论文笔记(三十四):ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
- 文章概括
- 摘要
- I. 介绍
- II. 相关工作
- III. ORBIT:摘要和界面设计
- IV. ORBIT: 特点
- V. 使用轨道的示范工作流程
-
- A. 基于 GPU 的强化学习
- B. 远程操作和模仿学习
- C. 运动规划
- D. 在真实机器人上部署
- VI. 讨论
- VII. 未来工作
- 致谢
文章概括
作者:Mayank Mittal, Calvin Yu, Qinxi Yu, Jingzhou Liu, Nikita Rudin, David Hoeller, Jia Lin Yuan, Ritvik Singh, Yunrong Guo, Hammad Mazhar, Ajay Mandlekar, Buck Babich, Gavriel State, Marco Hutter, Animesh Garg
来源:arXiv:2301.04195v1 [cs.RO] 10 Jan 2023
原文:https://arxiv.org/pdf/2301.04195.pdf
代码、数据和视频:
系列文章目录:
上一篇:
https://blog.csdn.net/xzs1210652636?spm=1000.2115.3001.5343
下一篇:
摘要
我们介绍的 ORBIT 是一个由英伟达 Isaac Sim 支持的统一模块化机器人学习框架。它采用模块化设计,可通过逼真的场景和快速准确的刚体和变形体模拟,轻松高效地创建机器人环境。通过 ORBIT,我们提供了一套难度各异的基准任务–从单步开柜和折布到多步任务(如房间重组)。为了支持不同的观察和行动空间,我们将固定手臂和移动机械手与不同的物理传感器和运动发生器结合在一起。借助基于 GPU 的并行化技术,ORBIT 可在几分钟内从手工或专家解决方案中训练强化学习策略和收集大型演示数据集。总之,我们提供了一个开源框架,其中包含 16 种机器人平台、4 种传感器模式、10 种运动发生器、20 多个基准任务以及 4 个学习库的封装程序。通过这个框架,我们旨在支持各种研究领域,包括表征学习、强化学习、模仿学习以及任务和运动规划。我们希望它能帮助这些领域建立跨学科的合作关系,而且它的模块化特性使它很容易扩展到未来的更多任务和应用中。有关视频、文档和代码,请访问:https://isaac-orbit.github.io/
I. 介绍
近来,机器学习的迅猛发展导致了机器人研究范式的转变。强化学习(RL)等方法在四足运动[1]、[2]、[3]和徒手操作[4]、[5]等挑战性问题上取得了令人难以置信的成功。然而,学习技术需要大量的训练数据,而在物理系统上大规模获取这些数据往往具有挑战性且成本高昂。因此,模拟器成为了安全、高效、经济地开发系统的一个极具吸引力的替代方案。
理想的机器人仿真框架需要提供快速准确的物理特性、高保真的传感器仿真、多样化的资产处理以及易于使用的界面,以便集成新的任务和环境。然而,现有的框架通常会根据其目标应用在这些方面进行权衡。例如,主要为视觉设计的模拟器,如 Habitat [18] 或 ManipulaTHOR [16],可提供不错的渲染效果,但简化了抓取等低级复杂交互。另一方面,用于机器人的物理模拟器,如 IsaacGym [17] 或 Sapien [15],可提供快速且相当精确的刚体接触动力学,但不包括基于物理的渲染(PBR)、可变形物体模拟或 ROS [19] 支持。
在这项工作中,我们介绍了基于英伟达 Isaac Sim [20]的开源框架 ORBIT,用于直观地设计环境和任务,让机器人通过逼真的场景和先进的物理模拟进行学习。它的模块化设计支持各种机器人应用,如强化学习(RL)、从演示中学习(LfD)和运动规划。通过精心设计界面,我们的目标是支持各种机器人和任务的学习,允许在不同层次的观察(本体感觉、图像、点云)和行动空间(关节空间、任务空间)进行操作。为确保高仿真吞吐量,我们利用硬件加速机器人仿真,并包括用于运动生成和观测处理的 GPU 实现。这样就可以对完整的机器人系统进行大规模的训练和评估,而不会抽象出机器人与环境交互中的低级细节。
此次发布的 ORBIT v1.0 具有以下特点:
- 三个四足机器人、七个机械臂、四个抓手、两个手和四个移动机械手的模型;
- 为每类机器人选择基于 CPU 和 GPU 的运动发生器,包括预训练运动策略、逆运动学、操作空间控制和模型预测控制;
- 使用外围设备(键盘、游戏手柄或 3D 鼠标)收集人类演示的实用程序,重放演示数据集,并将其用于学习;
- 一套用于基准测试的不同复杂程度的标准化任务。这些任务包括 11 个刚性物体操作、13 个可变形物体操作和两个运动环境。在每个任务中,我们允许轻松切换机器人、物体和传感器。
在本文的其余部分,我们将介绍基本的模拟选择(第二节)、框架的设计决策和抽象(第三节)以及其突出特点(第四节)。我们展示了该框架在不同工作流程中的适用性(第五节)–尤其是使用各种库的 RL、使用 robomimic [21] 的 LfD、运动规划 [22], [23] 以及与物理机器人的连接部署。
II. 相关工作
近年来,出现了多个仿真框架,它们都专门针对特定的机器人应用。在本节中,我们将重点介绍对建立统一仿真平台至关重要的设计选择,以及 ORBIT 与其他框架的比较(见表一)。

a) 物理引擎: 提高物理模拟环境的复杂性和逼真度对推进机器人研究至关重要。这包括改进接触动力学、更好地处理非凸几何形状(如螺纹)的碰撞、为可变形体提供稳定的求解器以及提高模拟吞吐量。
先前使用 MuJoCo [24] 或 Bullet [25] 的框架 [7], [10] 主要侧重于刚性物体操作任务。由于它们的底层物理引擎是基于 CPU 的,因此需要 CPU 集群来实现大规模并行化 [17]。另一方面,针对可变形体的框架[9]、[13]主要采用 Bullet [25] 或 FleX [26],它们使用基于粒子的动力学进行软体和布料模拟。然而,与用于刚性物体任务的框架相比,这些框架中的工具有限。ORBIT旨在通过PhysX SDK 5[27]提供一个支持刚体和变形体仿真的机器人框架,从而弥补这一差距。与其他引擎不同的是,ORBIT 采用基于 GPU 的硬件加速来实现高吞吐量、符号距离场(SDF)碰撞检查[28],以及基于有限元的更稳定的求解器来进行变形体仿真。
b) 传感器模拟: 现有的各种框架[7]、[10]、[17] 都使用传统的光栅化技术,这限制了生成图像的逼真度。最新技术[29]、[30]以物理上正确的方式模拟了光线与物体纹理的相互作用。这些方法有助于捕捉精细的视觉特性,如透明度和反射,因此有望缩小模拟与真实视觉领域的差距。虽然最近的框架 [15]、[12]、[16] 包括基于物理的渲染器,但它们主要支持基于摄像头的传感器(RGB、深度)。这对于某些需要测距传感器(如激光雷达)的移动机器人应用来说是不够的。ORBIT 利用英伟达 Isaac Sim 中的光线追踪技术,支持所有这些模式,并包含获取语义注释等附加信息的应用程序接口。
c) 场景设计和资产处理: 框架支持通过程序[6]、[7]、[15]、网格扫描[11]、[12]或游戏引擎式界面[31]、[14]创建场景。虽然网格扫描简化了大量场景的生成过程,但它们往往存在几何伪影和光照问题。另一方面,程序生成可以利用对象数据集生成各种场景。为了不局限于这两种可能性,我们通过使用图形界面和提供导入不同数据集的工具来促进场景设计 [32]、[33]、[34]。
模拟器通常都是通用型的,可以访问各种内部属性,但由于学习曲线较长,非专业用户往往会望而却步。ORBIT 继承了英伟达 Omniverse 和 Isaac Sim 平台的许多实用工具,如高质量渲染、多格式资产导入、ROS 支持和域随机化(DR)工具。不过,它的贡献在于为机器人学习提供了专门的界面,从而简化了环境设计,并便于将其移植到真实机器人上。例如,我们为不同的机器人和物体类型提供了统一的抽象,允许将执行器模型注入仿真以协助从仿真到真实的转换,并支持各种外围设备进行数据收集。总之,它提供了一个功能强大的先进仿真框架(表 I),同时通过直观的抽象保持了可用性。
III. ORBIT:摘要和界面设计
在高层次上,框架设计包括一个世界和一个代理,类似于真实世界和机器人上运行的软件栈。代理接收来自世界的原始观测数据,并计算出应用于体现体(机器人)的动作。通常在学习过程中,所有的感知和动作生成都会以相同的频率进行。然而,在现实世界中,这种情况并不多见:(1) 不同的传感器会以不同的频率滴答作响;(2) 根据控制架构的不同,动作会以不同的时间尺度进行[35];(3) 各种未建模的来源会导致实际系统中出现延迟和噪音。在 ORBIT 中,我们精心设计了界面和抽象来支持(1)和(2),而对于(3),我们将不同的执行器和噪声模型分别作为机器人和传感器的一部分来实现。
a) 世界: 与现实世界类似,我们定义了一个机器人、传感器和物体(静态或动态)存在于同一舞台上的世界。这个世界可以通过程序设计(基于脚本)、扫描网格[33]、[32]、Isaac Sim 基于游戏的图形用户界面,或两者结合,如导入扫描网格并添加对象。这种灵活性带来了三维重建网格的好处,它可以捕捉到各种建筑布局,而基于游戏的设计则简化了通过模拟游戏来创建和验证场景物理属性的体验。

机器人是世界的重要组成部分,因为它们是互动的化身。它们由铰接系统、传感器和底层控制器组成。机器人类通过 USD 文件加载其模型。它可以通过相同的 USD 文件或配置文件指定板载传感器。底层控制器通过配置的执行器模型处理输入动作,并向模拟器发出所需的关节位置、速度或扭矩指令(如图 4 所示)。致动器动力学可以使用物理学第一原理建模,也可以作为神经网络学习。这样就能将真实世界的致动器特性注入模拟,从而促进控制策略的模拟到真实的转换 [36]。
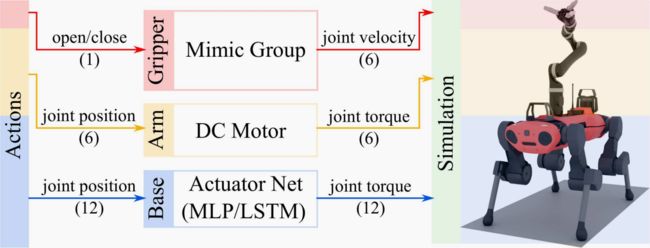
传感器既可能存在于关节上(作为机器人的一部分),也可能存在于外部(如第三人称摄像头)。ORBIT 接口将不同的物理传感器(范围、力和接触传感器)和渲染传感器(RGB、深度、法线)统一在一个通用接口下。为了模拟异步感应和执行,每个传感器都有一个内部定时器来控制其工作频率。传感器只能以配置的频率读取模拟器缓冲区。在两次定时之间,传感器会返回之前获得的数值。
传感器既可能存在于关节上(作为机器人的一部分),也可能存在于外部(如第三人称摄像头)。ORBIT 接口将不同的物理传感器(范围、力和接触传感器)和渲染传感器(RGB、深度、法线)统一在一个通用接口下。为了模拟异步感应和执行,每个传感器都有一个内部定时器来控制其工作频率。传感器只能以配置的频率读取模拟器缓冲区。在两次定时之间,传感器会返回之前获得的数值。
对象是世界中的被动实体。虽然场景中可能存在多个物体,但用户可以为指定任务定义感兴趣的物体,并只检索这些物体的数据/属性。对象属性主要包括视觉和碰撞网格、纹理和物理材料。对于任何给定的对象,我们都支持随机化其纹理和物理属性,如摩擦力和关节参数。
b) 代理: 代理指的是指导体现系统的决策过程(“智能”)。虽然机器人专家已经接受了 ROS 的模块化[19],但大多数机器人学习框架往往只关注环境定义。这种做法需要复制代码,并增加了在不同实现之间切换的摩擦。
ORBIT中的代理以模块化为核心,由多个节点组成一个计算图,节点之间交换信息。大体上,我们认为节点有两种类型: 1)基于感知的,即它们将输入处理为另一种表示(如从 RGB-D 图像到点云/TSDF),或 2)基于行动的,即它们将输入处理为行动指令(如从任务级指令到联合指令)。目前,节点之间的信息流通过 Python 同步进行,避免了服务-客户端协议的数据交换开销。
c) 学习任务和代理: 学习任务和代理等范式需要指定一个任务和一个世界,还可能包括代理的一些计算节点。任务逻辑有助于指定代理的目标,计算评估代理性能的指标(奖励/成本),并管理偶发重置。将这一组件作为一个独立模块,就可以将同一个世界定义用于不同的任务,这与现实世界中的学习类似,现实世界中的任务是通过外在奖励信号指定的。任务定义还可以包含不同的代理节点。将其形式化的一种直观方法是,考虑到特定节点的学习是通过对代理计算图进行图切割来实现的。
为了进一步具体化设计动机,请考虑通过任务空间而非低级关节动作来学习举起立方体的例子[35]。在这种情况下,任务空间控制器(如逆运动学(IK))通常以 50 Hz 的频率运行,而关节控制器需要以 1000 Hz 的频率发出指令。虽然任务空间控制器是代理计算的一部分,而不是世界计算的一部分,但可以将其封装到任务设计中。这种功能可以在运动发生器(如 IK、操作空间控制(OSC)或反应式规划器)之间轻松切换。
IV. ORBIT: 特点

虽然已经提出了各种机器人基准[9]、[6]、[10],但如何正确选择必要和充分的任务来展示 "智能 "行为仍是一个未决问题。我们没有对任务做出规定,而是将 ORBIT 作为一个平台,方便用户设计新任务。为了方便设计,我们提供了一系列不同的支持机器人、外围设备和运动发生器,以及大量用于操作刚性和柔性物体的任务,如折叠布料、打开洗碗机和将螺母拧入螺栓等基本技能。每项任务都展示了物理和渲染器的各个方面,我们相信这些方面将有助于回答关键的研究问题,例如建立可变形物体操作的表征,以及学习可推广到不同物体和机器人的技能。
a) 机器人: 我们支持 4 个移动平台(1 个全向驱动基座和 3 个四足机器人)、7 个机械臂(2 个 6-DoF 和 5 个 7-DoF)和 6 个末端执行器(4 个平行爪抓手和 2 个机械手)。我们提供的工具可将这些关节的不同组合组成复杂的机器人系统,如腿式移动机械手。这提供了大量的机器人平台,每个平台都可以在世界上进行切换。
b) 输入/输出设备: 这些设备定义了与外围控制器的接口,可实时远程操控机器人。接口从 I/O 设备读取输入指令,并将其解析为后续节点的控制指令。这不仅有助于收集演示[21],还有助于调试任务设计。目前,我们支持键盘、游戏手柄(Xbox 控制器)和来自 3Dconnexion 的 Spacemouse。
c) 动作发生器: 动作发生器将输入动作视为参考跟踪信号,从而将高级动作转化为低级指令。例如,逆运动学(IK)[37] 将指令解释为所需的末端执行器姿势,并计算所需的关节位置。采用这些控制器,特别是在任务空间中,有助于机器人操纵策略的仿真到真实的可移植性[7], [35]。
通过 ORBIT,我们在以下方面实现了基于 GPU 的功能:差分 IK [37]、操作空间控制 [38] 和关节级控制。此外,我们还提供最先进的基于模型的规划器的 CPU 实现,如用于固定臂机械手的 RMPFlow [22] 和用于移动机械手全身控制的 OCS2 [23]。我们还提供了针对腿部运动的预训练策略[39],以方便使用基本速度指令解决导航任务。
d) 刚体环境: 对于刚体环境而言,精确的接触物理、快速的碰撞检查和关节模拟至关重要。虽然这些任务中的一部分已存在于先前的作品中[6], [10], [28], [39],但我们利用我们框架的接口对其进行了增强,并使用 DR 工具提供了更多的可变性。我们还将固定臂机器人的操纵任务扩展到移动操纵器。为简洁起见,我们列出了以下环境:
- Reach - 跟踪末端执行器的理想姿势。
- Lift - 将物体举到所需位置。
- Beat the Buzz - 在不接触杆子的情况下将钥匙绕杆子移动。
- Nut-Bolt - 拧紧指定螺栓上的螺母。
- Cabinet - 打开或关闭一个柜子(铰接物体)。
- Pyramid Stack - 将积木堆成金字塔。
- Hockey [10] - 用球杆将冰球射入球网。
- Peg In Hole - 将积木插入孔中。
- Jenga [10] - 取出积木并堆叠成塔。
- In-Hand Repose - 使用灵巧的机械手。
- Velocity Locomotion - 通过腿部机器人在各种地形上追踪所需的速度指令。
e) 可变形物体环境: 可变形物体具有高维度状态和复杂的动态,很难在机器人学习中简洁地捕捉到。通过 ORBIT,我们提供了 17 种具有有效物理配置的可变形物体资产(如玩具和服装),以及程序化生成新资产(如矩形布)的方法。包含的环境简明列表如下:
- Cloth Lifting - 将布料提升到目标位置。
- Cloth Folding - 将布料折叠成所需状态。
- Cloth Spreading - 将布匹铺展在桌面上。
- Cloth Dropping - 将布放入容器中。
- Flag Hoisting - 升起立在桌上的旗帜。
- Soft Lifting - 将软物体举到目标位置。
- Soft Placing - 将软体物体放置在架子上。
- Soft Stacking - 将软体物体堆叠在一起。
- Soft Dropping - 将软体物体投掷到容器中。
- Tower of Hanoi - 将软体物体堆叠在柱子周围。
- Rope Reshaping - 在桌子上重塑绳子。
- Fluid Pouring - 将液体倒入另一个容器。
- Fluid Transport - 移动装满液体的容器而不造成任何溢出。
造成任何溢出。
需要注意的是,环境 (1)、(2) 和 (3) 具有相同的世界定义。它们的区别仅在于任务逻辑模块,即通过配置管理器定义的相关奖励。这种模块化允许代码重复使用,并使在同一个世界中定义大量任务变得更加容易。
V. 使用轨道的示范工作流程

图 6:使用手工制作的状态机和任务空间控制器演示所设计的任务。利用物理引擎的最新进展,我们支持对刚性和可变形物体进行高保真模拟。我们提供的环境允许通过配置文件(任务视频)在机器人、物体、观察结果和行动空间之间进行切换。
ORBIT 是一个统一的仿真基础架构,提供预建环境和易于使用的接口,可进行扩展和定制。由于具有高质量的物理、传感器仿真和渲染功能,ORBIT 可用于应对感知和决策方面的多种机器人挑战。我们通过示例工作流程概述了此类使用案例的子集。
A. 基于 GPU 的强化学习
我们为不同的 RL 框架(rl-games [40]、RSL-rl [39] 和 stable-baselines-3 [41])提供了包装器。这样,用户就可以在更多的 RL 算法集上测试他们的环境,促进 RL 算法的发展。
图 7 展示了使用 PPO [42] 的 Franka-Reach 在不同框架下的训练情况。虽然我们在框架中确保了相同的 PPO 参数设置,但我们注意到它们的学习性能和训练时间有所不同。由于 RSL-rl 和 rl-games 针对 GPU 进行了优化,我们观察到在 NVIDIA RTX3090 上 2048 环境下的训练速度为每秒 50,000-75,000 帧(FPS)。使用 stable-baselines3 时,我们能获得 6,000-18,0000 帧/秒的速度。

我们还展示了在弗兰卡-开柜任务中不同行动空间的训练结果,以及在影子-收手任务中各种网络架构和域随机化(DR)的训练结果。在测试中,我们发现这些环境的仿真吞吐量与 IsaacGymEnvs [17] 中的仿真吞吐量相当。
B. 远程操作和模仿学习
许多操作任务的计算成本很高,或者超出了当前 RL 算法的范围。在这些情况下,从用户演示中提取数据为技能学习提供了一条可行的途径。ORBIT 提供了一个数据收集界面,可用于使用输入/输出设备与所提供的环境进行交互,并收集类似于 roboturk [43] 的数据。我们还提供了一个用于训练模仿学习模型的 Robomimic [21] 界面。
举例来说,我们展示了Franka-Block-Lift任务的 LfD。对于初始位置和期望位置的四种设置(固定或随机起始位置和期望位置)中的每一种,我们都收集了 2000 条轨迹。利用这些演示,我们使用行为克隆(BC)和带有 RNN 策略(BC-RNN)的行为克隆来训练策略。表 II 显示了 100 次测试的性能。
表 II:在弗兰卡-布洛克-升降机环境中,在相同设置(不变)、改变初始状态(I)、目标状态(G)以及同时改变初始状态和目标状态(两者)的情况下,通过行为克隆获得的策略评估。我们报告了 100 次试验的成功率和轨迹长度。

C. 运动规划
运动规划是机器人学中研究较多的领域之一。传统的感知-模型-计划-行动(SMPA)方法将复杂的推理和控制问题分解为可能的子组件。ORBIT 支持通过程序和图形用户界面进行交互。
a) 手工创建策略: 我们为给定任务创建了一个状态机,作为代理中的一个单独节点来执行顺序规划。它提供了到达目标物体、关闭抓手、与物体互动以及操纵到下一个目标位置的目标状态。我们在图 6 中展示了这一范例在几项任务中的应用。这些手工创建的策略还可用于收集专家对布匹操纵等高难度任务的演示。
b) 交互式运动规划: 我们定义了一个由抓取生成、远程操作、任务空间控制和运动预览节点组成的系统(如图 8 所示)。通过图形用户界面,用户可以选择要抓取的物体,并查看可能的抓取姿势和使用 RMP 控制器生成的机器人运动序列。确认抓取姿势后,机器人会执行运动并举起物体。随后,用户就可以获得对机器人的远程操作控制。

图 8:使用 ORBIT 进行的交互式抓取和运动规划演示。该世界由用于桌面操作的物体组成。用户可以从图形用户界面选择一个物体进行抓取。这将触发基于图像的抓取生成器,并允许预览生成的抓取和机器人运动序列。然后,用户可以选择抓手,并在机器人上执行动作。
D. 在真实机器人上部署
在真实机器人上部署代理面临各种挑战,如处理实时控制和安全限制。不同的数据传输层,如ROSTCP[19]或ZeroMQ(ZMQ)[44],可用于连接机器人堆栈和真实平台。我们将展示如何将这些机制与 ORBIT 结合使用,在真实机器人上运行策略。
a) 使用 ZMQ: 为了保持轻量级和高效的通信,我们使用 ZMQ 将关节命令从 ORBIT 发送到为 Franka Emika 机器人运行实时内核的计算机上。为了遵守实时安全限制,我们使用五次插值器将模拟器中 60 Hz 的关节命令高采样到 1000 Hz,以便在机器人上执行(如图 9 所示)。
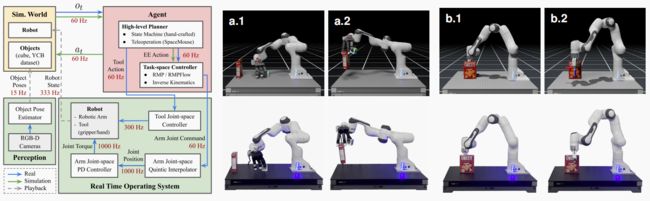
图 9:将模拟器作为数字孪生器,通过 ZMQ 连接在模拟机器人和真实机器人上计算和应用指令。a) 带有 Allegro 手的 Franka Panda 机械臂同时举起两个物体(视频)。
b) Franka Panda使用 RMP 避开物体(视频)。
我们对Franka机器人的两种配置进行了实验:一种是Franka Emika 手,另一种是 Allegro 手。对于每种配置,我们都展示了三项任务: 1)使用 Spacemouse 设备进行远程操作;2)部署状态机;3)带避障功能的航点跟踪。该代理的模块化特性使其能够轻松地在每个任务的不同控制架构之间切换,同时使用与真实机器人相同的界面。
b) 使用 ROS: 现有的各种机器人都自带 ROS 软件栈。在本演示中,我们将重点介绍如何将使用 ORBIT 训练的策略导出并部署到机器人平台上,尤其是 ANYbotics 的四足机器人 ANYmal-D。
我们完全在模拟中使用致动器网络[36]来训练腿部底座的运动策略。为使该策略具有鲁棒性,我们对底座质量(22 ± 5 千克)进行了随机化,并添加了模拟随机推力。我们使用接触报告器获得接触力,并将其用于奖励设计。我们使用 ANYmal ROS 堆栈将学习到的策略部署到机器人上(图 10)。这种从模拟到现实的转移表明,模拟接触动力学是可行的,并且适用于 ORBIT 中接触丰富的任务。

图 10:使用 ROS 连接在 ANYmal-D 机器人上部署 RL 策略(视频)。该策略是在模拟中训练的,以 50 Hz 的频率运行,而执行器网络以 200 Hz 的频率运行。
VI. 讨论
在本文中,我们提出了ORBIT:一个简化环境设计、使任务规范更容易实现并降低机器人技术和机器人学习入门门槛的框架。ORBIT 建立在最先进的物理和渲染引擎基础上,并提供接口,可轻松设计新颖逼真的环境,包括与刚性和可变形物体交互的各种机器人平台、基于物理的传感器模拟和传感器噪声模型,以及不同的执行器模型。我们随时支持各种机器人平台,从固定臂到腿部移动机械手、基于 CPU 和 GPU 的运动发生器以及对象数据集(如 YCB 和 Partnet-Mobility)。
正如第四部分所展示的那样,ORBIT所能提供的环境范围之广,使得ORBIT对机器人领域的各种研究问题都非常有用。以模块化为核心,我们展示了该框架对不同范式的可扩展性,包括强化学习、模仿学习和运动规划。我们还展示了通过基于 ZMQ 的消息传递和四足运动 RL 策略的模拟到真实部署,将该框架与 Franka Emika Panda 机器人连接起来的能力。
通过开源该框架,我们旨在减少开发新应用的开销,并为未来的机器人学习研究提供一个统一的平台。我们将继续改进该框架并增加更多的功能,同时希望研究人员为使其成为机器人研究的一站式解决方案做出贡献。
VII. 未来工作
ORBIT 的物理模拟速度高达每秒 125,000 个采样点,但摄像头渲染目前遇到了瓶颈,在 RTX 3090 上,10 个摄像头渲染 640×480 RGB 图像的速度仅为每秒 270 帧。虽然这一数字与其他框架不相上下,但我们正积极通过利用基于 GPU 的加速来进一步改进视觉运动策略的训练。
此外,尽管我们的实验展示了刚性接触建模的保真度,但在可变形物体仿真中接触的精确度仍有待探索。必须指出的是,到目前为止,该领域的机器人操纵研究还没有依赖于模拟到现实,因为现有的求解器通常比较脆弱或缓慢。通过使用基于有限元的求解器和基于物理的渲染,我们相信我们的框架将有助于在未来回答这些开放性问题。
致谢
我们感谢 Farbod Farshidian 对 OCS2 的帮助,Umid Targuliyev 对模仿学习实验的帮助,以及 Ossama Samir Ahmed、Lukasz Wawrzyniak、Avi Rudich、Bryan Peele、Nathan Ratliff、Milad Rakhsha、Viktor Makoviychuk、Jean-Francois Lafleche、Yashraj Narang 、Miles Macklin、Liila Torabi、Philipp Reist、Adam Moravansky 以及 NVIDIA PhysX 和 Omniverse 团队的其他成员对模拟器提供的帮助。