Spark 之 WholeStageCodegen
CodeGen framework
- CodegenSupport(接口)
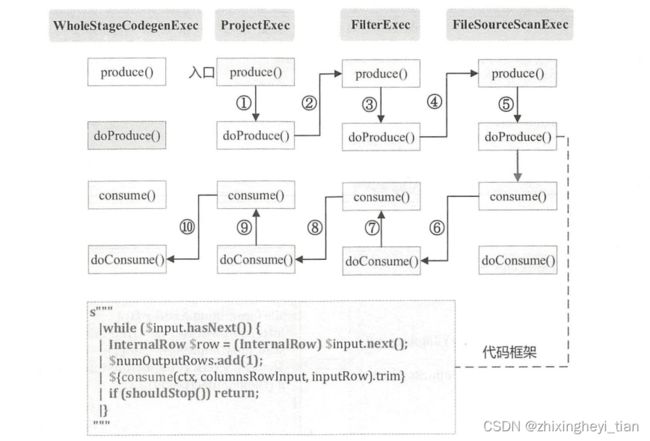
相邻Operator通过Produce-Consume模式生成代码。
Produce生成整体处理的框架代码,例如aggregation生成的代码框架如下:
if (!initialized) {
# create a hash map, then build the aggregation hash map
# call child.produce()
initialized = true;
}
while (hashmap.hasNext()) {
row = hashmap.next();
# build the aggregation results
# create variables for results
# call consume(), which will call parent.doConsume()
if (shouldStop()) return;
}
Consume生成当前节点处理上游输入的Row的逻辑。如Filter生成代码如下:
# code to evaluate the predicate expression, result is isNull1 and value2
if (!isNull1 && value2) {
# call consume(), which will call parent.doConsume()
}
- WholeStageCodegenExec(类)
CodegenSupport的实现类之一,Stage内部所有相邻的实现CodegenSupport接口的Operator的融合,产出的代码把所有被融合的Operator的执行逻辑封装到一个Wrapper类中,该Wrapper类作为Janino即时compile的入参。 - InputAdapter(类)
CodegenSupport的实现类之一,胶水类,用来连接WholeStageCodegenExec节点和未实现CodegenSupport的上游节点。 - BufferedRowIterator(接口)
WholeStageCodegenExec生成的java代码的父类,重要方法:
public InternalRow next() // 返回下一条Row
public void append(InternalRow row) // append一条Row
Simple call graph
/**
* WholeStageCodegen compiles a subtree of plans that support codegen together into single Java
* function.
*
* Here is the call graph of to generate Java source (plan A supports codegen, but plan B does not):
*
* WholeStageCodegen Plan A FakeInput Plan B
* =========================================================================
*
* -> execute()
* |
* doExecute() ---------> inputRDDs() -------> inputRDDs() ------> execute()
* |
* +-----------------> produce()
* |
* doProduce() -------> produce()
* |
* doProduce()
* |
* doConsume() <--------- consume()
* |
* doConsume() <-------- consume()
*
* SparkPlan A should override `doProduce()` and `doConsume()`.
*
* `doCodeGen()` will create a `CodeGenContext`, which will hold a list of variables for input,
* used to generated code for [[BoundReference]].
*/
Produce-Consume Pattern
doProduce() doConsume() 会被子类覆写
produce() consume() 均为 trait CodegenSupport extends SparkPlan 的 final 方法
insertInputAdapter
InputAdapter(类)
CodegenSupport的实现类之一,胶水类,用来连接WholeStageCodegenExec节点和未实现CodegenSupport的上游节点。
/**
* Inserts an InputAdapter on top of those that do not support codegen.
*/
private def insertInputAdapter(plan: SparkPlan): SparkPlan = {
plan match {
case p if !supportCodegen(p) =>
// collapse them recursively
InputAdapter(insertWholeStageCodegen(p))
case j: SortMergeJoinExec =>
// The children of SortMergeJoin should do codegen separately.
j.withNewChildren(j.children.map(
child => InputAdapter(insertWholeStageCodegen(child))))
case j: ShuffledHashJoinExec =>
// The children of ShuffledHashJoin should do codegen separately.
j.withNewChildren(j.children.map(
child => InputAdapter(insertWholeStageCodegen(child))))
case p => p.withNewChildren(p.children.map(insertInputAdapter))
}
}
WholeStageCodegenExec 核心函数 doExecute
override def doExecute(): RDD[InternalRow] = {
val (ctx, cleanedSource) = doCodeGen()
// try to compile and fallback if it failed
val (_, compiledCodeStats) = try {
CodeGenerator.compile(cleanedSource)
} catch {
case NonFatal(_) if !Utils.isTesting && sqlContext.conf.codegenFallback =>
// We should already saw the error message
logWarning(s"Whole-stage codegen disabled for plan (id=$codegenStageId):\n $treeString")
return child.execute()
}
// Check if compiled code has a too large function
if (compiledCodeStats.maxMethodCodeSize > sqlContext.conf.hugeMethodLimit) {
logInfo(s"Found too long generated codes and JIT optimization might not work: " +
s"the bytecode size (${compiledCodeStats.maxMethodCodeSize}) is above the limit " +
s"${sqlContext.conf.hugeMethodLimit}, and the whole-stage codegen was disabled " +
s"for this plan (id=$codegenStageId). To avoid this, you can raise the limit " +
s"`${SQLConf.WHOLESTAGE_HUGE_METHOD_LIMIT.key}`:\n$treeString")
return child.execute()
}
val references = ctx.references.toArray
val durationMs = longMetric("pipelineTime")
// Even though rdds is an RDD[InternalRow] it may actually be an RDD[ColumnarBatch] with
// type erasure hiding that. This allows for the input to a code gen stage to be columnar,
// but the output must be rows.
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
if (rdds.length == 1) {
rdds.head.mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter))
new Iterator[InternalRow] {
override def hasNext: Boolean = {
val v = buffer.hasNext
if (!v) durationMs += buffer.durationMs()
v
}
override def next: InternalRow = buffer.next()
}
}
} else {
// Right now, we support up to two input RDDs.
rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
Iterator((leftIter, rightIter))
// a small hack to obtain the correct partition index
}.mapPartitionsWithIndex { (index, zippedIter) =>
val (leftIter, rightIter) = zippedIter.next()
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(leftIter, rightIter))
new Iterator[InternalRow] {
override def hasNext: Boolean = {
val v = buffer.hasNext
if (!v) durationMs += buffer.durationMs()
v
}
override def next: InternalRow = buffer.next()
}
}
}
}
里面的关键点就在 编译出来的代码转成了Iterator。
mapPartitionsWithIndex { (index, iter) =>
val (clazz, _) = CodeGenerator.compile(cleanedSource)
val buffer = clazz.generate(references).asInstanceOf[BufferedRowIterator]
buffer.init(index, Array(iter))
new Iterator[InternalRow] {
override def hasNext: Boolean = {
val v = buffer.hasNext
if (!v) durationMs += buffer.durationMs()
v
}
override def next: InternalRow = buffer.next()
}
}
UT
test("range/filter should be combined") {
val df = spark.range(10).filter("id = 1").selectExpr("id + 1")
val plan = df.queryExecution.executedPlan
assert(plan.find(_.isInstanceOf[WholeStageCodegenExec]).isDefined)
assert(df.collect() === Array(Row(2)))
df.explain(false)
df.queryExecution.debug.codegen
}
11:32:34.837 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
== Physical Plan ==
*(1) Project [(id#0L + 1) AS (id + 1)#4L]
+- *(1) Filter (id#0L = 1)
+- *(1) Range (0, 10, step=1, splits=2)
Found 1 WholeStageCodegen subtrees.
== Subtree 1 / 1 (maxMethodCodeSize:301; maxConstantPoolSize:177(0.27% used); numInnerClasses:0) ==
*(1) Project [(id#0L + 1) AS (id + 1)#4L]
+- *(1) Filter (id#0L = 1)
+- *(1) Range (0, 10, step=1, splits=2)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean range_initRange_0;
/* 010 */ private long range_nextIndex_0;
/* 011 */ private TaskContext range_taskContext_0;
/* 012 */ private InputMetrics range_inputMetrics_0;
/* 013 */ private long range_batchEnd_0;
/* 014 */ private long range_numElementsTodo_0;
/* 015 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] range_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[3];
/* 016 */
/* 017 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 018 */ this.references = references;
/* 019 */ }
/* 020 */
/* 021 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 022 */ partitionIndex = index;
/* 023 */ this.inputs = inputs;
/* 024 */
/* 025 */ range_taskContext_0 = TaskContext.get();
/* 026 */ range_inputMetrics_0 = range_taskContext_0.taskMetrics().inputMetrics();
/* 027 */ range_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 028 */ range_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 029 */ range_mutableStateArray_0[2] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 030 */
/* 031 */ }
/* 032 */
/* 033 */ private void initRange(int idx) {
/* 034 */ java.math.BigInteger index = java.math.BigInteger.valueOf(idx);
/* 035 */ java.math.BigInteger numSlice = java.math.BigInteger.valueOf(2L);
/* 036 */ java.math.BigInteger numElement = java.math.BigInteger.valueOf(10L);
/* 037 */ java.math.BigInteger step = java.math.BigInteger.valueOf(1L);
/* 038 */ java.math.BigInteger start = java.math.BigInteger.valueOf(0L);
/* 039 */ long partitionEnd;
/* 040 */
/* 041 */ java.math.BigInteger st = index.multiply(numElement).divide(numSlice).multiply(step).add(start);
/* 042 */ if (st.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 043 */ range_nextIndex_0 = Long.MAX_VALUE;
/* 044 */ } else if (st.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 045 */ range_nextIndex_0 = Long.MIN_VALUE;
/* 046 */ } else {
/* 047 */ range_nextIndex_0 = st.longValue();
/* 048 */ }
/* 049 */ range_batchEnd_0 = range_nextIndex_0;
/* 050 */
/* 051 */ java.math.BigInteger end = index.add(java.math.BigInteger.ONE).multiply(numElement).divide(numSlice)
/* 052 */ .multiply(step).add(start);
/* 053 */ if (end.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 054 */ partitionEnd = Long.MAX_VALUE;
/* 055 */ } else if (end.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 056 */ partitionEnd = Long.MIN_VALUE;
/* 057 */ } else {
/* 058 */ partitionEnd = end.longValue();
/* 059 */ }
/* 060 */
/* 061 */ java.math.BigInteger startToEnd = java.math.BigInteger.valueOf(partitionEnd).subtract(
/* 062 */ java.math.BigInteger.valueOf(range_nextIndex_0));
/* 063 */ range_numElementsTodo_0 = startToEnd.divide(step).longValue();
/* 064 */ if (range_numElementsTodo_0 < 0) {
/* 065 */ range_numElementsTodo_0 = 0;
/* 066 */ } else if (startToEnd.remainder(step).compareTo(java.math.BigInteger.valueOf(0L)) != 0) {
/* 067 */ range_numElementsTodo_0++;
/* 068 */ }
/* 069 */ }
/* 070 */
/* 071 */ protected void processNext() throws java.io.IOException {
/* 072 */ // initialize Range
/* 073 */ if (!range_initRange_0) {
/* 074 */ range_initRange_0 = true;
/* 075 */ initRange(partitionIndex);
/* 076 */ }
/* 077 */
/* 078 */ while (true) {
/* 079 */ if (range_nextIndex_0 == range_batchEnd_0) {
/* 080 */ long range_nextBatchTodo_0;
/* 081 */ if (range_numElementsTodo_0 > 1000L) {
/* 082 */ range_nextBatchTodo_0 = 1000L;
/* 083 */ range_numElementsTodo_0 -= 1000L;
/* 084 */ } else {
/* 085 */ range_nextBatchTodo_0 = range_numElementsTodo_0;
/* 086 */ range_numElementsTodo_0 = 0;
/* 087 */ if (range_nextBatchTodo_0 == 0) break;
/* 088 */ }
/* 089 */ range_batchEnd_0 += range_nextBatchTodo_0 * 1L;
/* 090 */ }
/* 091 */
/* 092 */ int range_localEnd_0 = (int)((range_batchEnd_0 - range_nextIndex_0) / 1L);
/* 093 */ for (int range_localIdx_0 = 0; range_localIdx_0 < range_localEnd_0; range_localIdx_0++) {
/* 094 */ long range_value_0 = ((long)range_localIdx_0 * 1L) + range_nextIndex_0;
/* 095 */
/* 096 */ do {
/* 097 */ boolean filter_value_0 = false;
/* 098 */ filter_value_0 = range_value_0 == 1L;
/* 099 */ if (!filter_value_0) continue;
/* 100 */
/* 101 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* numOutputRows */).add(1);
/* 102 */
/* 103 */ // common sub-expressions
/* 104 */
/* 105 */ long project_value_0 = -1L;
/* 106 */
/* 107 */ project_value_0 = range_value_0 + 1L;
/* 108 */ range_mutableStateArray_0[2].reset();
/* 109 */
/* 110 */ range_mutableStateArray_0[2].write(0, project_value_0);
/* 111 */ append((range_mutableStateArray_0[2].getRow()));
/* 112 */
/* 113 */ } while(false);
/* 114 */
/* 115 */ if (shouldStop()) {
/* 116 */ range_nextIndex_0 = range_value_0 + 1L;
/* 117 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localIdx_0 + 1);
/* 118 */ range_inputMetrics_0.incRecordsRead(range_localIdx_0 + 1);
/* 119 */ return;
/* 120 */ }
/* 121 */
/* 122 */ }
/* 123 */ range_nextIndex_0 = range_batchEnd_0;
/* 124 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localEnd_0);
/* 125 */ range_inputMetrics_0.incRecordsRead(range_localEnd_0);
/* 126 */ range_taskContext_0.killTaskIfInterrupted();
/* 127 */ }
/* 128 */ }
/* 129 */
/* 130 */ }
11:32:40.126 WARN org.apache.spark.sql.execution.WholeStageCodegenSuite:
===== POSSIBLE THREAD LEAK IN SUITE o.a.s.sql.execution.WholeStageCodegenSuite, thread names: rpc-boss-3-1, shuffle-boss-6-1 =====
Process finished with exit code 0
一个简单的实验
/** Physical plan for Filter. */
case class FilterExec(condition: Expression, child: SparkPlan)
在FilterExec 增加这一行
override def supportCodegen: Boolean = false
会拆成两个wholestagecodegen
16:27:42.332 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
== Physical Plan ==
*(2) Project [(id#0L + 1) AS (id + 1)#4L]
+- Filter (id#0L = 1)
+- *(1) Range (0, 10, step=1, splits=2)
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 (maxMethodCodeSize:282; maxConstantPoolSize:175(0.27% used); numInnerClasses:0) ==
*(1) Range (0, 10, step=1, splits=2)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean range_initRange_0;
/* 010 */ private long range_nextIndex_0;
/* 011 */ private TaskContext range_taskContext_0;
/* 012 */ private InputMetrics range_inputMetrics_0;
/* 013 */ private long range_batchEnd_0;
/* 014 */ private long range_numElementsTodo_0;
/* 015 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] range_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 016 */
/* 017 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 018 */ this.references = references;
/* 019 */ }
/* 020 */
/* 021 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 022 */ partitionIndex = index;
/* 023 */ this.inputs = inputs;
/* 024 */
/* 025 */ range_taskContext_0 = TaskContext.get();
/* 026 */ range_inputMetrics_0 = range_taskContext_0.taskMetrics().inputMetrics();
/* 027 */ range_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 028 */
/* 029 */ }
/* 030 */
/* 031 */ private void initRange(int idx) {
/* 032 */ java.math.BigInteger index = java.math.BigInteger.valueOf(idx);
/* 033 */ java.math.BigInteger numSlice = java.math.BigInteger.valueOf(2L);
/* 034 */ java.math.BigInteger numElement = java.math.BigInteger.valueOf(10L);
/* 035 */ java.math.BigInteger step = java.math.BigInteger.valueOf(1L);
/* 036 */ java.math.BigInteger start = java.math.BigInteger.valueOf(0L);
/* 037 */ long partitionEnd;
/* 038 */
/* 039 */ java.math.BigInteger st = index.multiply(numElement).divide(numSlice).multiply(step).add(start);
/* 040 */ if (st.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 041 */ range_nextIndex_0 = Long.MAX_VALUE;
/* 042 */ } else if (st.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 043 */ range_nextIndex_0 = Long.MIN_VALUE;
/* 044 */ } else {
/* 045 */ range_nextIndex_0 = st.longValue();
/* 046 */ }
/* 047 */ range_batchEnd_0 = range_nextIndex_0;
/* 048 */
/* 049 */ java.math.BigInteger end = index.add(java.math.BigInteger.ONE).multiply(numElement).divide(numSlice)
/* 050 */ .multiply(step).add(start);
/* 051 */ if (end.compareTo(java.math.BigInteger.valueOf(Long.MAX_VALUE)) > 0) {
/* 052 */ partitionEnd = Long.MAX_VALUE;
/* 053 */ } else if (end.compareTo(java.math.BigInteger.valueOf(Long.MIN_VALUE)) < 0) {
/* 054 */ partitionEnd = Long.MIN_VALUE;
/* 055 */ } else {
/* 056 */ partitionEnd = end.longValue();
/* 057 */ }
/* 058 */
/* 059 */ java.math.BigInteger startToEnd = java.math.BigInteger.valueOf(partitionEnd).subtract(
/* 060 */ java.math.BigInteger.valueOf(range_nextIndex_0));
/* 061 */ range_numElementsTodo_0 = startToEnd.divide(step).longValue();
/* 062 */ if (range_numElementsTodo_0 < 0) {
/* 063 */ range_numElementsTodo_0 = 0;
/* 064 */ } else if (startToEnd.remainder(step).compareTo(java.math.BigInteger.valueOf(0L)) != 0) {
/* 065 */ range_numElementsTodo_0++;
/* 066 */ }
/* 067 */ }
/* 068 */
/* 069 */ protected void processNext() throws java.io.IOException {
/* 070 */ // initialize Range
/* 071 */ if (!range_initRange_0) {
/* 072 */ range_initRange_0 = true;
/* 073 */ initRange(partitionIndex);
/* 074 */ }
/* 075 */
/* 076 */ while (true) {
/* 077 */ if (range_nextIndex_0 == range_batchEnd_0) {
/* 078 */ long range_nextBatchTodo_0;
/* 079 */ if (range_numElementsTodo_0 > 1000L) {
/* 080 */ range_nextBatchTodo_0 = 1000L;
/* 081 */ range_numElementsTodo_0 -= 1000L;
/* 082 */ } else {
/* 083 */ range_nextBatchTodo_0 = range_numElementsTodo_0;
/* 084 */ range_numElementsTodo_0 = 0;
/* 085 */ if (range_nextBatchTodo_0 == 0) break;
/* 086 */ }
/* 087 */ range_batchEnd_0 += range_nextBatchTodo_0 * 1L;
/* 088 */ }
/* 089 */
/* 090 */ int range_localEnd_0 = (int)((range_batchEnd_0 - range_nextIndex_0) / 1L);
/* 091 */ for (int range_localIdx_0 = 0; range_localIdx_0 < range_localEnd_0; range_localIdx_0++) {
/* 092 */ long range_value_0 = ((long)range_localIdx_0 * 1L) + range_nextIndex_0;
/* 093 */
/* 094 */ range_mutableStateArray_0[0].reset();
/* 095 */
/* 096 */ range_mutableStateArray_0[0].write(0, range_value_0);
/* 097 */ append((range_mutableStateArray_0[0].getRow()));
/* 098 */
/* 099 */ if (shouldStop()) {
/* 100 */ range_nextIndex_0 = range_value_0 + 1L;
/* 101 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localIdx_0 + 1);
/* 102 */ range_inputMetrics_0.incRecordsRead(range_localIdx_0 + 1);
/* 103 */ return;
/* 104 */ }
/* 105 */
/* 106 */ }
/* 107 */ range_nextIndex_0 = range_batchEnd_0;
/* 108 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(range_localEnd_0);
/* 109 */ range_inputMetrics_0.incRecordsRead(range_localEnd_0);
/* 110 */ range_taskContext_0.killTaskIfInterrupted();
/* 111 */ }
/* 112 */ }
/* 113 */
/* 114 */ }
== Subtree 2 / 2 (maxMethodCodeSize:89; maxConstantPoolSize:91(0.14% used); numInnerClasses:0) ==
*(2) Project [(id#0L + 1) AS (id + 1)#4L]
+- Filter (id#0L = 1)
+- *(1) Range (0, 10, step=1, splits=2)
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage2(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private scala.collection.Iterator inputadapter_input_0;
/* 010 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] project_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[1];
/* 011 */
/* 012 */ public GeneratedIteratorForCodegenStage2(Object[] references) {
/* 013 */ this.references = references;
/* 014 */ }
/* 015 */
/* 016 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 017 */ partitionIndex = index;
/* 018 */ this.inputs = inputs;
/* 019 */ inputadapter_input_0 = inputs[0];
/* 020 */ project_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(1, 0);
/* 021 */
/* 022 */ }
/* 023 */
/* 024 */ protected void processNext() throws java.io.IOException {
/* 025 */ while ( inputadapter_input_0.hasNext()) {
/* 026 */ InternalRow inputadapter_row_0 = (InternalRow) inputadapter_input_0.next();
/* 027 */
/* 028 */ // common sub-expressions
/* 029 */
/* 030 */ long inputadapter_value_0 = inputadapter_row_0.getLong(0);
/* 031 */
/* 032 */ long project_value_0 = -1L;
/* 033 */
/* 034 */ project_value_0 = inputadapter_value_0 + 1L;
/* 035 */ project_mutableStateArray_0[0].reset();
/* 036 */
/* 037 */ project_mutableStateArray_0[0].write(0, project_value_0);
/* 038 */ append((project_mutableStateArray_0[0].getRow()));
/* 039 */ if (shouldStop()) return;
/* 040 */ }
/* 041 */ }
/* 042 */
/* 043 */ }
16:27:47.464 WARN org.apache.spark.sql.execution.WholeStageCodegenSuite:
===== POSSIBLE THREAD LEAK IN SUITE o.a.s.sql.execution.WholeStageCodegenSuite, thread names: rpc-boss-3-1, shuffle-boss-6-1 =====
Process finished with exit code 0
最里侧的operator
比如rangeExec, 肯定要实现 doproduce方法,但 consume不需要实现,直接调用父类的consume()
/**
* Physical plan for range (generating a range of 64 bit numbers).
*/
case class RangeExec(range: org.apache.spark.sql.catalyst.plans.logical.Range)
extends LeafExecNode with CodegenSupport {
val start: Long = range.start
val end: Long = range.end
val step: Long = range.step
val numSlices: Int = range.numSlices.getOrElse(sparkContext.defaultParallelism)
val numElements: BigInt = range.numElements
val isEmptyRange: Boolean = start == end || (start < end ^ 0 < step)
override val output: Seq[Attribute] = range.output
override def outputOrdering: Seq[SortOrder] = range.outputOrdering
override def outputPartitioning: Partitioning = {
if (numElements > 0) {
if (numSlices == 1) {
SinglePartition
} else {
RangePartitioning(outputOrdering, numSlices)
}
} else {
UnknownPartitioning(0)
}
}
override lazy val metrics = Map(
"numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"))
override def doCanonicalize(): SparkPlan = {
RangeExec(range.canonicalized.asInstanceOf[org.apache.spark.sql.catalyst.plans.logical.Range])
}
override def inputRDDs(): Seq[RDD[InternalRow]] = {
val rdd = if (isEmptyRange) {
new EmptyRDD[InternalRow](sqlContext.sparkContext)
} else {
sqlContext.sparkContext.parallelize(0 until numSlices, numSlices).map(i => InternalRow(i))
}
rdd :: Nil
}
protected override def doProduce(ctx: CodegenContext): String = {
val numOutput = metricTerm(ctx, "numOutputRows")
val initTerm = ctx.addMutableState(CodeGenerator.JAVA_BOOLEAN, "initRange")
val nextIndex = ctx.addMutableState(CodeGenerator.JAVA_LONG, "nextIndex")
val value = ctx.freshName("value")
val ev = ExprCode.forNonNullValue(JavaCode.variable(value, LongType))
val BigInt = classOf[java.math.BigInteger].getName
// Inline mutable state since not many Range operations in a task
val taskContext = ctx.addMutableState("TaskContext", "taskContext",
v => s"$v = TaskContext.get();", forceInline = true)
val inputMetrics = ctx.addMutableState("InputMetrics", "inputMetrics",
v => s"$v = $taskContext.taskMetrics().inputMetrics();", forceInline = true)
// In order to periodically update the metrics without inflicting performance penalty, this
// operator produces elements in batches. After a batch is complete, the metrics are updated
// and a new batch is started.
// In the implementation below, the code in the inner loop is producing all the values
// within a batch, while the code in the outer loop is setting batch parameters and updating
// the metrics.
// Once nextIndex == batchEnd, it's time to progress to the next batch.
val batchEnd = ctx.addMutableState(CodeGenerator.JAVA_LONG, "batchEnd")
// How many values should still be generated by this range operator.
val numElementsTodo = ctx.addMutableState(CodeGenerator.JAVA_LONG, "numElementsTodo")
// How many values should be generated in the next batch.
val nextBatchTodo = ctx.freshName("nextBatchTodo")
// The default size of a batch, which must be positive integer
val batchSize = 1000
val initRangeFuncName = ctx.addNewFunction("initRange",
s"""
| private void initRange(int idx) {
| $BigInt index = $BigInt.valueOf(idx);
| $BigInt numSlice = $BigInt.valueOf(${numSlices}L);
| $BigInt numElement = $BigInt.valueOf(${numElements.toLong}L);
| $BigInt step = $BigInt.valueOf(${step}L);
| $BigInt start = $BigInt.valueOf(${start}L);
| long partitionEnd;
|
| $BigInt st = index.multiply(numElement).divide(numSlice).multiply(step).add(start);
| if (st.compareTo($BigInt.valueOf(Long.MAX_VALUE)) > 0) {
| $nextIndex = Long.MAX_VALUE;
| } else if (st.compareTo($BigInt.valueOf(Long.MIN_VALUE)) < 0) {
| $nextIndex = Long.MIN_VALUE;
| } else {
| $nextIndex = st.longValue();
| }
| $batchEnd = $nextIndex;
|
| $BigInt end = index.add($BigInt.ONE).multiply(numElement).divide(numSlice)
| .multiply(step).add(start);
| if (end.compareTo($BigInt.valueOf(Long.MAX_VALUE)) > 0) {
| partitionEnd = Long.MAX_VALUE;
| } else if (end.compareTo($BigInt.valueOf(Long.MIN_VALUE)) < 0) {
| partitionEnd = Long.MIN_VALUE;
| } else {
| partitionEnd = end.longValue();
| }
|
| $BigInt startToEnd = $BigInt.valueOf(partitionEnd).subtract(
| $BigInt.valueOf($nextIndex));
| $numElementsTodo = startToEnd.divide(step).longValue();
| if ($numElementsTodo < 0) {
| $numElementsTodo = 0;
| } else if (startToEnd.remainder(step).compareTo($BigInt.valueOf(0L)) != 0) {
| $numElementsTodo++;
| }
| }
""".stripMargin)
val localIdx = ctx.freshName("localIdx")
val localEnd = ctx.freshName("localEnd")
val stopCheck = if (parent.needStopCheck) {
s"""
|if (shouldStop()) {
| $nextIndex = $value + ${step}L;
| $numOutput.add($localIdx + 1);
| $inputMetrics.incRecordsRead($localIdx + 1);
| return;
|}
""".stripMargin
} else {
"// shouldStop check is eliminated"
}
val loopCondition = if (limitNotReachedChecks.isEmpty) {
"true"
} else {
limitNotReachedChecks.mkString(" && ")
}
// An overview of the Range processing.
//
// For each partition, the Range task needs to produce records from partition start(inclusive)
// to end(exclusive). For better performance, we separate the partition range into batches, and
// use 2 loops to produce data. The outer while loop is used to iterate batches, and the inner
// for loop is used to iterate records inside a batch.
//
// `nextIndex` tracks the index of the next record that is going to be consumed, initialized
// with partition start. `batchEnd` tracks the end index of the current batch, initialized
// with `nextIndex`. In the outer loop, we first check if `nextIndex == batchEnd`. If it's true,
// it means the current batch is fully consumed, and we will update `batchEnd` to process the
// next batch. If `batchEnd` reaches partition end, exit the outer loop. Finally we enter the
// inner loop. Note that, when we enter inner loop, `nextIndex` must be different from
// `batchEnd`, otherwise we already exit the outer loop.
//
// The inner loop iterates from 0 to `localEnd`, which is calculated by
// `(batchEnd - nextIndex) / step`. Since `batchEnd` is increased by `nextBatchTodo * step` in
// the outer loop, and initialized with `nextIndex`, so `batchEnd - nextIndex` is always
// divisible by `step`. The `nextIndex` is increased by `step` during each iteration, and ends
// up being equal to `batchEnd` when the inner loop finishes.
//
// The inner loop can be interrupted, if the query has produced at least one result row, so that
// we don't buffer too many result rows and waste memory. It's ok to interrupt the inner loop,
// because `nextIndex` will be updated before interrupting.
s"""
| // initialize Range
| if (!$initTerm) {
| $initTerm = true;
| $initRangeFuncName(partitionIndex);
| }
|
| while ($loopCondition) {
| if ($nextIndex == $batchEnd) {
| long $nextBatchTodo;
| if ($numElementsTodo > ${batchSize}L) {
| $nextBatchTodo = ${batchSize}L;
| $numElementsTodo -= ${batchSize}L;
| } else {
| $nextBatchTodo = $numElementsTodo;
| $numElementsTodo = 0;
| if ($nextBatchTodo == 0) break;
| }
| $batchEnd += $nextBatchTodo * ${step}L;
| }
|
| int $localEnd = (int)(($batchEnd - $nextIndex) / ${step}L);
| for (int $localIdx = 0; $localIdx < $localEnd; $localIdx++) {
| long $value = ((long)$localIdx * ${step}L) + $nextIndex;
| ${consume(ctx, Seq(ev))}
| $stopCheck
| }
| $nextIndex = $batchEnd;
| $numOutput.add($localEnd);
| $inputMetrics.incRecordsRead($localEnd);
| $taskContext.killTaskIfInterrupted();
| }
""".stripMargin
}
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
if (isEmptyRange) {
new EmptyRDD[InternalRow](sqlContext.sparkContext)
} else {
sqlContext
.sparkContext
.parallelize(0 until numSlices, numSlices)
.mapPartitionsWithIndex { (i, _) =>
val partitionStart = (i * numElements) / numSlices * step + start
val partitionEnd = (((i + 1) * numElements) / numSlices) * step + start
def getSafeMargin(bi: BigInt): Long =
if (bi.isValidLong) {
bi.toLong
} else if (bi > 0) {
Long.MaxValue
} else {
Long.MinValue
}
val safePartitionStart = getSafeMargin(partitionStart)
val safePartitionEnd = getSafeMargin(partitionEnd)
val rowSize = UnsafeRow.calculateBitSetWidthInBytes(1) + LongType.defaultSize
val unsafeRow = UnsafeRow.createFromByteArray(rowSize, 1)
val taskContext = TaskContext.get()
val iter = new Iterator[InternalRow] {
private[this] var number: Long = safePartitionStart
private[this] var overflow: Boolean = false
private[this] val inputMetrics = taskContext.taskMetrics().inputMetrics
override def hasNext =
if (!overflow) {
if (step > 0) {
number < safePartitionEnd
} else {
number > safePartitionEnd
}
} else false
override def next() = {
val ret = number
number += step
if (number < ret ^ step < 0) {
// we have Long.MaxValue + Long.MaxValue < Long.MaxValue
// and Long.MinValue + Long.MinValue > Long.MinValue, so iff the step causes a step
// back, we are pretty sure that we have an overflow.
overflow = true
}
numOutputRows += 1
inputMetrics.incRecordsRead(1)
unsafeRow.setLong(0, ret)
unsafeRow
}
}
new InterruptibleIterator(taskContext, iter)
}
}
}
override def simpleString(maxFields: Int): String = {
s"Range ($start, $end, step=$step, splits=$numSlices)"
相关配置
val WHOLESTAGE_CODEGEN_ENABLED = buildConf("spark.sql.codegen.wholeStage")
.internal()
.doc("When true, the whole stage (of multiple operators) will be compiled into single java" +
" method.")
.version("2.0.0")
.booleanConf
.createWithDefault(true)