《ImageNet Classification with Deep Convolutional Neural Networks》阅读笔记
论文标题
《ImageNet Classification with Deep Convolutional Neural Networks》
- ImageNet :经典的划时代的数据集
- Deep Convolutional:深度卷积在当时还处于比较少提及的地位,当时主导的是传统机器学习算法
作者
一作 Alex Krizhevsky 和二作 Ilya Sutskever 都是 2018 年因作为 “深度学习领域的三大先驱之一” 而获得图灵奖的 Geoffrey E. Hinton 辛老爷子的学生。值得一提的是,二作 Ilya Sutskever 苏哥如今正带着 OpenAI 大杀四方,这位大佬又一次站在了人工智能发展史的转折点上。
初读
摘要
-
秀肌肉:
展示了 AlexNet 空前的低错误率,庞大的参数量和神经元数。
-
介绍网络结构:
五个卷积层组成,其中一些层后面是最大池化层,还有三个完全连接层,最后是 1000 路 softmax。
-
引入新的方法:
丢弃法。
结论
- 本文使用的是 Discussion 讨论,而不是 Conclusion 结论。
- 再次秀一下空前的精度,并强调了深度的重要性。
- 没有使用无监督学习以简化实验。
- 提出展望:想对视频序列进行深度学习。
再读
Section 1 Introduction
-
第一段主题:数据集
小图像数据集有很大的缺陷,为了应对现实环境中对象相当大的可变性,必须引入更大的数据集。小图像数据集的缺点虽早已广为人知 [TODO],但直到最近(当年的最近)才有诸如 ImageNet 之类的大数据集出现。
-
第二段主题:卷积,卷的好
繁杂的图像识别需要强大的学习能力,强大的学习能力优需要强大的模型,强大的模型意味着超高的复杂度。而卷积网络使用的参数少的多,训练更容易。
-
第三段主题:算力
卷积虽然大大降低了训练难度,但是大规模的训练依然很难。作者将 2D 卷积结合GPU进行了优化,进行了模型并行训练。
-
第四段主题:再次秀肌肉
- 迄今为止最大的卷积神经网络
- 使用双GPU进行模型并行训练
- 引入新方法来防止过拟合
- 强调深度很重要
-
第五段主题:训练难度
总结了网络大小的两大制约因素:显存和时间。作者的网络采用了两块 3GB 显存的 GTX 580,训练周期在五到六天。
Section 2 The Dataset
-
ImageNet 详细介绍:
由超 1500 万张带标签的高分辨率图像组成,包含大约 22000 个类别。从 2010 年开始的挑战赛使用的 ILSVRC 数据集是 ImageNet 的子集,由 ImageNet 中的 120 万张训练图像、5 万张验证图像和 15 万张测试图像组成,包含约 1000 个分类的各约 1000 张图片。
-
测试集的问题:
这段没看明白,作者说 ILSVRC-2010 是唯一可用的测试集,但是也参加了 ILSVRC-2012。待会再细看一下ILSVRC 到底是怎么个事儿 [TODO]。
-
图像预处理:
本文模型所需要的图像预处理极少,仅仅按照 256 × 256 256\times 256 256×256 的尺寸裁剪即可。经沐神提点,此处也是作者没有意识到,但是实际上很厉害的特点之一,此前需要对图像进行人工特征提取之类的复杂的预处理。
Section 3 The Architecture
-
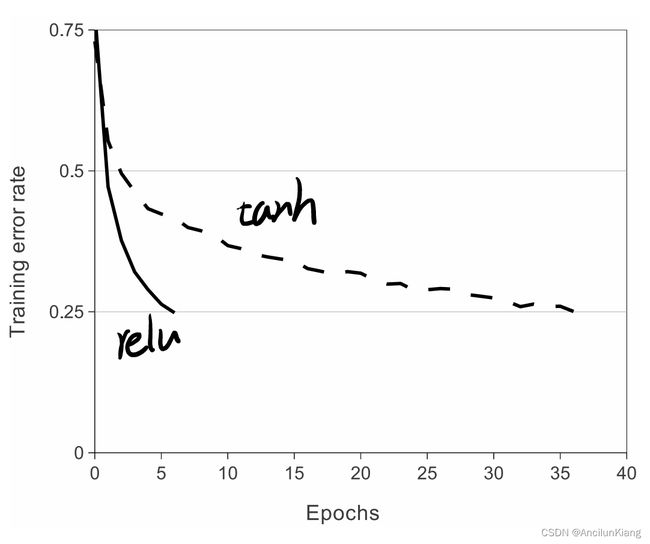
使用 ReLU:更好
使用 ReLu 会比使用 tanh 训练快得多,甚至使用 ∣ t a n h ∣ |tanh| ∣tanh∣ 也会好很多。但是并没有详细解释原因,仅给出了参考文献。此外,也不太理解这里 saturating 和 non-saturating 是啥意思 [TODO]。
-
多 GPU:复杂
这里介绍了使用双 GPU 进行训练。而且还不是类似分布式计算的东西,而是类似模型分布训练,两个 GPU 上各有一个卷积核,在第3、5层进行通信。
沐神提点,虽然这里的 GPU 并行运算占了作者很大工作量,但实际上这个方案通用性比较低,没有广泛应用。这部分属于复杂的工程细节,不必详看。
-
局部响应规范化:
使用了一个看起来很复杂的规范化公式,也不知道为啥有用,反正有用,用就完了。沐神提点,此处的规范化方法也没有得到广泛的应用,一是规范化似乎影响不那么大,二是后面又更好的规范化方法。
-
重叠池化:
据作者描述,重叠池化提高了百分之零点几的精度,但是会使拟合变得稍微困难一点。没听说过重叠池化这个东西,一会儿再看看 [TODO]。
-
整体结构:
和之前在书本上看的简化模型差不多,在此不赘述。原文模型更多是为了双GPU实现模型分布训练而做了特殊设计,当前的GPU性能已无此类烦恼。

Section 4 Reducing Overfitting
这一部分着重讲的是对严重过拟合的处理。
-
数据扩充:
主要使用了一下两种数据增强方案:
-
一是生成图像平移和水平反射:
具体操作是在 256 × 256 256\times 256 256×256 的图像上随机提取 224 × 224 224\times 224 224×224 的子图像,以达到扩充数据的目的。
-
二是改变训练图像中的 RGB 通道的强度:
具体操作是对训练集中对 RGB 像素值执行 PCA 来取得主要特征,然后加 σ = 0.1 \sigma=0.1 σ=0.1 的高斯分布的噪声。
-
-
Dropout 丢弃法:
这里使用了概率为 0.5 的 dropout,详细操作不在此赘述。
Section 5 Details of learning
-
权重衰减:使用了 0.0005 的权重衰减。
-
手动调节学习率:
在训练过程中,每次遇到拟合不动的时候,就把学习率缩小十倍 [TODO]。作者将学习率初始化为 0.01 并在训练过程中手动调节了三次。最终花了五到六天,训练了 90 轮。
Section 6 Results
-
精度:
- Top-1 错误率做到了 37.5%,相较于 Sparse coding 稀疏编码的 47.1% 和 SIFT + FVs 尺度不变特征变换的 45.7% 有较大提升。
- Top-5 错误率做到了 17.0%,相较于 Sparse coding 稀疏编码的 28.2% 和 SIFT + FVs 尺度不变特征变换的 25.7% 有较大提升。
-
定性评估:
-
由于受限连接,两个 GPU 上的两个网络各有不同侧重点,比如,GPU1 上的卷积核很大程度上与颜色无关。

-
通过观察,发现排名前五的预测标签都是合理的。并且偏离中心的对象也能够识别。
<

-
比较有意思的是,作者把网络最后一层那个 4096 维的特征向量摘了出来,把具有最小欧氏距离的特征向量对应的图像放在一起,可以看到这些图像都是一类的。可以说这个 4096 维的特征向量就是模型的眼看到的图像。

-
三读
TODO List
- 小图像数据集和大图像数据集
- ILSVRC-2010 和 ILSVRC-2012
- saturating 和 non-saturating nonlinearities
- ReLU 和 tanh
- 重叠池化
- 手动调节学习率
使用大图像数据集的必要性
这各问题读了参考文献 [21] N. Pinto, D.D. Cox, and J.J. DiCarlo. Why is real-world visual object recognition hard? PLoS computational biology, 4(1):e27, 2008. 不过这个参考文献又长又数学,实在读不懂,就用文心一言摘要了一下。一下为文心一言的辅助阅读结果。
这篇文章介绍了美国 McGovern 研究所和麻省理工学院等机构开发的自然图像数据库及其类别标签,以及不同识别系统的表现。重点来看图像背景的变化是影响识别系统性能的一个重要因素。例如,当图像中存在噪声、光照变化、或者物体姿态和大小的变化时,识别系统的性能可能会受到影响。这些背景变化可以导致图像的外观和特征发生改变,从而增加识别系统的难度。如果你正在构建一个识别系统,你会希望这个系统能在各种不同的背景上都能正常工作。然而,如果这些背景与所训练的图像数据集中的背景非常不同,那么你的识别系统可能就会遇到困难。为了解决这个问题,你可能需要收集更多具有不同背景的图像,并将它们添加到你的训练数据集中。这将有助于提高你的识别系统在各种不同背景上的性能。
ILSVRC-2010 和 ILSVRC-2012
因为只有 ILSVRC-2010 公布了测试集,从而可以自己验证。后续的 ILSVRC 2012-2017 都是需要像 Kaggle 竞赛那样上传到评估服务器。
top-5 评估法:对于每张图给出5次猜测结果,只要5次中有一次命中真实类别就算正确分类。
saturating 和 non-saturating nonlinearities
关于饱和非线性和不饱和非线性的理解参考 StackExchange 上的这个问答 和 Quora 上这个回答。
这里的饱和和非饱和指的是定义域到值域是否会压缩。比如 ReLU 的正半轴上当 x 趋于无穷时函数值也趋于无穷,所以可以说这段是非饱和的;而 sigmoid 会把输出压缩到 [0,1],所以就可以说是饱和的。
ReLU 和 tanh
关于 ReLU 为什么好,参考了本文的参考文献 [20] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th International Conference on Machine Learning, 2010.
ReLU 在输入小于0时输出0,这有效地避免了梯度消失的问题。也就是说,当反向传播时,如果上一个层的输出小于0,ReLU将不会更新其权重。这可以防止梯度消失的问题,也就是随着反向传播层数的增加,梯度会越来越小,最终接近于0。这有助于网络在训练过程中不会陷入局部最优解。
据沐神说,实际上后来人们发现激活函数的影响很小,所以这里其实也不必过多考虑。
重叠池化
是我理解复杂了,其实就是步长小于池化层尺寸的池化,也就是咱日常使用的池化,不重叠的池化反倒少见了。
手动调节学习率
现在的学习率调节会使用一些更柔和的手段而不是直接十倍十倍的降,比如会先线性增长再依余弦函数下降。大略画一下是这样:
个人感想
就如沐神所言,这篇论文读起来非常像一个技术说明书,阐述了自己怎么做的,而没有列举目前的别人的方案,有些自说自话的感觉。不过 AlexNet 的设计过于经典,沐神嘴里“不那么好”的论文也是不折不扣的奠基之作。
作为经典论文,AlexNet 有其经典之处,但也有过时之处,甚至有很多回旋镖。比如当年的潮流是无监督学习,AlexNet 带火了有监督学习,到了如今,随着 BERT 和 GAN 的兴起,有掀起了无监督学习的潮流;再比如其中的多GPU并行处理,由于GPU性能的飞速增长而被认为很复杂没怎么用,随着现在大模型的出现又兴起了多GPU甚至GPU集群。