物联网入门系列(一):快速搭建一站式数据存储与实时分析平台
本系列文章将以教程形式介绍物联网领域用户在安装部署、分布式数据库设计、数据写入和查询、流计算和高可用测试等过程中的常见问题、相应的解决方案与注意事项,以帮助新用户快速入门,体验 DolphinDB 的极致性能。
本次介绍内容为——如何快速搭建一站式数据存储与实时分析平台。
1. 快速体验
1.1 安装部署单节点服务
入门用户可先部署一个单节点模式 DolphinDB 以快速体验。单节点模式拥有与集群模式相同的功能,区别在于单节点模式不支持扩展节点和高可用,而集群模式可以方便地扩展到多个服务器节点以及支持高可用。安装的第一步是在官网下载DolphinDB 社区试用版。
-
选择 Windows 版本还是 Linux 版本?Linux 服务器比 Windows 服务器更稳定,建议生产环境选用 Linux 版本。若您现有环境是 Windows,亦可选择Windows 版本进行体验。
-
选择稳定版还是最新版?目前一般1-2周会发布一个最新版。新版本不仅包含 bug 修复,还可能包含新功能、改进、性能优化等其他内容的更新,可能会带来新的 bug。若用于生产环境,出于对稳定性的要求,请选择稳定版。稳定版只修复 bug,不增加新功能。若进行体验与测试,可选择最新版。
-
若选择了最新版,选择 JIT (即时编译)版本还是非 JIT 版本?DolphinDB 的即时编译功能显著提高了 for 循环,while 循环和 if-else 等语句的运行速度,特别适合于无法使用向量化运算但又对运行速度有极高要求的场景。但另一方面,DolphinDB 的 JIT 版本使用一个动态库,安装包要增加10多兆字节,这对原本仅20来兆的安装包相当可观。所以请综合考虑是否需要即时编译功能以及是否对安装包大小敏感,以决定是否下载 JIT 版本。
下载后,请参照单节点部署教程部署 DolphinDB。以 Linux 系统为例,步骤如下:
wget https://www.dolphindb.com/downloads/DolphinDB_Linux64_V1.30.7.zip
unzip DolphinDB_Linux64_V1.30.7.zip -d dolphindb
cd dolphindb/server
chmod +x dolphindb
./dolphindb安装路径名不要含有空格或中文字符,否则会提示异常:Cannot open configuration file。
安装过程若出现错误提示:Failed to bind the socket on port 8848,说明8848端口已被其他程序占用,请更换端口。假设修改端口为8900,可在配置文件dolphindb.cfg中进行如下修改:
localSite=localhost:8900:local8900启动后出现如下界面。然后在Console中输入1+1;,若输出2,即安装成功。

注意:
- 上述命令中 DolphinDB_Linux64_V1.30.7.zip 表明下载的是1.30.7版本,若是其他版本,请修改文件名中的版本号。
- 上述命令中采用前台运行的方式,若要后台运行,修改
./dolphindb命令为nohup ./dolphindb -console 0 &或sh startSingle.sh,然后用命令ps aux | grep dolphindb查看dolphindb进程是否已启动。若启动失败,请打开安装目录下的日志文件 dolphindb.log,查看日志中的错误提示信息。 - 数据文件默认存放在< DolphinDB 安装包 >/server/local8848/storage/CHUNKS。请选择容量较大的磁盘存放数据文件,并通过参数 volumes 配置数据文件存放目录。
- DolphinDB 通过参数 maxMemSize 设置节点的最大内存使用量,默认设置为0,表示内存使用没有限制。内存对于改进节点的计算性能非常明显,尽可能高配,但也不能设置太大。例如一台机器内存为16GB,并且只部署1个节点,建议将该参数设置为12GB 左右。否则使用内存接近或超过实际物理内存,有可能会触发操作系统强制关闭进程。如果在数据库使用过程中发生奔溃,可以用
dmesg -T | grep dolphindb查看一下Linux日志,确认一下是否被操作系统kill。 - 其他配置项请参见用户手册。修改配置后,需要重启 DolphinDB 服务。前台用
quit命令退出,后台用kill -9 <进程号>退出。
1.2 测试GUI和Web连接
1.2.1 GUI连接
DolphinDB 提供了多种方式与数据库交互,如 GUI、VSCode 插件、Web Notebook、Jupyter Notebook、命令行等。对入门用户,建议使用 DolphinDB GUI 编写 DolphinDB 脚本。请到DolphinDB 官网下载 DolphinDB GUI 。安装前,需要确保已经安装 Java 8 及以上 64bit 版本。DolphinDB GUI 无需安装,开箱即用。在 Windows 环境下,双击 gui.bat 即可。在 Linu 和 Mac 环境下,在 Terminal 中输入:
cd /your/gui/folder
chmod +x gui.sh
./gui.sh若 GUI 无法启动,请在 GUI 安装目录下运行:
java -version若系统不能显示 Java 版本信息,说明Java没有安装或 Java 的安装路径不在系统路径中。在Windows 上,需要查看是否在 Path 中;在 Linux 上,需要查看是否在 PATH 中。
若命令显示了 Java 版本信息,请检查版本是否符合要求。DolphinDB GUI 使用环境需要64 位Java 8 及以上版本。32 位的 Java 由于只支持 Client 模式,不支持 Server 模式,所以无法启动GUI。符合要求的 Java 版本示例如下:
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)如果版本信息的最后一行如下所示,那么 DolphinDB GUI 将无法正常启动,需要到 Oracle官网重新下载安装。
Java HotSpot(TM) Client VMGUI 启动后,首先根据提示,选择一个文件夹作为工作区。然后请参照 GUI帮助手册的说明,连接DolphinDB 服务器,新建项目和脚本文件,再运行脚本。执行脚本时若出现错误提示:Failed to connect to selected server,请检查:
-
DolphinDB 端口是否被防火墙屏蔽。若端口没有开放,需要在防火墙打开该端口。
-
DolphinDB server 的 license 是否过期。
-
中文出现乱码
请在菜单栏点击 File-Preferences,在 Font 中设置中文字体,例如微软雅黑( Microsoft Yahei )。 然后执行 print (变量名),查看输出结果,乱码是否消失。
- 浮点数精度丢失
DolphinDB GUI 默认精度是 4 位,如果需要更高或低的精度,请在菜单栏点击 File-Preferences, 在 Default number of decimal places 中调整精度,例如设置为 8。
- 执行脚本提示:java.lang.OutOfMemoryError: Java heap space
这意味着发生 GUI 内存溢出,说明 GUI 的默认 2048MB 启动内存不能满足需要。这种情况一般是由于执行了结果的数据量较大的SQL查询且未将查询结果赋值予一个变量(例如直接执行 select ... from ...),因为此种操作会将结果的全部数据返回GUI,占用GUI的内存。要避免此种情况下的 GUI内存溢出,只需将结果赋值于一个变量,例如 t = select ... from ... 即可。此类语句在 server 端执行,不占用 GUI 内存。
假设需将 GUI 的内存扩大至 4096MB,可修改 gui/gui.bat 或者 gui/gui.sh中的 -Xmx 启动参数,如下:
start javaw -classpath dolphindb.jar;dolphingui.jar;jfreechart-1.0.1.jar;jcommon-1.0.0.jar;jxl-2.6.12.jar;rsyntaxarea.jar;autocomplete.jar -Dlook=cross -Xmx4096m com.xxdb.gui.XXDBMain关于 DolphinDB GUI 的更多细节,请参阅 DolphinDB客户端教程第1节。
1.2.2 Web 连接
Web Notebook 是 DolphinDB 安装包自带的、基于网页的图形化交互工具,主要用于系统监控、日志查看、以及数据浏览,也可用于快速编辑执行代码、查看变量、以及基本的画图功能。与 GUI不同,Web Notebook 更适合临时任务,不适于执行复杂的开发任务。为了保证 DolphinDB 服务器的性能,若10分钟内无命令执行,系统会自动关闭 Notebook 的会话以释放 DolphinDB 系统资源。在单节点模式下,启动 DolphinDB 服务器后,只要在浏览器输入网址(http://IP:PORT ,默认为 http://localhost:8848 )即可访问。若无法访问,请检查:
- DolphinDB 端口是否被防火墙屏蔽。若端口没有开放,需要在防火墙打开该端口。
- DolphinDB server 的 license 是否过期。
- http 是否写成了 https。若需要使用 https 协议访问 web,请按照权限管理和安全第3节"使用HTTPS 实现安全通信"进行配置。
DolphinDB Notebook 不会强制用户登录服务器,但是有些功能例如浏览/创建数据库或分区表需要登录才能访问。如果需要将权限设置为用户登录后才能执行脚本,单节点模式下可在配置文件dolphindb.cfg 中添加配置项:
webLoginRequired=true;若用户成功登录,会在屏幕上方显示登录用户名。如果10分钟内无命令执行,会自动退出登录。
有关如何使用 Web Notebook 的更多信息,请参阅 DolphinDB客户端教程第3节。
1.3 使用脚本建库建表
DolphinDB 采用数据分区技术,按照用户指定的规则将大规模数据集水平分区,每个分区内的数据采用列式存储。在数据存储时,一个分区是一个目录。以按天分区为例,一天的数据存于同一个目录下。借助数据分区,在后续的查询过程中可直接跳过不必要的数据目录,从而提升查询性能。合理地利用分区,还可以实现数据的更新与删除操作,譬如数据表按天分区,那么数据就可以按天的粒度被更新或删除。
DolphinDB 的每个分布式数据库采用一种分区机制,一个数据库内的多个事实表( fact table )共享这种分区机制,而且同一个分区的多个子表( tablet chunk )数据落在同一个节点上,保证同一个数据库的多个事实表连接( join )的效率非常高。除了分布式的事实表,DolphinDB 还提供了不分区的维度表(dimension table),通常用于存储不经常更新的小数据集。这类数据的数据量通常不会随着时间的积累而增长,而且数据内容变化较小。维度表可与任何采用分区机制的事实表关联。
在 DolphinDB 中,数据库使用 database 函数创建,分区表和维度表分别使用createPartitionedTable和 createTable 函数创建。具体请参考用户手册中创建数据库和表这一节。
DolphinDB 不提供行级的索引,而是将分区作为数据库的物理索引。一个分区字段相当于数据表的一个物理索引。如果查询时用到了该分区字段做数据过滤,SQL 引擎就能快速定位需要的数据块,而无需对整表进行扫描。为提高查询和计算性能,每个分区的数据量不宜过大、也不宜过小,一般建议每个分区压缩前的数据量控制在100MB 左右(第2章会详细介绍,亦可参阅分区数据库教程)。
下例中假设有1000台设备,每台设备有50个指标,每个指标的数据类型都是 float,每秒采集一次数据。假设常用的查询基于时间段和设备进行,因此按时间和设备标识这2个维度进行分区。每台设备每天产生的数据约16MB,因此数据库可按2个维度分区,第一个维度按天(datetime 列)值分区,第二个维度按设备编号(machineId列)范围分区,10个设备一个区,每个分区数据量约160MB。建库建表代码如下:
db1 = database("",VALUE,2020.10.01..2020.12.30)
db2 = database("",RANGE,0..100*10+1)
db = database("dfs://iot",COMPO,[db1,db2])
m = "tag" + string(1..50)
schema = table(1:0, `machineId`datetime join m, [INT,DATETIME] join take(FLOAT,50) )
db.createPartitionedTable(schema,"machines",`datetime`machineId)上述代码新建分布式数据库 dfs://iot 与该库中的分布式数据表 machines。代码中,schema 是一个内存表,作为分区表的模板,指定了分区表的结构,包括设备编号列machineNo、时间列datetime以及50个指标列 tag1~tag50,以及相应的数据类型。schema 表的第一个参数1:0分别为capacity:size,其中 capacity 表示建表时系统为该表分配的内存(以行数为单位),size 表示该表新建时的行数。size=0 表示创建一个空表,仅仅作为分区表的模板使用。上述 schema 因为列名有规律、类型一致,所以用函数 join 进行了简化,实际等价于下面2种写法,可根据列名、类型情况进行仿写:
schema = table(1:0, `machineId`datetime`tag1`tag2`tag3`tag4`tag5`tag6`tag7`tag8`tag9`tag10`tag11`tag12`tag13`tag14`tag15`tag16`tag17`tag18`tag19`tag20`tag21`tag22`tag23`tag24`tag25`tag26`tag27`tag28`tag29`tag30`tag31`tag32`tag33`tag34`tag35`tag36`tag37`tag38`tag39`tag40`tag41`tag42`tag43`tag44`tag45`tag46`tag47`tag48`tag49`tag50,
[INT,DATETIME,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT,FLOAT] )
schema=table(
array(INT,0) as machineId,
array(DATETIME,0) as datetime,
array(FLOAT,0) as tag1,
array(FLOAT,0) as tag2,
array(FLOAT,0) as tag3,
array(FLOAT,0) as tag4,
array(FLOAT,0) as tag5,
array(FLOAT,0) as tag6,
array(FLOAT,0) as tag7,
array(FLOAT,0) as tag8,
array(FLOAT,0) as tag9,
array(FLOAT,0) as tag10,
array(FLOAT,0) as tag11,
array(FLOAT,0) as tag12,
array(FLOAT,0) as tag13,
array(FLOAT,0) as tag14,
array(FLOAT,0) as tag15,
array(FLOAT,0) as tag16,
array(FLOAT,0) as tag17,
array(FLOAT,0) as tag18,
array(FLOAT,0) as tag19,
array(FLOAT,0) as tag20,
array(FLOAT,0) as tag21,
array(FLOAT,0) as tag22,
array(FLOAT,0) as tag23,
array(FLOAT,0) as tag24,
array(FLOAT,0) as tag25,
array(FLOAT,0) as tag26,
array(FLOAT,0) as tag27,
array(FLOAT,0) as tag28,
array(FLOAT,0) as tag29,
array(FLOAT,0) as tag30,
array(FLOAT,0) as tag31,
array(FLOAT,0) as tag32,
array(FLOAT,0) as tag33,
array(FLOAT,0) as tag34,
array(FLOAT,0) as tag35,
array(FLOAT,0) as tag36,
array(FLOAT,0) as tag37,
array(FLOAT,0) as tag38,
array(FLOAT,0) as tag39,
array(FLOAT,0) as tag40,
array(FLOAT,0) as tag41,
array(FLOAT,0) as tag42,
array(FLOAT,0) as tag43,
array(FLOAT,0) as tag44,
array(FLOAT,0) as tag45,
array(FLOAT,0) as tag46,
array(FLOAT,0) as tag47,
array(FLOAT,0) as tag48,
array(FLOAT,0) as tag49,
array(FLOAT,0) as tag50
)注意:
- 创建或访问分布式数据库和表需要相应的用户权限。若不登录,会出现类似" Not granted to ..."这样的错误提示。DolphinDB 的默认管理员用户是" admin ",其默认密码是"123456"。登录命令如下:
login(`admin, `123456)登录后使用函数 changePwd 修改密码。更多权限管理细节,请参阅权限管理和安全。
- 库表创建后,可使用函数
getAllDBs()显示当前所有数据库,使用函数 schema 显示某个表或某个数据库的结构信息。例如查询上述dfs://iot数据库的设备分区信息可用如下代码:
database("dfs://iot").schema().partitionSchema[1]查询上述 machines 的表结构可用如下代码:
loadTable("dfs://iot","machines").schema().colDefs- 数据库创建后,无法通过 database 函数修改分区类型或分区方案,若要修改,请先删库再重新创建。删除数据库可使用 dropDatabase 函数。若删除某个数据表,可使用 dropTable。分布式表支持增加列,不支持修改列和删除列。增加列可使用 addColumn 函数。
有关数据库操作更详细的说明,请参阅用户手册中数据库操作。
1.4 数据库增删改查
分布式表( DFS table )不支持使用 insert into插入数据,仅支持使用 append! 或 tableInsert 函数插入数据。即使只插入一条数据,也要用表的形式来表示新增的数据。插入数据的代码示例如下,其中自定义函数 genData输入设备编号集,开始时间和每台设备记录数,返回一个包含所有模拟记录的内存表。
下面首先为1000个设备产生1小时的数据,然后举例说明如何查询、修改和删除数据库记录:
def genData(uniqueMachineId, startDateTime, freqPerMachine){
numMachines = size(uniqueMachineId)
numRecords = numMachines * freqPerMachine
machineId = array(INT, numRecords)
for(i in 0:numMachines) machineId[(i*freqPerMachine) : ((i+1)*freqPerMachine)] = uniqueMachineId[i]
t = table(machineId, take(startDateTime + (0..(freqPerMachine-1)), numRecords) as ts)
m = "tag" + string(1..50)
for (i in 0 : 50) t[m[i]] =rand(10.0, numRecords)
return t
}
machines = loadTable("dfs://iot", "machines")
t=genData(1..1000, datetime(2020.10.05), 3600)
machines.append!(t)与其他关系数据库、NoSQL、NewSQL 等数据库不同,DolphinDB 将数据库、编程语言和分布式计算三者融为一体,这种设计使得 DolphinDB 可以一站式轻量化的解决海量大数据的存储与计算。但也使得数据库和表在 DolphinDB 中只是一个普通变量,引用数据库和表时,有可能会与脚本中的其他变量名发生冲突,所以不能直接使用数据库或表名,必须使用l oadTable 函数先加载数据表。上例中,加载数据库 dfs://iot 中的数据表 machines,并把这个表对象赋值给变量 machines,之后就可以使用变量 machines 来访问这个数据表。
例1. 查询每个设备的记录总数:
select count(*) from machines group by machineId若查询到的记录数是0,请检查一下写入数据的分区字段值是否超出了分区范围。比如这个数据库日期分区是2020.10.01到2020.12.30,若数据的时间是在2020.10.01之前或2020.12.30之后,就会写入失败。为了解决这个问题,请参照用户手册中增加分区这小节的说明,在配置文件中增加配置项 newValuePartitionPolicy=add 并重启 DolphinDB 节点。
例2. 查询设备1在2020.10.05这一天的历史记录:
select * from machines where machineId=1 and datetime between 2020.10.05T00:00:00 : 2020.10.05T23:59:59查询时需要注意:系统在执行分布式查询时,首先根据 where 条件确定相关分区。大多数分布式查询只涉及分布式表的部分分区,系统不必全表扫描,从而节省大量时间。但若不能根据 where 条件做分区剪枝,就会全表扫描,影响查询性能。另外,还可能出现类似下列错误:
The number of partitions [372912] relevant to the query is too large. Please add more specific filtering conditions on partition columns in WHERE clause, or consider changing the value of the configuration parameter maxPartitionNumPerQuery.配置参数 maxPartitionNumPerQuery 指定一个查询最多可以涉及的分区数量,默认值是65535,用于防止生产环境中有人手误提交超级大的 query,影响性能。请注意,若 where 子句中的过滤条件不符合分区剪枝的规则,即使计算只使用了少数分区,在确定相关分区的过程中仍可能进行全表扫描,导致涉及的分区数量多于 maxPartitionNumPerQuery 的值。例如,若例2中的涉及日期的where 条件写为 date (datetime)=2020.10.05,即使计算实质使用的分区数量不变,但由于违反了分区剪枝的规则,会全表扫描,耗时会显著增加。有关分区剪枝的规则请参考用户手册中的查询数据一节。
可以使用以下方法解决这个问题:
- 查询中限定尽可能精确的分区范围。
- 定义数据库的分区机制时,时间戳列的定义不要包含将来的日期,可以在系统中将newValuePartitionPolicy 设置成 add。这样新的日期出现时,系统会自动更新数据库定义。
- 将 maxPartitionNumPerQuery 的值调大。不推荐这种方法,因为若不小心忘记设定查询的过滤条件或将过滤条件设置过松,则该查询会耗时过久,浪费系统资源。
例3. 查询设备1在2020.10.05这一天的最早的10条历史记录:
select top 10 * from machines where machineId=1 and datetime between 2020.10.05T00:00:00 : 2020.10.05T23:59:59DolphinDB 的分区之间存在先后顺序;分区内的数据按照写入顺序存储。查询或计算的时候,如果需要,可以用 order by、csort 等排序。下面我们选择不同分区的1号设备和11号设备,先写入2020.10.06T00:00:01各一条记录,然后写入2020.10.06T00:00:00各一条记录。再查询 top 2 记录:
t=genData([1,11],2020.10.06T00:00:01,1)
machines.append!(t)
t=genData([1,11],2020.10.06T00:00:00,1)
machines.append!(t)
select top 2 * from machines where datetime >= 2020.10.06T00:00:00查询结果如下所示。从中可见,虽然11号设备的2020.10.06T00:00:01的数据先写入,但因为它属于符合 where 条件(即2020.10.06日)第二个分区(每10台机器一个分区),所以结果中没有它,而是返回了第一个分区1号设备2020.10.06T00:00:00的数据。在第一个分区里,虽然2020.10.06T00:00:00的时间早,但它写入晚,所以先返回了2020.10.06T00:00:01的数据。如果查询top 1,则只有2020.10.06T00:00:01的数据被返回。
machineId datetime tag1 ... tag50
1 2020.10.06T00:00:01 1.7039 ... 7.8002
1 2020.10.06T00:00:00 7.9393 ... 2.7662例4. 查询每个设备的最新一条记录:
select top 1 * from machines context by machineId csort datetime desc 此查询通过 SQL 的 context by子句对表内记录进行分组,然后在组内按时间戳列进行 csort 降序排序,再与top一起使用,获取每个分组中的最新记录。
SQL 的 context by 子句为 DolphinDB 对标准 SQL 进行的拓展,在处理面板数据( panel data )时极为方便。更多细节请参考用户手册的 context by 的介绍。
若在生产环境中不断写入的情况下进行查询,为了减少查询范围,可增加一个查询条件,即限制datetime 为最近一小时,如下所示:
select top 1 * from machines where datetime >= datetimeAdd(now().datetime(),-1,`h) context by machineId csort datetime desc 若数据是按时间顺序插入,系统内存资源充足,此查询也可使用快照引擎实现。快照引擎性能更佳,但目前仅支持单节点服务模式。
另外,在测试查询性能时,DolphinDB 提供了 timer 函数用于计算查询耗费的时间。譬如在 GUI 中查询21号设备在2020.10.05的记录:
timer select * from machines where machineId=21, datetime between 2020.10.05T00:00:00 : 2020.10.05T23:59:59返回如下信息:
2020.10.28 19:34:34.181: executing code (line 2489)...
Time elapsed: 9.52 ms
2020.10.28 19:34:34.227: execution was completed [46ms]这里打印了2个时间。第一个时间9.52 ms 是 timer返回的时间,为这个查询在服务器上运行耗费的时间;第二个时间46 ms则是从脚本命令发送到接收返回结果的整个过程花费的时间,两者之差为序列化/反序列化和网络传输的耗时。类似 select * from table 即返回整个数据集到 GUI 这样的查询语句,若数据量特别大,序列化/反序列化和网络传输的耗时可能会远远超过在服务器上运行的耗时。
从1.30.6版本起,DolphinDB 支持使用 SQL update 和 delete 语句修改分布式表(包括维度表和分区表)。
例5. 更新设备1在2020.10.05T00:00:00时间点 tag1值为1.0:
update machines set tag1 = 1.0 where machineId=1 and datetime=2020.10.05T00:00:00例6. 删除设备1在2020.10.05T00:00:01时间点的记录:
delete from machines where machineId=1 and datetime=2020.10.05T00:00:011.5 Grafana 连接 DolphinDB
DolphinDB 提供了标准协议的 SQL 查询接口,与第三方分析可视化系统如Grafana、Redash和帆软等可轻松实现集成与对接。本节以 Grafana 为例,介绍DolphinDB与第三方可视化系统的连接与展示。
1.5.1 安装配置
安装 Grafana 请参考Grafana官网教程。安装后,若本机浏览器中可以打开http://localhost:3000/ ,说明 Grafana 安装成功,否则请检查3000这个端口是否被防火墙屏蔽或被其他应用占用。
DolphinDB 为了支持使用 Grafana 来实时展示时序数据,提供了 Grafana 的 dolphindb-datasource 插件,并且实现了对 Grafana 的 HTTP 数据接口,可以通过类 SQL 的查询脚本将DolphinDB 的数据表以直观的方式展示在 Grafana 的 Dashboard 上。插件的下载与安装请参阅插件教程。
1.5.2 显示数据
在 GUI 中运行以下脚本模拟1号设备每一秒产生一条数据,其中 gen 为1.4节描述的自定义函数,使用 submitJob 函数把自定义的 writeIOTData 函数提交批处理作业:
def writeIoTData(){
login("admin", "123456")
machines = loadTable("dfs://iot", "machines")
for (i in 0:86400) {
t=genData(1, now().datetime(), 1)
machines.append!(t)
sleep(1000)
}
}
submitJob("jobId1","writeDataToMachine1",writeIoTData)在 Grafana 的 Home 界面点击" Create Dashboard ",然后点击" Add new panel ",在如下图所示界面的 Query options 中选择 DolphinDB 数据源后,数据源下方会出现一个用于输入脚本的文本输入框,输入以下查询语句以读取1号设备前5分钟的tag1数据:
login('admin', '123456'); select gmtime(timestamp(datetime)) as time_sec, tag1 from loadTable('dfs://iot', 'machines') where machineId=1 and datetime> now().datetime()-5*60在右上角设置定时刷新及数据时间段的长度,就可以看到实时的数据变化走势图。
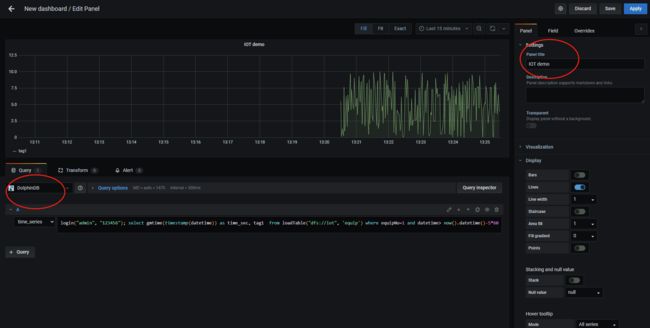
上图若不能正常显示,请检查:
- 在 GUI 中运行函数 getRecentJobs,查看作业运行是否有错,若有错,返回结果中 errorMsg会显示错误信息。取消作业用 cancelJob。
- Grafana 默认返回 timer_series 格式,SQL 中返回的第一个字段必须是 timestamp 类型。
- DFS 数据库需要登录后才能访问,所以 select 语句前需要先登录。
- 检查查询语句中是否含有双引号,若有双引号,改其为单引号。
- 若上述方法还不能解决问题,建议用 Goole Chrome 浏览器运行 Grafana,然后按F12调试,可以查看一下网络交互信息是否提示了异常。
1.6 DolphinDB 与其他数据库异同点小结
物联网历史数据有可能达到几百 TB 甚至 PB 级别。传统的关系型数据库(如 Oracle,SQL Server,MySQL 等)受到行式存储和数据索引的限制,处理如此量级数据的性能非常低下,即使分库分表,效果也不理想。DolphinDB 采用了分区机制,可以轻松应对 PB 级别的海量数据。DolphinDB 通过数据分区而不是索引的方式来快速定位数据,适合海量数据的存储,检索和计算。在数据量不是非常大时,创建索引可以显著提高系统的性能,但在海量数据场景下,随着数据量的不断增加,索引会不断膨胀(需要占用的内存甚至可能超过了服务器的内存),反而导致系统性能下降。
DolphinDB 将分布式数据库、分布式计算和编程语言从底层进行一体化设计,这种设计使得DolphinDB 可以一站式轻量化的解决海量大数据的存储与计算。但是,引用数据库和表时,因为可能会与脚本中的变量名发生冲突,所以不能直接使用数据库或表名,必须使用 loadTable 函数先加载数据表。
与关系型数据库不同,DolphinDB 分布式表不支持使用 insert into 插入数据,仅支持使用append! 或 tableInsert 函数以表的形式插入数据。DolphinDB 支持事务,客户端每次写入都是一个事务但是用户层面不提供事务操作,不需要用户像关系数据库一样显式地开始事务、提交事务等。
相比其他时序数据库,DolphinDB 是一个非常轻量级的系统,用 GNU C++ 开发,核心程序仅20余兆字节,无任何依赖,开箱即用。DolphinDB 已适配国产的 X86、ARM、MIPS(龙芯)等 CPU,可以运行在 Linux 和 Windows 操作系统上。
下一期有关物联网入门系列的介绍内容为——分布式数据库设计和测试,敬请期待。