空间过剩,建议使用单独一块数据盘作为Docker分区。否则,建议将一块数据盘的一个分区作为Docker分区。
如果您使用的是RedHat或者CentOS系统,Docker分区 必须 使用XFS文件系统。其他磁盘或分区 推荐 使用EXT4文件系统。更多详细信息请参考 Docker官方文档。
在安装之前需要对docker分区进行格式化处理:
3.1.1 Redhat/CentOS
在Redhat/CentOS上,docker分区必须采用XFS格式,实现的步骤如下:
1.创建目录/var/lib/docker
mkdir -p /var/lib/docker
2.对分区进行xfs格式化
mkfs.xfs -f -n ftype=1 /dev/
3.挂载分区
mount /dev/ /var/lib/docker
4.进行验证,检查是否格式化成功
xfs_info /dev/ | grep ftype=1
如果该语句返回结果中有ftype=1字样,则说明格式化成功。
5.配置/etc/fstab
执行语句下述命令查看UUID:
blkid /dev/
将查到的UUID值添加在/etc/fstab中:
UUID=<UUID> /var/lib/docker xfs defaults,uquota,pquota 0 0
3.1.2 SUSE
在SUSE上,docker分区应采用ext4格式,处理实现的步骤如下:
1.创建目录/var/lib/docker
mkdir -p /var/lib/docker
2.对分区进行ext4格式化
mkfs.ext4 /dev/<p_name>
3.挂载分区
mount /dev/<p_name> /var/lib/docker
4.配置/etc/fstab
执行语句下述命令查看UUID:
blkid /dev/<p_name>
将查到的UUID值添加在/etc/fstab中:
UUID=<UUID> /var/lib/docker ext4 defaults 0 0
例 1. 磁盘资源不富余时的规划
某台机器有两块硬盘,容量都为600GB,分区及挂载目录将如下,其中/dev/sda1用作系统分区:
| 文件系统 | 大小 | 挂载目录 | 文件系统类型 |
|---|---|---|---|
| /dev/sda1 | 368GB | / | EXT4 |
| /dev/sda2 | 32GB | swap | |
| /dev/sda3 | 100GB | /var/log | EXT4 |
| /dev/sda4 | 100GB | (空,Docker备用分区) | XFS |
| /dev/sdb1 | 250GB | /mnt/disk1 | EXT4 |
| /dev/sdb2 | 250GB | /mnt/disk2 | EXT4 |
| /dev/sdb3 | 100GB | /var/lib/docker | XFS |
注意,这是磁盘资源不富余情形下的规划。如果磁盘资源比较富余,建议操作系统安装在单独磁盘上,防止数据分区与系统分区造成数据读写竞争,如下一个例子。
例 2. 磁盘资源富余时的规划
某台机器有6块硬盘,容量都为600GB,分区及挂载目录将如下,其中一块磁盘用作系统分区:
| 文件系统 | 大小 | 挂载目录 | 文件系统类型 |
|---|---|---|---|
| /dev/sda1 | 400GB | / | EXT4 |
| /dev/sda2 | 32GB | swap | |
| /dev/sda3 | 168GB | /var/log | EXT4 |
| /dev/sdb1 | 600GB | /mnt/disk1 | EXT4 |
| /dev/sdc1 | 600GB | /mnt/disk2 | EXT4 |
| /dev/sdd1 | 400GB | /mnt/disk3 | EXT4 |
| /dev/sdd2 | 200GB | /var/lib/docker | XFS |
| /dev/sde1 | 400GB | /mnt/disk4 | EXT4 |
| /dev/sde2 | 200GB | (空,Docker备用分区) | XFS |
3.2 磁盘目录规划要求
由于 NameNode,JournalNode,Ganglia,TCOS Master的etcd,TxSQL,Guardian ApacheDS,ZooKeeper等服务或角色对磁盘IO要求比较高,所以要求这些服务或角色目录不能在同一块磁盘上,并且不能全部在系统盘上,如果可以,应尽量都不安装在系统根目录。
上述服务或角色所使用的磁盘配置或路径如下。请按照以下路径,提前规划好磁盘使用目录,并在安装时检查相关配置项的值是否为正确路径。
| 服务 | 角色 | 配置项/路径 |
|---|---|---|
| TOS | TOS Master (etcd) | /var/etcd/data/ |
| Ganglia | Gmetad | /var/lib/ganglia/rrds/ |
| ZooKeeper | ZooKeeper Server | /var/ |
| HDFS | Name Node | dfs.namenode.name.dir |
| Data Node | dfs.datanode.data.dir | |
| Journal Node | hdfs-site.xml 中的配置项 dfs.journalnode.edits.dir,默认为 /hadoop/journal | |
| TxSQL | TxSQL Server | data.dir 和 log.dir |
| Guardian | ApacheDS | guardian.apacheds.data.dir |
| Guardian | TxSQL Server | data.dir |
| Transwarp Manager(开启HA时) | TxSQL Server | /var/lib/transwarp-manager/master/data/txsql/ |
3.3 内存容量要求
每个节点必须至少有64GB的RAM。根据节点所安装的Transwarp Data Hub服务,节点可能需要超过64GB的RAM。下表列出在节点上运行不同服务时,该节点所需的额外内存。
| 服务 | 要求 |
|---|---|
| Management Server | 8GB |
| HDFS NameNode | 32GB |
| HDFS Standby NameNode | 32GB |
| {HDFS DataNode | 4GB |
| Inceptor Server | 8GB |
| Inceptor executor | 32GB |
| YARN ResourceManager | 4GB |
| YARN NodeManager | 4GB |
| NodeManager分配给Container的计算资源数 | 用户指定 |
| Zookeeper | 4GB |
| HBase Master | 4GB |
具体节点需要内存的计算步骤如下所示:
1.确认所有会在节点上运行的TDH服务。
2.确认每个服务要求的内存容量。
3.将所有内存要求相加。
4.如果相加后内存要求小于64GB,则最低内存要求为64GB。如果相加后内存要求大于64GB,则最低内存要求为相加后的和。
比如,如果节点上运行以下服务:
- HDFS DataNode
- YARN ResourceManager
- HBase RegionServer
- YARN NodeManager分配给Inceptor executor为32G
- 则节点的内存容量要求如下(生产环境实际使用内存要结合具体的应用场景):4GB+4GB+32GB+32GB=72GB
3.4 网络设置
安装Transwarp Data Hub需要最低的网络为千兆以太网。当一台机器上有多个网络适配器时,用户可以在安装Transwarp Data Hub之前对其进行绑定配置。
3.5 集群和网络拓扑要求
- 决定集群中的节点数目。
- 决定集群中的机柜数目及每个机柜的名称。
- 决定每个机柜中的节点数目。
- 决定每个节点所在的子网(或多个子网)。
- 决定每个节点的主机名和IP地址。
- 决定哪个机器是管理节点。
- 决定哪些机器是NameNode。
- 决定哪些机器是客户端,哪些机器运行TDH服务,或二者兼是。
- 一旦主机名分配给NameNode,主机名则不能再更改。
- 确定你知道要加入到TDH集群中的每个节点的root密码。
- 管理节点必须和集群中的其他节点属于同一子网。
- 决定在集群中使用哪些组件。
- 决定网络带宽和交换机背板带宽。决定交换机型号。
- 决定如何连接到交换机。必须知道需要用到哪些以太网端口和是否需要绑定。
- 确定每台机器的IP地址和主机名。决定如何分配IP(使用DHCP或静态分配)。决定如何解析主机名(使用DNS或/etc/hosts)。如果使用/etc/hosts,管理节点将负责更新集群中每台机器的/etc/hosts。
3.6 NTP服务设置
决定如何进行时间同步。管理节点将负责所有服务器上的时间的同步,但您需要决定是否使用外部的NTP服务。如果不使用外部NTP服务,集群中所有服务器的时间是相同的,但这个时间有可能不是标准时间,这有可能导致集群与外部连接时产生错误。
3.7 安全设置
禁掉SELinux和iptables(Transwarp Manager会自动禁掉SELinux和iptables)。
3.8 系统的推荐设置
以下推荐配置可帮助确保TDH集群的性能优化和可管理性。
- 节点的主机名解析。注意,主机名只能由英文、数字和“-”组成,否则之后的安装会出现问题。
- 要同时添加一组节点到集群中。
- 要减少网络延迟,集群中的所有节点都必须属于同一子网。
- 每个节点应配置一块10GE的网卡,用于节点间的通信和执行集群中需要网络连接的任务。
- 如果节点没有使用10GE的网卡,则可使用网卡绑定以便将多个网卡组合在一起以提升网络流量。绑定的网卡必须使用工作模式6。
- 每个节点推荐最小的系统分区,至少有300GB的磁盘空间。
- 每个节点应至少有6T的可用磁盘空间用于HDFS。
- 集群中应至少有5个DataNode。
- 如果可能,避免将物理磁盘分为多个逻辑分区。除了系统分区外,每个物理磁盘应当仅有一个分区,且该分区包含整个物理磁盘。
- 仅使用物理机器,不要使用虚拟机器。虚拟机可能会明显导致HDFS I/O的缓慢。
- 节点所在的单个或多个子网不允许有其他机器。
- 集群中不能同时有物理机器和虚拟机器。
- 要确保集群中的机器不成为性能和I/O的瓶颈,所有机器必须有相似的硬件和软件配置,包括RAM、CPU和磁盘空间。
- 每个节点应至少有64GB的内存。
- 在管理节点上,由于集群中节点执行的系统监控,大量数据可被写入/var/lib/ganglia。推荐分配200GB(鉴于Ganglia非常消耗硬盘,建议根据节点数目调整该值)的磁盘空间给/var/lib/ganglia所在分区。
- 由于服务可能生成大量日志,推荐将/var/log放置在其他逻辑分区。这可保证日志不会占满根分区的空间。
- 要加快对本地文件系统的读取,可使用noatime选项挂载磁盘,这表示文件访问时间不会被写回。
四、TDH服务的角色
要在集群中运行服务,需要指定集群中的一个或多个节点执行该服务的特定功能。这些功能被归类为功能性的角色,角色用于定义节点能为集群中的服务提供哪些功能。角色分配是必须的,没有角色集群将无法正常工作。 在分配角色前,需要了解这些角色的含义,以及对应于服务节点需要哪些角色。
4.1 Transwarp_License_Cluster角色
| 角色 | 描述 |
|---|---|
| License Node | 提供License认证服务,判断许可证是否符合授权。 |
4.2 TCOS角色
| 角色 | 描述 |
|---|---|
| TCOS Master | 提供TCOS服务的主节点。 |
| TCOS Slave | 提供TCOS服务的备用节点。 |
| TCOS Registry | Image管理工具。 |
4.3 Flannel角色
| 角色 | 描述 |
|---|---|
| Flanneld | Flannel服务在节点上的代理服务。 |
| Kube Dns | Kubernetes DNS插件,用于发现服务和通过服务名访问服务。 |
4.4 Zookeeper角色
| 角色 | 描述 |
|---|---|
| Zookeeper Server | 一个或多个运行Zookeeper服务的节点。Zookeeper服务是指包含一个或多个节点的集群提供服务框架用于集群管理。对于集群,Zookeeper服务提供的功能包括维护配置信息、命名、提供Hyperbase的分布式同步,以及当 HMaster停止时触发master选择。Hyperbase需要有一个Zookeeper集群才能工作。 推荐在Zookeeper集群中至少有3个节点。 |
4.5 HDFS角色
| 角色 | 描述 |
|---|---|
| Httpfs | 对HDFS提供Web UI服务。允许用户在可视化界面上对HDFS进行操作和管理。 |
| Data Node | 在HDFS中,DataNode是用来存储数据块的节点。 |
| Name Node | HDFS系统中的节点,用于维护文件系统中所有文件的目录结构并跟踪文件数据存储于哪些数据节点。当客户端需要从HDFS文件系统中获得文件时,它通过和NameNode通讯来知道客户端哪个数据节点上有客户端需要的文件。 一个集群中只能有一个NameNode。NameNode不能被赋予其他角色。 |
| Journal Node | Standby NameNode和Active NameNode通过JournalNode通信,保持信息同步。 |
4.6 YARN角色
| 角色 | 描述 |
|---|---|
| Resource Manager | Resource Manager负责将各个资源部分(计算、内存、带宽等)安排给基础 NodeManager,并与NodeManager一起启动和监视它们的基础应用程序。 |
| Node Manager | Node Manager管理一个YARN集群中的每个节点。提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点的状态。 |
| History Server | 应用状态监控平台。 |
| Timeline Server | 提供对YARN的作业历史日志信息的展现服务。 |
4.7 Search角色
| 角色 | 描述 |
|---|---|
| Search Server | 提供内部搜索引擎服务。 |
| Search Head | Search 的网页版本的集群管理工具,支持数据的增删改查,并且可以通过语句进行可视化查询,是ES开发人员的一个非常有用的辅助工具。 |
4.8 Hyperbase角色
| 角色 | 描述 |
|---|---|
| Hyperbase Master | 节点实现Hyperbase数据库以下功能: 配区域给RegionServers,平衡整个集群。1.确认RegionServer在运行中。2.如果没找到参考值,删除parents。3.管理数据库表。4.在RegionServers中分发消息。5.监控RegionServers以决定是否有必要执行恢复,如果是,则执行恢复。可以分配HMaster角色给一个或多个节点以进行备份切换。如果你分配角色给多个节点,这将创建一个active-standby状态的HMaster节点的集群,即一个节点处于active状态而集群中的另一个节点处于standby状态。如果active状态的HMaster停止,Zookeeper集群将选出一个inactive状态的HMaster来作为active状态的HMaster。 |
| Region Server | 负责服务和管理Hyperbase区域的节点。 |
| Hyperbase Thrift | Thrift Client API开放的节点,客户端可通过Thrift和Hyperbase通讯。 |
4.9 TxSQL角色
| 角色 | 描述 |
|---|---|
| TxSQL Server | 高可用的元数据存储,支持数据访问,同Metastore进行通信。 |
4.10 TDDMS角色
| 角色 | 描述 |
|---|---|
| TDDMS Master | 管理所有Tablets、Tablet服务器以及其他集群相关的元数据。 |
| TDDMS Webserver | Web服务器。 |
| TDDMS Tablet Serve | 用于存储和管理Tablet。 |
4.11 Inceptor角色
| 角色 | 描述 |
|---|---|
| Inceptor Server | Inceptor运行的节点,帮助查询和管理HDFS的大型数据集。Inceptor Server提供工具从文件系统中提取、转换和装载数据,实施数据格式结构,以及提供HDFS或Hyperbase的直接文件访问。 |
| Inceptor MetaStore | 管理表结构及其元数据信息,从TxSQL中获取目标元数据。 |
| Inceptor Nucleon | 批处理任务的执行节点。 |
4.12 Pilot角色
| 角色 | 描述 |
|---|---|
| Pilot Server | 轻量的在线报表工具,支持多种报表样式,提供丰富美观的报表展现。 |
| Filerobot Server | 用于对接Pilot上对HDFS的操作。 |
4.13 EventStore角色
| 角色 | 描述 |
|---|---|
| EventStore Server | EventStore的任务管理工具。 |
| EventStore Rest | 提供EventStore Rest服务的服务器。 |
| EventStore Sentinel | Sentinel(哨兵)是用于监控EventStore集群中Master状态的工具,是EventStore的高可用性解决方案 |
4.14 Notification角色
| 角色 | 描述 |
|---|---|
| Notification Server | 提供消息通知服务。此服务覆盖TDH中所有具有通知功能的工具,如Governor。 |
4.15 Governor角色
| 角色 | 描述 |
|---|---|
| Governor Server | 负责提供对元数据的访问、历史跟踪、状态统计等功能,为用户提供数据治理服务。 |
4.16 KMS角色
| 角色 | 描述 |
|---|---|
| KMS Server | Hadoop密钥管理服务器。 |
4.17 Transporter角色
| 角色 | 描述 |
|---|---|
| Transporter Server | 提供Transporter ETL服务。实现数据的实时入库。 |
4.18 Workflow角色
| 角色 | 描述 |
|---|---|
| Workflow Server | 提供可视化的工作流设计,以及对工作流的调试、调度,对工作流任务具有丰富的分析功能。 |
4.19 Rubik角色
| 角色 | 描述 |
|---|---|
| Rubik Server | 提供对OLAP Cube的设计、创建、实例化服务。 |
4.20 KeyByte角色
| 角色 | 描述 |
|---|---|
| KeyByte Server | KeyByte服务器。 |
| KeyByte Slave | 集群模式下KeyByte副本服务器。 |
4.21 QuarkGateway角色
| 角色 | 描述 |
|---|---|
| Quark Gateway | Inceptor网关服务器。 |
4.22 日志分析组件角色
| 角色 | 描述 |
|---|---|
| Filebeat | 负责采集日志数据并写入EventStore topic。 |
| Logstash | 负责把数据从对应的EventStore topic写入Search index。 |
| Kibana | 为Logstash和Search的日志分析提供友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。 |
| EventStoreManager | 管理整个平台公用的EventStore集群。 |
| Crontab | 用于调度定时或周期性执行的任务。 |
4.23 Discover角色
| 角色 | 描述 |
|---|---|
| Discover IDE | RStudio是一个R的集成开发环境(IDE),它包括一个控制台和语法编辑器,支持直接代码执行,提供绘图、历史、调试和工作区管理等工具。 |
| Discover Notebook | 轻量的科学计算开发工具。支持使用R、Scala和SQL做数据分析,提供方便的交互界面。 |
| Discover Local-Cran | 本地的R语言程序库。 |
4.24 Slipstream角色
| 角色 | 描述 |
|---|---|
| Slipstream Server | 接收流计算请求,实现任务分配的服务。 |
| Slipstream Metastore | 管理和流相关的表结构及其元数据信息,从TxSQL中获取目标元数据。 |
| Slipstream History Server | 装载Slipstream任务的运行信息并以Web的方式供用户浏览。 |
| Slipstream Executor | 流计算的执行节点。 |
4.25 Slipboard角色
| 角色 | 描述 |
|---|---|
| Slipboard | Slipstream开发工具套件。 |
五、安装准备
5.1 操作系统安装
在安装Transwarp Data Hub之前,集群中的所有节点必须满足环境要求和安装前的检查中所列举的所有要求。
可以使用两种方式来安装集群中的服务器的操作系统,单独安装方式和PXE安装方式。
其中单独安装方式是使用Red Hat Enterprise Linux for Servers、CentOS系列或SUSE Linux Enterprise Server的安装光盘在每台服务器上独立安装操作系统。
注意:对于Red Hat Enterprise Linux for Servers、CentOS 系列的操作系统,需要使用visudo命令打开/etc/sudoers配置文件:
# visudo
将该文件中的“Defaults requiretty”注释掉
如要使用非root用户安装产品,使用的用户必须拥有sudo权限。所以,管理员需要向/etc/sudoers文件中添加sudo用户。方法为在该文件以下部分最后一行的内容:
## which machines (the sudoers file can be shared between multiple
## systems).
## Syntax:
##
## user MACHINE=COMMANDS
##
## The COMMANDS section may have other options added to it.
##
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
[sudo用户] ALL=(ALL) NOPASSWD: ALL
例如,如果为用户admin添加sudo权限,在文件的末尾增添的内容是:
admin ALL=(ALL) NOPASSWD:ALL
5.2 安装前系统配置改动
如果您有DNS,那么您可以直接跳到下一节。如果您没有DNS,在安装前,请打开包含Transwarp Manager在内的每个节点下的/etc/hosts文件,确保该文件包含所有节点的hostname和IP地址的映射关系列表,例如:
172.16.2.124 tw-manager
172.16.2.125 tw-node2125
172.16.2.126 tw-node2126
您可以登入到节点使用 hostname 命令检查节点主机名,确保节点名称与上述 /etc/hosts 里设置的名称相同。请注意,集群的节点名称不能重复,且必须符合DNS-1123规范,由数字、小写字母或“-”组成,不能包含大写字母,长度小于63。
您可以使用 hostnamectl set-hostname hostname 命令来修改主机名,参考以下示例:
[root@localhost ~]# hostnamectl set-hostname tw-node2125
[root@localhost ~]# hostname
tw-node2125
请注意 /etc/hosts 文件的第一行必须为127.0.0.1的记录,不能将此行注释掉,也不能将当前主机名写在该行中。通常如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
5.3 安装介质
5.3.1 安装介质获取方式
5.3.2 安装介质使用说明
如果有安装光盘可将安装光盘插入服务器CD/DVD ROM中直接运行。由于安装过程中会使用到操作系统的安装介质,建议用户将OS的ISO文件事先拷贝到管理服务器上。
如客户服务代表或技术支持提供的是压缩包,请将压缩文件导入服务器中。
目前TDH共提供以下三个压缩包:
- Manager安装包
- TDH-Basic-Component-Transwarp-8.1.0-X86_64-snapshot.tar.gz (8.1.0版本)
TDH-Platform-Transwarp-version.tar.gz (8.1.0版本) - TDH除Discover外所有产品的产品包
- TDH-Image-Registry-Transwarp-8.0.x-final.tar.gz
为了更好的支持不同产品线的产品,Transwarp Manager自6.0版本开始独立安装。
您需要先安装Transwarp Manager,之后再上传产品包来安装相应产品。
六、安装Manager
本章节将详细描述如何在管理节点上安装Manager。
注意,在安装之前请确保已经按照安装前的检查的要求为Docker分配专门的分区。
6.1 安装Manager
Manager的安装需要先解压安装包,然后运行Web Installer使用图形化界面安装。
1.解压Manager安装包。在安装包所在的服务器上运行以下命令:
# 解压出安装目录
tar xvzf <manager-install-pkg>
# 进入解压后的transwarp目录
cd transwarp
#执行install二进制文件
./install
为Manager安装包的名称,通常为 TDH-Platform-Transwarp-version.tar.gz,具体名称请参阅“5.3 安装介质”小节。
2.通过浏览器访问管理节点,进入Web Installer界面。

3.系统首先需要您阅读Java许可。阅读完毕,点击“同意”进入下一步。

4.系统将自动检查管理节点的环境配置,主要包括时间、日期、时区及主机名信息并显示在屏幕上,请确认。

5.取决于管理节点上的网卡数量,您需要进行如下操作:
- 如果管理节点上只有一块网卡,安装结束后,您会被要求设置
Transwarp Manager端口,推荐默认端口“8180”。

- 如果管理节点上有多块网卡,系统会要求您从中选择一块网卡,用于Transwarp Manager和集群中其他节点通信。在这一步,您应该选择用于集群内部通信的网卡。
6.等待安装

7.安装Manager需要一个包含对应版本操作系统的资源库(repo)。如果您的操作系统为CentOS或者Red Hat,您会看到如下提示:
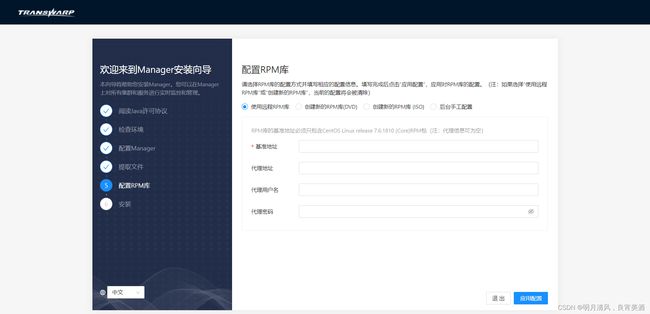
8.(该步骤中所有操作以CentOS/Red Hat系统为例,SUSE系统的操作完全相同,区别在于如果您使用的是SUSE系统,示例步骤中显示“yum”的地方将会在您的操作中显示“zypper”)这一步中,您可以选择是否添加一个新的操作系统资源库。取决于您的选择,您需要进行下面的操作:
- 如果您选择“使用远程RPM库”,您需要输入已经创建好的资源库的URL:
 - 如果您选择“创建新的RPM库(DVD)”,您需要准备好对应版本操作系统的光盘。
- 如果您选择“创建新的RPM库(DVD)”,您需要准备好对应版本操作系统的光盘。
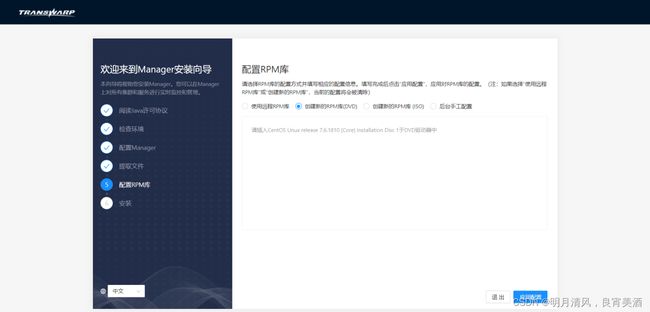
- 如果您选择“创建新的RPM库(ISO)”,您需要准备好对应版本操作系统的ISO文件。我们 建议 您采用ISO镜像方法生成资源库库包。

- 如果您选择“后台手工配置”,您在该步骤无需进行其他操作。
您进行选择后,系统会清理资源库缓存:


9.资源库缓存清理完毕后,系统会自动开始安装和配置Transwarp Manager。安装程序会自动安装必需的软件包,全程静默安装,安装配置完成后自动跳转到下一步。
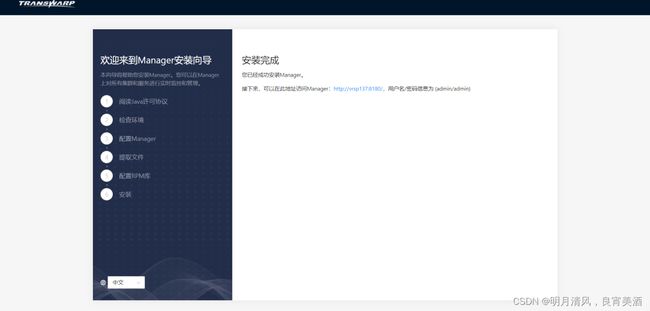
10.Manager安装完成,可以访问提示的安装地址并使用默认的用户名/密码(admin/admin)去登录管理界面继续接下来的配置。
6.2 升级Manager
如果您的节点上已安装以前版本的Transwarp Manager,您也可以通过Web Installer来进行升级。
1.请先执行安装Transwarp Manager中的第1步,运行Web Installer。
2.通过浏览器访问管理节点,如http://:8179,进入升级页面,选择升级:

3.可以看到系统已经预先填写好Manager的升级配置,如果没有特殊需求,不建议对此页配置进行更改。

4.点击“继续”,进入环境检查页面:

5.如果环境检查出错,您可以返回上一步对配置进行修改,也可以手工修改后在此页面点击重试。环境检查通过后,系统会开始进行升级,可以看到如下页面:


6.升级可能需要一段时间,完成后看到如下页面表示升级成功。

如果升级失败,页面会显示失败信息,您可以点击“重试”可以重新开始升级,或者点击“回滚”则可以将Manager恢复到升级前的状态。
七、配置集群
1.打开客户端浏览器(推荐使用Google Chrome浏览器),输入安装好的管理节点IP或DNS地址,比如http://172.16.3.108:8180/(172.16.3.108是管理节点的IP地址)。访问这个地址,您会看到下面的登录页面。Manager会试着根据您的系统判断您使用的语言,如果当前显示的语言和您想要使用的不同,可以点击右上角的language icon来选择语言。目前Manager支持中文和英文:

2.以admin的身份登录,密码也是admin。
3.登录后,您需要先接受最终用户协议才可以进行进一步操作:
4.您需要给您的集群设置一个名字。输入集群名字后点击“下一步”:

7.1 全局设定
7.1.1 DNS配置
如果配置集群中的节点可以通过用主机名互相访问,用户必须配置有效的DNS服务器或/etc/hosts文件。否则请选择需要管理工具配置/etc/hosts,Transwarp Manager会相应为您配置/etc/hosts文件,然后添加节点。
7.1.2 NTP配置
使用NTP服务器可以确保集群中节点时钟同步,您可以指定外部的NTP服务器或者依赖Transwarp Manager自动选择一台节点作为内部NTP服务器。
要使用外部NTP服务器为您的集群保证时钟同步,您需要确保您的集群可以连接到该外部NTP服务器。
如果您需要使用外部NTP服务器,选择“所有节点向外部NTP同步”或“内部NTP服务器向外部NTP同步,其它节点向内部NTP服务器同步”,如下图所示。点击“添加NTP服务器”,输入您想要添加的NTP服务器,并点击“测试链接”来测试添加的NTP服务器的连接。多次点击“添加NTP服务器”可以让您添加多台外部NTP服务器。

全局设定完成后,点击“下一步”。
7.2 添加/刪除集群服务器
您可以在此步骤添加/删除/修改机柜,添加节点,以及配置RPM库。
1.点击机柜的名字和描述可以对它们进行编辑。节点数会随着您之后的配置自动改变。完成后点击“下一步”。
您可以在这一步添加新的RPM库。自5.2版本起,TDH支持集群的节点运行在不同的操作系统上,您只需要添加RPM库配置,并为节点配置相应的RPM库即可。

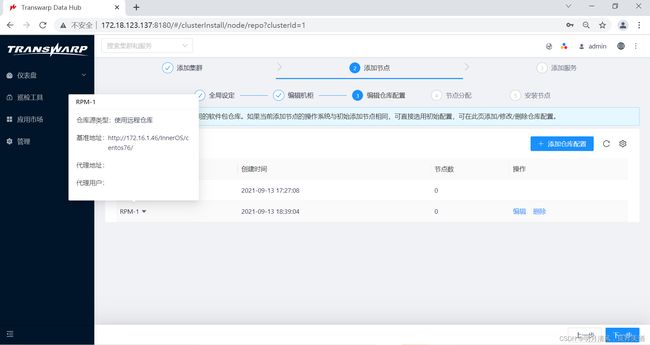
2.点击“添加RPM库配置”,并填写相关配置:

3.完成后,点击“保存”来保存您的配置。您可以点击相应RPM的下拉箭头看到详细配置信息:
4.点击“下一步”,为您的集群分配节点。
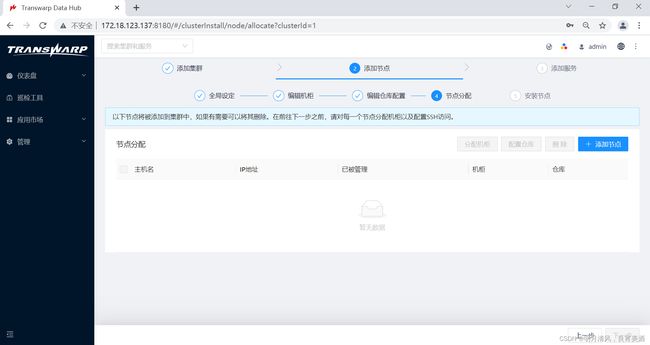
5.点击“添加节点”,在弹出窗口中按照提示输入符合格式的节点IP,然后点击“搜索”,Transwarp Manager会搜索您输入的节点:

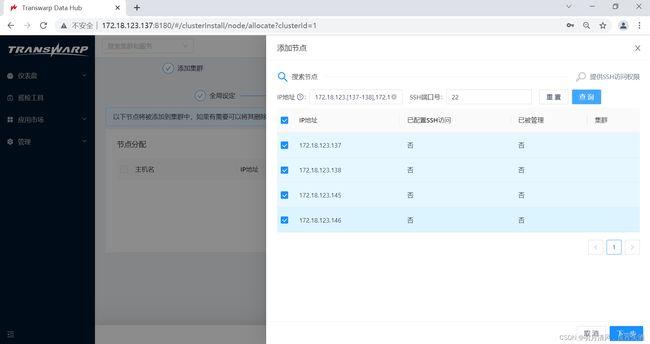
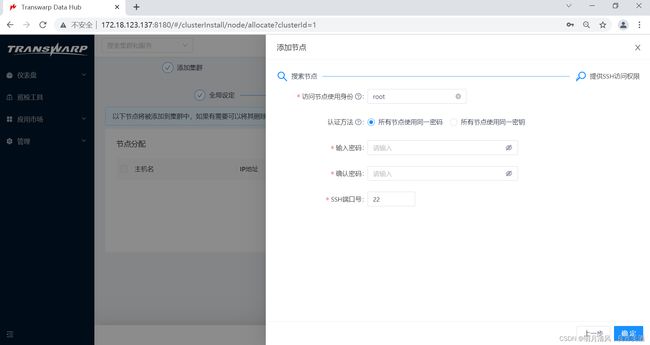
6.点击“继续”,将出现进行SSH访问权限配置的界面,在该节点上您可以选择访问节点使用身份,并且提供了两种认证方法:
- 所有节点使用同一密码
如果您选择此选项,请在对应的输入框中输入您管理节点的密码、确认密码、输入ssh端口号:
- 所有节点使用同一密钥
如果您选择此选项,请点击 选择文件 按钮,在目录窗口中选择待上传的密钥文件,并输入ssh端口号;也可以输入密钥口令(可选):

7.上述配置完成后,点击“完成”。节点便添加完成。如果只有一个机柜,Transwarp Manager会自动将所有节点分配给默认机柜。如果您有多个机柜,您可以通过点击“分配机柜”来指明节点和机柜之间的分配关系。如果您的集群中有6个以上的节点,那么您必须配置机柜信息,方便以后的运维和服务配置。

8.在这一步您可以为节点分配RPM库,点击“配置RPM库”,选择一个RPM库。默认使用初始配置。节点添加工作完成后,点击“下一步”继续。
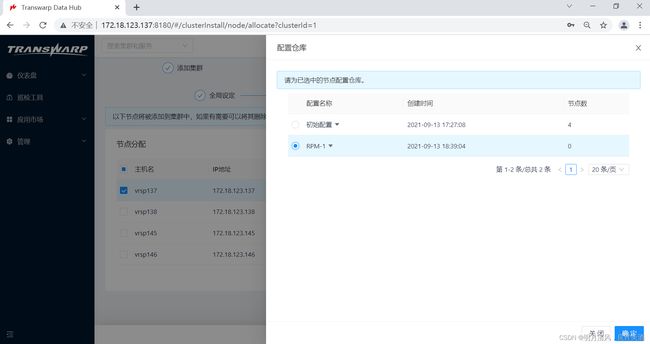
9.系统会开始自动添加节点,添加节点的过程会进行一段时间,成功后您会看到成功页面。
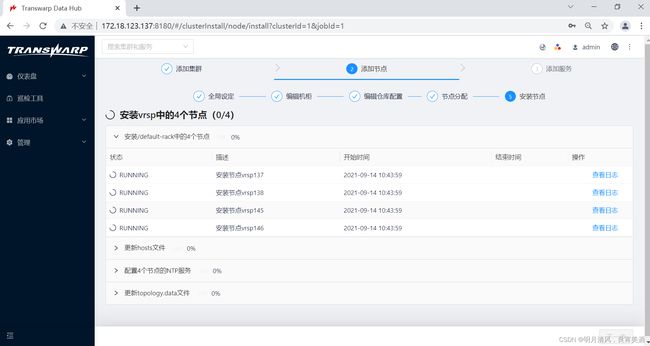
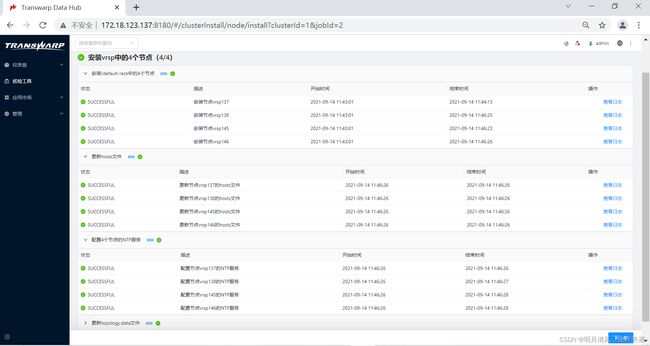
10.点击“下一步”开始向集群安装服务。
如果您已经安装完成,可以在Manager的管理页面向集群添加新的节点。具体步骤请参考《TDH运维手册》。
八、安装服务
接下来,我们介绍如何使用Transwarp Manager向集群安装TDH的服务。
8.1 上传产品包
自6.0版本开始,Transwarp Manager作为一个单独的产品安装,各产品线的产品需要在Transwarp Manager的应用市场里先上传产品包,而后Transwarp Manager会自动完成解压,取代了之前版本的手动解压步骤,使安装服务更加便捷,并且更加灵活,例如,您可以上传不同版本的产品包,来安装不同版本的服务。
TDH的产品包名称请参考安装介质小节。
如果您刚刚完成第一个集群的节点安装,您可能会进入以下界面:
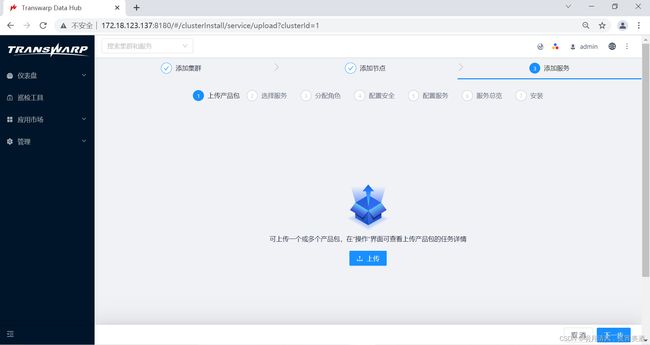
在此界面您可以直接点击上传来选择产品包上传。您也可以点击取消,回到Manager主界面,稍后再按照以下步骤上传产品包:
1.从Manager菜单点击 应用市场,打开应用市场页面:

2.进入应用市场默认页面,从左侧导航栏点击 上传产品包。

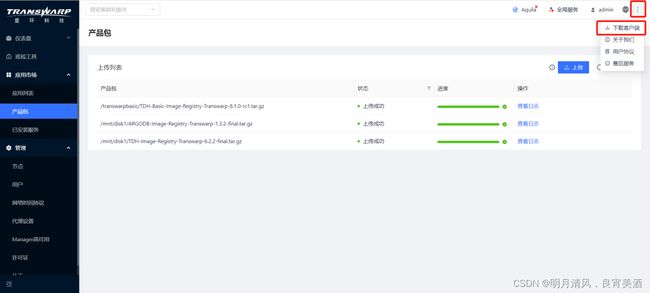
3.在上传产品包页面,点击左上角的 上传,并在以下弹出窗口中选择产品包的位置:

4.上传需要一段时间,完成后可以看到状态图标。您也可以点击产品包右侧的查看日志来查看上传进程。
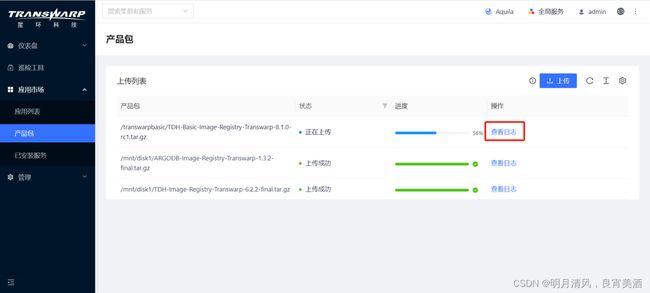

5.上传成功后,相应的服务将会出现在安装服务时的选择服务页面。


8.2 选择服务
在安装服务之前请再次确认已按照安装前的检查的要求分配资源,并已成功上传产品包。只有产品包上传成功的产品才会出现在选择服务页面。
TDH中,各个服务将被包装为容器,安装在TCOS上。TCOS是基于Docker和Kubernetes的云操作系统,在部署安装TDH服务时不会显示在服务列表中,默认安装,无需您手动添加。但您可以在后续步骤 服务角色的分配 和配置服务页面为TCOS服务分配角色和配置参数、属性等。
安装TxSQL前请保证在某个数据盘上已为TxSQL预留至少200G的空间,并且将TxSQL的data dir设置为该磁盘下的某个目录。
- 左侧为服务所属产品与版本选择,右侧为具体的服务。当某个产品被上传时,属于该产品的所有服务都将在右侧被列举出来。
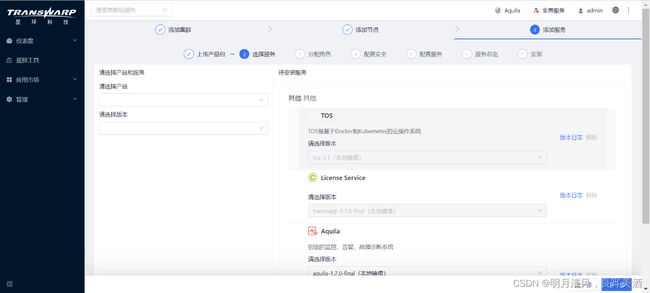
- 如果您上传了多个版本的产品包,您可以点击选择要安装的版本

- 点击下一步安装所选择的服务。
8.3 服务角色的分配
选择想要安装的服务之后,接下来分配各项服务的角色。各服务角色都对应若干个勾选框,每个勾选框代表集群中的一个节点。分配角色的方法为勾选或取消勾选服务右侧对应的节点,被选中的节点将承担该服务角色。例如下图中,四个勾选框被选中代表集群中的这四个节点将承担TOS Slave角色。
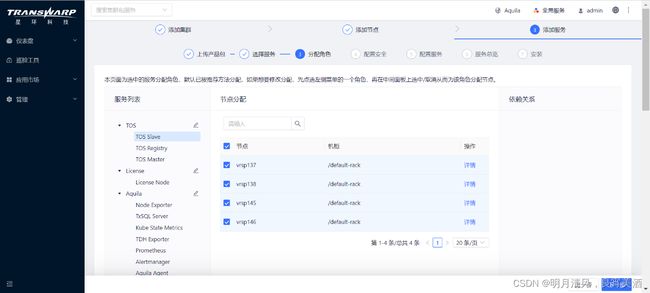
Transwarp Manager对服务的角色提供默认分配,如果您想要使用默认的分配,可以点击“下一步”直接进行配置。但是我们推荐您根据实际的生产场景进行规划,同时我们推荐遵守下面的一些分配原则:
- 首次安装集群时需要安装TCOS角色和License角色。TOS Registry角色 必须 安装在Transwarp
Manager所在节点。TOS Slave角色需要安装在每个节点上。 - 推荐 将Zookeeper角色分配给 奇数 个节点,建议集群大小在20个节点以下配置3个,20个节点以上配置5-7个,不超过7个。
- 在集群资源宽裕的情况下,将HDFS
NameNode和DataNode配置给不同的节点,也就是说避免同一节点既是NameNode又是DataNode的情况。 - 推荐 将Hyperbase Master角色分配给 奇数 个节点。
- 分配了Hyperbase RegionServer的节点 必须 同时拥有HDFS DataNode角色。
8.3.1 部署角色多实例
自6.0版本起,Transwarp Manager支持同一个节点上部署同一角色的多个实例。如果服务的某一些角色支持多实例,那么服务创建之后,Transwarp Manager会将每个角色实例放到一个实例组里。您只需要在分配角色步骤添加一个实例组,就可以创建一批角色实例,再为它们分配节点即可。
例如下图中,默认创建了instancegroup1,点击 + Instance Group 创建实例组instance2,在右侧为它分配节点,即可完成多实例部署。

如果您已经安装完成,您也可以在Transwarp Manager的节点页面通过添加节点来扩容角色。具体步骤请参考《TDH运维手册》。
8.3.2 角色属性配置

Transwarp Data Hub中每个服务都可以设置该服务在集群中的服务名,用于在集群中指代该服务,这里显示的是HDFS服务的编辑页面。
如果不设置,默认服务名为“服务+整数”,这是因为在集群计算资源允许的情况下,一些服务可以在集群中有多个实例,这些实例工作时需要通过服务名互相区分(如Zookeeper1和Zookeeper2)。在第一次安装集群时,每个服务都只能安装一个实例,额外的服务实例可以向安装好的集群添加。
8.4 配置安全
您可以在这一步进行安全配置。如果您当前还没有安装Guardian,您可以选择简单认证模式。如果您安装了Guardian,您可以在这一步选择Kerberos认证模式,并输入KAdmin票据名和密码开启Guardian插件。


8.5 服务的配置
服务的配置非常重要,请您务必在这一步仔细检查每一项服务的配置。在“配置服务”下,您可以为所有的服务进行配置。
8.5.1 服务的可配置项
Transwarp Data Hub中的每个服务都自有一系列的可配置项。
通用的可配置项包括(以Zookeeper服务为例):
基础参数:
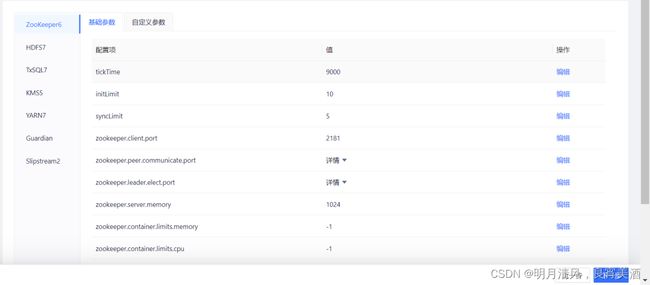
这里显示的是Zookeeper服务的基础参数配置页。如果没有特殊要求,您可以直接使用Transwarp Manager对基础参数提供的默认值。基础参数值不仅在这一步可以设置,安装完成后还可以在服务配置页面进行修改。
基础参数分为节点特定参数(例如上图中的 zookeeper.peer.communicate.port, zookeeper.leader.elect.port )和非节点特定参数(例如上图中的 tickTime,init.Limit 和 syncLimit )。
- 对于非节点特定参数,直接点击右侧的编辑便可以进行修改。
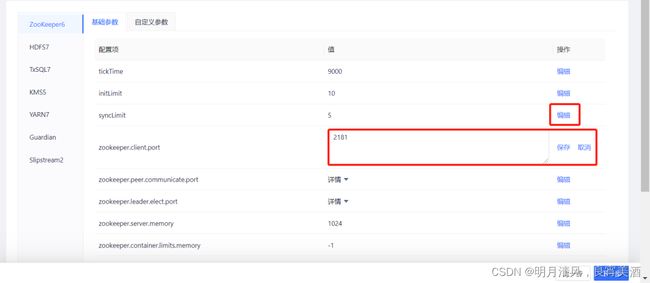
- 对于节点特定参数,点击右侧红框中的编辑来打开为节点分别配置的窗口:
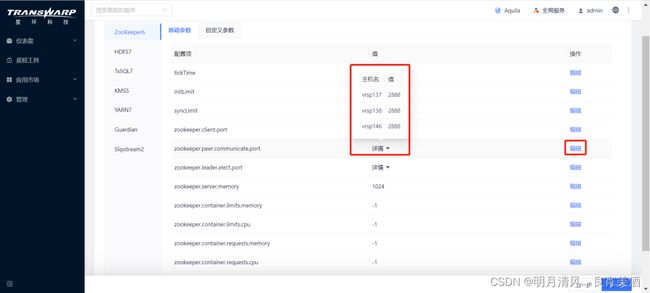

然后点击节点对应的值进行修改。 - 自定义参数:

所有服务都可以添加自定义参数。这里显示的是Zookeeper服务的自定义参数配置页。 - 属性
Transwarp Data Hub中部分服务可以配置属性,这里显示的是Guardian服务的属性配置页。

8.5.2 特殊配置要求
- TDDMS参数配置
请注意 tabletserver.store.datadirs 参数在部署时会默认选择本机所有容量超过200GB的挂载点作为数据目录。如本机不存在容量超过200GB的挂载点,请手动指定数据目录。
- 特定角色的配置要求
由于 NameNode,JournalNode,TCOS Master的etcd,TxSQL,Guardian ApacheDS,ZooKeeper等服务或角色对磁盘IO要求比较高,所以要求这些服务或角色目录不能在同一块磁盘上,并且不能全部在系统盘上,如果可以,应尽量都不安装在系统根目录。
上述服务或角色所使用的磁盘配置或路径如下。请检查相关配置项的值是否为正确路径。
| 服务 | 角色 | 配置项/路径 |
|---|---|---|
| TOS | TOS Master (etcd) | /var/etcd/data/ |
| ZooKeeper | ZooKeeper Server | /var/ |
| HDFS | Name Node | dfs.namenode.name.dir |
| Data Node | dfs.datanode.data.dir | |
| Journal Node | hdfs-site.xml 中的配置项 dfs.journalnode.edits.dir,默认为 /hadoop/journal | |
| TxSQL | TxSQL Server | data.dir 和 log.dir |
| Guardian | ApacheDS | guardian.apacheds.data.dir |
| Guardian | TxSQL Server | data.dir |
| Transwarp Manager(开启HA时) | TxSQL Server | /var/lib/transwarp-manager/master/data/txsql/ |
8.6 服务的安装
配置好参数后,点击“下一步”,在出现的如下所示窗口中可以看到配置信息总览,如果需要修改,可点击“上一步”返回修改。

确认配置信息后,点击 下一步 准备执行安装。
此时,Transwarp Manager会弹出一个“安装确认”窗口确认开始安装。点击“确认”继续。
安装开始,系统将花费一些时间安装您所选中的服务,请耐心等待。
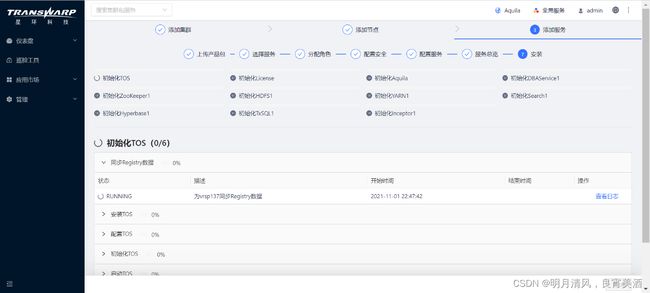
安装完成后,点击“完成”进入Transwarp Manager的控制面板。

8.7 安装TDH客户端
服务安装完成后,用户必须安装TDH客户端,才可以在交互界面上执行各个服务的命令行,如 beeline 、hdfs dfs 等。
8.7.1 安裝步驟
安装过程如下。
1.获取安装包
在Transwarp Manager界面上点击icon manage → 下载客户端 ,下载TDH客户端。
2.解压文件
将下载的tdh-client.tar文件放在集群中的任意机器上,然后于该机器上执行如下命令解压文件:
tar -xvf tdh-client.tar
执行成功后文件会被解压至目录TDH-Client中。
3.执行脚本
请执行位于目录TDH-Client内的脚本init.sh。
source TDH-Client/init.sh
您可以以任何用户执行该脚本,但是我们建议以root用户身份执行。当以其他用户身份执行时,需要输入root密码。
注意 ,用户必须使用source命令执行该脚本。 bash init.sh 和 ./init.sh 都不起作用。
该脚本接受两个参数,默认都是y。第一个参数表示是否修改/etc/hosts文件(y 表示修改,n表示不修改),第二个参数表示是否安装Kerberos Client (y 表示安装,n 表示不安装)。
因此有如下表格所示的组合方式:
| 命令 | 含义 |
|---|---|
| source TDH-Client/init.sh | 修改/etc/hosts文件,并且安装Kerberos client |
| source TDH-Client/init.sh y y | 修改/etc/hosts文件,并且安装Kerberos client |
| source TDH-Client/init.sh y n | 修改/etc/hosts文件,不安装Kerberos client |
| source TDH-Client/init.sh n y | 不修改/etc/hosts文件,安装Kerberos client |
| source TDH-Client/init.sh n n | 不修改/etc/hosts文件,并且不安装Kerberos client |
当使用source命令执行完脚本后,如果输出结中没有出现ERROR,则表示成功。此时可以直接执行相关服务的命令。
注意:
1.TDH客户端既可以在集群內也可以在集群外的任意机器上使用。目前只支持Linux环境(CentOS, Ubuntu等),不支持Windows环境。
2.如果用户修改了集群中服务的配置文件(例如从未开启Kerberos变成开启Kerberos),需要重新下载TDH客户端,并重新安裝。
3.当开启了Kerberos后,在执行相关服务的命令前,务必注意先进行kinit。
4.TDH客户端不会自动拷贝keytab文件,所以当它所在的机器本身没有keytab文件时,无法通过kinit -kt的方式进行kinit。此时必须通过kinit ,并根据提示输入该principal密码的方式进行kinit。
九、向集群添加服务
在安装完您所选择的服务后,您还可通过Transwarp Manager主界面向集群新增服务。
以下,我们将以EventStore服务为例,演示如何在Transwarp Manager主界面添加并安装服务。
1.点击Transwarp Manager主页面上集群名旁的
 ,您将进入添加服务向导。
,您将进入添加服务向导。

2.进入选择服务页面,选择Slipstream,点击“下一步”。

3.选择服务版本,这里会显示出您在上传产品包步骤上传成功的所有版本,选择一个版本。

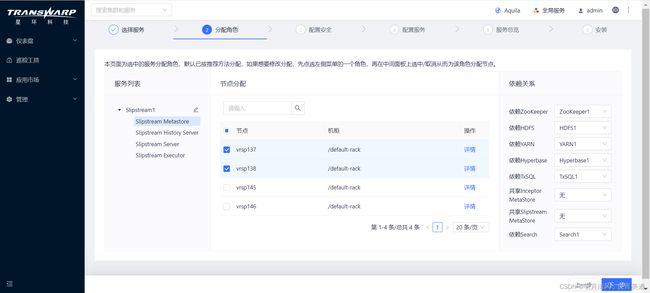
4.接下来,您需要为Slipstream服务分配角色,若您需要更改依赖的具体服务可在右侧列表中选择,完成后点击“下一步”继续。
5.配置安全。如果您当前还没有安装Guardian,您可以选择简单认证模式。如果您安装了Guardian,您可以在这一步选择Kerberos认证模式,并输入KAdmin票据名和密码开启Guardian插件。

6.这一步,您需要为Slipstream进行服务配置:
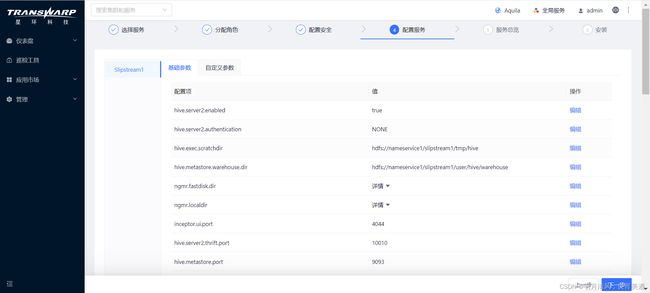
配置完成后点击“下一步”。
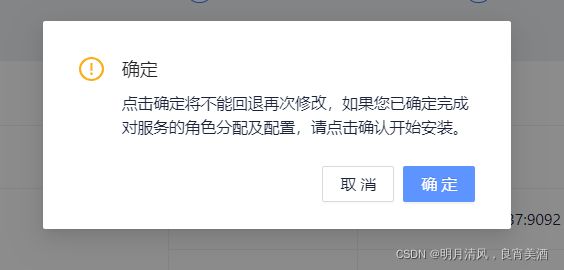
7.进入服务总览页面,确认配置无误后,点击“下一步”:

弹出“安装确认”弹框,点击“确认”,开始安装:
8.安装过程一般需要几分钟时间。安装成功后点击“完成”,完成Slipstream安装。

十、集群扩容指导
这里仅介绍为TDH环境增加数据节点的扩容步骤,不涉及在原来的节点上增加硬件资源以及进行角色迁移的操作。TDH的节点扩容主要包含扩容前节点检查、扩容节点操作2个步骤。
10.1 扩容前节点检查
与安装TDH前检查的操作类似,在扩容前需要检查新节点的软硬件配置是否符合要求,请参考《TDH安装手册》中的第二章:环境要求和第三章:安装前检查要求
10.2 扩容节点操作
扩容操作流程包括 添加节点 和 扩容角色 2个阶段。添加节点即添加新的集群节点,扩容角色指为新节点分配服务。
10.2.1 添加节点
首先,打开浏览器,访问http://
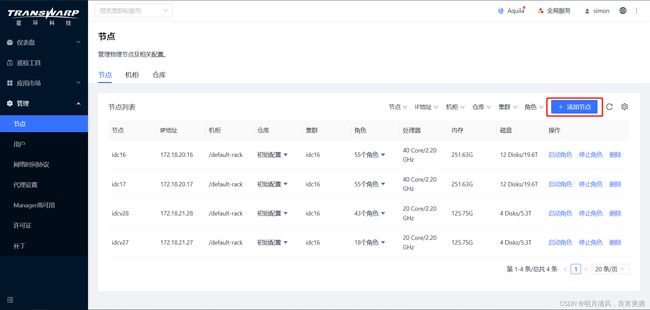
10.2.1.1 选择集群
进入扩容节点向导后,选择需要增加节点的集群。完成后点击“下一步”。
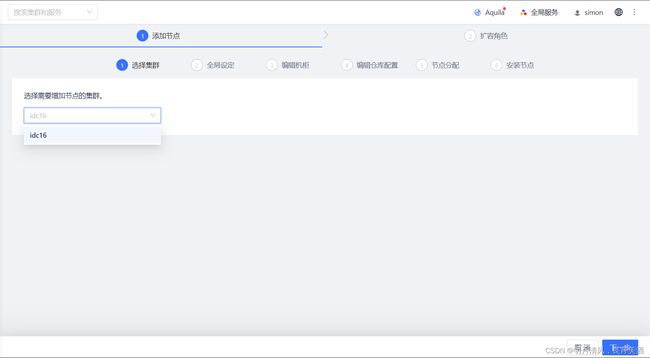
10.2.1.2 全局设定
1.DNS配置
如果配置集群中的节点可以通过用主机名互相访问,您必须配置有效的DNS服务器或/etc/hosts文件。否则请选择需要Transwarp Manager配置/etc/hosts,Transwarp Manager会相应为您配置/etc/hosts文件。建议和集群安装时的设置保持一致,完成后点击“下一步”。
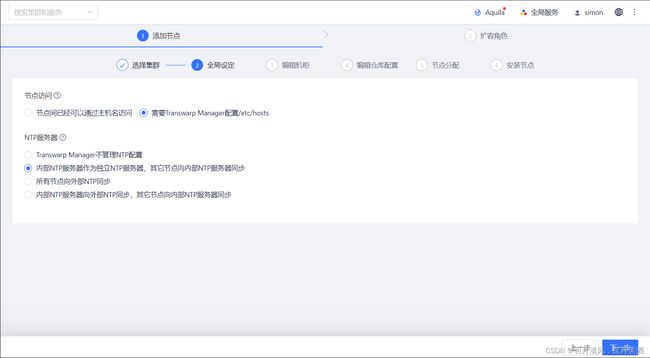
1.NTP配置
使用NTP服务器可以确保集群中节点时钟同步,您可以指定外部的NTP服务器或者依赖Transwarp Manager自动选择一台节点作为内部NTP服务器。建议和集群安装时的设置保持一致。
要使用外部NTP服务器为您的集群保证时钟同步,您需要确保您的集群可以连接到该外部NTP服务器。
如果您需要使用外部NTP服务器,选择“所有节点向外部NTP同步”或“内部NTP服务器向外部NTP同步,其它节点向内部NTP服务器同步”,如下图所示。点击“添加NTP服务器”,输入您想要添加的NTP服务器,多次点击“添加NTP服务器”可以让您添加多台外部NTP服务器。点击“下一步”时,Manager会自动测试添加的NTP服务器的连接。

全局设定完成后,点击“下一步”。
10.2.1.3 编辑机柜
编辑机柜步骤与安装步骤中编辑机柜类似,可以添加机柜来分配扩容过程中新增的节点。点击 ![]()
按钮,点进入机柜添加向导过程,如下:
在该步骤中只能新增机柜,或对新增的机柜进行编辑操作,已配置的机柜信息不可修改或编辑。

完成机柜编辑后点击“确认”,点击“下一步”。
10.2.1.4 配置仓库
配置仓库步骤与安装步骤中配置仓库类似,默认选择集群安装时的初始配置,您也可以在这一步添加新的RPM库。自5.2版本起,TDH支持集群的节点运行在不同的操作系统上,您只需要添加RPM库配置,并为节点配置相应的RPM库即可。点击 ![]()
,并填写相关配置,如下图:
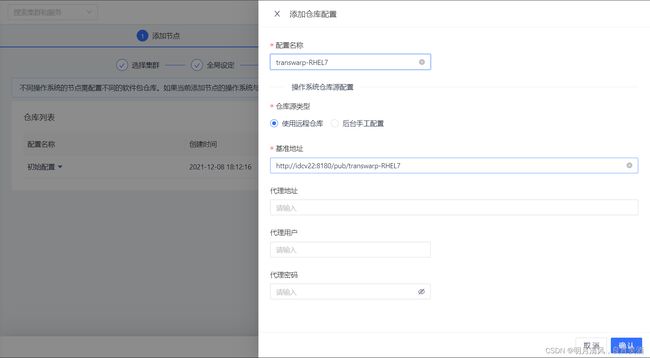
完成后,点击“确认”来保存您的配置。您可以拖动鼠标到相应RPM的下拉箭头看到详细配置信息:
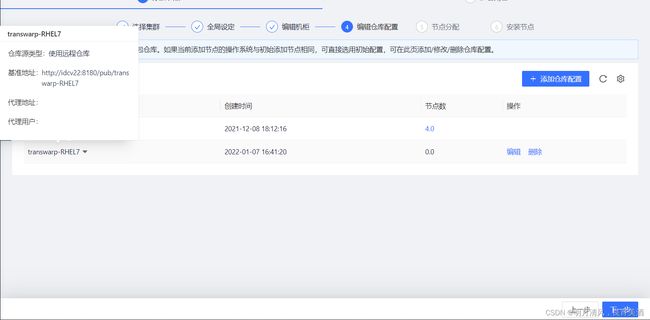
点击“下一步”,为您的集群分配节点。
10.2.1.5 节点分配
添加节点
节点分配步骤与安装步骤中节点分配类似,点击 ![]()
,在弹出窗口中按照提示输入符合格式的节点IP,然后点击“搜索”,Transwarp Manager会搜索您输入的节点,勾选需要扩容的节点进行添加。

点击“下一步”,将出现进行SSH访问权限配置的界面,在该节点上您可以选择访问节点使用身份,并且提供了两种认证方法:
- 所有节点使用同一密码
如果您选择此选项,请在对应的输入框中输入您管理节点的密码、确认密码、输入ssh端口号:

- 所有节点使用同一密钥
如果您选择此选项,请点击 选择文件 按钮,在目录窗口中选择待上传的密钥文件,并输入ssh端口号;也可以输入密钥口令(可选):

点击“确定”后,回到节点分配界面对节点进行机柜和仓库配置。
分配机柜
勾选需要分配机柜的节点,点击“分配机柜”为节点进行配置,如果您有多个机柜,以此来指明节点和机柜之间的分配关系,方便以后的运维和服务配置。

配置仓库
勾选需要分配RPM库的节点,点击“配置仓库”选择一个RPM库。配置完成后,点击“确定”继续。
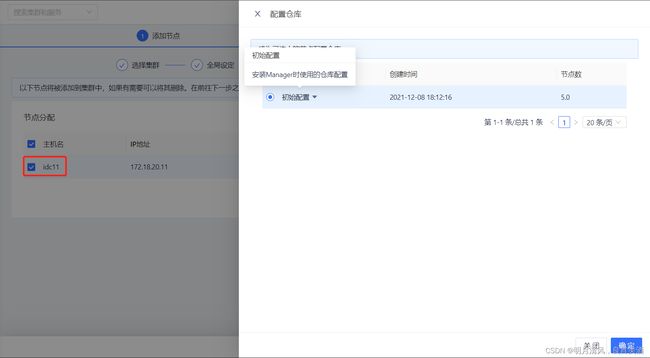
点击“下一步”,进行节点安装。
安装节点
系统会开始自动添加节点,添加节点的过程会进行一段时间,成功后您会看到成功页面。完成后,点击“下一步”继续。

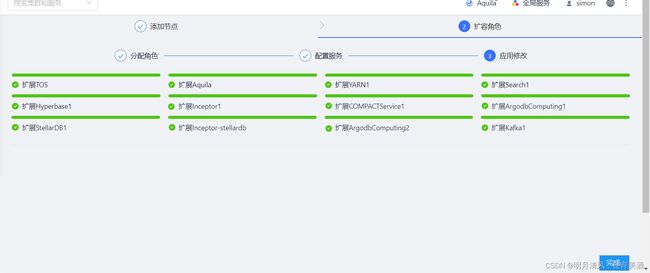
10.2.2 扩容角色
10.2.2.1 分配角色
在分配角色界面,您可以点击服务列表的下拉箭头以展开明细,请参考界面下方的节点配置建议对新节点进行服务角色的分配,扩容前已配置角色的节点不要修改或编辑。配置完成后,点击“下一步”继续。
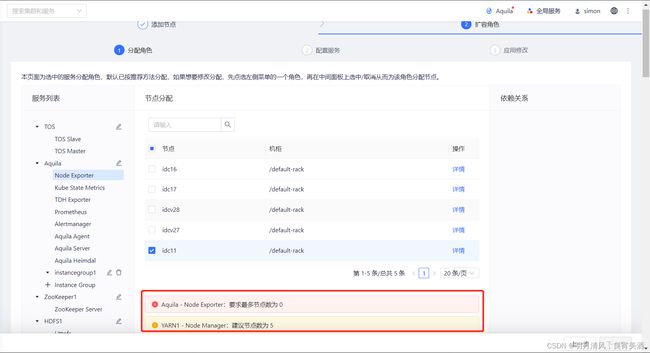
10.2.2.2 配置服务
服务的配置非常重要,请您务必在这一步仔细检查每一项服务的配置。鼠标悬浮于值“详情”可查看参数值,您可以点击“编辑”进入参数修改界面。
为保障新节点正常运行,这一步注意参考老节点的配置修改新节点的参数,特别是YARN NodeManager、Inceptor Executor等角色服务的相关参数

- 点击“编辑”或批量修改,对参数值进行修改。完成后,点击保存退出。
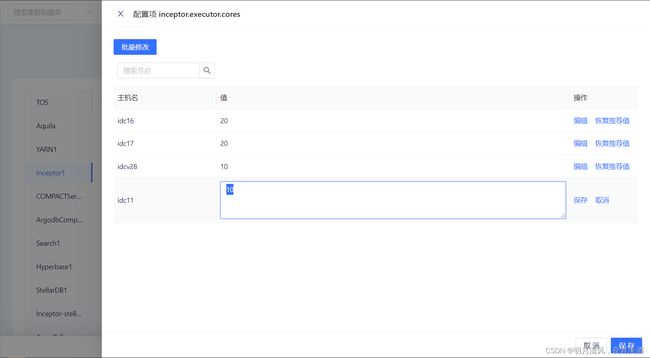
- 配置好参数后,点击“下一步”,继续
10.2.2.3 应用修改
系统会开始自动为新节点配置角色服务,应用修改稿的过程会进行一段时间,成功后您会看到成功页面。至此,扩容操作步骤完成。
十一、管理面与业务面隔离场景安装部署说明
通俗说的双网卡环境,管理面对应外网网段,业务面对应集群内网网段
11.1 安装Manager服务
需要注意的是必须从业务面网段安装服务,具体安装步骤同本手册第六章《安装Manager》。
11.2 双平面隔离配置
集群安装部署好后,通过手动修改配置的方式达到管理面与业务面隔离。
11.2.1 修改manager配置文件。
修改Manager所在节点的 /etc/transwarp-manager/master/application-user.properties 文件,将server.address改为该节点管理面网段ip(manager开启了ha的情况下两个manager节点都需修改为各自的管理面网段ip)
然后重启transwarp-manager服务
systemctl restart transwarp-manager
11.2.2 修改Aquila配置,保证管理面正常访问aquila服务
双平面隔离的场景下,通过业务面访问aquila 8666页面失败(业务面网段可以正常访问管理面网段),rootcause:aquila的配置中是通过hostname port的方式访问8180,hostname解析的是非8180监听的业务面ip导致访问失败。
操作步骤:
(1) 手动修改aquila server所在节点/etc/aquila/conf/server/application.yml文件:
manager-proxy:
endpoints:
- https://<改为manager管理面网段IP>:8180
- https://>:8180
....
logoutUrl: https://<改为manager管理面网段IP>:8180/api/users/logout
(2) 通过kubectl delete pod 的方式重启aquila server服务即可。
页面配置服务重启会导致配置文件被刷新回去
11.2.3 修改集群机器yum repo源配置
保证yum正常使用,所有机器的配置都需要修改。进入节点目录/etc/yum.repos.d
(1)修改文件os.repo
baseurl=http://<改为manager管理面网段IP>:8180/pub/os
(2)修改文件transwarp.repo
baseurl=http://<改为manager管理面网段IP>:8180/pub/transwarp-RHEL7
十二、 许可证的激活与认证
Transwarp Data Hub采用许可证授权方式提供相关服务,因此在安装过程中需要输入许可证并激活以启用所有服务。
12.1 许可证管理
将鼠标移至Transwarp Manager主界面左侧的“管理”菜单,在弹出的菜单栏中点击“许可证”进入许可证管理页面。
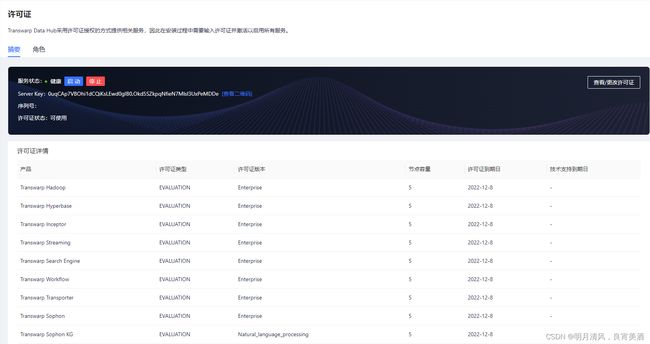
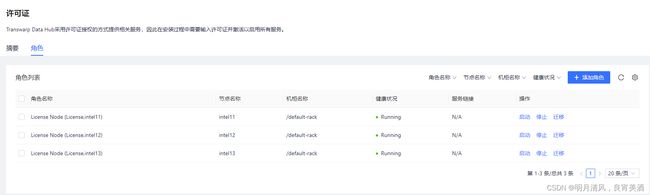
许可证管理页面分为“摘要”和“角色”两个板块。“摘要”板块显示许可服务的健康状态,Server Key、序列号、当前许可证情况,点击“启动”和“停止”可以启动或者停止许可证集群。“许可证详情”板块显示当前每一个已安装服务的License类型、版本、节点容量、License到期时间。“角色”板块展示了许可服务的角色运行的节点、每个角色运行的健康状态。
12.2 许可证激活和使用
点击“查看/更改许可证”可以查看/更改一个许可证,系统会弹出以下窗口。

如果您还没有购买商业版的Transwarp Data Hub,您可以通过 用户中心 申请社区版的License,关于社区版的安装与使用请参阅 社区版介绍 。
如果您购买了商业版的Transwarp Data Hub,我们将为您提供序列号和License Key。将两条信息都输入后点击“保存”,您便可以开始使用商业版的Transwarp Data Hub。
12.3 查看许可证授权管理
如果您已经上传过License,您可以点击“查看/更改许可证”来查看您的License Key。
12.4 许可证过期预警
当许可证离过期还有7天时,控制面板上会显示告警信息,及时提醒用户更换许可证。
十三、安装和设置问题及回答
1.问题:客户机房在节假日期间断电,需要提前进行哪些操作?
因直接断电在极端情况下会影响到TDH的稳定性,我们推荐客户在断电之前,优先在manager停止集群所有服务,再用servicetranswarp-managerstop命令停止manager。待机器上电后使用servicetranswarp-managerstart启动manager,并登入启动全部服务。
2.问题: 如何修改CentOS和Redat 操作系统中的hostname?
使用 hostnamectl set-hostname 命令。 注意: 安装完成之后尽量不要修改hostname,很多参数和配置都与hostname挂钩;在/etc/hostname文件中localhost 必须在127.0.0.1的第一个,例如:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3.问题: 在安装第一步hostname检查中就失败退出TDH Transwarp Manager安装,如何解决?
登入到管理节点上执行hostname指令和/etc/hosts里的IP 后面的名字比较,看名字是否匹配。如不匹配,修改/etc/hosts文件,确保集群中的所有节点的hostname都正确。
4.问题: 为Docker创建逻辑卷组时,在执行pvcreate /dev/xxx后出现Can’t open /dev/vdb exclusively.Mounted filesystem? 如何解决?
该情况表示分区被占用,需要查看是否挂载文件系统。如果已挂载需要umount掉。
5.问题: 为Docker创建逻辑卷组时,在执行pvcreate /dev/xxx后出现“Can’t initialize physical volume “/dev/vdb” of volume group “docker” without -ff” 如何解决?
该情况表示物理卷已经创建,不需要再重复创建。可以直接执行后面步骤。
6.问题: 安装后访问http://hostname:8180出错可能有哪些原因?
1.可能是安装出现问题:请仔细按照安装文档进行安装。
2.确保访问方式是http。
3.确保http的8180端口没有被防火墙阻止。
7.问题:节点断开可能有哪些原因?
1.可能是硬件原因(网线,网口,交换机等问题)。
2.可能是机器防火墙屏蔽了ssh。
8.问题: 如何检查防火墙是否开启?
1.在命令行状态下执行setup命令,按菜单指引防火墙配置→不选防火墙开启,然后保存设置。
2.在命令行下面执行service iptables stop关闭防火墙服务。
9.问题: Transwarp Data Hub对Hostname是否有要求?
Transwarp Data Hub对需要添加或安装的节点名有一定的要求,必须是数字,字母或符号组成的,不支持使用_(下划线)和.(点)的hostname,比如TDH1.cluster.com, TDH_2.cluster.com等。 用户需要编辑/etc/sysconfig/network文件里的hostname名字。
10.问题: Transwarp Manager对网络延迟是否有要求?
Transwarp Manager对节点和服务添加中对网络的延迟有一定要求,如果客户端浏览器到Transwarp Manager的延迟过长会导致添加失败,在客户端使用ping程序ping一下安装Transwarp Manager服务器的延迟,如果超过2ms, 可能会发生安装失败的问题。
11.问题: HDFS Format NameNode失败怎么办?
该问题表现为安装服务进行到HDFS的安装时出现。

解决方法为:确定该集群上是否安装过HDFS。如果安装过HDFS,且需要保留其中的数据,请不要继续下面的步骤,而应进行备份或升级操作。如果该集群上的没有需要保留数据的HDFS,可继续下面的步骤,清空HDFS中的残存数据。
a.在所有Journal Node上,清空(清空指删除目录中的所有内容,但保留目录,下同)/hadoop/journal 中的所有内容,然后执行:
service hadoop-hdfs-journalnode-hdfs1 restart
b.在所有Name Node上,清空dfs.namenode.name.dir配置的相应目录的所有内容,dfs.namenode.name.dir参数值在/etc//conf/hdfs-site.xml文件中(为集群上之前安装的HDFS服务的服务名,下同。)
c.在所有Data Node上,清空dfs.datanode.data.dir配置的相应目录的所有内容,dfs.datanode.data.dir参数值在/etc//conf/hdfs-site.xml文件中。
12.问题:Docker分区所在磁盘发生故障,如何快速恢复服务?
1.运行 mount /dev/
2.运行 systemctl restart docker 重启Docker服务;
3.运行 docker info 验证重启后的Docker是否正常。如果没有报错,则说明Docker正常运行。