TensorFlow入门(十二、分布式训练)
1、按照并行方式来分
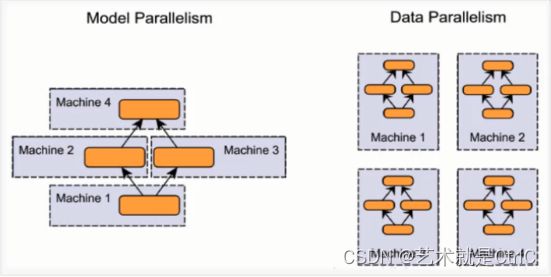
①模型并行
假设我们有n张GPU,不同的GPU被输入相同的数据,运行同一个模型的不同部分。
在实际训练过程中,如果遇到模型非常庞大,一张GPU不够存储的情况,可以使用模型并行的分布式训练,把模型的不同部分交给不同的GPU负责。这种方式存在一定的弊端:①这种方式需要不同的GPU之间通信,从而产生较大的通信成本。②由于每个GPU上运行的模型部分之间存在一定的依赖,导致规模伸缩性差。
②数据并行
假设我们有n张GPU,不同的GPU被输入不同的数据,运行相同的完整的模型。
如果遇到一张GPU就能够存下一个模型的情况,可以采用数据并行的方式,这种方式的各部分独立,伸缩性好。
2、按照更新方式来分
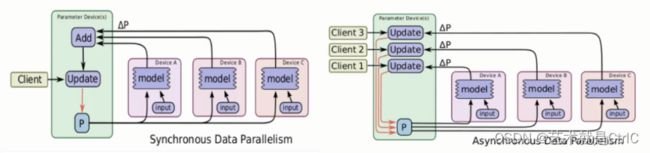
采用数据并行方式时,由于每个GPU负责一部分数据,涉及到如何更新参数的问题,因此分为同步更新和异步更新两种方式。
①同步更新
所有GPU计算完每一个batch(也就是每批次数据)后,再统一计算新权值,等所有GPU同步新值后,再开始进行下一轮计算。
同步更新的好处是loss的下降比较稳定,但是这个的坏处也很明显,这种方式有等待,处理的速度取决于最慢的那个GPU计算的时间。
②异步更新
每个GPU计算完梯度后,无需等待其他GPU更新,立即更新整体权值并同步。
异步更新的好处是计算速度快,计算资源能得到充分利用,但是缺点是loss的下降不稳定,抖动大。
3、按照算法来分
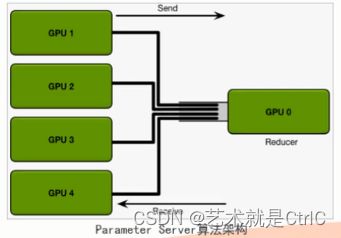

①Parameter Sever算法
原理:假设我们有n张GPU,GPU0将数据分成n份分到各张GPU上,每张GPU负责自己那一批次数据的训练,得到梯度后,返回给GPU0上做累计,得到更新的权重参数后,再分发给各张GPU。
②Ring AllReduce算法
原理:假设我们有n张GPU,它们以环形相连,每张GPU都有一个左邻和一个右邻,每张GPU向各自的右邻发送数据,并从它的左邻接近数据。循环n-1次完成梯度积累,再循环n-1次做参数同步。整个算法过程分两个步骤进行:首先是scatter_reduce,然后是allgather。在scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在allgather步骤中,gpu将交换这些块,以便所有gpu得到完整的最终结果。
tf.distribute API:
它是TensorFlow在多GPU、多机器上进行分布式训练用的API。使用这个API,可以在尽可能少改动代码的同时,分布式训练模型。
它的核心API是tf.distribute.Strategy,只需简单几行代码就可以实现单机多GPU,多机多GPU等情况的分布式训练。
它的主要优点:
①简单易用,开箱即用,高性能
②便于各种分布式Strategy切换
③支持Custom Training Loop、Estimator、Keras
④支持eager excution
tf.distribute.Strategy目前主要有四个Strategy:
①MirroredStrategy,即镜像策略
MirroredStrategy用于单机多GPU、数据并行、同步更新的情况,它会在每个GPU上保存一份模型副本,模型中的每个变量都镜像在所有副本中。这些变量一起形成一个名为MirroredVariable的概念变量。通过apply相同的更新,这些变量保持彼此同步。
创建一个镜像策略的方法如下:
mirrored_strategy = tf.distribute.MirroredStrategy()
也可以自定义用哪些devices,如:
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0","/gpu:1"])
训练过程中,镜像策略用了高效的All-reduce算法来实现设备之间变量的传递更新。默认情况下它使用NVIDA NCCL (tf.distribute.NcclAllReduce)作为all-reduce算法的实现。通过apply相同的更新,这些变量保持彼此同步。
官方也提供了其他的一些all-reduce实现方法,可供选择,如:
tf.distribute.CrossDeviceOps
tf.distribute.HierarchicalCopyAllReduce
tf.distribute.ReductionToOneDevice
②CentralStorageStrategy,即中心存储策略
使用该策略时,参数被统一存在CPU里,然后复制到所有GPU上,它的优点是通过这种方式,GPU是负载均衡的,但一般情况下CPU和GPU通信代价比较大。
创建一个中心存储策略的方法如下:
central_storage_strategy = tf.distribute.experimental.CentralStorageStratygy()
③MultiWorkerMirroredStrategy,即多端镜像策略
该API和MirroredStrategy类似,它是其多机多GPU分布式训练的版本。
创建一个多端镜像策略的方法如下:
multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
④ParameterServerStrategy,即参数服务策略
简称PS策略,由于计算速度慢和负载不均衡,很少使用这种策略。
创建一个参数服务策略的方法如下:
ps_strategy = tf.distribute.experimental.ParameterServerStrategy()
示例代码如下:
import tensorflow as tf
#设置总训练轮数
num_epochs = 5
#设置每轮训练的批大小
batch_size_per_replica = 64
#设置学习率,指定了梯度下降算法中用于更新权重的步长大小
learning_rate = 0.001
#创建镜像策略
strategy = tf.distribute.MirroredStrategy()
#通过同步更新时副本的数量计算出本机的GPU设备数量
print("Number of devices: %d"% strategy.num_replicas_in_sync)
#通过副本数量乘以每轮训练的批大小,得出训练总数据量的大小
batch_size = batch_size_per_replica * strategy.num_replicas_in_sync
#函数将输入的图片调整为224x224大小,再将像素值除以255进行归一化,同时返回标签信息
def resize(image,label):
image = tf.image.resize(image,[224,224])/255.0
return image,label
#载入数据集并预处理
dataset,_ = tf.keras.datasets.cifar10.load_data()
images,labels = dataset
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)
#在strategy.scope下创建模型和优化器
with strategy.scope():
#载入了MobileNetV2模型,该模型在ImageNet上预先训练好了,并可以在分类问题上进行微调
model = tf.keras.applications.MobileNetV2()
#设置训练时用的优化器、损失函数和准确率评测标准
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate),
loss = tf.keras.losses.sparse_categorical_crossentropy,
metrics = [tf.keras.metrics.sparse_categorical_accuracy]
)
#执行训练过程
model.fit(dataset,epochs = num_epochs)
对于CIFAR-10数据集下载过慢的问题,可以手动去官网下载
https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz下载完成后将其放在如下图的路径下,并将数据集文件改名为cifar-10-batches-py.tar.gz并解压
https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz下载完成后将其放在如下图的路径下,并将数据集文件改名为cifar-10-batches-py.tar.gz并解压
