【R的网络提取】用R进行CSDN任意博主的信息提取
基于上一篇文章的结论,稍作修改,进行CSDN博客中,各位博主的博客标题和url的提取,本质上只是对之前的特定提取做个广义化,但是有一点确实也在困惑我,因为在XML转换过程中,有很多的list套list,然而apply族函数现阶段看到很多用法都是在大的list中,举个例子:
a<-list(list(1,2),3)
a
[[1]]
[[1]][[1]]
[1] 1
[[1]][[2]]
[1] 2
[[2]]
[1] 3这边如果我们要unlist,直接unlist就会成为一个向量:
unlist(a)
[1] 1 2 3class(unlist(a))
[1] "numeric"但是如果还是只要list呢,只是把最底层的list解绑,那么unlist中的一个参数非常有用,就是recursive,介绍上说,这个是循环unlist,如果设置成F,那么只会unlist一层,比如
unlist(a,recursive = F)
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3那么:
class(unlist(a,recursive = F))
[1] "list"这个函数非常有用,在进行xpath提取做lapply时特别有用,会保证字符先拆解再拼接,但是行数不变的效果;
下面进行R中提取CSDN博客的代码:
library(XML)
library(stringr)
Ex_CSDN<-function(name,page=1){
baseurl<-c('http://blog.csdn.net')
for (i in 1:page){
url[i]<-str_c('http://blog.csdn.net/',name,'/article/list/',i)
Title[i]<-list(
unlist(
xpathApply(htmlParse(url[i],encoding='UTF-8'),
'//div[@class="list_item article_item"]/*/*/*/a',
xmlValue)))
#标题栏的list
Url[i]<-list(
unlist(lapply(
xpathApply(htmlParse(url[i],encoding='UTF-8'),
'//div[@class="list_item article_item"]/*/*/*/a',
xmlAttrs),
str_extract_all,
'\\/\\S+')))
#URL的list
}
TITLE<-unlist(
lapply(
unlist(
lapply(
unlist(Title),str_extract_all,'[^\\s+]\\S+'),recursive = F),
paste,collapse=' '))
URL<-mapply(str_c,baseurl,unlist(Url))
myCSDN<-data.frame(TITLE,URL)
write.csv(myCSDN,
file=str_c('D:\\R study\\CSDN_',name,'toppage=',page,'.csv'),
row.names = F)
}
这个封装的函数和之前那篇文章类似,但是其中修改了下逻辑,因为很多人喜欢在标题中使用多个空格,包括置顶之类的,所以逻辑是拆分标题中所有非空字符,然后用空格拼接。具体的这一段代码是这样:
TITLE<-unlist(
lapply(
unlist(
lapply(
unlist(Title),str_extract_all,'[^\\s+]\\S+'),recursive = F),
paste,collapse=' '))先对一些类似乱码的Title进行解码,Title是这样的:
[[1]]
[1] "\r\n [置顶]\r\n LSH︱python实现局部敏感随机投影森林——LSHForest/sklearn(一) \r\n "
[2] "\r\n [置顶]\r\n R+先知︱Facebook大规模时序预测『真』神器——Prophet(遍地代码图) \r\n "需要把前面的空格去掉,置顶后面的空格统统去掉,然后用paste进行拼接,拼接的中间字符就是空格;
Ex_CSDN函数我设计的有两个参数:name和page:
name就是提取人的名字,page是想提取几页的博客;
测试下,比如这个知名博主:sinat_26917383
http://blog.csdn.net/sinat_26917383;
我想要看下他前两页的博客和url,那么
Ex_CSDN('sinat_26917383',2)然后,其实在R中也可以看,但是为了方便,直接上CSV图:
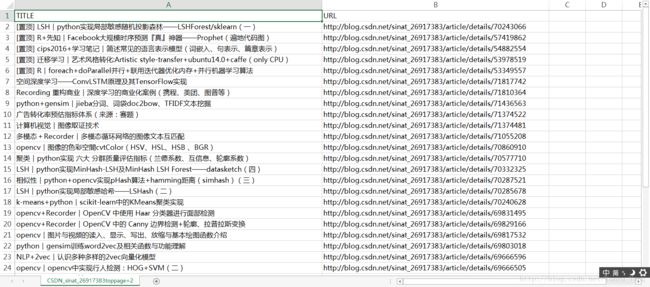
还有google下一位写爬虫的博主:pleasecallmewhy
Ex_CSDN('pleasecallmewhy',2)对应的title和url为:
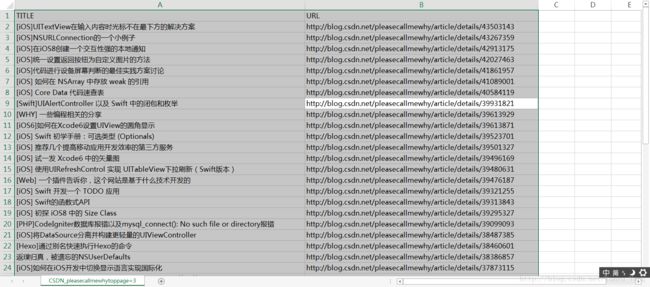
CSV看不清在R中是这样的:
TITLE
1 [置顶] LSH︱python实现局部敏感随机投影森林——LSHForest/sklearn(一)
2 [置顶] R+先知︱Facebook大规模时序预测『真』神器——Prophet(遍地代码图)
3 [置顶] cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
4 [置顶] 迁移学习︱艺术风格转化:Artistic style-transfer+ubuntu14.0+caffe(only CPU)
5 [置顶] R︱foreach+doParallel并行+联用迭代器优化内存+并行机器学习算法
6 空间深度学习——ConvLSTM原理及其TensorFlow实现
7 Recording 重构商业︱深度学习的商业化案例(携程、美团、图普等)
8 python+gensim︱jieba分词、词袋doc2bow、TFIDF文本挖掘
9 广告转化率预估指标体系(来源:赛题)
10 计算机视觉︱图像取证技术
11 多模态+Recorder︱多模态循环网络的图像文本互匹配
12 opencv︱图像的色彩空間cvtColor(HSV、HSL、HSB 、BGR)
13 聚类︱python实现 六大 分群质量评估指标(兰德系数、互信息、轮廓系数)
14 LSH︱python实现MinHash-LSH及MinHash LSH Forest——datasketch(四)
15 相似性︱python+opencv实现pHash算法+hamming距离(simhash)(三)
16 LSH︱python实现局部敏感哈希——LSHash(二)
17 k-means+python︱scikit-learn中的KMeans聚类实现
18 opencv+Recorder︱OpenCV 中使用 Haar 分类器进行面部检测
19 opencv+Recorder︱OpenCV 中的 Canny 边界检测+轮廓、拉普拉斯变换
20 opencv︱图片与视频的读入、显示、写出、放缩与基本绘图函数介绍
21 python︱gensim训练word2vec及相关函数与功能理解
22 NLP+2vec︱认识多种多样的2vec向量化模型
23 opencv︱opencv中实现行人检测:HOG+SVM(二)
24 opencv︱HOG描述符介绍+opencv中HOG函数介绍(一)
25 python︱Python进程、线程、协程详解
26 SSD+caffe︱Single Shot MultiBox Detector 目标检测+fine-tuning(二)
27 CRU+MXnet︱CRU-Net Collective Residual Networks
28 SSD+caffe︱Single Shot MultiBox Detector 目标检测(一)
29 知识图谱+Recorder︱中文知识图谱API与工具
30 R+中文︱中文文本处理杂货柜——chinese.misc
31 Recorder+人脸识别︱国内人脸识别技术趋势与识别难点、技术实践
32 DeepFashion︱衣物时尚元素关键点定位+时尚元素对齐技术
33 图像检索︱图像的相似性搜索与图像向量化、哈希化(文献、方法描述)
34 Recorder︱图像特征检测及提取算法、基本属性、匹配方法
URL
1 http://blog.csdn.net/sinat_26917383/article/details/70243066
2 http://blog.csdn.net/sinat_26917383/article/details/57419862
3 http://blog.csdn.net/sinat_26917383/article/details/54882554
4 http://blog.csdn.net/sinat_26917383/article/details/53978519
5 http://blog.csdn.net/sinat_26917383/article/details/53349557
6 http://blog.csdn.net/sinat_26917383/article/details/71817742
7 http://blog.csdn.net/sinat_26917383/article/details/71810364
8 http://blog.csdn.net/sinat_26917383/article/details/71436563
9 http://blog.csdn.net/sinat_26917383/article/details/71374522
10 http://blog.csdn.net/sinat_26917383/article/details/71374481
11 http://blog.csdn.net/sinat_26917383/article/details/71055208
12 http://blog.csdn.net/sinat_26917383/article/details/70860910
13 http://blog.csdn.net/sinat_26917383/article/details/70577710
14 http://blog.csdn.net/sinat_26917383/article/details/70332325
15 http://blog.csdn.net/sinat_26917383/article/details/70287521
16 http://blog.csdn.net/sinat_26917383/article/details/70285678
17 http://blog.csdn.net/sinat_26917383/article/details/70240628
18 http://blog.csdn.net/sinat_26917383/article/details/69831495
19 http://blog.csdn.net/sinat_26917383/article/details/69829166
20 http://blog.csdn.net/sinat_26917383/article/details/69817532
21 http://blog.csdn.net/sinat_26917383/article/details/69803018
22 http://blog.csdn.net/sinat_26917383/article/details/69666596
23 http://blog.csdn.net/sinat_26917383/article/details/69666505
24 http://blog.csdn.net/sinat_26917383/article/details/69666371
25 http://blog.csdn.net/sinat_26917383/article/details/68951673
26 http://blog.csdn.net/sinat_26917383/article/details/68068113
27 http://blog.csdn.net/sinat_26917383/article/details/68060325
28 http://blog.csdn.net/sinat_26917383/article/details/67639189
29 http://blog.csdn.net/sinat_26917383/article/details/66473253
30 http://blog.csdn.net/sinat_26917383/article/details/63706260
31 http://blog.csdn.net/sinat_26917383/article/details/63686786
32 http://blog.csdn.net/sinat_26917383/article/details/63682987
33 http://blog.csdn.net/sinat_26917383/article/details/63306206
34 http://blog.csdn.net/sinat_26917383/article/details/62891686这段代码可以复制下,其中我觉得最精髓的就是unlist的recursive使用~