九四、node+selenium-webdriver爬虫高级
爬虫高级
- 使用Selenium库爬取前端渲染的网页
- 反反爬虫技术
Selenium简介
官方原文介绍:
Selenium automates browsers. That’s it! What you do with that power is entirely up to you. Primarily, it is for automating web applications for testing purposes, but is certainly not limited to just that. Boring web-based administration tasks can (and should!) be automated as well.
Selenium has the support of some of the largest browser vendors who have taken (or are taking) steps to make Selenium a native part of their browser. It is also the core technology in countless other browser automation tools, APIs and frameworks.
百度百科介绍:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),[Mozilla Firefox](https://baike.baidu.com/item/Mozilla Firefox/3504923),Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
简单总结:
Selenium是一个Web应用的自动化测试框架,可以创建回归测试来检验软件功能和用户需求,通过框架可以编写代码来启动浏览器进行自动化测试,换言之,用于做爬虫就可以使用代码启动浏览器,让真正的浏览器去打开网页,然后去网页中获取想要的信息!从而实现真正意义上无惧反爬虫手段!
Selenium的基本使用
-
根据平台下载需要的webdriver
-
项目中安装selenium-webdriver包
-
根据官方文档写一个小demo
根据平台选择webdriver
| 浏览器 | webdriver |
|---|---|
| Chrome | chromedriver(.exe) |
| Internet Explorer | IEDriverServer.exe |
| Edge | MicrosoftWebDriver.msi |
| Firefox | geckodriver(.exe) |
| Safari | safaridriver |
选择版本和平台:

下载后放入项目根目录
安装selenium-webdriver的包
npm i selenium-webdriver
自动打开百度搜索“xxxx“
const { Builder, By, Key, until } = require('selenium-webdriver');
(async function example() {
let driver = await new Builder().forBrowser('chrome').build();
// try {
await driver.get('https://www.baidu.com');
await driver.findElement(By.id('kw')).sendKeys('xxxx', Key.ENTER);
console.log(await driver.wait(until.titleIs('xxxx_百度搜索'), 1000))
// } finally {
// await driver.quit();
// }
})();
为什么要用Selenium来做爬虫
目前的大流量网站,都会有些对应的反爬虫机制
例如在拉勾网上搜索传智播客:

找到对应的ajax请求地址,使用postman来测试数据:
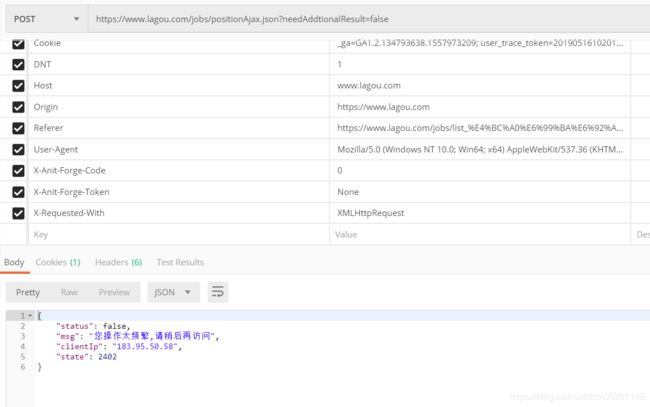
前几次可能会获取到数据,但多几次则会出现操作频繁请稍后再试的问题
而通过Selenium可以操作浏览器,打开某个网址,接下来只需要学习其API,就能获取网页中需要的内容了!
反爬虫技术只是针对爬虫的,例如检查请求头是否像爬虫,检查IP地址的请求频率(如果过高则封杀)等手段
而Selenium打开的就是一个自动化测试的浏览器,和用户正常使用的浏览器并无差别,所以再厉害的反爬虫技术,也无法直接把它干掉,除非这个网站连普通用户都想放弃掉(12306曾经迫于无奈这样做过)
Selenium API学习
核心对象:
-
Builder
-
WebDriver
-
WebElement
辅助对象:
- By
- Key
Builder
用于构建WebDriver对象的构造器
let driver = new webdriver.Builder()
.forBrowser('chrome')
.build();
其他API如下:
可以获取或设置一些Options
如需设置Chrome的Options,需要先导入Options:
const { Options } = require('selenium-webdriver/chrome');
const options = new Options()
options.addArguments('Cookie=user_trace_token=20191130095945-889e634a-a79b-4b61-9ced-996eca44b107; X_HTTP_TOKEN=7470c50044327b9a2af2946eaad67653; _ga=GA1.2.2111156102.1543543186; _gid=GA1.2.1593040181.1543543186; LGUID=20181130095946-9c90e147-f443-11e8-87e4-525400f775ce; sajssdk_2015_cross_new_user=1; JSESSIONID=ABAAABAAAGGABCB5E0E82B87052ECD8CED0421F1D36020D; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543543186,1543545866; LGSID=20181130104426-da2fc57f-f449-11e8-87ea-525400f775ce; PRE_UTM=; PRE_HOST=www.cnblogs.com; PRE_SITE=https%3A%2F%2Fwww.cnblogs.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E5%2589%258D%25E7%25AB%25AF%25E5%25BC%2580%25E5%258F%2591%3Fkd%3D%25E5%2589%258D%25E7%25AB%25AF%25E5%25BC%2580%25E5%258F%2591%26spc%3D1%26pl%3D%26gj%3D%26xl%3D%26yx%3D%26gx%3D%26st%3D%26labelWords%3Dlabel%26lc%3D%26workAddress%3D%26city%3D%25E5%2585%25A8%25E5%259B%25BD%26requestId%3D%26pn%3D1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221676257e1bd8cc-060451fc44d124-9393265-2359296-1676257e1be898%22%2C%22%24device_id%22%3A%221676257e1bd8cc-060451fc44d124-9393265-2359296-1676257e1be898%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; ab_test_random_num=0; _putrc=30FD5A7177A00E45123F89F2B170EADC; login=true; unick=%E5%A4%A9%E6%88%90; hasDeliver=0; gate_login_token=3e9da07186150513b28b29e8e74f485b86439e1fd26fc4939d32ed2660e8421a; _gat=1; SEARCH_ID=334cf2a080f44f2fb42841f473719162; LGRID=20181130110855-45ea2d22-f44d-11e8-87ee-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543547335; TG-TRACK-CODE=search_code')
.addArguments('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20')
WebDriver
通过构造器创建好WebDriver后就可以使用API查找网页元素和获取信息了:
- findElement() 查找元素
WebElement
- getText() 获取文本内容
- sendKeys() 发送一些按键指令
- click() 点击该元素
自动打开拉勾网搜索"前端"
-
使用driver打开拉勾网主页
-
找到全国站并点击一下
-
输入“前端”并回车
const { Builder, By, Key } = require('selenium-webdriver');
(async function start() {
let driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
})();
获取需要的数据
使用driver.findElement()找到所有条目项,根据需求分析页面元素,获取其文本内容即可:
const { Builder, By, Key } = require('selenium-webdriver');
(async function start() {
let driver = await new Builder().forBrowser('chrome').build();
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
let items = await driver.findElements(By.className('con_list_item'))
items.forEach(async item => {
// 获取岗位名称
let title = await item.findElement(By.css('.p_top h3')).getText()
// 获取工作地点
let position = await item.findElement(By.css('.p_top em')).getText()
// 获取发布时间
let time = await item.findElement(By.css('.p_top .format-time')).getText()
// 获取公司名称
let companyName = await item.findElement(By.css('.company .company_name')).getText()
// 获取公司所在行业
let industry = await item.findElement(By.css('.company .industry')).getText()
// 获取薪资待遇
let money = await item.findElement(By.css('.p_bot .money')).getText()
// 获取需求背景
let background = await item.findElement(By.css('.p_bot .li_b_l')).getText()
// 处理需求背景
background = background.replace(money, '')
console.log(title, position, time, companyName, industry, money, background)
})
})();
自动翻页
思路如下:
- 定义初始页码
- 获取数据后,获取页面上的总页码,定义最大页码
- 开始获取数据时打印当前正在获取的页码数
- 获取完一页数据后,当前页码自增,然后判断是否达到最大页码
- 查找下一页按钮并调用点击api,进行自动翻页
- 翻页后递归调用获取数据的函数
const { Builder, By, Key } = require('selenium-webdriver');
let currentPageNum = 1;
let maxPageNum = 1;
let driver = new Builder().forBrowser('chrome').build();
(async function start() {
await driver.get('https://www.lagou.com/');
await driver.findElement(By.css('#changeCityBox .checkTips .tab.focus')).click();
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.ENTER);
maxPageNum = await driver.findElement(By.className('totalNum')).getText()
getData()
})();
async function getData() {
console.log(`正在获取第${currentPageNum}页的数据, 共${maxPageNum}页`)
while (true) {
let flag = true
try {
let items = await driver.findElements(By.className('con_list_item'))
let results = []
for (let i = 0; i < items.length; i++) {
let item = items[i]
// 获取岗位名称
let title = await item.findElement(By.css('.p_top h3')).getText()
// 获取工作地点
let position = await item.findElement(By.css('.p_top em')).getText()
// 获取发布时间
let time = await item.findElement(By.css('.p_top .format-time')).getText()
// 获取公司名称
let companyName = await item.findElement(By.css('.company .company_name')).getText()
// 获取公司所在行业
let industry = await item.findElement(By.css('.company .industry')).getText()
// 获取薪资待遇
let money = await item.findElement(By.css('.p_bot .money')).getText()
// 获取需求背景
let background = await item.findElement(By.css('.p_bot .li_b_l')).getText()
// 处理需求背景
background = background.replace(money, '')
// console.log(id, job, area, money, link, need, companyLink, industry, tags, welfare)
results.push({
title,
position,
time,
companyName,
industry,
money,
background
})
}
console.log(results)
currentPageNum++
if (currentPageNum <= maxPageNum) {
await driver.findElement(By.className('pager_next')).click()
await getData(driver)
}
} catch (e) {
// console.log(e.message)
if (e) flag = false
} finally {
if (flag) break
}
}
}