hive、sparksql行转列 列转行详解
行转列:
行转列的需求一般都是对某个分组键做聚合,并且造出新的列
如下面一个简单案例:
转换前:
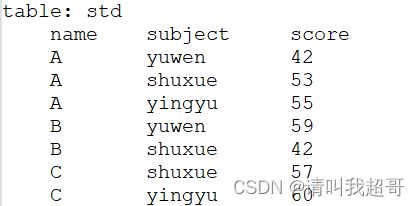
转换后:

答案如下:
insert overwrite table std2
select
name,
if(all_subject like '%yuwen%' ,split(split(all_subject,'yuwen_')[1],',')[0],'') as yuwen,
if(all_subject like '%shuxue%' ,split(split(all_subject,'shuxue_')[1],',')[0],'') as shuxue,
if(all_subject like '%yingyu%' ,split(split(all_subject,'yingyu_')[1],',')[0],'') as yingyu
from (
select
name,concat_ws(',',collect_list(tmp)) as all_subject
from (
select
name,concat(subject,'_',score) tmp
from std)t
group by name
)t2
思路解析:
核心就是根据分组键分组并使用collect_list函数把数据归到一起,实际上这里就已经完成了行转列了,只是此时的数据结构还不符合期望的结果,因此后面再用split函数处理字符串,达到最终的期望结果。使用collect_list/collect_set函数后面再进行字符串的处理应该可以实现大部分的行转列,可以仔细理解下,行转列此后就不再话下了。
列转行:
列转行就接着上面的案例把std2反转为std
在解决列转行之前需要先了解一下udtf和later view
UDTF:
udtf是一种输入一行输出多行的函数,系统自带的就有UDTF函数,天生就用来做列转行
eg:explode函数,explode是一个系统自带的UDTF函数,输入参数需要是array,单独使用时会把一条array记录中的所有值拆分成多行,但单独使用时无法带出其他的字段,因此在实际运用中一般不会单独使用,不可与group by同时使用。
LATER VIEW :
表示侧视图,不可单独使用,经过后面和UDTF函数配合使用,会将UTDTF函数分割出的列表虚拟成一张表并和前面的source_table关联起来,从而可以把其他字段带出来,如explode函数;使用形式如下:
lateral view udtf(expression) tableAlias as columnAlias
eg:
from table_A later view explode(array_column) virtual_table_name as new_column_name
仔细理解了上面的内容之后列转行也很简单,上面的案例中把std2反转为std的sql如下:
select
name,subject,new_score as score
from (
select
name,
case when score like '%yuwen%' then 'yuwen'
when score like '%shuxue%' then 'shuxue'
when score like '%yingyu%' then 'yingyu'
else 'others' end as subject,
split(score,'_')[1] as new_score
from (
select
name,
concat('yuwen','_',yuwen,',','shuxue','_',shuxue,',','yingyu','_',yingyu) as score_info
from std2
) t later view explode (split(score_info,',')) t as score
) t2 where new_score is not null and new_score!='';
sql实现的方式有很多种,我只是写出了一种让大家参考,希望能对大家有所帮助