Go-Python-Java-C-LeetCode高分解法-第九周合集
前言
本题解Go语言部分基于 LeetCode-Go
其他部分基于本人实践学习
个人题解GitHub连接:LeetCode-Go-Python-Java-C
欢迎订阅CSDN专栏,每日一题,和博主一起进步
LeetCode专栏
我搜集到了50道精选题,适合速成概览大部分常用算法
突破算法迷宫:精选50道-算法刷题指南
文章目录
- 前言
- [57. Insert Interval](https://leetcode.com/problems/insert-interval/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [58. Length of Last Word](https://leetcode.com/problems/length-of-last-word/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Python
- Java
- Cpp
- [59. Spiral Matrix II](https://leetcode.com/problems/spiral-matrix-ii/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [60. Permutation Sequence](https://leetcode.com/problems/permutation-sequence/)
-
- 题目
- 题目大意
- 解题思路
- Go
- Python
- Java
- Cpp
- [61. Rotate List](https://leetcode.com/problems/rotate-list/description/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [62. Unique Paths](https://leetcode.com/problems/unique-paths/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
- [63. Unique Paths II](https://leetcode.com/problems/unique-paths-ii/)
-
- 题目
- 题目大意
- 解题思路
- 代码
- Go
- Python
- Java
- Cpp
57. Insert Interval
题目
Given a set of non-overlapping intervals, insert a new interval into the intervals (merge if necessary).
You may assume that the intervals were initially sorted according to their start times.
Example 1:
Input: intervals = [[1,3],[6,9]], newInterval = [2,5]
Output: [[1,5],[6,9]]
Example 2:
Input: intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
Output: [[1,2],[3,10],[12,16]]
Explanation: Because the new interval [4,8] overlaps with [3,5],[6,7],[8,10].
题目大意
这一题是第 56 题的加强版。给出多个没有重叠的区间,然后再给一个区间,要求把如果有重叠的区间进行合并。
解题思路
可以分 3 段处理,先添加原来的区间,即在给的 newInterval 之前的区间。然后添加 newInterval ,注意这里可能需要合并多个区间。最后把原来剩下的部分添加到最终结果中即可。
以下是每个版本的解题思路:
Go 版本解题思路:
- 初始化
left和right分别为newInterval的起始和结束值,以及一个merged标志用于跟踪是否已经合并了newInterval。 - 使用
for循环遍历原始区间intervals。 - 对于每个区间,检查三种情况:
- 如果该区间在
newInterval的右侧且无交集,则将newInterval添加到结果中,并将merged设置为true。然后将当前区间添加到结果中。 - 如果该区间在
newInterval的左侧且无交集,则直接将当前区间添加到结果中。 - 如果存在交集,更新
left和right以合并区间。
- 如果该区间在
- 循环结束后,如果
newInterval没有与任何区间合并(!merged),则将其添加到结果中。 - 返回最终结果。
Python 版本解题思路:
- 初始化一个空列表
res用于存储合并后的区间。 - 使用
for循环遍历原始区间列表intervals。 - 对于每个区间,检查三种情况:
- 如果当前区间的结束位置小于
newInterval的起始位置,直接将当前区间添加到res。 - 如果当前区间的起始位置大于
newInterval的结束位置,将newInterval和后面的区间都添加到res。 - 否则,合并当前区间和
newInterval,更新newInterval的起始和结束位置。
- 如果当前区间的结束位置小于
- 将
newInterval添加到res。 - 返回最终结果
res。
Java 版本解题思路:
- 初始化一个
ArrayList类型的结果列表ret。 - 使用
for循环遍历原始区间数组intervals。 - 处理三种情况:
- 左侧区间:如果当前区间的结束位置小于
newInterval的起始位置,将当前区间添加到ret。 - 区间重叠:如果当前区间与
newInterval有重叠,合并它们并更新newInterval的起始和结束值。 - 右侧区间:如果当前区间的起始位置大于
newInterval的结束位置,将当前区间添加到ret。
- 左侧区间:如果当前区间的结束位置小于
- 将
newInterval添加到ret。 - 将
ret转换为数组形式并返回最终结果。
C++ 版本解题思路:
- 初始化一个
vector类型的结果向量result。 - 使用
for循环遍历原始区间向量intervals。 - 处理三种情况:
- 左侧区间:如果当前区间的结束位置小于
newInterval的起始位置,将当前区间添加到result。 - 区间重叠:如果当前区间与
newInterval有重叠,合并它们并更新newInterval的起始和结束值。 - 右侧区间:如果当前区间的起始位置大于
newInterval的结束位置,将当前区间添加到result。
- 左侧区间:如果当前区间的结束位置小于
- 将
newInterval添加到result。 - 返回最终结果
result。
这些解题思路的核心思想是遍历原始区间,处理不同情况下的区间合并和添加操作,最终得到合并后的结果。要解决这个问题,需要理解如何比较区间的位置关系、如何合并区间以及如何使用循环和条件语句来控制程序逻辑。
代码
Go
func insert(intervals [][]int, newInterval []int) (ans [][]int) {
left, right := newInterval[0], newInterval[1]
merged := false
for _, interval := range intervals {
if interval[0] > right {
// 在插入区间的右侧且无交集
if !merged {
ans = append(ans, []int{left, right})
merged = true
}
ans = append(ans, interval)
} else if interval[1] < left {
// 在插入区间的左侧且无交集
ans = append(ans, interval)
} else {
// 与插入区间有交集,计算它们的并集
left = min(left, interval[0])
right = max(right, interval[1])
}
}
if !merged {
ans = append(ans, []int{left, right})
}
return
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
Python
class Solution:
def insert(self, intervals, newInterval):
# 初始化结果列表
res = []
# 遍历区间列表
for interval in intervals:
# 如果当前区间的结束位置小于新区间的起始位置,直接将当前区间加入结果
if interval[1] < newInterval[0]:
res.append(interval)
# 如果当前区间的起始位置大于新区间的结束位置,将新区间和后面的区间都加入结果
elif interval[0] > newInterval[1]:
res.append(newInterval)
newInterval = interval
else:
# 否则,合并当前区间和新区间,更新新区间的起始和结束位置
newInterval[0] = min(newInterval[0], interval[0])
newInterval[1] = max(newInterval[1], interval[1])
# 将新区间加入结果
res.append(newInterval)
return res
Java
class Solution {
public int[][] insert(int[][] intervals, int[] newInterval) {
List ret = new ArrayList<>();
int i = 0;
int n = intervals.length;
// 左侧区间:将结束位置小于新区间的起始位置的区间加入结果
while (i < n && intervals[i][1] < newInterval[0]) {
ret.add(intervals[i]);
i++;
}
// 区间重叠:合并重叠的区间,更新新区间的起始和结束值
while (i < n && intervals[i][0] <= newInterval[1] && intervals[i][1] >= newInterval[0]) {
newInterval[0] = Math.min(intervals[i][0], newInterval[0]);
newInterval[1] = Math.max(newInterval[1], intervals[i][1]);
i++;
}
ret.add(newInterval);
// 右侧区间:将起始位置大于新区间的结束位置的区间加入结果
while (i < n && intervals[i][0] > newInterval[1]) {
ret.add(intervals[i]);
i++;
}
// 将结果转换为数组形式
int[][] ans = new int[ret.size()][];
for (int k = 0; k < ret.size(); ++k) {
ans[k] = ret.get(k);
}
return ans;
}
}
Cpp
class Solution {
public:
vector> insert(vector>& intervals, vector& newInterval) {
vector> result;
int n = intervals.size();
int i = 0;
// 左侧区间:将结束位置小于新区间的起始位置的区间加入结果
while (i < n && intervals[i][1] < newInterval[0]) {
result.push_back(intervals[i]);
i++;
}
// 区间重叠:合并重叠的区间,更新新区间的起始和结束值
while (i < n && intervals[i][0] <= newInterval[1] && intervals[i][1] >= newInterval[0]) {
newInterval[0] = min(intervals[i][0], newInterval[0]);
newInterval[1] = max(intervals[i][1], newInterval[1]);
i++;
}
result.push_back(newInterval);
// 右侧区间:将起始位置大于新区间的结束位置的区间加入结果
while (i < n) {
result.push_back(intervals[i]);
i++;
}
return result;
}
};
以下是每个版本所需要掌握的详细基础知识:
Go 版本:
- Slice(切片):Go 中的切片是动态数组,这个版本中使用切片来处理 intervals 和结果集。
- For 循环:了解 Go 中的
for循环语法,它用于遍历切片和执行循环操作。 - 条件语句:理解
if和else条件语句,这里使用条件语句来判断区间的位置关系和重叠。 - 函数定义和调用:了解如何定义和调用函数,这里有两个自定义函数
min和max,用于求最小值和最大值。 - 切片操作:了解如何使用切片来追加元素,这里使用
append函数将元素添加到结果集中。
Python 版本:
- 列表(List):Python 中的列表是动态数组,这个版本中使用列表来处理 intervals 和结果集。
- For 循环:了解 Python 中的
for循环语法,它用于遍历列表和执行循环操作。 - 条件语句:理解
if和else条件语句,这里使用条件语句来判断区间的位置关系和重叠。 - 类和方法:这个版本使用一个类
Solution,需要了解如何定义类和类方法,并且如何调用类方法。
Java 版本:
- 数组:Java 中的数组是固定大小的数据结构,这个版本中使用二维数组来处理 intervals 和结果集。
- For 循环:了解 Java 中的
for循环语法,它用于遍历数组和执行循环操作。 - 条件语句:理解
if和else条件语句,这里使用条件语句来判断区间的位置关系和重叠。 - 列表(List):Java 中有
List接口和ArrayList类,但这里没有使用它们。你需要了解如何使用数组来存储和操作数据。 - 类和方法:这个版本使用一个类
Solution,需要了解如何定义类和类方法,并且如何调用类方法。
C++ 版本:
- 数组:C++ 中的数组是固定大小的数据结构,这个版本中使用二维数组来处理 intervals 和结果集。
- For 循环:了解 C++ 中的
for循环语法,它用于遍历数组和执行循环操作。 - 条件语句:理解
if和else条件语句,这里使用条件语句来判断区间的位置关系和重叠。 - 向量(Vector):C++ 中的
vector是动态数组,但这里没有使用它。你需要了解如何使用数组来存储和操作数据。 - 类和函数:这个版本没有使用类,但使用了函数。需要了解如何定义函数和如何调用函数。
总体来说,无论你选择哪个版本,你需要了解数组或列表的基本操作、循环和条件语句的使用,以及如何定义和调用函数或方法。此外,不同编程语言有不同的语法和特性,所以你需要熟悉所选语言的语法和特点来理解和修改这些代码。
58. Length of Last Word
题目
Given a string s consisting of some words separated by some number of spaces, return the length of the last word in the string.
A word is a maximal substring consisting of non-space characters only.
Example 1:
Input: s = "Hello World"
Output: 5
Explanation: The last word is "World" with length 5.
Example 2:
Input: s = " fly me to the moon "
Output: 4
Explanation: The last word is "moon" with length 4.
Example 3:
Input: s = "luffy is still joyboy"
Output: 6
Explanation: The last word is "joyboy" with length 6.
Constraints:
1 <= s.length <= 104sconsists of only English letters and spaces' '.- There will be at least one word in
s.
题目大意
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中最后一个单词的长度。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
解题思路
- 先从后过滤掉空格找到单词尾部,再从尾部向前遍历,找到单词头部,最后两者相减,即为单词的长度。
以下是每个版本的解题思路的详细介绍:
Go 版本解题思路:
-
首先,计算输入字符串的长度,以便后续的操作。
-
初始化一个变量
last,将其设置为字符串的最后一个字符的索引,即length - 1。 -
从字符串的末尾开始向前遍历,通过逐步减少
last的值来跳过末尾的空格字符,直到找到最后一个单词的末尾。 -
如果整个字符串都是空格,那么直接返回 0。
-
接下来,从
last开始向前遍历,找到最后一个单词的开头,通过逐步减少first的值,直到找到空格字符或达到字符串的开头。 -
最后,通过计算
last和first之间的距离,即last - first,得到最后一个单词的长度,然后返回这个长度作为结果。
Python 版本解题思路:
-
首先,计算输入字符串的长度,以便后续的操作。
-
初始化一个变量
last,将其设置为字符串的最后一个字符的索引,即length - 1。 -
从字符串的末尾开始向前遍历,通过逐步减少
last的值来跳过末尾的空格字符,直到找到最后一个单词的末尾。 -
如果整个字符串都是空格,那么直接返回 0。
-
接下来,从
last开始向前遍历,找到最后一个单词的开头,通过逐步减少first的值,直到找到空格字符或达到字符串的开头。 -
最后,通过计算
last和first之间的距离,即last - first,得到最后一个单词的长度,然后返回这个长度作为结果。
Java 版本解题思路:
-
首先,计算输入字符串的长度,以便后续的操作。
-
初始化一个变量
last,将其设置为字符串的最后一个字符的索引,即length - 1。 -
从字符串的末尾开始向前遍历,通过逐步减少
last的值来跳过末尾的空格字符,直到找到最后一个单词的末尾。 -
如果整个字符串都是空格,那么直接返回 0。
-
接下来,从
last开始向前遍历,找到最后一个单词的开头,通过逐步减少first的值,直到找到空格字符或达到字符串的开头。 -
最后,通过计算
last和first之间的距离,即last - first,得到最后一个单词的长度,然后返回这个长度作为结果。
C++ 版本解题思路:
-
首先,计算输入字符串的长度,以便后续的操作。
-
初始化一个变量
last,将其设置为字符串的最后一个字符的索引,即length - 1。 -
从字符串的末尾开始向前遍历,通过逐步减少
last的值来跳过末尾的空格字符,直到找到最后一个单词的末尾。 -
如果整个字符串都是空格,那么直接返回 0。
-
接下来,从
last开始向前遍历,找到最后一个单词的开头,通过逐步减少first的值,直到找到空格字符或达到字符串的开头。 -
最后,通过计算
last和first之间的距离,即last - first,得到最后一个单词的长度,然后返回这个长度作为结果。
总的来说,这四个版本的解题思路都是基本相同的,都是通过从字符串末尾向前遍历来寻找最后一个单词的末尾和开头,然后计算长度并返回。关键是了解如何操作字符串的长度、索引和循环,以及如何处理边界条件。
代码
func lengthOfLastWord(s string) int {
// 获取字符串的最后一个字符的索引
last := len(s) - 1
// 循环直到找到字符串末尾不是空格的字符位置
for last >= 0 && s[last] == ' ' {
last--
}
// 如果字符串全是空格,则返回0
if last < 0 {
return 0
}
// 从最后一个字符开始,向前查找第一个空格之前的字符
first := last
for first >= 0 && s[first] != ' ' {
first--
}
// 返回最后一个单词的长度(最后一个字符的位置 - 第一个字符的位置)
return last - first
}
Python
class Solution:
def lengthOfLastWord(self, s: str) -> int:
# 获取字符串的长度
length = len(s)
# 初始化最后一个字符的索引
last = length - 1
# 从字符串末尾向前查找,跳过末尾的空格字符
while last >= 0 and s[last] == ' ':
last -= 1
# 如果字符串全是空格,则返回0
if last < 0:
return 0
# 从最后一个字符开始,向前查找第一个空格之前的字符
first = last
while first >= 0 and s[first] != ' ':
first -= 1
# 返回最后一个单词的长度(最后一个字符的位置 - 第一个字符的位置)
return last - first
Java
class Solution {
public int lengthOfLastWord(String s) {
// 获取字符串的长度
int length = s.length();
// 初始化最后一个字符的索引
int last = length - 1;
// 从字符串末尾向前查找,跳过末尾的空格字符
while (last >= 0 && s.charAt(last) == ' ') {
last--;
}
// 如果字符串全是空格,则返回0
if (last < 0) {
return 0;
}
// 从最后一个字符开始,向前查找第一个空格之前的字符
int first = last;
while (first >= 0 && s.charAt(first) != ' ') {
first--;
}
// 返回最后一个单词的长度(最后一个字符的位置 - 第一个字符的位置)
return last - first;
}
}
Cpp
class Solution {
public:
int lengthOfLastWord(string s) {
// 获取字符串的长度
int length = s.length();
// 初始化最后一个字符的索引
int last = length - 1;
// 从字符串末尾向前查找,跳过末尾的空格字符
while (last >= 0 && s[last] == ' ') {
last--;
}
// 如果字符串全是空格,则返回0
if (last < 0) {
return 0;
}
// 从最后一个字符开始,向前查找第一个空格之前的字符
int first = last;
while (first >= 0 && s[first] != ' ') {
first--;
}
// 返回最后一个单词的长度(最后一个字符的位置 - 第一个字符的位置)
return last - first;
}
};
每个版本的代码所需的基础知识。
Go 版本:
-
字符串操作: 了解如何获取字符串的长度,访问字符串中的字符以及字符串切片操作。
-
循环和条件语句: 理解 Go 中的
for和if条件语句的使用,以及如何在循环中逐步处理字符串。
Python 版本:
-
字符串操作: 熟悉字符串的长度计算(使用
len()函数)和字符串索引访问。 -
字符串遍历: 了解如何使用
for循环遍历字符串中的字符。 -
条件语句: 了解如何使用
if条件语句来进行条件判断。
Java 版本:
-
字符串操作: 了解如何获取字符串的长度(使用
length()方法)以及如何使用charAt()方法访问字符串中的字符。 -
循环和条件语句: 理解 Java 中的
while循环和if条件语句的使用,以及如何在循环中逐步处理字符串。
C++ 版本:
-
字符串操作: 熟悉 C++ 中的字符串类(
std::string)的基本操作,包括获取字符串长度(使用length()方法)和访问字符串中的字符。 -
循环和条件语句: 了解 C++ 中的
while循环和if条件语句的使用,以及如何在循环中逐步处理字符串。
在这些版本的代码中,最关键的基础知识包括字符串操作、循环和条件语句的使用。同时,还需要了解如何进行字符串的索引访问和遍历,以及如何处理边界条件,例如字符串为空或仅包含空格的情况。这些是解决这个问题所需的基本概念和技能。
59. Spiral Matrix II
题目
Given a positive integer n, generate a square matrix filled with elements from 1 to n2 in spiral order.
Example:
Input: 3
Output:
[
[ 1, 2, 3 ],
[ 8, 9, 4 ],
[ 7, 6, 5 ]
]
题目大意
给定一个正整数 n,生成一个包含 1 到 n^2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
解题思路
题目要求生成一个正方形矩阵,矩阵的元素按照螺旋顺序从1到n^2依次填充。
首先,我们需要初始化一个n×n的矩阵,并定义四个方向,分别是向右、向下、向左、向上。然后按照螺旋顺序依次填充矩阵。
具体步骤如下:
定义一个n×n的矩阵,初始化所有元素为0。
定义四个方向的偏移量,分别是向右、向下、向左、向上,用来控制填充顺序。
根据题目要求,依次填充矩阵中的元素,同时更新当前位置和下一个位置的坐标,以及判断是否需要改变方向。
继续填充直到所有位置都被填充。
这些版本的解题思路共同点是通过模拟螺旋填充的过程,依次填充矩阵的每个位置。在填充的过程中,根据规定的螺旋顺序不断更新坐标,并在达到边界或已访问过的位置时改变填充方向。
代码
Go
// 定义一个名为 generateMatrix 的函数,接收一个整数参数 n,表示要生成的螺旋矩阵的大小
func generateMatrix(n int) [][]int {
// 如果 n 为 0,返回一个空的二维整数数组
if n == 0 {
return [][]int{}
}
// 如果 n 为 1,返回一个包含元素 1 的二维整数数组
if n == 1 {
return [][]int{[]int{1}}
}
// 初始化结果矩阵 res,访问标记矩阵 visit,螺旋方向 round,以及当前坐标 x 和 y
res, visit, round, x, y, spDir := make([][]int, n), make([][]int, n), 0, 0, 0, [][]int{
[]int{0, 1}, // 朝右
[]int{1, 0}, // 朝下
[]int{0, -1}, // 朝左
[]int{-1, 0}, // 朝上
}
// 初始化结果矩阵和访问标记矩阵
for i := 0; i < n; i++ {
visit[i] = make([]int, n)
res[i] = make([]int, n)
}
// 标记起始点已访问
visit[x][y] = 1
res[x][y] = 1
// 循环填充矩阵
for i := 0; i < n*n; i++ {
// 根据当前螺旋方向更新坐标
x += spDir[round%4][0]
y += spDir[round%4][1]
// 检查是否需要改变螺旋方向
if (x == 0 && y == n-1) || (x == n-1 && y == n-1) || (y == 0 && x == n-1) {
round++
}
// 如果坐标越界,返回结果矩阵
if x > n-1 || y > n-1 || x < 0 || y < 0 {
return res
}
// 如果当前坐标未被访问过,标记为已访问并填充值
if visit[x][y] == 0 {
visit[x][y] = 1
res[x][y] = i + 2
}
// 根据当前螺旋方向检查下一个位置是否已经访问,如果访问过则改变方向
switch round % 4 {
case 0:
if y+1 <= n-1 && visit[x][y+1] == 1 {
round++
continue
}
case 1:
if x+1 <= n-1 && visit[x+1][y] == 1 {
round++
continue
}
case 2:
if y-1 >= 0 && visit[x][y-1] == 1 {
round++
continue
}
case 3:
if x-1 >= 0 && visit[x-1][y] == 1 {
round++
continue
}
}
}
// 返回生成的螺旋矩阵
return res
}
Python
class Solution:
def generateMatrix(self, n: int) -> List[List[int]]:
# 初始化结果矩阵和访问标记矩阵
result = [[0] * n for _ in range(n)]
visited = [[False] * n for _ in range(n)]
# 定义方向数组,表示右、下、左、上四个方向
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
x, y, direction = 0, 0, 0
for num in range(1, n * n + 1):
result[x][y] = num
visited[x][y] = True
# 计算下一个坐标
next_x, next_y = x + directions[direction][0], y + directions[direction][1]
# 如果下一个坐标越界或已访问过,则改变方向
if next_x < 0 or next_x >= n or next_y < 0 or next_y >= n or visited[next_x][next_y]:
direction = (direction + 1) % 4
next_x, next_y = x + directions[direction][0], y + directions[direction][1]
x, y = next_x, next_y
return result
Java
class Solution {
public int[][] generateMatrix(int n) {
// 初始化结果矩阵和访问标记矩阵
int[][] result = new int[n][n];
boolean[][] visited = new boolean[n][n];
// 定义方向数组,表示右、下、左、上四个方向
int[][] directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
int x = 0, y = 0, direction = 0;
for (int num = 1; num <= n * n; num++) {
result[x][y] = num;
visited[x][y] = true;
// 计算下一个坐标
int nextX = x + directions[direction][0];
int nextY = y + directions[direction][1];
// 如果下一个坐标越界或已访问过,则改变方向
if (nextX < 0 || nextX >= n || nextY < 0 || nextY >= n || visited[nextX][nextY]) {
direction = (direction + 1) % 4;
nextX = x + directions[direction][0];
nextY = y + directions[direction][1];
}
x = nextX;
y = nextY;
}
return result;
}
}
Cpp
class Solution {
public:
vector> generateMatrix(int n) {
// 初始化结果矩阵和访问标记矩阵
vector> result(n, vector(n, 0));
vector> visited(n, vector(n, false));
// 定义方向数组,表示右、下、左、上四个方向
vector> directions = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
int x = 0, y = 0, direction = 0;
for (int num = 1; num <= n * n; num++) {
result[x][y] = num;
visited[x][y] = true;
// 计算下一个坐标
int nextX = x + directions[direction][0];
int nextY = y + directions[direction][1];
// 如果下一个坐标越界或已访问过,则改变方向
if (nextX < 0 || nextX >= n || nextY < 0 || nextY >= n || visited[nextX][nextY]) {
direction = (direction + 1) % 4;
nextX = x + directions[direction][0];
nextY = y + directions[direction][1];
}
x = nextX;
y = nextY;
}
return result;
}
};
好的,我会分别介绍每个版本的代码涉及的基础知识和算法思路。
Go 版本
基础知识:
- 函数定义与调用:
func generateMatrix(n int) [][]int定义了一个接受整数参数n的函数。 - 条件判断: 使用
if条件判断语句进行不同情况的处理。 - 数组操作: 使用二维数组表示矩阵,通过数组索引进行访问和修改。
Python 版本
基础知识:
- 类和方法: 使用
class Solution定义一个类,其中的generateMatrix方法是解决问题的主要逻辑。 - 列表(List)操作: 使用列表表示矩阵,通过索引访问和修改元素。
- 循环与条件判断: 使用
for循环和if条件判断进行逻辑控制。
Java 版本
基础知识:
- 类和方法: 使用
class Solution定义一个类,其中的generateMatrix方法是解决问题的主要逻辑。 - 二维数组操作: 使用二维数组表示矩阵,通过数组索引进行访问和修改。
- 循环与条件判断: 使用
for循环和if条件判断进行逻辑控制。
C++ 版本
基础知识:
- 类和方法: 使用
class Solution定义一个类,其中的generateMatrix方法是解决问题的主要逻辑。 - 二维数组操作: 使用二维数组表示矩阵,通过数组索引进行访问和修改。
- 循环与条件判断: 使用
for循环和if条件判断进行逻辑控制。
60. Permutation Sequence
题目
The set [1,2,3,...,*n*] contains a total of n! unique permutations.
By listing and labeling all of the permutations in order, we get the following sequence for n = 3:
"123""132""213""231""312""321"
Given n and k, return the kth permutation sequence.
Note:
- Given n will be between 1 and 9 inclusive.
- Given k will be between 1 and n! inclusive.
Example 1:
Input: n = 3, k = 3
Output: "213"
Example 2:
Input: n = 4, k = 9
Output: "2314"
题目大意
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:“123”,“132”,“213”,“231”,“312”,“321”,给定 n 和 k,返回第 k 个排列。
解题思路
下面分别介绍每个版本的解题思路:
Go 版本解题思路:
- 创建一个存储阶乘结果的数组
factorial,并初始化第一个元素为 1。 - 计算从 1 到 n 的阶乘值,并将结果存储在
factorial数组中。 - 将 k 减去 1,将其转换为从 0 开始的索引,以便在数组中访问。
- 创建一个空字符串
ans用于存储最终的排列结果。 - 创建一个
valid数组,用于标记数字是否已经被使用。初始化所有数字为可用(1)。 - 循环计算每个位置上的数字:
- 计算当前位置上的数字在当前剩余排列中的顺序(order)。
- 寻找符合顺序的数字,遍历
valid数组,减去已经使用的数字的数量,找到对应的数字。 - 将找到的数字添加到
ans中,并将该数字标记为不可用。 - 更新 k,去除已经确定的数字对应的排列数。
- 返回
ans作为最终的排列结果。
Python 版本解题思路:
- 计算阶乘数组
factorial,其中存储从 1 到 n 的阶乘值。 - 将 k 减去 1,将其转换为从 0 开始的索引。
- 创建一个空列表
ans用于存储最终的排列结果。 - 创建一个
valid列表,用于标记数字是否已经被使用。初始化所有数字为可用。 - 循环计算每个位置上的数字:
- 计算当前位置上的数字在当前剩余排列中的顺序(order)。
- 寻找符合顺序的数字,遍历
valid列表,减去已经使用的数字的数量,找到对应的数字。 - 将找到的数字添加到
ans中,并将该数字标记为不可用。 - 更新 k,去除已经确定的数字对应的排列数。
- 返回
ans作为最终的排列结果。
Java 版本解题思路:
- 计算阶乘数组
factorial,其中存储从 1 到 n 的阶乘值。 - 将 k 减去 1,将其转换为从 0 开始的索引。
- 创建一个空字符串
ans用于存储最终的排列结果。 - 创建一个整数数组
valid,用于标记数字是否已经被使用。初始化所有数字为可用。 - 循环计算每个位置上的数字:
- 计算当前位置上的数字在当前剩余排列中的顺序(order)。
- 寻找符合顺序的数字,遍历
valid数组,减去已经使用的数字的数量,找到对应的数字。 - 将找到的数字添加到
ans中,并将该数字标记为不可用。 - 更新 k,去除已经确定的数字对应的排列数。
- 返回
ans作为最终的排列结果。
C++ 版本解题思路:
- 计算阶乘数组
factorial,其中存储从 1 到 n 的阶乘值。 - 将 k 减去 1,将其转换为从 0 开始的索引。
- 创建一个空字符串
ans用于存储最终的排列结果。 - 创建一个整数数组
valid,用于标记数字是否已经被使用。初始化所有数字为可用。 - 循环计算每个位置上的数字:
- 计算当前位置上的数字在当前剩余排列中的顺序(order)。
- 寻找符合顺序的数字,遍历
valid数组,减去已经使用的数字的数量,找到对应的数字。 - 将找到的数字添加到
ans中,并将该数字标记为不可用。 - 更新 k,去除已经确定的数字对应的排列数。
- 返回
ans作为最终的排列结果。
无论使用哪种编程语言版本,核心思路都是相同的,只是具体的语法和数据结构会有所不同。通过理解这些思路,你可以实现解决这个问题的代码。## 代码
Go
func getPermutation(n int, k int) string {
// 创建一个数组 factorial 用于存储阶乘结果
factorial := make([]int, n)
factorial[0] = 1
// 计算 1 到 n 的阶乘值并存储在 factorial 数组中
for i := 1; i < n; i++ {
factorial[i] = factorial[i - 1] * i
}
k-- // 减去 1,将 k 转换为从 0 开始的索引
ans := "" // 存储最终的排列结果
valid := make([]int, n + 1) // 创建一个数组 valid 用于标记数字是否已经被使用
for i := 0; i < len(valid); i++ {
valid[i] = 1 // 初始化 valid 数组,所有数字都可用
}
// 循环计算每个位置上的数字
for i := 1; i <= n; i++ {
// 计算当前位置上的数字在当前剩余排列中的顺序
order := k / factorial[n - i] + 1
// 寻找符合顺序的数字
for j := 1; j <= n; j++ {
order -= valid[j]
if order == 0 {
ans += strconv.Itoa(j) // 将找到的数字添加到结果中
valid[j] = 0 // 将已经使用的数字标记为不可用
break
}
}
k %= factorial[n - i] // 更新 k,去除已经确定的数字对应的排列数
}
return ans // 返回最终的排列结果
}
Python
class Solution:
def getPermutation(self, n: int, k: int) -> str:
# 计算阶乘数组
factorial = [1]
for i in range(1, n):
factorial.append(factorial[-1] * i)
k -= 1 # 将 k 转换为从 0 开始的索引
ans = [] # 存储最终的排列结果
valid = [1] * (n + 1) # 创建一个数组用于标记数字是否已经被使用
# 循环计算每个位置上的数字
for i in range(1, n + 1):
# 计算当前位置上的数字在当前剩余排列中的顺序
order = k // factorial[n - i] + 1
# 寻找符合顺序的数字
for j in range(1, n + 1):
order -= valid[j]
if order == 0:
ans.append(str(j)) # 将找到的数字添加到结果中
valid[j] = 0 # 将已经使用的数字标记为不可用
break
k %= factorial[n - i] # 更新 k,去除已经确定的数字对应的排列数
return ''.join(ans) # 返回最终的排列结果
Java
class Solution {
public String getPermutation(int n, int k) {
// 计算阶乘数组
int[] factorial = new int[n];
factorial[0] = 1;
for (int i = 1; i < n; i++) {
factorial[i] = factorial[i - 1] * i;
}
k--; // 将 k 转换为从 0 开始的索引
StringBuilder ans = new StringBuilder(); // 存储最终的排列结果
int[] valid = new int[n + 1];
Arrays.fill(valid, 1); // 初始化数组,所有数字都可用
// 循环计算每个位置上的数字
for (int i = 1; i <= n; i++) {
// 计算当前位置上的数字在当前剩余排列中的顺序
int order = k / factorial[n - i] + 1;
// 寻找符合顺序的数字
for (int j = 1; j <= n; j++) {
order -= valid[j];
if (order == 0) {
ans.append(j); // 将找到的数字添加到结果中
valid[j] = 0; // 将已经使用的数字标记为不可用
break;
}
}
k %= factorial[n - i]; // 更新 k,去除已经确定的数字对应的排列数
}
return ans.toString(); // 返回最终的排列结果
}
}
Cpp
class Solution {
public:
string getPermutation(int n, int k) {
// 计算阶乘数组
vector factorial(n);
factorial[0] = 1;
for (int i = 1; i < n; i++) {
factorial[i] = factorial[i - 1] * i;
}
k--; // 将 k 转换为从 0 开始的索引
string ans; // 存储最终的排列结果
vector valid(n + 1, 1); // 创建一个数组用于标记数字是否已经被使用
// 循环计算每个位置上的数字
for (int i = 1; i <= n; i++) {
// 计算当前位置上的数字在当前剩余排列中的顺序
int order = k / factorial[n - i] + 1;
// 寻找符合顺序的数字
for (int j = 1; j <= n; j++) {
order -= valid[j];
if (order == 0) {
ans += to_string(j); // 将找到的数字添加到结果中
valid[j] = 0; // 将已经使用的数字标记为不可用
break;
}
}
k %= factorial[n - i]; // 更新 k,去除已经确定的数字对应的排列数
}
return ans; // 返回最终的排列结果
}
};
你需要具备以下基础知识:
Go 版本:
- Go 语言基础: 理解 Go 语言的基本语法,包括变量声明、循环、条件语句等。
- 切片(Slice): Go 中的切片是一种动态数组,你需要了解如何使用切片来处理和拼接字符串。
- 函数: 了解如何声明和调用函数,以及函数参数和返回值的概念。
Python 版本:
- Python 基础: 理解 Python 的基本语法,包括变量、列表、循环、条件语句等。
- 列表(List): Python 中的列表是一种常用的数据结构,你需要知道如何处理和操作列表。
- 字符串操作: 了解如何连接字符串和将整数转换为字符串。
Java 版本:
- Java 基础: 了解 Java 的基本语法,包括类、方法、变量声明和循环。
- 数组: Java 中的数组是一种常见的数据结构,你需要知道如何声明、初始化和使用数组。
- StringBuilder: 了解如何使用
StringBuilder类来高效地构建字符串。
C++ 版本:
- C++ 基础: 了解 C++ 的基本语法,包括变量、数组、循环、条件语句等。
- 字符串操作: 了解如何连接字符串和将整数转换为字符串。在 C++ 中,你可以使用字符串流(
stringstream)来转换整数为字符串。 - 类和对象: 了解如何创建类和对象,以及如何在类中定义成员函数。
不管你选择哪个编程语言版本,你需要理解问题的核心思想,即如何计算第 k 个排列。你还需要了解每个编程语言的语法和特性,以便正确实现算法。不过,问题的核心解决思路在不同版本中是相同的。
61. Rotate List
题目
Given a linked list, rotate the list to the right by k places, where k is non-negative.
Example 1:
Input: 1->2->3->4->5->NULL, k = 2
Output: 4->5->1->2->3->NULL
Explanation:
rotate 1 steps to the right: 5->1->2->3->4->NULL
rotate 2 steps to the right: 4->5->1->2->3->NULL
Example 2:
Input: 0->1->2->NULL, k = 4
Output: 2->0->1->NULL
Explanation:
rotate 1 steps to the right: 2->0->1->NULL
rotate 2 steps to the right: 1->2->0->NULL
rotate 3 steps to the right: 0->1->2->NULL
rotate 4 steps to the right: 2->0->1->NULL
题目大意
旋转链表 K 次。
解题思路
这道题需要注意的点是,K 可能很大,K = 2000000000 ,如果是循环肯定会超时。应该找出 O(n) 的复杂度的算法才行。由于是循环旋转,最终状态其实是确定的,利用链表的长度取余可以得到链表的最终旋转结果。
这道题也不能用递归,递归解法会超时。
解决这个问题的思路:
Go 版本解题思路:
-
首先,检查是否需要旋转。如果链表为空,只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
-
计算链表的长度。使用一个循环遍历链表,计算链表中的节点数量。
-
检查是否需要旋转。如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
-
找到新头节点的位置。这是通过链表长度和 k 的关系来确定的,即链表长度减去 k 对链表长度取模的结果。
-
创建一个新的头节点,并将其指向新头节点的下一个节点。然后断开循环链表,将新链表的尾部指向空。
-
返回新链表的头节点。
Python 版本解题思路:
-
同样地,首先检查是否需要旋转。如果链表为空,只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
-
计算链表的长度。使用一个循环遍历链表,计算链表中的节点数量。
-
检查是否需要旋转。如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
-
找到新头节点的位置。这是通过链表长度和 k 的关系来确定的,即链表长度减去 k 对链表长度取模的结果。
-
更新链表的头尾连接关系,形成新的旋转链表。
-
返回新链表的头节点。
Java 版本解题思路:
-
同样地,首先检查是否需要旋转。如果链表为空,只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
-
计算链表的长度。使用一个循环遍历链表,计算链表中的节点数量。
-
检查是否需要旋转。如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
-
找到新头节点的位置。这是通过链表长度和 k 的关系来确定的,即链表长度减去 k 对链表长度取模的结果。
-
更新链表的头尾连接关系,形成新的旋转链表。
-
返回新链表的头节点。
C++ 版本解题思路:
-
同样地,首先检查是否需要旋转。如果链表为空,只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
-
计算链表的长度。使用一个循环遍历链表,计算链表中的节点数量。
-
检查是否需要旋转。如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
-
找到新头节点的位置。这是通过链表长度和 k 的关系来确定的,即链表长度减去 k 对链表长度取模的结果。
-
更新链表的头尾连接关系,形成新的旋转链表。
-
返回新链表的头节点。
无论使用哪种编程语言,解决这个问题的思路都是相似的,都是基于链表的长度和旋转次数 k 来确定新头节点的位置,然后重新连接链表节点以得到旋转后的链表。
代码
Go
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
// ListNode 结构体定义了链表节点,包括一个整数值 Val 和指向下一个节点的指针 Next。
func rotateRight(head *ListNode, k int) *ListNode {
// 如果链表为空,或者只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
if head == nil || head.Next == nil || k == 0 {
return head
}
// 创建一个新的头节点 newHead,将其指向原始链表的头节点。
newHead := &ListNode{Val: 0, Next: head}
// 计算链表的长度 len。
len := 0
cur := newHead
for cur.Next != nil {
len++
cur = cur.Next
}
// 如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
if (k % len) == 0 {
return head
}
// 将链表首尾相连,形成一个循环链表。
cur.Next = head
cur = newHead
// 计算新头节点的位置,即链表长度减去 k 对链表长度取模的结果。
for i := len - k%len; i > 0; i-- {
cur = cur.Next
}
// 创建一个新的结果链表 res,将其指向新头节点的下一个节点,然后断开循环链表。
res := &ListNode{Val: 0, Next: cur.Next}
cur.Next = nil
// 返回结果链表的头节点。
return res.Next
}
Python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def rotateRight(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
# 如果链表为空,或者只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
if not head or not head.next or k == 0:
return head
# 计算链表的长度 len。
cur = head
length = 1
while cur.next:
cur = cur.next
length += 1
# 如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
if k % length == 0:
return head
# 找到新头节点的位置,即链表长度减去 k 对链表长度取模的结果。
cur = head
for _ in range(length - k % length - 1):
cur = cur.next
# 更新链表的头尾连接关系,并返回新的头节点。
new_head = cur.next
cur.next = None
cur = new_head
while cur.next:
cur = cur.next
cur.next = head
return new_head
Java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode rotateRight(ListNode head, int k) {
// 如果链表为空,或者只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
if (head == null || head.next == null || k == 0) {
return head;
}
// 计算链表的长度 len。
ListNode cur = head;
int length = 1;
while (cur.next != null) {
cur = cur.next;
length++;
}
// 如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
if (k % length == 0) {
return head;
}
// 找到新头节点的位置,即链表长度减去 k 对链表长度取模的结果。
cur = head;
for (int i = 0; i < length - k % length - 1; i++) {
cur = cur.next;
}
// 更新链表的头尾连接关系,并返回新的头节点。
ListNode newHead = cur.next;
cur.next = null;
cur = newHead;
while (cur.next != null) {
cur = cur.next;
}
cur.next = head;
return newHead;
}
}
Cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* rotateRight(ListNode* head, int k) {
// 如果链表为空,或者只包含一个节点,或者旋转次数 k 为 0,则直接返回原始链表。
if (!head || !head->next || k == 0) {
return head;
}
// 计算链表的长度 len。
ListNode* cur = head;
int length = 1;
while (cur->next) {
cur = cur->next;
length++;
}
// 如果 k 对链表长度取模等于 0,表示不需要旋转,直接返回原始链表。
if (k % length == 0) {
return head;
}
// 找到新头节点的位置,即链表长度减去 k 对链表长度取模的结果。
cur = head;
for (int i = 0; i < length - k % length - 1; i++) {
cur = cur->next;
}
// 更新链表的头尾连接关系,并返回新的头节点。
ListNode* newHead = cur->next;
cur->next = nullptr;
cur = newHead;
while (cur->next) {
cur = cur->next;
}
cur->next = head;
return newHead;
}
};
每个版本的基础知识要点:
Go 版本:
-
链表:你需要了解链表数据结构,这是问题的核心数据结构。在 Go 中,通常使用
struct来定义链表节点,包含一个整数值Val和指向下一个节点的指针Next。 -
条件语句和循环:你需要了解 Go 中的条件语句(
if语句)和循环(for语句),因为代码中有一些条件检查和循环遍历链表。 -
指针:了解如何在 Go 中使用指针是非常重要的,因为链表的节点是通过指针连接的。你需要知道如何创建和使用指针,以及如何访问指针指向的值。
Python 版本:
-
链表:与 Go 版本一样,你需要了解链表数据结构。在 Python 中,通常使用类来定义链表节点,每个节点有一个整数值和一个指向下一个节点的引用。
-
条件语句和循环:你需要了解 Python 中的条件语句(
if语句)和循环(for语句),因为代码中有一些条件检查和循环遍历链表。 -
类和对象:在 Python 中,链表节点通常是类的实例。了解如何定义类、创建对象和访问对象属性是必要的。
Java 版本:
-
链表:与 Go 和 Python 版本一样,你需要了解链表数据结构。在 Java 中,链表节点通常是一个自定义类,包含整数值和下一个节点的引用。
-
条件语句和循环:了解 Java 中的条件语句(
if语句)和循环(for循环)是必要的,因为代码中有条件检查和循环遍历链表。 -
类和对象:在 Java 中,链表节点是类的实例。你需要了解如何定义类、创建对象和访问对象的属性和方法。
C++ 版本:
-
链表:你需要了解链表数据结构,这是问题的核心数据结构。在 C++ 中,链表节点通常是一个自定义的结构体,包含整数值和下一个节点的指针。
-
条件语句和循环:了解 C++ 中的条件语句(
if语句)和循环(for循环)是必要的,因为代码中有条件检查和循环遍历链表。 -
结构体和指针:了解如何在 C++ 中定义结构体和使用指针非常重要,因为链表节点是结构体,通过指针连接。
在理解这些基础知识的基础上,你将能够理解和修改提供的代码以解决 “Rotate List” 这道题目。链表操作是这个问题的核心,所以对链表的理解至关重要。如果你对链表操作不熟悉,建议先学习链表的基本操作,然后再尝试解决这个问题。
62. Unique Paths
题目
A robot is located at the top-left corner of a m x n grid (marked ‘Start’ in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked ‘Finish’ in the diagram below).
How many possible unique paths are there?
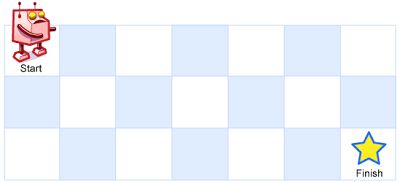
Above is a 7 x 3 grid. How many possible unique paths are there?
Note: m and n will be at most 100.
Example 1:
Input: m = 3, n = 2
Output: 3
Explanation:
From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
1. Right -> Right -> Down
2. Right -> Down -> Right
3. Down -> Right -> Right
Example 2:
Input: m = 7, n = 3
Output: 28
题目大意
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。问总共有多少条不同的路径?
解题思路
- 这是一道简单的 DP 题。输出地图上从左上角走到右下角的走法数。
- 由于机器人只能向右走和向下走,所以地图的第一行和第一列的走法数都是 1,地图中任意一点的走法数是
dp[i][j] = dp[i-1][j] + dp[i][j-1]
当然,让我为每个版本详细介绍解题思路:
Go 版本解题思路
-
创建二维切片: 首先,我们创建一个大小为
n的二维切片dp,用于存储每个位置的唯一路径数。Go 中的切片是动态数组,可以方便地动态扩展。 -
初始化第一行和第一列: 遍历二维切片,初始化第一行和第一列的路径数为 1,因为在这些位置上,机器人只有一种路径可以到达,即向右或向下移动。
-
填充二维切片: 从第二行和第二列开始,遍历每个位置
(i, j),用动态规划的思想计算出到达这个位置的唯一路径数。路径数等于上方格子的路径数加上左边格子的路径数,即dp[i][j] = dp[i-1][j] + dp[i][j-1]。 -
返回结果: 最终,右下角格子的路径数就是从左上角到右下角的唯一路径数,即
dp[n-1][m-1]。
Python 版本解题思路
-
创建二维列表: 首先,我们创建一个大小为
nxm的二维列表dp,用于存储每个位置的唯一路径数。Python 中的列表是动态数组,可以方便地动态扩展。 -
初始化第一行和第一列: 遍历二维列表,初始化第一行和第一列的路径数为 1,因为在这些位置上,机器人只有一种路径可以到达,即向右或向下移动。
-
填充二维列表: 从第二行和第二列开始,遍历每个位置
(i, j),用动态规划的思想计算出到达这个位置的唯一路径数。路径数等于上方格子的路径数加上左边格子的路径数,即dp[i][j] = dp[i-1][j] + dp[i][j-1]。 -
返回结果: 最终,右下角格子的路径数就是从左上角到右下角的唯一路径数,即
dp[n-1][m-1]。
Java 版本解题思路
-
创建二维数组: 首先,我们创建一个大小为
nxm的二维数组dp,用于存储每个位置的唯一路径数。Java 中的二维数组可以表示矩阵。 -
初始化第一行和第一列: 遍历二维数组,初始化第一行和第一列的路径数为 1,因为在这些位置上,机器人只有一种路径可以到达,即向右或向下移动。
-
填充二维数组: 从第二行和第二列开始,遍历每个位置
(i, j),用动态规划的思想计算出到达这个位置的唯一路径数。路径数等于上方格子的路径数加上左边格子的路径数,即dp[i][j] = dp[i-1][j] + dp[i][j-1]。 -
返回结果: 最终,右下角格子的路径数就是从左上角到右下角的唯一路径数,即
dp[n-1][m-1]。
C++ 版本解题思路
-
创建二维向量: 首先,我们创建一个大小为
nxm的二维向量dp,用于存储每个位置的唯一路径数。C++ 中的向量可以动态地增加或减少元素。 -
初始化第一行和第一列: 遍历二维向量,初始化第一行和第一列的路径数为 1,因为在这些位置上,机器人只有一种路径可以到达,即向右或向下移动。
-
填充二维向量: 从第二行和第二列开始,遍历每个位置
(i, j),用动态规划的思想计算出到达这个位置的唯一路径数。路径数等于上方格子的路径数加上左边格子的路径数,即dp[i][j] = dp[i-1][j] + dp[i][j-1]。 -
返回结果: 最终,右下角格子的路径数就是从左上角到右下角的唯一路径数,即
dp[n-1][m-1]。
希望这些解题思路能够帮助你更好地理解每个版本的代码!如果有任何进一步的问题,请随时向我提问。
代码
Go
func uniquePaths(m int, n int) int {
// 创建一个大小为 n 的二维切片 dp,用于存储每个位置的唯一路径数
dp := make([][]int, n)
for i := 0; i < n; i++ {
// 对每一行都创建一个大小为 m 的切片
dp[i] = make([]int, m)
}
// 遍历矩形网格的每个位置
for i := 0; i < n; i++ {
for j := 0; j < m; j++ {
// 如果当前位置是第一行或第一列,那么路径数为1,因为只能向右或向下移动一步
if i == 0 || j == 0 {
dp[i][j] = 1
continue
}
// 对于其他位置,路径数等于上方格子的路径数加上左边格子的路径数
dp[i][j] = dp[i-1][j] + dp[i][j-1]
}
}
// 返回右下角格子的路径数,这就是从左上角到右下角的唯一路径数
return dp[n-1][m-1]
}
Python
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
# 创建一个大小为 n 的二维数组 dp,用于存储每个位置的唯一路径数
dp = [[0] * m for _ in range(n)]
# 初始化第一行和第一列的路径数为1,因为只有一种方式可以到达这些位置
for i in range(n):
dp[i][0] = 1
for j in range(m):
dp[0][j] = 1
# 从第二行第二列开始填充数组,每个位置的路径数等于上方格子和左边格子的路径数之和
for i in range(1, n):
for j in range(1, m):
dp[i][j] = dp[i-1][j] + dp[i][j-1]
# 返回右下角格子的路径数,即从左上角到右下角的唯一路径数
return dp[n-1][m-1]
Java
class Solution {
public int uniquePaths(int m, int n) {
// 创建一个大小为 n 的二维数组 dp,用于存储每个位置的唯一路径数
int[][] dp = new int[n][m];
// 初始化第一行和第一列的路径数为1,因为只有一种方式可以到达这些位置
for (int i = 0; i < n; i++) {
dp[i][0] = 1;
}
for (int j = 0; j < m; j++) {
dp[0][j] = 1;
}
// 从第二行第二列开始填充数组,每个位置的路径数等于上方格子和左边格子的路径数之和
for (int i = 1; i < n; i++) {
for (int j = 1; j < m; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
// 返回右下角格子的路径数,即从左上角到右下角的唯一路径数
return dp[n-1][m-1];
}
}
Cpp
class Solution {
public:
int uniquePaths(int m, int n) {
// 创建一个大小为 n 的二维数组 dp,用于存储每个位置的唯一路径数
vector> dp(n, vector(m, 0));
// 初始化第一行和第一列的路径数为1,因为只有一种方式可以到达这些位置
for (int i = 0; i < n; i++) {
dp[i][0] = 1;
}
for (int j = 0; j < m; j++) {
dp[0][j] = 1;
}
// 从第二行第二列开始填充数组,每个位置的路径数等于上方格子和左边格子的路径数之和
for (int i = 1; i < n; i++) {
for (int j = 1; j < m; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
// 返回右下角格子的路径数,即从左上角到右下角的唯一路径数
return dp[n-1][m-1];
}
};
当然,让我们分开介绍每个版本的代码所需的基础知识。
Go 版本
-
基础语法: 了解 Go 语言的基本语法,包括变量、循环、条件语句等。了解切片(slices)的使用,它是 Go 中动态数组的数据结构。
-
二维切片(Two-dimensional slices): 学习如何创建和操作二维切片,即切片的切片,用于表示二维数据结构。
-
动态规划(Dynamic Programming): 理解动态规划的基本概念,了解如何通过填充二维数组来解决动态规划问题。在这个问题中,二维数组表示了网格中各个位置的唯一路径数。
Python 版本
-
基础语法: 了解 Python 的基本语法,包括变量、循环、条件语句等。
-
列表(Lists): 了解列表的使用,列表是 Python 中的动态数组,可以存储多个元素。
-
二维列表(Two-dimensional lists): 学习如何创建和操作二维列表,它是嵌套列表的概念,用于表示二维数据结构。
-
动态规划(Dynamic Programming): 理解动态规划的基本概念,了解如何通过填充二维数组来解决动态规划问题。在这个问题中,二维数组表示了网格中各个位置的唯一路径数。
Java 版本
-
基础语法: 了解 Java 的基本语法,包括变量、循环、条件语句等。
-
二维数组(Two-dimensional arrays): 学习如何创建和操作二维数组,它是 Java 中表示矩阵的数据结构。
-
动态规划(Dynamic Programming): 理解动态规划的基本概念,了解如何通过填充二维数组来解决动态规划问题。在这个问题中,二维数组表示了网格中各个位置的唯一路径数。
C++ 版本
-
基础语法: 了解 C++ 的基本语法,包括变量、循环、条件语句等。
-
向量(Vectors): 了解向量的使用,它是 C++ 中的动态数组,可以存储多个元素。
-
二维向量(Two-dimensional vectors): 学习如何创建和操作二维向量,它是嵌套向量的概念,用于表示二维数据结构。
-
动态规划(Dynamic Programming): 理解动态规划的基本概念,了解如何通过填充二维数组来解决动态规划问题。在这个问题中,二维数组表示了网格中各个位置的唯一路径数。
以上是每个版本代码所需的基础知识。如果你在其中的任何一个方面有疑问,都可以随时问我!
63. Unique Paths II
题目
A robot is located at the top-left corner of a m x n grid (marked ‘Start’ in the diagram below).
The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked ‘Finish’ in the diagram below).
Now consider if some obstacles are added to the grids. How many unique paths would there be?

An obstacle and empty space is marked as 1 and 0 respectively in the grid.
Note: m and n will be at most 100.
Example 1:
Input:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
Output: 2
Explanation:
There is one obstacle in the middle of the 3x3 grid above.
There are two ways to reach the bottom-right corner:
1. Right -> Right -> Down -> Down
2. Down -> Down -> Right -> Right
题目大意
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
解题思路
- 这一题是第 62 题的加强版。也是一道考察 DP 的简单题。
- 这一题比第 62 题增加的条件是地图中会出现障碍物,障碍物的处理方法是
dp[i][j]=0。 - 需要注意的一种情况是,起点就是障碍物,那么这种情况直接输出 0 。
每个版本的解题思路:
Go 版本解题思路:
-
首先,检查输入网格是否为空或者起始格子就是障碍物,如果是则返回0,因为没有有效的路径。
-
获取网格的行数和列数,分别存储在
m和n变量中。 -
创建一个二维数组
dp用于存储路径数,初始化为0,其大小为m x n。 -
设置起始格子的路径数为1,因为只有一种方式可以到达起始格子。
-
初始化第一行,如果前一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
初始化第一列,如果上一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
计算其余格子的路径数,如果当前格子不是障碍物,则路径数为上方格子和左方格子的路径数之和。
-
返回右下角格子的路径数,即从左上角到右下角的不同路径数。
Python 版本解题思路:
-
首先,检查输入网格是否为空或者起始格子就是障碍物,如果是则返回0,因为没有有效的路径。
-
获取网格的行数和列数,分别存储在
m和n变量中。 -
创建一个二维列表
dp用于存储路径数,初始化为0,其大小为m x n。 -
设置起始格子的路径数为1,因为只有一种方式可以到达起始格子。
-
初始化第一行,如果前一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
初始化第一列,如果上一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
计算其余格子的路径数,如果当前格子不是障碍物,则路径数为上方格子和左方格子的路径数之和。
-
返回右下角格子的路径数,即从左上角到右下角的不同路径数。
Java 版本解题思路:
-
首先,检查输入网格是否为空或者起始格子就是障碍物,如果是则返回0,因为没有有效的路径。
-
获取网格的行数和列数,分别存储在
m和n变量中。 -
创建一个二维数组
dp用于存储路径数,初始化为0,其大小为m x n。 -
设置起始格子的路径数为1,因为只有一种方式可以到达起始格子。
-
初始化第一行,如果前一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
初始化第一列,如果上一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
计算其余格子的路径数,如果当前格子不是障碍物,则路径数为上方格子和左方格子的路径数之和。
-
返回右下角格子的路径数,即从左上角到右下角的不同路径数。
C++ 版本解题思路:
-
首先,检查输入网格是否为空或者起始格子就是障碍物,如果是则返回0,因为没有有效的路径。
-
获取网格的行数和列数,分别存储在
m和n变量中。 -
创建一个二维向量
dp用于存储路径数,初始化为0,其大小为m x n。 -
设置起始格子的路径数为1,因为只有一种方式可以到达起始格子。
-
初始化第一行,如果前一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
初始化第一列,如果上一个格子的路径数不为0且当前格子不是障碍物,则路径数为1。
-
计算其余格子的路径数,如果当前格子不是障碍物,则路径数为上方格子和左方格子的路径数之和。
-
返回右下角格子的路径数,即从左上角到右下角的不同路径数。
这些解题思路都遵循动态规划的原理,通过填充一个二维数组来记录每个格子的路径数,最终计算出从起始点到目标点的不同路径数。
代码
Go
func uniquePathsWithObstacles(obstacleGrid [][]int) int {
// 检查输入网格是否为空或者起始格子就是障碍物,如果是则返回0
if len(obstacleGrid) == 0 || obstacleGrid[0][0] == 1 {
return 0
}
// 获取网格的行数和列数
m, n := len(obstacleGrid), len(obstacleGrid[0])
// 创建一个二维数组 dp 用于存储路径数,初始化为0
dp := make([][]int, m)
for i := 0; i < m; i++ {
dp[i] = make([]int, n)
}
// 设置起始格子的路径数为1,因为只有一种方式可以到达起始格子
dp[0][0] = 1
// 初始化第一行,如果前一个格子的路径数不为0且当前格子不是障碍物,则路径数为1
for i := 1; i < n; i++ {
if dp[0][i-1] != 0 && obstacleGrid[0][i] != 1 {
dp[0][i] = 1
}
}
// 初始化第一列,如果上一个格子的路径数不为0且当前格子不是障碍物,则路径数为1
for i := 1; i < m; i++ {
if dp[i-1][0] != 0 && obstacleGrid[i][0] != 1 {
dp[i][0] = 1
}
}
// 计算其余格子的路径数,如果当前格子不是障碍物,则路径数为上方格子和左方格子的路径数之和
for i := 1; i < m; i++ {
for j := 1; j < n; j++ {
if obstacleGrid[i][j] != 1 {
dp[i][j] = dp[i-1][j] + dp[i][j-1]
}
}
}
// 返回右下角格子的路径数,即从左上角到右下角的不同路径数
return dp[m-1][n-1]
}
Python
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
if not obstacleGrid or obstacleGrid[0][0] == 1:
return 0
m, n = len(obstacleGrid), len(obstacleGrid[0])
dp = [[0] * n for _ in range(m)]
dp[0][0] = 1
for i in range(1, n):
if dp[0][i-1] != 0 and obstacleGrid[0][i] != 1:
dp[0][i] = 1
for i in range(1, m):
if dp[i-1][0] != 0 and obstacleGrid[i][0] != 1:
dp[i][0] = 1
for i in range(1, m):
for j in range(1, n):
if obstacleGrid[i][j] != 1:
dp[i][j] = dp[i-1][j] + dp[i][j-1]
return dp[-1][-1]
Java
class Solution {
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
if (obstacleGrid == null || obstacleGrid[0][0] == 1) {
return 0;
}
int m = obstacleGrid.length;
int n = obstacleGrid[0].length;
int[][] dp = new int[m][n];
dp[0][0] = 1;
for (int i = 1; i < n; i++) {
if (dp[0][i-1] != 0 && obstacleGrid[0][i] != 1) {
dp[0][i] = 1;
}
}
for (int i = 1; i < m; i++) {
if (dp[i-1][0] != 0 && obstacleGrid[i][0] != 1) {
dp[i][0] = 1;
}
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] != 1) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
}
return dp[m-1][n-1];
}
}
Cpp
class Solution {
public:
int uniquePathsWithObstacles(vector>& obstacleGrid) {
if (obstacleGrid.empty() || obstacleGrid[0][0] == 1) {
return 0;
}
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector> dp(m, vector(n, 0));
dp[0][0] = 1;
for (int i = 1; i < n; i++) {
if (dp[0][i-1] != 0 && obstacleGrid[0][i] != 1) {
dp[0][i] = 1;
}
}
for (int i = 1; i < m; i++) {
if (dp[i-1][0] != 0 && obstacleGrid[i][0] != 1) {
dp[i][0] = 1;
}
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] != 1) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
}
return dp[m-1][n-1];
}
};
基础知识。
Go 版本:
-
基本语法和数据结构:了解 Go 的基本语法、变量声明、条件语句(if)、循环语句(for)、数组和切片的使用。
-
二维数组:理解如何声明和使用二维数组,以表示网格。
-
动态规划(DP):了解动态规划的基本概念,包括如何使用DP数组解决问题以及如何进行状态转移。
-
条件语句:理解如何使用条件语句(if)来处理特殊情况,例如检查输入是否为空或者起始点是否是障碍物。
Python 版本:
-
基本语法:了解 Python 的基本语法,包括变量声明、条件语句(if)、循环语句(for)等。
-
列表和二维列表:掌握 Python 中列表和二维列表的使用,用于表示网格和DP数组。
-
动态规划(DP):了解动态规划的概念和原理,包括如何定义状态和状态转移方程。
-
类和方法:Python 版本的解法使用了类和方法,了解如何定义类和实现方法。
Java 版本:
-
基本语法:掌握 Java 的基本语法,包括变量声明、条件语句(if)、循环语句(for)等。
-
二维数组:了解如何声明和使用二维数组,以表示网格。
-
动态规划(DP):理解动态规划的概念,包括如何定义DP数组和状态转移。
-
类和方法:Java 版本的解法使用了类和方法,了解如何定义类和实现方法。
C++ 版本:
-
基本语法:了解 C++ 的基本语法,包括变量声明、条件语句(if)、循环语句(for)等。
-
二维向量:了解如何使用 C++ 的二维向量(vector
) 来表示网格和DP数组。 -
动态规划(DP):理解动态规划的概念,包括如何定义DP数组和状态转移。
-
类和方法:C++ 版本的解法没有使用类,但了解如何定义和使用函数是有帮助的。
以上是每个版本解法所需要的基础知识,但不必担心一开始完全掌握所有这些概念。通过学习和实践,逐渐积累经验和技能,能够更好地理解和编写这些代码。如果需要深入了解任何特定概念,可以参考相关的编程教程和文档。