Vue2.0源码解析——编译原理
Vue2.0源码解析——编译原理
前言:本篇文章主要对Vue2.0源码的编译原理进行一个粗浅的分析,其中涉及到正则、高阶函数等知识点,对js的考察是非常的深的,因此我们来好好啃一下这个编译原理的部分。
一、编译流程
1.为什么需要编译流程?
不知道各位有没有思考过这样一个问题,为什么我们无论是在脚手架项目中还是在单文件html中,只要使用Vue框架开发,我们就可以书写出千奇百怪且好用的指令,比如v-for、v-model、@event…等等,但是浏览器默认情况下是只认识原生js、css以及html的呀,为什么我们的Vue应用程序可以在浏览器上跑呢?

那是以因为当我们在书写出一个Vue的模板的时候,Vue会在内部做一个编译的过程,这个过程就是把我们写的浏览器不认识的带有指令版本的模板(注意这里模板不是html),经过一次编译,把它变成浏览器能认识的内容。
因此简单来讲,因为浏览器不认识我们的指令版的模板,但这种带有指令的模板又特别好用,那怎么办呢,只有我们创建一个编译的过程,将其变成浏览器可以认识的内容。这就是我们为什么需要编译原理的原因。
2.编译流程过程
实际上,Vue最终在渲染函数的时候,是通过js来进行渲染的,Vue封装了所有的创建DOM的操作,基于虚拟DOM来渲染真实DOM,因为对真实DOM进行操作太过于消耗性能,但是我们可以构建一个虚拟的DOM,只对这个虚拟DOM进行操作,最后生成一个最终的虚拟DOM,然后利用j创建DOM的方法,就可以生成真实的DOM了。源码中可以找到证据!

在源码patform/web/runtime/node-opts中可以找到所有创建DOM的方法,而这些方法最终会被引用用于创建真正的DOM。
而怎么样生成这个虚拟DOM呢,我们都知道虚拟DOM实际上是一个对象,里面包含了一个元素的很多属性,特征等。
这就不得不引出Vue另外一个概念了,渲染函数,渲染函数是专门用来生成虚拟DOM的,我们也叫作render函数,这个函数一调用就会生成一个完整的虚拟DOM。而这个渲染函数是通过抽象语法树AST使用字符串拼接出来的,而抽象语法树是通过模板解析出来的。
所以我们可以总结一下,vue的编译流程是这样的
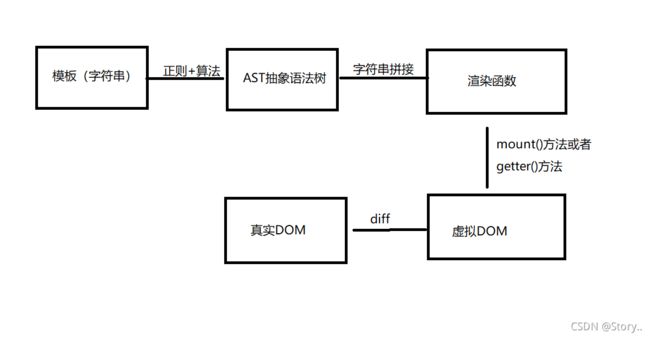
所以本篇文章我们主要就来探讨一下,一个字符串的模板,是如何变成一个虚拟DOM的,这其中经历了什么,当然,具体很多情况是非常复杂的我们只是去繁就简的进行解释。最深层次的东西我们还是要死磕源码。
二、核心函数
在上一章响应式原理中,我们提到了这个问题。我们说当触发响应式数据的改变的时候,会触发getter执行,getter执行时就会循环遍历属于自己Dep对象中的watcher,然后依次执行他们的update方法,还有印象吧!
然后我们接下看一下在update方法中做了什么!记得打开源码
core/observer/watcher中查看一下!
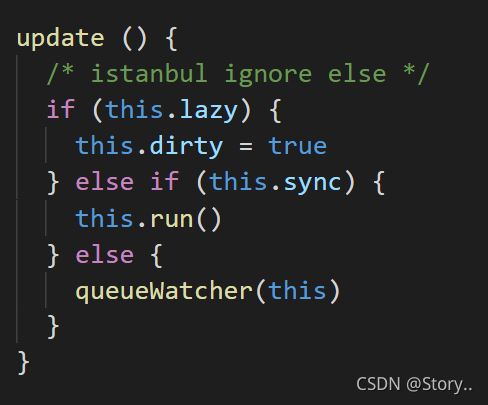
最终会执行run方法,这个这中间会去执行queueWatcher这个方法,这个方法是一个队列结构的任务调度器,是一个异步操作,这个异步操作里面实际上也执行的是run方法,然后run方法执行的实际上是get方法。

这里可以看到首先就会执行value = this.getter.call(vm,vm)这个就是核心了。我们看一下这个this.getter是个什么函数。

如果阅读完我的上一篇博客,其实就应该知道这其实是一个路径表达式或者是一个渲染函数。我们来看一下渲染函数长什么样子。

这就是渲染函数的真相了,
function (){
vm._update(vm.render() , hydrating)
}
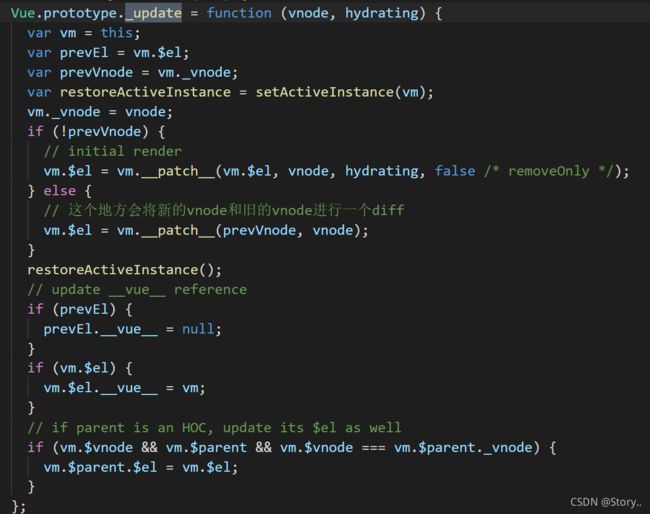
在这其中,update接受的是一个虚拟DOM,从而我们可以得出我之前的结论,渲染函数执行的结果是一个虚拟DOM,虚拟DOM在这个里面就会与之前的旧DOM进行__patch_,实际上这里就是进行diff啦,包括实际上的更新和渲染真实DOM,但这不是我们今天这篇博客探讨的重点,我们继续来看那个_render是怎么回事。它返回的是一个虚拟DOM,因此它一定会生成一个虚拟DOM,
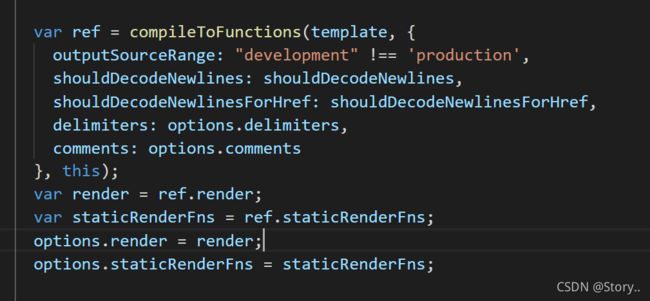
而实际上的render渲染函数是通过这个compileToFunctions函数得来的,将渲染函数挂载到了options配置项身上,供_render调用,我们来看一下,这个compileToFunctions调用后生成了什么。
![]()
就是一串这样的东西,实际上是一个函数被字符串化的一个函数字符串,因为vue这编译过程中,这个函数是根据抽象语法树,用字符串拼接出来的。仔细看一下,里面_s()中的东西就是那些动态的数据了,在这个渲染函数被生成时,这个响应式数据是没有被访问到的,只有调用这个函数,生成虚拟DOM时,响应式数据才会被访问到,真正的值会被替换到虚拟DOM中。

这是我打印出来的虚拟DOM,在虚拟DOM中所有的循环,响应式变量等vue操作符都已经生效,真正的值都已经被替换到了虚拟DOM中,可以这么说,虚拟DOM,和真实DOM,除了更小一点,几乎就是一一对应的了。
那么接下来我们就来研究一下这个渲染函数是怎么得来的吧,这也是最难啃的了。
1.模板 to ast
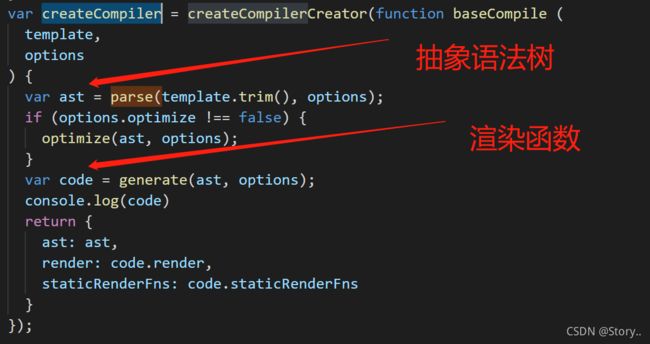
我们直接打开vue.js生产环境的源码看吧,因为那个开发环境的源码文件太多找半天不容易看懂,因为大部分结结构我们其实已经知道了,直接在这个文件中搜索parse( 就会找到这个函数,他会把模板字符串,也就是我们写的vue源代码,传进去,生成抽象语法树,并对其进行优化处理,然后利用抽象语法树生成渲染函数后再将抽象语法树和渲染函数都返回出去。
| 由 | 到 | by |
|---|---|---|
| 模板字符串(template) | ast抽象语法树 | parse() |
| ast抽象语法树 | 渲染函数 | generate |
所以我们今天的目的就是把parse()和generate()这两个函数给弄明白。
因为源码中这个parse方法实在是太大了,因此我画了一个流程图,一起来看一下吧!
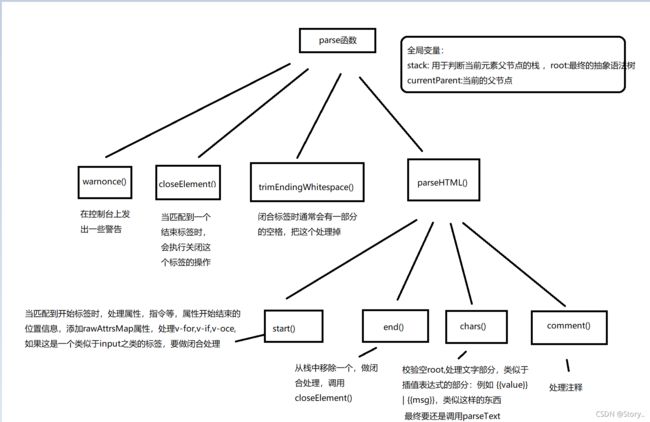
然后我们走进这个parseHTML的方法中。实际上,这个parseHTML也非常长,但是我们分而治之,暂且不管praseHTML做了什么,我们先来看几个简单的函数。
2.正则+函数
没错,vue在解析模板的时候,大量的使用了正则表达式去匹配里面的各项指令和操作符,而这个过程确实比较费脑筋,一起来看一下吧!
function advance (n) {
index += n;
html = html.substring(n);
}
这是专门用来截取字符串的函数,我们可以叫他前进函数,传什么数字,就往前截取几位,我们的模板也就是这么一段一段的往前进,慢慢生成整个抽象语法树的。
var ncname = "[a-zA-Z_][\\-\\.0-9_a-zA-Z" + (unicodeRegExp.source) + "]*";
var qnameCapture = "((?:" + ncname + "\\:)?" + ncname + ")";
var startTagOpen = new RegExp(("^<" + qnameCapture));
function parseStartTag () {
var start = html.match(startTagOpen);
if (start) {
var match = {
tagName: start[1],
attrs: [],
start: index
};
advance(start[0].length);
var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(dynamicArgAttribute) || html.match(attribute))) {
attr.start = index;
advance(attr[0].length);
attr.end = index;
match.attrs.push(attr);
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
}
只要碰到符合要求的开始标签带<开始的,就进入这个匹配过程,创建一个局部变量match,开启循环直到遇到结束标记 > ,将这其中的属性一一添加到match身上,最后返回。
function parseEndTag (tagName, start, end) {
var pos, lowerCasedTagName;
if (start == null) { start = index; }
if (end == null) { end = index; }
// Find the closest opened tag of the same type
if (tagName) {
lowerCasedTagName = tagName.toLowerCase();
for (pos = stack.length - 1; pos >= 0; pos--) {
if (stack[pos].lowerCasedTag === lowerCasedTagName) {
break
}
}
} else {
// If no tag name is provided, clean shop
pos = 0;
}
if (pos >= 0) {
// 大多数情况都是走这里的。
for (var i = stack.length - 1; i >= pos; i--) {
if (options.end) {
options.end(stack[i].tag, start, end);
}
}
// Remove the open elements from the stack
stack.length = pos;
lastTag = pos && stack[pos - 1].tag;
} else if (lowerCasedTagName === 'br') {
if (options.start) {
options.start(tagName, [], true, start, end);
}
} else if (lowerCasedTagName === 'p') {
if (options.start) {
options.start(tagName, [], false, start, end);
}
if (options.end) {
options.end(tagName, start, end);
}
}
}
}
这个函数就是处理当匹配到结束标签时的处理,可以看到最终会执行options.end()这个方法,而这个方法本质上是执行的上图中的end()方法,就是在全局栈中剔除一位,然后做结束标签的处理。调用closeElement()的方法。而我可以提前告诉这位这里面其实还有很多复杂的关系,closeElement()会调用processElement(),这里面会调用 processRef,processSlot,processAttrs,等。如果遇到事件会调用addHandler ,这里面会在el上添加一部分关于事件修饰的东西。
function handleStartTag (match) {
var tagName = match.tagName;
var unarySlash = match.unarySlash;
var l = match.attrs.length;
var attrs = new Array(l);
for (var i = 0; i < l; i++) {
var args = match.attrs[i];
var value = args[3] || args[4] || args[5] || '';
var shouldDecodeNewlines = tagName === 'a' && args[1] === 'href'
? options.shouldDecodeNewlinesForHref
: options.shouldDecodeNewlines;
attrs[i] = {
name: args[1],
value: decodeAttr(value, shouldDecodeNewlines)
};
if (options.outputSourceRange) {
attrs[i].start = args.start + args[0].match(/^\s*/).length;
attrs[i].end = args.end;
}
}
if (!unary) {
stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs, start: match.start, end: match.end });
lastTag = tagName;
}
if (options.start) {
options.start(tagName, attrs, unary, match.start, match.end);
}
}
他会将匹配好的结果整理成一个属性数组attrs,这里面有属性key,属性value,属性开始结束位置。然后调用options.start方法,也就是我们图中的start方法。我们回顾一下。

执行一下这个方法,这个el元素就比较开始像抽象语法树了
形如:
el:{
attrsList:[ ]
attrs:[]
rawAttrsMap:[]
nativeEvents:[]
....
}
是的,也就是解析的过程,就是往这个语法树对象上不断的添加不同的属性,遇到什么样的指令就添加什么样的属性,然后利用这样的一套循环最终会把整个模板解析完,就会形成一颗抽象语法树。
我们来看一下。

这是一个更加丰富的抽象语法树了。

好了,我们此时此刻已经将抽象语法树生成好了,接下来就是生成渲染函数了。
3.ast to render
我们上面有提到过,渲染函数是由generate()函数生成的,所以我们在源码中搜索这个关键字,一起来看一下吧!
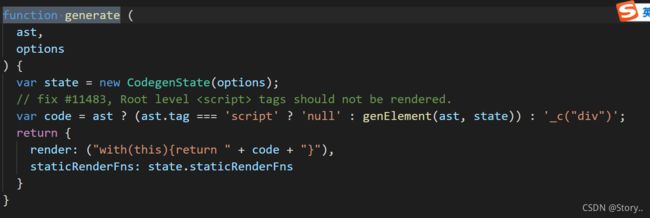
这个函数接受一个抽象语法树,也就是上面我们生成的抽象语法树,然后实际上是调用了genElement()这个方法。最终把生成的code装进
with(this){
return code
}
这里要解释一下这个width是什么语法?
with语句可以在不造成性能损失的情況下,减少变量的长度。其造成的附加计算量很少。使用’with’可以减少不必要的指针路径解析运算。
简单来讲,就是可以让大括号内部书写的变量优先在width中的作用域查找。因此就有以下的效果。
const obj = { a:1 }
with(obj){
console.log(a) // 1
}
//可以直接输出1 , 而不用写obj.a
因此可以得出,code中使用的所有变量也都会优先在当前函数作用域中查找,且不用写前缀了。那接下来我们来聊聊genElement()
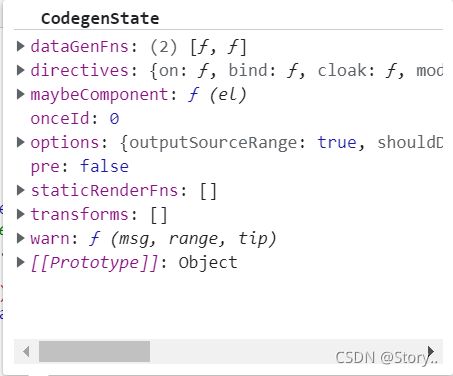
这是上图中state这个实例对象。我们先走一遍genElement()的流程。
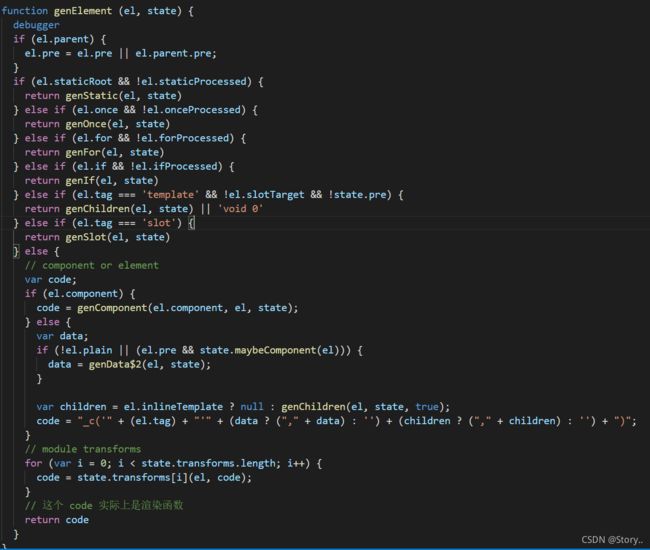
当抽象语法树收到之后,会判断跟节点,从这里也可以看出,对于同一节点来说,v-for是要比v-if的优先级要高的,因为这里的判断中当genElement识别到当前元素有for指令值,直接就会处理这个元素了,后面的genIf要到后面才会执行了,因此它会先将list循环出来再进行判断是否移除DOM,这就是为什么尽量不要把v-for和v-if写到同一个元素身上的原因。根元素一般都会跳过前面的筛选,直接走genData。通过genData一般会把属性id:root提取到attrs身上了,然后再走genChildren方法,最后用code方法将他们拼接起来,_c最终其实是createElement()方法,属于创建虚拟DOM的方法,我们来看一下genChildren干了些什么?

genChildren会遍历每一个根节点的子元素,对他们一一进行gen的处理,而这个gen是这个:

所以说这是一个递归的操作,使用递归每次返回符合要求的字符串,然后将其拼接到最终的render函数中,这就是最终渲染函数的由来。当然里面的每个函数都很精妙的,我们还是应该抽时间一一去读一下。
我们再次把最终生成的渲染函数进行展示一下。

这其中有一些例如:
_c 、_l、_v、_s的貌似函数的东西是什么呀?
这些其实就是生成虚拟DOM的函数,也是真正将所有的指令有效化的哈数,我们来一一认识一下。

不仅有以上提到的函数,还有很多没有提到的,比如一个简单的例子,模板中的v-for="item in 2"这样的指令会被解析成{for:2 alias:item}类似这样的抽象语法树,这样的抽象语法树会被拼接成_l((2),function(item){return _c('div',{key:item}类似这样的字符串函数,而_l是真正去执行循环生成2个虚拟DOM节点的函数。不信我们来点击去看一下。
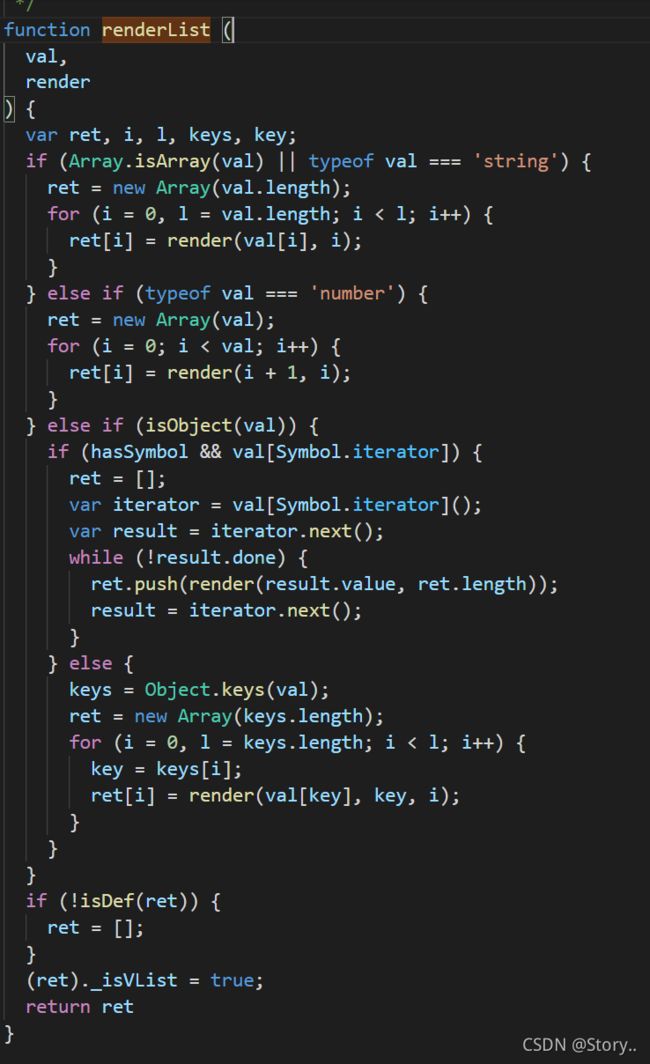
发现了么?我们传进来的循环主体会在这里进行判断,如果是数字,数组,或是对象都会在这里进行相应的循环,然后进行_c的处理。并添加key属性,这里有一个很厉害的技巧,因为在函数的最近作用域中传入的this。这个this实际上指的是当前vue的实例对象也就是vm,而因为whth操作符的原因,所有的变量都会指向当前实例,所以直接可以使用vm身上的变量,而上面渲染函数中的变量正好大多都是需要访问vm的因此,可以直接进行访问,这个就会触发响应式数据的getter,然后进行依赖的收集。就和上一章讲的串起来了。
小结:于是乎,vue的渲染函数便是同时递归完成的渲染函数的生成。然后只要关联的watcher一旦调用就会生成最新的虚拟DOM,而接下来我们只需要去关系vue如何进行diff的就可以了。
四、指令原理
1.探寻v-model原理
大家都知道v-model在vue中是一个很受开发者喜爱的指令!我们今天就来了解一下它的原理。
我们都知道v-model是一种指令因此,他一定会保存到抽象语法树的directives属性身上,因此在生成渲染函数时它一定会调用genDirectives()这个方法。
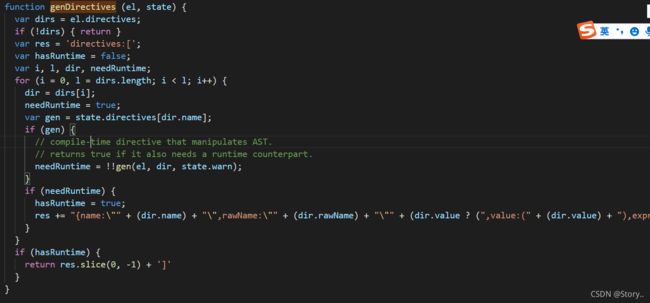
然后我们打个断点看一下。
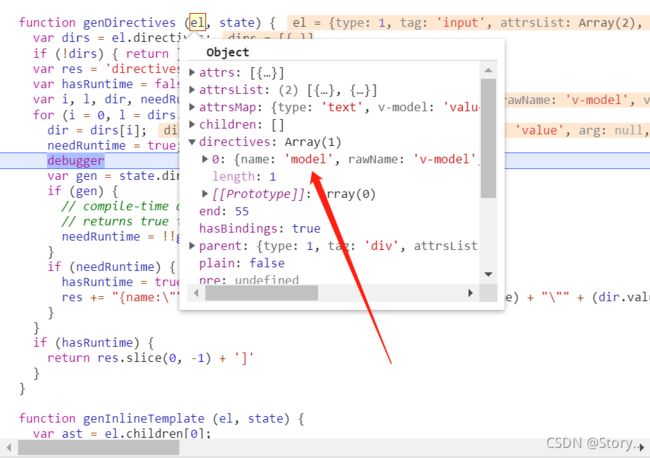
它会走这个state.directives()这个方法。
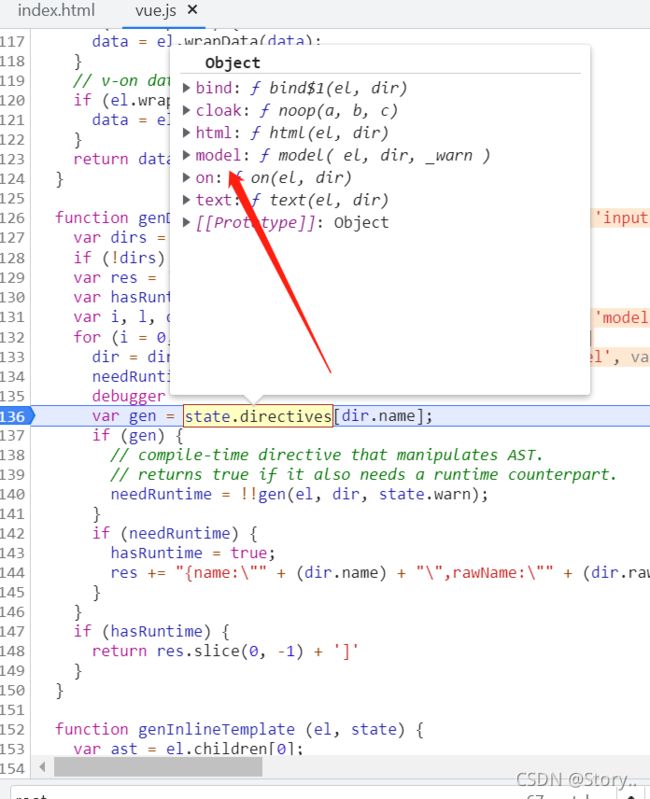
原来这个state.directives中已经有了这么多方法,进去看一下。

这个model最终会走这里的genDefaultModel方法。然后这里面应该就是真正的真相了。

这里有个很巧妙的地方,如果绑定的值没有在我们定义的响应式数据里面,vue会帮助我们添加$set方法进行响应式处理。所以我们绑定的model的vlaue哪怕之前没有定义在响应式数据里,它最终也是响应式的。

这里就是双向绑定的真相了,单向的绑定时每一个响应式数据都具备的,v-mode多做了一步,他是给相应的控件添加了一个input事件,当这个事件一旦触发, 就改变变量的值,

如图所示,这便是v-model的原理。