【读一读论文吧】BERT
沐神论文精读B站地址:https://www.bilibili.com/video/BV1PL411M7eQ/?spm_id_from=333.788
paper:https://arxiv.org/pdf/1810.04805.pdf&usg=ALkJrhhzxlCL6yTht2BRmH9atgvKFxHsxQ
BERT简化了NLP任务的训练,提升了NLP任务的性能。
标体
1. 标题
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
pre-training: 在一个大的数据集上训练好一个模型 pre-training,模型的主要任务是用在其它任务 training 上。
deep bidirectional transformers: 深的双向 transformers
language understanding: 更广义,transformer 主要用在机器翻译
BERT: 用深的、双向的、transformer 来做预训练,用来做一般的语言理解的任务。
在自然语言处理里面,在Bert前没有一个深的神经网络使得它训练好之后能够类似计算机视觉中在一个大的数据集上训练出的模型可以用来处理一大片的机器视觉任务也应用到很多的NLP任务,其简化了NLP任务的训练,提升了NLP任务的性能。
2. 摘要
BERT是设计用来训练深的双向表示,使用的是没有标号的数据,再联合左右的上下文信息
因为这样的设计导致训练好的BERT只用加一个额外的输出层,就可以在很多NLP的任务(比如问答、语言推理)上面得到一个不错的结果,而且不需要对任务做很多特别的架构上的改动
3. 导言
自然语言任务包括两类
句子层面的任务(sentence-level):主要是用来建模句子之间的关系,比如说对句子的情绪识别或者两个句子之间的关系
词元层面的任务(token-level):包括实体命名的识别(对每个词识别是不是实体命名,比如说人名、街道名),这些任务需要输出一些细腻度的词元层面上的输出
上面的这两个任务都是相同的目标函数,使用一个单向的语言模型
在GPT中使用的是一个从左到右的架构(在看句子的时候只能从左看到右),这样的坏处在于如果要做句子层面的分析的话,比如说要判断一个句子层面的情绪是不是对的话,从左看到右和从右看到左都是合法的,另外,就算是词元层面上的一些任务,比如QA的时候也是看完整个句子再去选答案,而不是一个一个往下走
这篇文章的贡献
展示了双向信息的重要性,GPT只用了单向,之前有的工作只是很简单地把一个从左看到右的语言模型和一个从右看到左的语言模型简单地合并到一起,类似于双向的RNN模型(contact到一起),这个模型在双向信息的应用上更好
假设有一个比较好的预训练模型就不需要对特定任务做特定的模型改动。BERT是第一个在一系列的NLP任务上(包括在句子层面上和词元层面上的任务)都取得了最好的成绩的基于微调的模型
4. 结论
ELMo:使用了双向的信息,但是网络架构比较老RNN
GPT:用的是transformer的架构但是只能处理单向的信息
BERT将ELMo双向的想法和GPT的transformer架构结合起来,具体的改动是在做语言模型的时候不是预测未来而是在做完形填空。
5. 相关工作
非监督的基于特征的一些工作:词监督;ELMo
非监督的基于微调的一些工作:GPT
在有标号的数据上做迁移学习:BERT验证在NLP上面使用没有标号的大量数据集训练成的模型效果比在有标号的相对来说小一点的数据集上训练的模型效果更好。
6. BERT模型
BERT中有两个步骤:
pre-training预训练:在预训练中,这个模型是在一个没有标号的数据集上训练的
fine-tuning微调:在微调的时候同样是用一个BERT模型,但是它的权重被初始化成在预训练中得到的权重,所有的权重在微调的时候都会参与训练,用的是有标号的数据。每一个下游的任务都会创建一个新的BERT模型,虽然它们都是用最早预训练好的BERT模型作为初始化,但是每个下游任务都会根据自己的数据训练好自己的模型
模型架构

BERT模型就是一个多层的双向transformer编码器,而且它是直接基于原始的论文和它原始的代码,没有做改动
输入和输出
对于下游任务的话,有些任务是处理一个句子,有些任务是处理两个句子,所以为了使BERT模型能够处理所有的任务,它的输入既可以是一个句子,也可以是一个句子对
这里的一个句子是指一段连续的文字,不一定是真正的语义上的一段句子
输入叫做一个序列,可以是一个句子,也可以是两个句子
这和之前文章里的transformer是不一样的:transformer在训练的时候,他的输入是一个序列对,因为它的编码器和解码器分别会输入一个序列,但是BERT只有一个编码器,所以为了使它能够处理两个句子,就需要把两个句子变成一个序列
序列的构成
这里使用的切词的方法是WordPiece,核心思想是:
假设按照空格切词的话,一个词作为一个token,因为数据量相对比较大,所以会导致词典大小特别大,可能是百万级别的,那么根据之前算模型参数的方法,如果是百万级别的话,就导致整个可学习参数都在嵌入层上面
WordPiece是说假设一个词在整个里面出现的概率不大的话,那么应该把它切开看它的一个子序列,它的某一个子序列很有可能是一个词根,这个词很有可能出现的概率比较大话,那么就只保留这个子序列就行了。这样的话,可以把一个相对来说比较长的词切成很多一段一段的片段,而且这些片段是经常出现的,这样的话就可以用一个相对来说比较小的词典就能够表示一个比较大的文本了
切好词之后如何将两个句子放在一起
- 序列的第一个词永远是一个特殊的记号[CLS],CLS表示classification,这个词的作用是BERT希望最后的输出代表的是整个序列的信息(比如说整个句子层面的信息),因为BERT使用的是transformer的编码器,所以它的自注意力层中每一个词都会去看输出入中所有词的关系,就算是词放在第一的位置,它也是有办法能够看到之后的所有词
- 把两个句子合在一起,但是因为要做句子层面的分类,所以需要区分开来这两个句子,这里有两个办法:(1)在每一个句子后面放一个特殊的词:[SEP]表示separate;(2)学一个嵌入层来表示这个句子到底是第一个句子还是第二个句子

[CLS]是第一个特殊的记号表示分类,中间用一个特殊的记号[SEP]分隔开,每一个token进入BERT得到这个token的embedding表示(对BERT来讲,就是输入一个序列,然后得到另外一个序列),最后transformer块的输出就表示这个词元的BERT表示,最后再添加额外的输出层来得到想要的结果
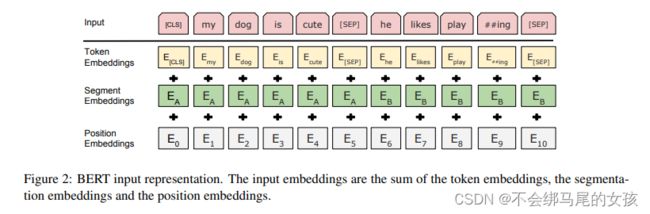
这个图表示了BERT的嵌入层的做法,即由一个词元的序列得到一个向量的序列,这个向量的序列会进入transformer块。一个方块是一个词元。 - token embedding:正常的embedding层,对每一个词元输出它对应的向量。
- segment embedding:表示是第一句话还是第二句话
- position embedding:输入的大小是这个序列的最大长度,它的输入就是每个词元这个序列中的位置信息(从零开始),由此得到对应的位置的向量
- 在transformer中,位置信息是手动构造出来的一个矩阵,但是在BERT中不管是属于哪个句子,还是具体的位置,它对应的向量表示都是通过学习得来的
Bert的损失函数
bert的损失函数包括两部分,一个是句子中预测遮掩词的损失(MLM),另一个是判断是否是下一句的损失(NSP)
MLM:在 encoder 的输出上添加一个分类层,用嵌入矩阵乘以输出向量,将其转换为词汇的维度,用 softmax 计算mask中每个单词的概率
NSP:用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量,用 softmax 计算 IsNextSequence 的概率
预训练中的两个任务
- 带掩码的语言模型
对于输入的词元序列,如果词元序列是由WordPiece生成的话,那么它有15%的概率会随机替换成掩码,但是对于特殊的词元(第一个词元和中间的分割词元不做替换),如果输入序列长度是1000的话,那么就要预测150个词
这里也会存在问题:因为在做掩码的时候会把词元替换成一个特殊的token([MASK]),在训练的时候大概会看到15%的词元,但是在微调的时候是没有的,因为在微调的时候不用这个目标函数,所以没有mask这个东西,导致在预训练和微调的时候所看到的数据会有多不同
解决方法:对这15%的被选中作为掩码的词有80%的概率是真的将它替换成这个特殊的掩码符号([MASK]),还有10%的概率将它替换成一个随机的词元(其实是加入了一些噪音),最后有10%的概率什么都不干,就把它存在那里用来做预测(附录中有例子)
- 预测下一个句子
在QA和自然语言推理中都是句子对,如果让它学习一些句子层面的信息也不错,具体来说,一个输入序列里面有两个句子:a和b,有50的概率b在原文中间真的是在a的后面,还有50%的概率b就是随机从别的地方选取出来的句子,这就意味着有50%的样本是正例(两个句子是相邻的关系),50%的样本是负例(两个句子没有太大的关系),加入这个目标函数能够极大地提升在QA和自然语言推理的效果(附录中有例子)