Linux三剑客(grep,sed,awk)详解
目录
-
- Linux运维三剑客
-
- Linux正则表达式
-
- 正则表达式是什么
- 三剑客与正则表达式的关系
- 基本正则表达式集合
- 扩展正则表达式集合
- Linux三剑客
- grep
-
- grep语法
-
- grep的常用基本案例
- grep与基本正则表达式案例
- grep与扩展正则表达式案例
- sed
-
- sed语法
-
- sed常见的案例
- sed结合正则表达式案例
- awk
-
- awk语法
- 内置变量
- awk参数
-
- 案例
- awlk自定义变量
- awk格式化
-
- printf格式化输出
-
- printf语法
- echo 和printf区别
- printf和print的区别
- printf添加格式
- printf案例
Linux运维三剑客
Linux正则表达式
正则表达式是什么
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本
简单来说就是通过一些特殊的符号,可以让用户完成查找 删除 替换。
正则表达式分两类:
- 基本正则表达式(BRE)
- BRE对应元字符有 ^ $ . [ ] *
- 扩展正则表达式(ERE)
- ERE在BRE基础上增加了 ( ) { } ? + | 等字符
三剑客与正则表达式的关系
学习三剑客首先要了解正则表达式
我们可以这样理解,三剑客就是普通的命令,有的把他们叫做工具,在我看来都一样。而正则表达式就好比一个模版。三剑客能读懂这个模版。就这么简单。注意只有三剑客才能读懂这个模版哦!
现在把他们的关系和功能都搞懂了,接下里就可以考虑怎么结合他们
基本正则表达式集合
基本正则表达式功能如下
- 匹配字符
- 匹配次数
- 位置锚定
| 符号 | 作用 |
|---|---|
| ^ | 尖角号,用于模式的最左侧,如" ^csq " 就是匹配以csq开头的行 |
| $ | 美元符,用于模式的最右侧,如“csq$”,表示以csq结尾的行 |
| ^$ | 组合符,表示空行 |
| . | 匹配任意一个且只有一个字符,不能匹配空行 |
| \ | 转移字符,让特殊含义的符号现出原形,如\ . 代表小数点. |
| * | 匹配前一个字符(连续出现) 0次或1次以上,重复0次代表空,即匹配所有内容 |
| .* | 组合符,匹配所有内容 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合符,匹配以任意多个字符结尾的内容 |
| [abc] | 匹配[ ]集合内的任意一个字符,a或b或c,可以写成[a-c] |
| [^abc] | 匹配除了^后面的任意字符,a或b或c,^表示对[abc]的取反 |
扩展正则表达式集合
扩展正则必须用 grep -E 才能生效
| 字符 | 作用 |
|---|---|
| + | 匹配前一个字符1次或多次 |
| [ : / ] + | 匹配括号内的":"或者“/”字符1次或多次 |
| ? | 匹配前一个字符0次或1次 |
| | | 表示或者,同时过滤多个字符 |
| () | 分组过滤,被括起来的内容表示一个整体 |
| a{n,m} | 匹配前一个字符最少n次,最多M次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{n} | 匹配前一个字符正好n次 |
| a{,m} | 匹配前一个字符最多m次 |
Linux三剑客
- grep:擅长查找功能
- sed:擅长取行和替换
- awk:擅长取列
grep
全拼:Global Regular Expression Print
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行
grep语法
用法: grep [参数选项]... PATTERN [FILE]...
在每个 FILE 或是标准输入中查找 PATTERN。
默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。
例如: grep -i 'hello world' menu.h main.c
| 参数选项 | 解释说明 |
|---|---|
| -v | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配的行数 |
| -E | 使用扩展正则表达式命令 |
| –color=auto | 为grep过滤结果添加颜色 |
| -w | 只匹配过滤的单词 |
| -o | 只输出匹配的内容 |
grep的常用基本案例
将/etc/passwd,有出现 root 的行取出来
[root@csq ~]# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
或
[root@csq ~]# cat /etc/passwd | grep root
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
将/etc/passwd,输出root并显示行号 -n
[root@csq ~]# grep -n "root" /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin
输出root并不区分大小写 -i
# 自行编辑一个带有root 和ROOT的文件测试
[root@csq ~]# grep -i "root" passwd.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/ROOT:/sbin/nologin
找出没有root的行 -v
[root@csq ~]# grep -v "root" passwd.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/ROOT:/sbin/nologin
统计匹配root的行数 -c
[root@csq ~]# grep -c "root" /etc/passwd
2
只匹配root -w
# 加上-w 和grep “root” /etc/passwd 一样
[root@csq ~]# grep -w "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
只输出匹配的内容 -o
# 通常与-n一起使用显示匹配内容的具体位置
[root@csq ~]# grep -o "root" /etc/passwd -n
1:root
1:root
1:root
10:root
grep与基本正则表达式案例
准备一份测试文件
[root@csq ~]# cat test.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:
bin:x:1:
daemon:x:2:
sys:x:3:
adm:x:4:
输出所有以root开头的行
[root@csq ~]# grep -in "^root" test.txt
1:root:x:0:0:root:/root:/bin/bash
7:root:x:0:
输出所有空行
# 可以利用 cat -A 来查看文件,可以发现每行结尾都有个$符号
[root@csq ~]# grep -in "^$" test.txt
6:
8:
10:
12:
14:
输出除了空行外的内容
[root@csq ~]# grep -inv "^$" test.txt
1:root:x:0:0:root:/root:/bin/bash
2:bin:x:1:1:bin:/bin:/sbin/nologin
3:daemon:x:2:2:daemon:/sbin:/sbin/nologin
4:adm:x:3:4:adm:/var/adm:/sbin/nologin
5:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7:root:x:0:
9:bin:x:1:
11:daemon:x:2:
13:sys:x:3:
15:adm:x:4:
输出除了注释行和空行以外的内容
[root@csq ~]# grep -v "^#" test.txt | grep "^$" test.txt -inv
1:#passwd
2:root:x:0:0:root:/root:/bin/bash
3:bin:x:1:1:bin:/bin:/sbin/nologin
4:daemon:x:2:2:daemon:/sbin:/sbin/nologin
5:adm:x:3:4:adm:/var/adm:/sbin/nologin
6:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7:#group
8:root:x:0:
10:bin:x:1:
12:daemon:x:2:
14:sys:x:3:
16:adm:x:4:
找出与字符p相关的行
[root@csq ~]# grep -n ".p" test.txt
1:#passwd
6:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7:#group
匹配所有内容
[root@csq ~]# grep -n ".*" test.txt
1:#passwd
2:root:x:0:0:root:/root:/bin/bash
3:bin:x:1:1:bin:/bin:/sbin/nologin
4:daemon:x:2:2:daemon:/sbin:/sbin/nologin
5:adm:x:3:4:adm:/var/adm:/sbin/nologin
6:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
7:#group
8:root:x:0:
9:
10:bin:x:1:
11:
12:daemon:x:2:
13:
14:sys:x:3:
15:
16:adm:x:4:
贪婪匹配前面不管有什么以字符b结尾的

匹配字符a-z并输出
- [a-z]匹配所有小写字母
- [A-Z]匹配所有大写字母
- [a-zA-Z]匹配所有大小写字母
- [0-9]匹配所有单个数字
- [a-zA-Z0-9]匹配所有大小写字母和单个数字

匹配除了a-c以外的行
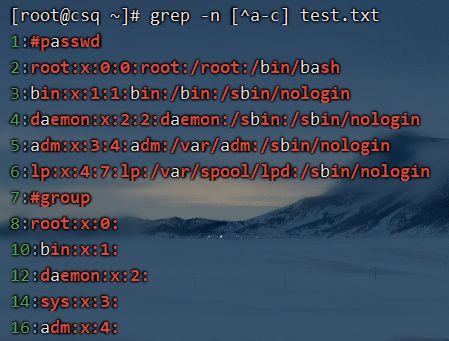
grep与扩展正则表达式案例
此处使用grep -E 进行实践扩展正则
+符号
+号表示匹配前一个字符1次或多次

?符号
匹配前一个字符0次或1次
cs?q表示匹配前一个字符s 0次或者1次

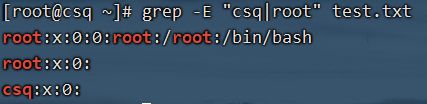
|符号
找出字符串csq以及root相干的行
()小括号
分组过滤,被括起来的内容表示一个整体

匹配以root开头以root结尾的行
[root@csq ~]# grep -E "(r..t).*\1" test.txt
root:x:0:0:root:/root:/bin/bash
a{n,m}
匹配o字符,最少1次最多2次

sed
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具
其中最常用的功能就是过滤和取行(指定行)
sed语法
用法: sed [选项]... {sed内置命令符} [输入文件]...
| 选项参数 | 解释 |
|---|---|
| -e | 进行多项(多次)编辑 |
| -n | 取消默认输出 |
| -r | 使用扩展正则表达式 |
| -i | 原地编辑(修改文件) |
| -f | 指定sed脚本的文件名 |
常用的处理动作
所有动作都要在单引号里
| 动作 | 解释 |
|---|---|
| p | 打印 |
| i | 在指定行之前插入内容 |
| a | 在指定行之后插入内容 |
| c | 替换指定行的所有内容 |
| d | 删除指定行 |
| s | 查找并替换 |
sed常见的案例
# 测试内容
[root@csq ~]# cat 11.txt
molly: it's a-ok.
gordon: any problem?
molly: i have trouble talking with my teacher.
gordon: why are you nervous?
molly: i never know how to act around my teacher. i need to review more.
gordon: no problem, i will help you review.
molly: you would do that for me? you are a-ok.
输出文件的2,3行
[root@csq ~]# sed -n ’2,3p‘ 11.txt
gordon: any problem?
molly: i have trouble talking with my teacher.
过滤出含有you的字符串行
[root@csq ~]# sed -n ’/you/p‘ 11.txt
gordon: why are you nervous?
gordon: no problem, i will help you review.
molly: you would do that for me? you are a-ok.
删除含有help的行
[root@csq ~]# sed -in ’/help/d‘ 11.txt
[root@csq ~]# cat -n 11.txt
1 molly: it's a-ok.
2 gordon: any problem?
3 molly: i have trouble talking with my teacher.
4 gordon: why are you nervous?
5 molly: i never know how to act around my teacher. i need to review more.
6 molly: you would do that for me? you are a-ok.
将文件中的you全部替换为my

替换所有he为my,同时替换i 为I
[root@csq ~]# sed -e 's/he/my/g' -e 's/i/I/g' 11.txt -i
molly: It's a-ok.
gordon: any problem?
molly: I have trouble talkIng wIth my teacmyr.
gordon: why are my nervous?
molly: I never kyesw how to act around my teacmyr. I need to revIew more.
molly: my would do that for me? my are a-ok.
在文件第二行下追加内容
[root@csq ~]# sed -in '2a I like sed\nI like grep' 11.txt
[root@csq ~]# head -n 3 11.txt
molly: It's a-ok.
gordon: any problem?
I like sed
I like grep
在每一行添加----分隔
[root@csq ~]# sed -in 'a -------------' 11.txt
[root@csq ~]# head -n 4 11.txt
molly: It's a-ok.
-------------
gordon: any problem?
-------------
sed结合正则表达式案例
[root@csq ~]# ifconfig enp2s0 | sed -n '2p' |sed -e 's/^.*inet//g' -e 's/net.*$//g'
192.168.124.3
awk
awk是一个强大的Linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表样式
awk早期在Unix上实现,我们用的awk是gawk,是GUN awk的意思

awk也是一门编程语言,支持条件判断、数组、循环功能等
awk语法
awk options ’pattern[action]‘ {filenames}
- options:awk可选参数
- pattern :模式
- action:动作
内置变量
| 参数 | 解释 |
|---|---|
| ORS | 输出当前记录分隔符 |
| FS | 输入字符风隔符,默认为空白字符 |
| OFS | 输出字段分隔符,默认为空白 字符 |
| RS | 输入记录分隔符(输入换行符),指定输入时的额换行符 |
| NF | number of Field,当前行的字段的个数,字段数量 |
| NR | 行号,当前处理的文本行的行号 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGC | 命令行参数的个数 |
| ARGV | 数组,保存的是命令行所给定的各参数 |
awk参数
| 参数 | 说明 |
|---|---|
| -F | 指定分隔字段符 |
| -v | 定义或修改一个awk内部变量 |
| -f | 从脚本文件中读取awk命令 |
案例
做完练习就能看懂此图了

# 准备一份测试文件
[root@csq ~]# cat 22.txt
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
# 准备第二份测试文件
$0打印当前文件内容
[root@csq ~]# awk '{print $0}' 22.txt
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
$1,$3打印第一列,和第三列
[root@csq ~]# awk '{print $1,$3}' 22.txt
csq csq2
csq5 csq7
csq10 csq12
csq14 csq16
NR打印行号
显示文件第一列信息
[root@csq ~]# awk '{print "第"NR"行",$1}' 22.txt
第1行 csq
第2行 csq5
第3行 csq10
第4行 csq14
显示文件第三行,和第四行
[root@csq ~]# awk 'NR==3,NR==4' 22.txt
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
显示文件第三行 第二列 并显示行号
[root@csq ~]# awk 'NR==3{print NR,$2}' 22.txt
3 csq11
NF打印字段数
字段数就是计算每一行有多少列
[root@csq ~]# awk '{print "第"NR"行",$1,"字段数"NF}' 22.txt
第1行 csq 字段数5
第2行 csq5 字段数5
第3行 csq10 字段数4
第4行 csq14 字段数4
awk取IP的用法
[root@csq ~]# ifconfig enp2s0 |awk 'NR==2{print $2}'
192.168.100.10
FS输入分隔符
awk逐行处理文本的时候,以输入分隔符为准,把文本切成多个片段,默认符号是空格,当我们处理特殊文件,没有空格的时候,可以自定义分隔符
打印文件第一列内容
[root@csq ~]# awk -F ':' '{print $1}' 33.txt
root
bin
daemon
adm
lp
sync
shutdown
halt
除了使用-F选项,还可以使用变量的形式,指定分隔符,使用-v选项搭配,修改FS变量
# 测试文件
[root@csq ~]# cat 44.txt
csq?csq1?csq2?csq3?csq4
csq5?csq6?csq7 csq8?csq9
csq10?csq11?csq12?csq13
csq14?csq15?csq16?csq17
使用-v指定分隔符打印第二列信息
[root@csq ~]# awk -v FS'?' '{print $2}' 44.txt
csq1
csq6
csq11
csq15
OFS输出分隔符
awk执行完命令,默认用空格隔开每一列,这个空格就是awk的默认输出符
利用OFS输出分隔符分隔开,第一列,第二列,第三列
[root@csq ~]# awk -F ':' -v OFS='---' '{print $1,$2,$3}' 33.txt
root---x---0
bin---x---1
daemon---x---2
adm---x---3
lp---x---4
sync---x---5
shutdown---x---6
halt---x---7
RS输入记录分隔符
RS变量的作用就是 输入分隔符 ,默认是 回车符 ,也就是说 回车 和 换行符
我们也可以自定义 空格 作为 行分隔符 每遇到一个空格就换行处理
[root@csq ~]# cat 22.txt
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
[root@csq ~]# awk -v RS=' ' '{print NR,$0}' 22.txt
1 csq
2 csq1
3 csq2
4 csq3
5 csq4
csq5
6 csq6
7 csq7
8 csq8
9 csq9
csq10
10 csq11
11 csq12
12 csq13
csq14
13 csq15
14 csq16
15 csq17
内置变量ORS
ORS是输出分隔符的意思,awk默认认为,每一行结束了,就得添加 回车换行符
ORS变量可以更改输出符·
[root@csq ~]# awk -v ORS='&&&' '{print NR,$0}' 22.txt
1 csq csq1 csq2 csq3 csq4&&&2 csq5 csq6 csq7 csq8 csq9&&&3 csq10 csq11 csq12 csq13&&&4 csq14 csq15 csq16 csq17&&&
内置变量FILENAME
显示awk正在处理文件的名字
[root@csq ~]# awk '{print FILENAME,NR,$1}' 22.txt
22.txt 1 csq
22.txt 2 csq5
22.txt 3 csq10
22.txt 4 csq14
变量ARGC,ARGV
ARGV表示的是一个数组,数组中保存的命令行所给的 参数
数组是一种数据类型,如同一个盒子
盒子有它的名字,且内部有N个小格子,标号从0开始
BEGIN表示你在打印动作的时候先做的事
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print $2}' 22.txt
csqcsq
csq1
csq6
csq11
csq15
argv[0] 指向程序运行的全路径名
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[0]}' 22.txt
csqcsq
awk
awk
awk
awk
argv[1] 指向在DOS命令行中执行程序名后的第一个字符串
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[1]}' 22.txt
csqcsq
22.txt
22.txt
22.txt
22.txt
argv[2] 指向执行程序名后的第二个字符串
[root@csq ~]# awk 'BEGIN{print "csqcsq"} {print ARGV[0], ARGV[1],ARGV[2]}' 22.txt 33.txt
csqcsq
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awk 22.txt 33.txt
awlk自定义变量
顾名思义,就是我们自己定义变量
- 方法①:-v varName=value
- 方法②:在程序中直接定义
方法①:
[root@csq ~]# awk -v myname="csq" 'BEGIN{print "下面的文件内容?",myname}{print $0}' 22.txt
下面的文件内容? csq
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
方法②:
[root@csq ~]# awk 'BEGIN{csq1="我是我是我是我是我是";csq2="是我是我是我是我";print csq1,csq2}'
我是我是我是我是我是 是我是我是我是我
# 定义了2个变量,最后打印变量
方法③:间接引用shell变量
[root@csq ~]# Linuxbianliang="这个是Linux定义的变量"
[root@csq ~]# awk -v awkbl=$Linuxbianliang 'BEGIN{print awkbl }'
这个是Linux定义的变量
awk格式化
之前大部分内容都是写的{print}的功能,之呢个对文本简单的输出,并不能美化或者修改格式
printf格式化输出
printf命令的作用是按照我们指定的格式输出文本
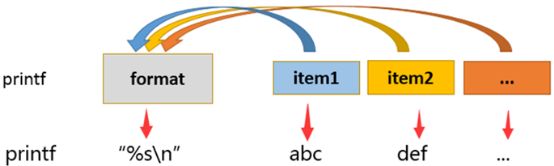
printf语法
printf命令的语法如下
printf "指定的格式" "文本1" "文本2" "文本3" ......
echo 和printf区别
输出文本,echo命令也可以进行输出,它们的无别
[root@csq ~]# echo "mynamecsq"
mynamecsq
[root@csq ~]# printf "mynamecsq"
mynamecsq[root@csq ~]#
在输出文本时,echo会对输出的文本进行换行,而printf命令则不会对输出的文本进行换行,我们使用转义符\n就可以换行
[root@csq ~]# printf "mynamecsq\n"
mynamecsq
printf和print的区别
format的使用
要点:
- 其与print命令的最大不同是,printf需要指定format;
- format用于指定后面的每个item的输出格式
- printf语句不会自动打印换行符:\n
format格式如下
%c:显示字符的ASCII码;
%d,%i:十进制整数;
%e,%E:科学计数法显示;
%f:显示浮点数
%g,%G:以科学计数法的格式或浮点数的格式显示数值;
%s:显示字符串;
%u:无符号整数;
%%:显示%自身;
printf修饰符:
-:左对齐(默认是右对齐)
+:显示数值符号:printf “%+d”
printf动作默认不会添加换行符
print默认添加空格换行符
[root@csq ~]# awk '{print $1}' 22.txt
csq
csq5
csq10
csq14
[root@csq ~]# awk '{printf $1}' 22.txt
csqcsq5csq10csq14[root@csq ~]#
printf添加格式
格式化字符串%s代表字符串的意思
[root@csq ~]# awk '{printf "%s\n",$1}' 22.txt
csq
csq5
csq10
csq14
对多个变量进行格式化
当我们使用linux命令printf时,是这样的,一个%s格式替换符,可以对多个参数进行重复格式化
[root@csq ~]# printf "%s\n" a a a a a
a
a
a
a
a
然而awk的格式替换符想要修改多个变量,必须传入多个
[root@csq ~]# awk 'BEGIN{printf "%d\n%d\n%d\n",1,2,3}'
1
2
3
printf案例
准备测试文件
[root@csq ~]# cat 22.txt
csq csq1 csq2 csq3 csq4
csq5 csq6 csq7 csq8 csq9
csq10 csq11 csq12 csq13
csq14 csq15 csq16 csq17
[root@csq ~]# awk '{printf "第一列:%s 第二列:%s 第三列:%s\n",$1,$2,$3}' 22.txt
第一列:csq 第二列:csq1 第三列:csq2
第一列:csq5 第二列:csq6 第三列:csq7
第一列:csq10 第二列:csq11 第三列:csq12
第一列:csq14 第二列:csq15 第三列:csq16
- awk通过空格切割文档
- printf动作对数据格式化
对pwd.txt文件格式化
准备测试文件
[root@csq ~]# cat pwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin

[root@csq ~]# awk -v FS=":" 'BEGIN{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户使用的注释器"} {printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n",$1,$2,$3,$4,$5,$6,$7}' pwd.txt
参数解释:
- BEGIN{printf “格式化替换符 格式化替换符”,“变量”,”变量“} 执行BEGIN模式
- %s:是格式替换符,替换字符串
- %s\t: 格式化字符串后,添加制表符
- %s-25s:-代表左对齐,25代表25个字符长度
sq16
- awk通过空格切割文档
- printf动作对数据格式化
**对pwd.txt文件格式化**
**准备测试文件**
```shell
[root@csq ~]# cat pwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@csq ~]# awk -v FS=":" 'BEGIN{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","用户使用的注释器"} {printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n",$1,$2,$3,$4,$5,$6,$7}' pwd.txt
参数解释:
- BEGIN{printf “格式化替换符 格式化替换符”,“变量”,”变量“} 执行BEGIN模式
- %s:是格式替换符,替换字符串
- %s\t: 格式化字符串后,添加制表符
- %s-25s:-代表左对齐,25代表25个字符长度