大数据——基于Spark Streaming的流数据处理和分析
基于Spark Streaming的流数据处理和分析
- 流是什么
- 为什么需要流处理
- 流处理应用场景
- 如何进行流处理
- Spark Streaming简介
- Spark Streaming流数据处理架构
- Spark Streaming内部工作流程
- StreamingContext
- Spark Streaming快速入门
- DStream
- Input DStreams与接收器(Receivers)
-
- 内建流式数据源
- DStream支持的转换算子
-
- 转换算子-transform
- DStream输出算子
-
- 输出算子-foreachRDD
- Spark Streaming编程实例(一)
- Spark Streaming编程实例(二)
- Spark Streaming编程实例(三)
- Spark Streaming高级应用(一)
- Spark Streaming高级应用(二)
- Spark Streaming优化策略
流是什么
- 数据流
- 数据的流入
- 数据的处理
- 数据的流出
- 随处可见的数据流
- 电商网站、日志服务器、社交网络和交通监控产生的大量实时数据
- 流处理
- 是一种允许用户在接收到的数据后的段时间内快速查询连续数据流和检测条件的技术
为什么需要流处理
- 它能够更快地提供洞察力,通常在毫秒到秒之间
- 大部分数据的产生过程都是一个永无止境的事件流
- 流处理自然适合时间序列数据和检测模式随时间推移
流处理应用场景
- 股市监控
- 交通监控
- 计算机系统与网络监控
- 监控生产线
- 供应链优化
- 入侵、监视和欺诈检测
- 大多数智能设备应用
- 上下文感知促销和广告
- …
如何进行流处理
- 常用流处理框架
- Apache Spark Streaming
- Apache Flink
- Confluent
- Apache Storm
Spark Streaming简介
- 是基于Spark Core API的扩展,用于流式数据处理
- 支持多种数据源和多种输出
- 高容错
- 可扩展
- 高流量
- 低延时

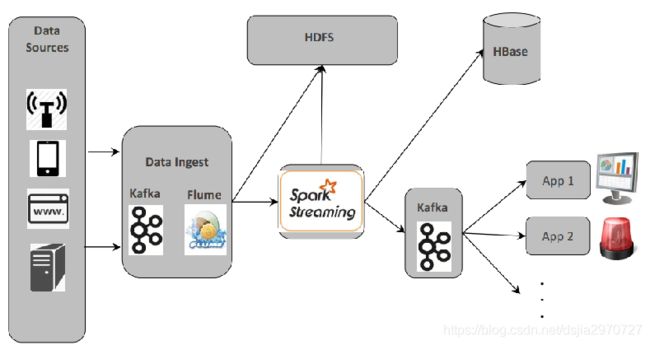
Spark Streaming流数据处理架构
- 典型架构
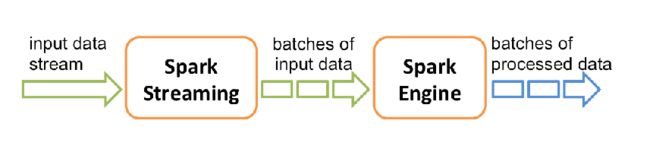
Spark Streaming内部工作流程
- 微批处理:输入->分批处理->结果集
- 以离散流的形式传入数据(DStream:Discretized Streams)
- 流被分成微批次(1-10s),每一微批都是一个RDD
StreamingContext
- Spark Streaming流处理的入口
- 2.2版本SparkSession未整合StreamingContext,所以仍需单独创建
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val conf=new SparkConf().setMaster("local[2]").setAppName("kgc streaming demo")
val ssc=new StreamingContext(conf,Seconds(8))
1、一个JVM只能有一个StreamingContext启动
2、StreamingContext停止后不能再启动
在Spark-shell下,会出现如下错误提示:
org.apache.spark.SparkException:Only onc SparkContext may be running in this JVM
解决:
方法1、sc.stop //创建ssc之前,停止spark-shell自行启动的SparkContext
方法2、或者通过已有的sc创建ssc:val ssc=new StreamingContext(sc,Seconds(8))
Spark Streaming快速入门
- 单词统计——基于TCPSocket接收文本数据
$nc -lk 9999 //数据服务器。当ssc启动后输入测试数据,观察Spark Streaming处理结果
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val sparkConf = new
//local[n]其中n>接收器的个数
SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
//DStream
val lines = ssc.socketTextStream("localhost", 9999)//指定数据源
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
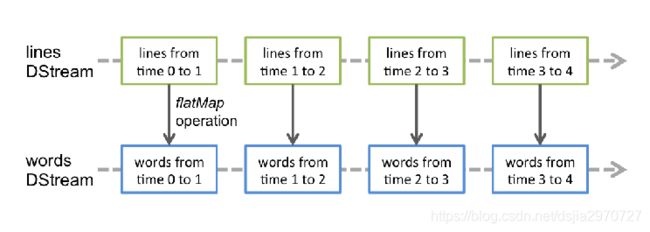
DStream
- 离散数据流(Discretized Stream)是Spark Streaming提供的高级别抽象
- DStream代表了一系列连续的RDDs
- 每个RDD都包含了一个时间间隔内的数据
- DStream既是输入的数据流,也是对转换处理过的数据流
- 对DStream的转换操作即是对具体RDD操作
Input DStreams与接收器(Receivers)
- Input DStream指从某种流式数据源(Streaming Sources)接收流数据的DStream
- 内建流式数据源:文件系统、Socket、Kafka、Flume…

- 内建流式数据源:文件系统、Socket、Kafka、Flume…
每一个Input DStream(file stream除外)都与一个接收器(Receiver)相关联,接收器是从数据源提取数据到内存的专用对象
内建流式数据源
- 文件系统
def textFileStream(directory: String): DStream[String]
- Socket
def socketTextStream(hostname: String, port: Int, storageLevel: StorageLevel): ReceiverInputDStream[String]
- Flume Sink
val ds = FlumeUtils.createPollingStream(streamCtx, [sink hostname], [sink port]);
- Kafka Consumer
val ds = KafkaUtils.createStream(streamCtx, zooKeeper, consumerGrp, topicMap);
DStream支持的转换算子
- map,flatMap
- filter
- count,countByValue
- repartition
- union,join,cogroup
- reudce,reduceByKey
- transform
- updateStateByKey
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val input1 = List((1, true), (2, false), (3, false), (4, true), (5, false))
val input2 = List((1, false), (2, false), (3, true), (4, true), (5, true))
val rdd1 = sc.parallelize(input1)
val rdd2 = sc.parallelize(input2)
val ssc = new StreamingContext(sc, Seconds(3))
import scala.collection.mutable
val ds1 = ssc.queueStream[(Int, Boolean)](mutable.Queue(rdd1))
val ds2 = ssc.queueStream[(Int, Boolean)](mutable.Queue(rdd2))
val ds = ds1.join(ds2)
ds.print()
ssc.start()
ssc.awaitTerminationOrTimeout(5000)
ssc.stop()
转换算子-transform
- transform操作允许在DStream应用任意RDD-TO-RDD的函数
// RDD 包含垃圾邮件信息
//从Hadoop接口API创建RDD
val spamRDD = ssc.sparkContext.newAPIHadoopRDD(...)
val cleanedDStream = wordCounts.transform { rdd =>
//用垃圾邮件信息连接数据流进行数据清理 rdd.join(spamRDD).filter( /* code... */)
// 其它操作...
}
DStream输出算子
- print()
- saveAsTextFiles(prefix,[suffix])
- saveAsObjectFiles(prefix,[suffix])
- saveAsHadoopFiles(prefix,[suffix])
- foreachRDD(func)
- 接收一个函数,并将该函数作用于DStream每个RDD上
- 函数在Driver节点上执行
输出算子-foreachRDD
//错误
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // 在driver节点执行
rdd.foreach { record =>
connection.send(record) // 在worker节点执行
}
}
//正确
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record =>
connection.send(record))
}
}
Spark Streaming编程实例(一)
- 需求:使用Spark Streaming统计HDFS文件的词频
- 关键代码
val sparkConf = new SparkConf().setAppName("HdfsWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// 创建FileInputDStream去读取文件系统上的数据
val lines = ssc.textFileStream("/data/input") //启动后,往该HDFS目录上传文本文件并观察输出
//使用空格进行分割每行记录的字符串
val words = lines.flatMap(_.split(" "))
//类似于RDD的编程,将每个单词赋值为1,并进行合并计算
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
Spark Streaming编程实例(二)
- 使用Spark Streaming处理带状态的数据
- 需求:计算到目前位置累计词频的个数
- 分析:DStream转换操作包括无状态转换换和有状态转换
- 无状态转换:每个批次的处理不依赖于之前批次的数据
- 有状态转换:当前批次的处理需要使用之前批次的数据
- updateStateByKey属于有状态转换,可以跟踪状态的变化
- 实现要点
- 定义状态:状态数据可以是任意类型
- 定义状态更新函数:参数为数据流之前的状态和新的数据流数据
- 关键代码StatefulWordCount.scala
//定义状态更新函数
def updateFunction(currentValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val curr = currentValues.sum
val pre = preValues.getOrElse(0)
Some(curr + pre)
}
val sparkConf = new SparkConf().setAppName("StatefulWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint(".")
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_, 1))
val state = result.updateStateByKey(updateFunction)
state.print()
ssc.start()
ssc.awaitTermination()

Spark Streaming编程实例(三)
- Spark Steaming整合Spark SQL
- 需求:使用Spark Streaming+Spark SQL完成WordCount
- 分析:将每个RDD转换为DataFrame
case class Word(word:String)
val sparkConf = new SparkConf().setAppName("NetworkSQLWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val spark=SparkSession.builder.config(sparkConf).getOrCreate()
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" "))
result.print()
result.foreachRDD(rdd => {
if (rdd.count() != 0) {
import spark.implicits._
//将RDD转换成DataFrame
val df = rdd.map(x => Word(x)).toDF
df.registerTempTable("tb_word")
spark.sql("select word, count(*) from tb_word group by word").show
}})
ssc.start()
ssc.awaitTermination()
Spark Streaming高级应用(一)
- Spark Streaming整合Flume
- Flume依赖:org.apache.spark:spark-streaming -flume_2.11:2.x.x
- Flume Agent配置文件
#SparkSink——Pull方式:Spark使用Flume接收器从sink中拉取数据
simple-agent.sinks.spark-sink.type=org.apache.spark.streaming.flume.sink.SparkSink
simple-agent.sinks.spark-sink.channel=netcat-memory-channel
simple-agent.sinks.spark-sink.hostname=localhost
simple-agent.sinks.spark-sink.type=41414
- Spark Streaming处理Flume数据
//Pull方式关键代码
val flumeStream=FlumeUtils.createPollingStream(ssc,"localhost",41414,StorageLevel.MEMORY_ONLY_SER_2)
flumeStream.map(x=>new String(x.event.getBody.array()).trim).flatMap(_.split(" "))
……
- 运行方式
- 启动Flume
- 启动Spark Streaming作业
- telne连接44444端口并发送数据
$/opt/flume/bin/flume-ng agent --name simple-agent \
--conf-file ./flume_push_streaming.conf -Dflume.root.logger=INFO,console &
$spark-submit \
--class cn.kgc.FlumePushWordCount \
--jars spark-streaming-flume_2.11-2.3.0.cloudera1.jar,/opt/flume/lib/flume-ng-sdk-1.8.0.jar \
./sparkdemo-1.0-SNAPSHOT.jar localhost 41414
#新开终端进行测试,44444是Flume agent source连接的netcat端口
telnet localhost 44444
Spark Streaming高级应用(二)
- Spark Streaming整合Kafka
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, LocationStrategies}
val Array(brokers, topics) = args
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount").setMaster("local[1]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("bootstrap.servers" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet,kafkaParams))
messages.map(_.value()) // 取出value
.flatMap(_.split(" ")) // 将字符串使用空格分隔
.map(word => (word, 1)) // 每个单词映射成一个pair
.reduceByKey(_+_) // 根据每个key进行累加
.print() // 打印前10个数据
ssc.start()
ssc.awaitTermination()
Spark Streaming优化策略
- 减少批处理时间
- 数据接收并发度
- 数据处理并发度
- 任务启动开销
- 设置合适的批次间隔
- 内存调优
- DStream持久化级别
- 清除老数据
- CMS垃圾回收器
- 其他:使用堆外内存持久化RDD