自然语言处理之数据平滑方法
转载自:https://blog.csdn.net/fuermolei/article/details/81353746
在自然语言处理中,经常要计算单词序列(句子)出现的概率估计。但是,算法训练的时候,预料库中不可能包含所有可能出现的序列,因此为了防止对训练样本中为出现的新序列概率估计值为零,人们发明了不少可以改善估计新序列出现的概率算法,即数据的平滑。最常见的数据平滑算法包括如下几种:
-
Add-one (Laplace) smoothing
-
Add-k smoothing
-
Backoff回退法
-
Interpolation插值法
-
Absolute discounting
-
Kneser-Ney smoothing
-
Modified Kneser-ney smoothing
这几个方法实际上可以简单的理解为三种不同的方法:第一种类型为政府给大家每人一笔或者几笔钱(如1和2),第二种为找父母要(如3和4),最后一种就是劫富济贫(如5-7)。下面依次简单介绍上面的方法,具体详细的介绍,大家可以参阅相应的论文和书籍。
数据预处理
在介绍上面几种平滑的方法之前,这里先给出一个简单的的数据预处理的方法,特别是对于OOV(需要训练的词不在词袋里面)的情况特别有效,而且如果训练的时候,如果有几十万的词汇,一般不会对这几十万的词汇进行全部训练,而是需要预先做下面的处理后再进行数据的平滑和训练。
假设训练数据集中出现了|N|个不同的词汇,那么可以根据词频对这些词汇进行排序,可以选择词频最高的M个词汇作为我们的词汇集合,这样在训练和测试数据集中,将不属于V的词汇都替换成特殊的词汇UNK,这样可以大大减少计算量,也可以提高计算的精度。
Add-one (Laplace) smoothing
Add-one 是最简单、最直观的一种平滑算法,既然希望没有出现过的N-gram的概率不再是0,那就直接规定在训练时任何一个N-gram在训练预料至少出现一次(即规定没有出现的,在语料中也出现一次),因此:Countnew(n-gram) = countold(n-gram)+1;
于是对于n-gram的模型而言,假设V是所有可能的不同的N-gram的类型个数,那么根据贝叶斯公式有

当然这里的n-gram的可以相应的改成uingram和bigram表达式,并不影响。其中C(x)为x在训练中出现的次数,wi为给定的训练数据中第i个单词。
这样一来,训练语料库中出现的n-gram的概率不再为0,而是一个大于0的较小的概率值,Add-one平滑算法确实解决了我们的问题,但是显然它也并不完美,由于训练语料中未出现的n-gram数量太多,平滑后,所有未出现的占据了整个概率分布的一个很大的比例,因此,在自然语言处理中,Add-one给语料库中没有出现的n-gram分配了太多的概率空间。此外所有没有出现的概率相等是不是合理,这也是需要考虑的。
Add-k smoothing
由Add-one衍生出来的另一种算法就是Add-k,既然我们认为加1有点过了,那么我们可以选择一个小于1的正数k,概率计算公式就可以变成如下表达式:

它的效果通常会比Add-one好,但是依旧没有办法解决问题,至少在实践中,k必须认为的给定,而这个值到底多少该取多少都没有办法确定。
Backoff回退法
回退模型,思路实际上是:如果你自己有钱,那么就自己出钱,如果你自己没有钱,那么就你爸爸出,如果你爸爸没有钱,就你爷爷出,举一个例子,当使用Trigram的时候,如果Count(trigram)满足条件就使用,否则使用Bigram,再不然就使用Unigram.
它也被称为:Katz smoothing,具体的可以去查看相应的书籍。
它的表达式为:
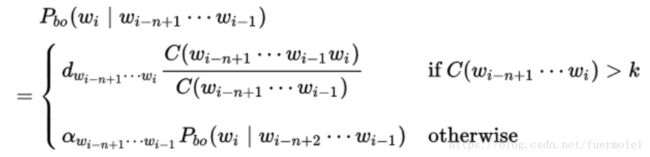
其中d,a和k分别为参数。k一般选择为0,但是也可以选其它的值。
Interpolation插值法
插值法和回退法的思想非常相似,设想对于一个trigram的模型,我们要统计语料库中“”“I like chinese food”出现的次数,结果发现它没有出现,则计数为0,在回退策略中们将会试着用低阶的gram来进行替代,也就是用“like chinese food”出现的次数来替代。在使用插值的时候,我们把不同阶层的n-gram的模型线性叠加组合起来之后再使用,简单的如trigram的模型,按照如下的方式进行叠加:

参数可以凭借经验进行设定,也可以通过特定的算法来进行确定,比如EM算法。对于数据一般可以分为: traning set, development set, testing set. 那么P的概率使用training set进行训练得出,lamda参数使用development set得到。
Absolute discounting
插值法使用的参数实际上没有特定的选择,如果将lamda参数根据上下文进行选择的话就会演变成Absolute discounting。对于这个算法的基本想法是,有钱的,每个人交固定的税D,建立一个基金,没有钱的根据自己的爸爸有多少钱分这个基金。比如对于bigram的模型来说,有如下公式。

D为参数,可以通过测试优化设定。
Kneser-Ney smoothing
这种算法是目前一种标准的而且是非常先进的平滑算法,它其实相当于前面讲过的几种算法的综合。它的思想实际上是:有钱的人,每个人交一个固定的税D,大家一起建立一个基金,没有钱的呢,根据自己的的爸爸的“交际的广泛”的程度来分了这个基金。这里交际的广泛实际上是指它爸爸会有多少种不同的类型,类型越多,这说明越好。其定义式为:
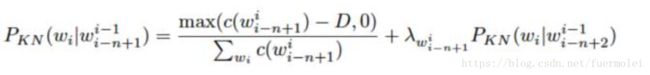
其中max(c(X)-D,0)的意思是要保证最后的计数在减去一个D后不会变成一个负数,D一般大于0小于1。这个公式递归的进行,直到对于Unigram的时候停止。而lamda是一个正则化的常量,用于分配之前的概率值(也就是从高频词汇中减去的准备分配给哪些未出现的低频词的概率值(分基金池里面的基金))。其表达是为:

PKN是在wi固定的情况下,unigram和bigram数目的比值,这里需要注意的是PKN是一个分布,它是一个非负的值,求和的话为1。
Modified Kneser-ney smoothing
这一种方法是上一种方法的改进版,而且也是现在最优的方法。上一个方法,每一个有钱的人都交一个固定的锐,这个必然会出现问题,就像国家收税一样,你有100万和你有1个亿交税的量肯定不一样这样才是比较合理的,因此将上一种方法改进就是:有钱的每个人根据自己的收入不同交不同的税D,建立一个基金,没有钱的,根据自己的爸爸交际的广泛程度来分配基金。

这里D根据c来设定不同的值,比如c为unigram,则使用D1,c位bigram,则使用D2,如果是大于等于3阶的使用D3.
转自:微信公众号:自然语言处理技术
参考书籍:
[1] Speech and language processing, Daniel Jurafsky, et la.
[2] 语音识别实践,俞栋等人。