视频预训练模型总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- vilbert (2019年)
- Hero
- Uni-Perceiver(2021年)
- Data2vec(2022年)
- ViLT(2021 ICML)
- ViTAEv2(2022 NeurIPS)
- VideoCLIP(2021 EMNLP)
- M3P (CVPR 2021)
vilbert (2019年)
论文题目:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
结构:一个双流多模态模型:文本+视觉
创新点:VilBERT的主要创新点在于提出一种双流机制,即分别面向视觉和语言的流,双流在Transformer层交互。这种结构在多模态下能分别对不同的模态进行处理,并提供模态之间的交互。
网络结构:
修改BERT中query条件下的key-value注意力机制,将其发展成一个多模态共注意transformer模块。在多头注意力中交换的key-value对,并通过共同注意力机制实现稀疏交互;
预训练:
随机进行mask操作,训练模型重建;
Hero
论文题目:HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
结构:1、跨模态Transformer 来融合字幕句子及其相应的局部视频帧;
2、 时间Transformer 使用所有周围的帧作为全局上下文,来获取每个视频帧的顺序上下文嵌入。所提出的层次模型能够首先在帧级别上吸收视觉和文本的局部上下文,然后转移到全局视频级的时间上下文中。
预训练任务:1、文本mask(MLM)
2、帧mask(MFM)
3、模态对齐(VSM)
4、随机打乱帧顺序(FOM)
Uni-Perceiver(2021年)
未开源
论文题目:Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for
Zero-shot and Few-shot Tasks
结构:Transformer作为多模态应用(如视觉语言识别)的主干网络。它们将不同模态的输入用模态特定tokenizer转换为的统一输入标记序列,并使用与模态无关的Transformer编码器共享不同输入模态和目标任务的参数,然后将不同的token序列编码到共享的表示空间中。
创新点:将输入和目标从任意模态编码到同一的表示空间,并通过输入和目标表示的相似性来建模输入和目标的联合概率。
单模态和多模态的各种任务都可以通过比较embedding的相似度来解决,因此,作者在本文中提出了一个双Encoder的结构,一个Encoder用于处理input信息,一个Encoder用于处理target信息,最后通过余弦相似度得到input和target的相似度,预训练的目标是最大化匹配的input和target的相似度。 联合概率:
Loss:
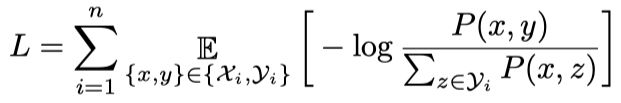
Data2vec(2022年)
论文题目:Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
结构:
1、使用ViT策略将图像编码为一系列patches,每个patches为16x16像素,输入到linear transformation模块;
使用多层1-D卷积神经网络对语音数据进行编码,该网络将16 kHz波形映射到50 Hz表示。
文本经过预处理以获得子单词单元,然后通过可学习的embedding向量将其嵌入分布空间。
2、mask
3、训练:在教师和学生网络之间共享特征编码器和位置编码器的参数更有效,更精确。
创新点:使用标准Transformer体系结构下的自蒸馏(self-distillation)。首先构建完整输入数据的表示,其目的是作为学习任务的目标(教师模式);接下来,我们对输入样本的Masked版本进行编码,用它预测完整的数据表示(学生模式)。通过预测给定输入部分视图的完整输入数据的模型表示来进行训练,学习任务是让学生在给出输入部分视图的情况下预测这些表征;
Loss: 平滑L1损失
ViLT(2021 ICML)
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
论文地址:https://arxiv.org/abs/2102.03334
代码地址:https://github.com/dandelin/vilt
在uniter的基础上进行的调整,运行速度大大加快;
思路:1、效率/速度 ,提取输入特征比多模态交互拥有更多的计算量;2、表现力 ,视觉embedder的能力和预定义的视觉词汇决定了整个模型性能的上限。3、在模态交互部分做调整。
网络框架:1、利用在其他数据集上的预训练特征提取器提取视觉信息,本文采用ViT中采用的线性投影方式,没有用卷积,因此速度快。
2、 文本也采用线性映射。
3、结构大部分的计算都用在模态交互上面,在模态特征提取上应用的都是轻量化的网络。
预训练:
1、图像文本匹配(ITM):1)随机以0.5的概率将文本对应的图片替换成不同的图片2)文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像文本是否匹配。然后计算负对数似然损失作为ITM的损失函数(交叉熵)。此外,作者还设计了单词块对齐(WPA),来计算的两个子集之间的对齐分数:(文本子集)和(视觉子集)。2、MLM:该任务的目标是根据上下文向量来预测被mask掉的单词
,在本文中,作者将mask的概率设为0.15。作者使用一个两层的MLM head,输入并输出mask词汇的logit。然后,将MLM损失设为mask token的负对数似然损失。
总结:创新点在于视觉特征提取部分,利用ViT的线性投影方法,速度很快,但性能不如region feature的方法。
ViTAEv2(2022 NeurIPS)
6亿参数模型,更大模型、更多任务、更高效率。。。
网络框架:视觉特征提取利用的是多尺度卷积引入尺度不变性,输出拼接;
创新点:
1、RC模块:reduction cell使用多尺度卷积来为transformer模型引入尺度不变性,最后进行concate;
2、NC模块:Normal cell用并行的卷积分支,在不影响transformer全局建模能力的情况下引入局部归纳偏置。
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
VideoCLIP(2021 EMNLP)
论文地址:https://arxiv.org/pdf/2109.14084.pdf
代码地址:https://github.com/pytorch/fairseq/tree/main/examples/MMPT
网络结构:1、文本和视觉分别送入两个独立训练的transformer;
2、使用对比损失来学习视频和文本之间的对应关系。学习目标是最小化两个模态之间的对比损失函数之和。
创新点:1、对文本进行采样,(如果先对视频clip进行采样,可能没有相应的文本)
2、在文本clip的边界内采样timestamp,作为视频clip的中心;
3、从该中心timestamp开始对视频clip进行拓展。
M3P (CVPR 2021)
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
论文地址:https://arxiv.org/abs/2006.02635
代码地址:https://github.com/microsoft/M3P
将以不同方式出现的对象或以不同语言表达的文本映射到一个公共语义空间:
1)通过多语种预训练,学习使用多语种语料库表示多语种数据;
2)通过随机将一些英语单词替换为其他语言的翻译,学习多语种多模态表示;
3)通过多任务的目标来学习这些表征,以处理多语言多模态任务。