爬虫进阶-1-多线程爬虫入门
爬虫进阶入门-1-多线程爬虫入门
单线程爬虫每次只能访问一个页面,不能充分利用计算机的网络带宽。一个页面最多也就几百KB,所以在爬取一个页面的时候,多出来的网速和从发起请求到源代码中间的时间被白白浪费。
如果我们可以让爬虫同时发生在10个页面,就相当于是爬取速度提高了10倍,为了达到这个效果,就需要用到多线程技术。

全局锁GIL
Python中有一个全局锁的概念:GIL,Global Interpreter Lock,使得Python的多线程实际上还是一个线程,是一个伪多线程。
但是每个线程执行的时间只有几毫秒,几毫秒之后就可以恢复并保存现场,再进行其他事情,几毫秒之后再做其他,这样的过程时间间隔非常小;微观上的单线程,就好像是同时在做几件事,感觉上就好像是多线程。
这种机制在I/O(输入/输出)密集型的操作上影响不大,但是在CPU计算密集型的操作上面,由于只能使用CPU的一个核,就会对性能产生很大的影响。
Python的多进程不受GIL影响,爬虫是属于I/O密集型的程序。在爬取网页的时候请求源码的时候,如果使用单线程开发,会浪费大量的时间来等待网页返回数据,将多线程技术应用到爬虫中,可以大大提供爬虫的运行效率。
多进程库
multiprocessing本身是Python的多进程库,用来处理和多进程相关的操作。
- 进程和进程之间不能共享内存和堆栈资源
- 启动新的进程开销比线程大的多
使用多线程爬取更有优势
- 开销小
- 资源共享
multiprocessing下面的dummy模块能够让Python的线程使用multiprocessing的各种方法:
- dummy下的Pool类:实现线程池
- 线程池的map方法,可以让线程池里面的所有线程同时执行一个函数
举例说明:计算0-10000每个数的平方
通过不同方式运行的时间,我们来进行对比
(1)我们使用for循环实现:
for i in range(0,10000):
print(i**i)
电脑跑崩了改成计算0-1000的时间都比下面的时间长。
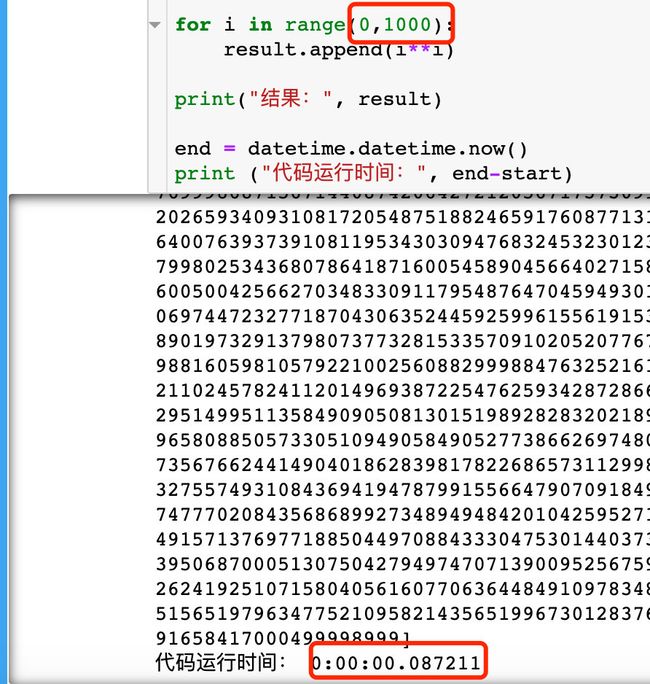
(2)使用多线程技术实现:
from multiprocessing.dummy import Pool
import datetime
start = datetime.datetime.now() # 初始时间
def pingfang(num): # 定义函数
return num * num
pool = Pool(3) # 开启3个线程
origin_num = [x for x in range(0,10000)] # 初始数据
result = pool.map(pingfang, origin_num) # 函数+参数
print("结果:", result)
end = datetime.datetime.now() # 结束时间
print ("代码运行时间:", end-start)

map函数的两个参数:
- 需要执行的函数名,不能带括号
- 列表,可迭代对象(元组、集合都可以),里面的每个元素都执行前面的函数
多线程爬虫
通过访问百度首页100次来进行对比
(1)、单线程访问
# 单线程运行
def query(url):
requests.get(url)
start = time.time()
for i in range(100):
query("https://baidu.com")
end = time.time()
print("单线程时间差:",end-start)

(2)、多线程访问
# 多线程运行
from multiprocessing.dummy import Pool
import time
start = time.time()
def query(url):
requests.get(url)
url_list = []
for i in range(100):
url_list.append("https://baidu.com")
pool = Pool(5)
pool.map(query, url_list)
end = time.time()
print("多线程时间:", end-start)

多线程的时间比单线程的五分之一多一点,这多出来的就是切换线程的时间,所以Python的多线程其实还是串行的:执行一个线程,立马切换,再执行下一个线程,再切换,再执行下一个。只是中间切换的时间极短
线程池的大小需要根据实际情况来确定
练习网站:http://exercise.kingname.info/
一切看似逝去的,都不曾离开,你所给与的爱与温暖,让我执着地守护着这里。
尤而小屋,一个温馨的小屋。小屋主人,一手代码谋求生存,一手掌勺享受生活,欢迎你的光临
