【 NLP】如何减小预训练语言模型?
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
一、为什么减小预训练语言模型?
二、减小模型大小的方法
1、模型微调(Fine-tune)及具体实现
模型微调的pytorch实现
2、模型剪枝(Pruning)及具体实现
模型剪枝的Pytorch实现
3、模型量化及具体实现
模型量化的Pytorch实现
4、数据分块及具体实现
数据分块的Pytorch实现
5、模型压缩及具体实现
模型压缩的pytorch实现
6、模型蒸馏及具体实现
模型蒸馏的pytorch实现
三、减小预训练语言模型的前景
一、为什么减小预训练语言模型?
预训练语言模型可以通过大量的文本数据进行训练,从而学习到更多的语言规律和语义信息。但是,由于大规模的语言模型通常需要庞大的计算资源和存储容量,因此减小预训练语言模型的大小可以带来以下一些好处:
-
加速模型推理:减小模型的大小可以降低模型的计算复杂度,从而提高模型的推理速度,特别是在边缘设备和移动设备等有限计算资源的场景中。
-
减少存储空间:预训练语言模型经常需要大量的存储空间,减小模型的大小可以减少存储需求,从而节省成本或者增加存储容量。
-
适应低资源环境:使用较小的预训练语言模型可以适应低资源环境,例如机器翻译、语音识别和智能客服等领域,这些领域通常需要较高的精度和较快的响应速度,同时也需要满足资源有限的要求。
-
避免过拟合:较小的模型具有较强的泛化能力,在预测未知数据时表现更为优秀,同时对于大规模数据训练预训练语言模型时,会产生过拟合的问题,这时减小预训练语言模型大小也可以缓解这个问题。
需要注意的是,在减小预训练语言模型的大小时,需要保持较高的模型效果和精度。通常的做法是通过调整模型结构、使用低精度权重、剪枝或者量化等技术来实现。在选择减小预训练语言模型的大小时也需要综合考虑应用场景、数据规模和计算需求等因素。
二、减小模型大小的方法
下面是一些可以减小模型大小的方法:
-
Fine-tune:尝试在更小的数据集上用 大语言模型 进行 Fine-tune。Fine-tune 可以使模型更好地适应特定领域的数据,并且可以减小模型的大小。
-
剪枝:使用剪枝算法可以去除掉模型中不必要的连接、节点和参数等,从而减少模型的大小并提高模型的运行速度。具体的实现可以参考相关的文献或者开源库,例如 NVIDIA 的 TensorRT。
-
量化:将浮点数权重和激活值转换为定点数或者低精度浮点数可以减小模型的大小,并且可以提高模型的运行速度和内存使用效率。可以使用 PyTorch 提供的量化 API 或者其他量化框架来实现。
-
分块:将模型分块处理,只在需要的时候加载每个块的部分参数。这种方法可以减少模型在内存中的占用空间,并且可以加快模型的训练和推理速度。
-
压缩:使用压缩算法可以将模型的大小进一步压缩。常见的压缩算法包括打包、哈夫曼编码、LZW 算法等。可以使用 Python 提供的压缩库或者其他第三方压缩库来实现。
-
网络蒸馏:利用小模型和大模型之间的关系,将大模型中的知识“蒸馏”到小模型中,从而实现减小模型大小的目的。可以使用开源的网络蒸馏框架,例如 Hugging Face 的 DistilBERT。
请注意,例如对于 Randeng-Pegasus-238M-Summary-Chinese 这样的大型预训练模型,以上方法可能需要进行一定的调整和适应。具体的实现方案需要根据实际情况进行选择和调整。
1、模型微调(Fine-tune)及具体实现
Fine-tune,也称微调,是指在已经预训练好的模型基础上,针对特定任务进行进一步的训练和优化,以提高模型在该任务上的性能。Fine-tune 是 NLP 领域中常用的技术之一,通常用于文本分类、命名实体识别、语义相似度等各种自然语言处理任务中。
以下是 Fine-tune 的一般步骤:
-
选择预训练模型:首先选择一个与待解决任务相关的预训练模型。目前常用的预训练模型包括 BERT、GPT 和 XLNet 等。
-
准备数据集:接下来需要准备用于 Fine-tune 的数据集,该数据集应该与预训练模型目标领域相关。数据集的质量和数量都会影响 Fine-tune 的效果。
-
调整模型结构:Fine-tune 通常涉及到对预训练模型进行微调,在 Fine-tune 阶段通常会针对具体任务选择在预训练模型上添加一些新的网络层或者对现有的网络层进行修改,以适应具体任务的需求。
-
训练模型:利用 Fine-tune 数据集对调整后的模型进行训练,Fine-tune 阶段同时还需要设置一些新的超参数,例如学习率、batch size等。
-
模型评估:训练结束后,需要使用测试集对 Fine-tune 后的模型进行评估和调整。评估指标通常包括准确率、召回率、F1 值等。
-
部署应用:Fine-tune 阶段结束后,可以将 Fine-tune 后的模型部署到生产环境中。
需要注意的是,Fine-tune 的成功与否与数据集的质量、Fine-tune 数据集与预训练数据集的相似性、Fine-tune 阶段的超参数选择、迭代次数等因素都有关系,Fine-tune 过程中出现的过拟合等问题也需要进行调试和优化。
模型微调的pytorch实现
在 PyTorch 中,进行模型微调(fine-tuning)的一般流程如下:
- 加载预训练模型。
import torch.nn as nn
import torchvision.models as models
# 加载预训练模型
model = models.resnet18(pretrained=True)- 修改模型最后一层的输出,以适应新的任务。
# 替换最后一层全连接层
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, num_classes)其中,num_classes 表示新任务需要分类的类别数。
- 定义损失函数和优化器。
import torch.optim as optim
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)- 加载数据,进行训练。
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# 定义数据增强变换
transform_train = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = datasets.ImageFolder(traindir, transform_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# 训练模型
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()其中,traindir 表示数据集所在的路径,batch_size 表示每个 batch 的大小,num_epochs 表示训练的总轮数。
- 在测试集上进行评估。
# 定义测试集变换
transform_test = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载测试集
test_dataset = datasets.ImageFolder(valdir, transform_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 在测试集上进行评估
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))其中,valdir 表示测试集所在的路径,device 表示使用的设备(如 'cuda' 表示使用 GPU)。
需要注意的是,在微调模型时,可以根据具体情况调整学习率、数据增强方式等超参数,以及适时冻结前几层的参数等操作。
2、模型剪枝(Pruning)及具体实现
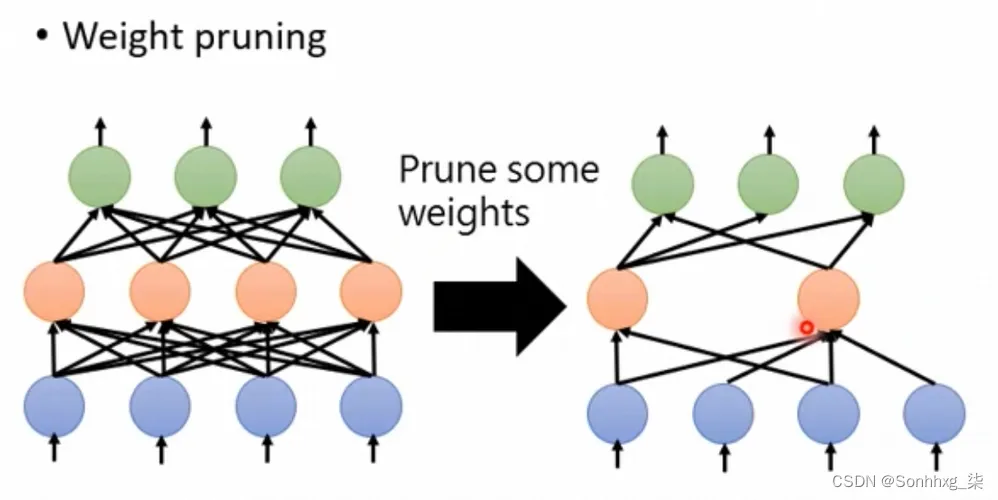
剪枝(Pruning)是一种用于减少神经网络模型参数数量的技术,其核心思想是将模型中不必要的连接、节点和参数等去除,从而减小模型的大小并提高模型的运行速度。下面介绍一下剪枝的具体实现方法。
1.首先需要定义一个剪枝策略,即如何判断哪些参数可以被剪枝。常见的剪枝策略有:
- Magnitude-based pruning:根据参数的大小来决定是否剪枝。例如,将参数按照绝对值大小排序,删除最小的若干个参数。
- Connection-based pruning:判断每个连接的重要性,去除权重值最小的连接或者在一定阈值内的权重。
- Structured pruning:按模块、层或其他结构分组,然后去除整个组或者组内部的参数。
2.在训练过程中,根据上述策略进行剪枝。这一过程通常包括以下步骤:
- 训练原始模型,得到初始的参数。
- 选择一定比例的参数进行剪枝。可以设置剪枝比例、剪枝阈值等超参数来控制剪枝程度。
- 剪枝之后,重新训练模型,保持剪枝前后的表现相近。
3.在剪枝之后,对于被剪枝的参数,可以将其设置为 0 或者使用平均值来填充。需要注意的是,在计算梯度时需要忽略这些参数,否则会对训练造成干扰。
4.为了避免过拟合,可以使用正则化方法来保持模型的泛化能力。常见的正则化方法有 L1 和 L2 正则化、Dropout 等。
需要特别注意的是,在剪枝之后,模型的复杂度会减小,但是模型的训练难度和效果可能会受到影响。因此,在进行剪枝时需要仔细控制剪枝的程度和剪枝策略,并且需要对剪枝前后的模型效果进行详细分析和比较。
模型剪枝的Pytorch实现
在 PyTorch 中,模型剪枝的一般流程如下:
- 加载预训练模型。
import torch.nn as nn
import torchvision.models as models
# 加载预训练模型
model = models.resnet18(pretrained=True)- 定义剪枝策略和剪枝比例。
import torch.nn.utils.prune as prune
# 设置全局剪枝参数
prune.global_unstructured(
parameters=model.conv1.parameters(),
pruning_method=prune.L1Unstructured,
amount=0.2,
)
# 进行剪枝
prune.l1_unstructured(model.layer1[0].conv1, name="weight", amount=0.5)其中,prune.L1Unstructured 表示使用 L1 正则化进行剪枝,amount 表示要剪枝掉的权重占比。
- 定义损失函数和优化器,进行微调。
import torch.optim as optim
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 微调模型
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每个 epoch 结束后,需要调用 remove() 函数,将剪枝的效果去掉。
for module in model.modules():
if isinstance(module, nn.Conv2d):
prune.remove(module, 'weight')其中,num_epochs 表示微调的总轮数。
需要注意的是,在实际使用中,还需要根据具体场景和需求进行选择和调整剪枝策略、剪枝比例等超参数。同时,在部署时,需要对剪枝后的模型进行测试和评估。
3、模型量化及具体实现

模型量化是一种将浮点数权重和激活值转换为定点数或者低精度浮点数的技术,其目的是减小模型的大小,并提高模型的运行速度和内存使用效率。在深度学习应用中,通常使用 32 位浮点数来表示模型的权重和激活值,这样可以获得较高的精度和可靠性,但是会占用大量的内存空间和计算资源。而通过量化技术,可以将权重和激活值转换为低位数的定点数或者浮点数,从而大大减少了内存占用和计算复杂度。
常见的模型量化方法包括:
-
定点数量化:将浮点数转换为定点数,可以减少存储空间和计算复杂度。通常使用的是 n 位定点数,其中 n 通常取 8 或者 16,可以根据实际需要进行调整。
-
浮点数量化:将浮点数转换为低精度浮点数,例如 8 位浮点数或者 4 位浮点数。此方法相对于定点数量化可以提供更高的精度。
-
混合精度量化:在网络中同时使用不同精度的数据类型,例如使用低精度浮点数表示激活值和梯度,使用高精度浮点数表示权重。这种方法可以在提高计算速度的同时减少模型的内存占用。
需要注意的是,量化技术对模型的精度、速度和存储空间都有一定的影响。通常情况下,在进行量化之前需要对模型进行 Fine-tune 或者微调,以保证量化后模型的性能达到预期。此外,不同的量化方法和参数选择对模型性能的影响也会有所不同,需要根据实际情况进行选择和调整。
模型量化的Pytorch实现
对于 PyTorch 中的模型量化,可以按照以下步骤进行实现:
- 加载预训练模型。
import torch.nn as nn
import torchvision.models as models
# 加载预训练模型
model = models.resnet18(pretrained=True)- 在数据集上进行 Fine-tuning。
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义数据增强变换
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
trainset = datasets.ImageFolder(traindir, transform=train_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(num_epochs):
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0其中,traindir 表示数据集所在的路径,batch_size 表示每个 batch 的大小,num_epochs 表示训练的总轮数。
- 定义量化配置。
import torch.quantization as quant
# 定义量化配置
quantization_config = quant.QConfig(activation=quant.MinMaxObserver.with_args(dtype=torch.qint8),
weight=quant.MinMaxObserver.with_args(dtype=torch.qint8)) 其中,activation=quant.MinMaxObserver.with_args(dtype=torch.qint8) 表示对激活值进行量化,并使用 8 位整型表示;weight=quant.MinMaxObserver.with_args(dtype=torch.qint8) 表示对权重进行量化,并使用 8 位整型表示。
- 进行模型量化。
# 使用动态量化进行模型量化
model.qconfig = quantization_config
torch.backends.quantized.engine = 'qnnpack'
model = quant.dynamic_quantization.convert_dynamic(model)
# 在数据集上进行测试
model.eval()
with torch.no_grad():
for data, target in testloader:
output = model(data)其中,torch.backends.quantized.engine = 'qnnpack' 表示使用 QNNPACK 引擎进行量化计算,quant.dynamic_quantization.convert_dynamic(model) 表示对模型进行动态量化,这样可以动态地调整量化参数,从而达到更好的量化效果。
- 在量化后的模型上进行推理。
# 在量化后的模型上进行推理
model = quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
model.eval()
with torch.no_grad():
for data, target in testloader:
output = model(data) 其中,quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8) 表示将模型的线性层量化为 8 位整数,并返回量化后的模型。
需要注意的是,使用模型量化后,可能会对模型的精度产生一定影响。可以在量化前后对模型进行测试,以评估精度损失情况,并根据需要进行优化。
4、数据分块及具体实现
在自然语言处理任务中,由于文本数据通常是变长的,为了使得模型能够处理这些变长数据,需要将数据进行分块处理。分块的方法通常有以下几种:
-
固定长度分块:将文本数据按照固定长度进行分块,例如指定每个块的长度为 128,将文本数据均匀地分为多个长度为 128 的块。这种方法简单易行,但可能会造成信息的丢失或冗余。
-
滑动窗口分块:在文本数据上设置一个固定大小的窗口,对于每个窗口内的文本数据进行处理。滑动窗口能够保证不漏掉文本数据,并且能够产生更多的输入输出对,但是窗口大小的选择需要进行权衡,如果窗口过大会导致序列过长,而过小则会造成信息丢失。
-
动态长度分块:根据文本数据的实际长度来动态地划分数据块,这种方法可以避免信息的丢失,但在计算时需要额外的计算成本。
-
段落分块:将文本数据按照段落进行分块,可以利用文本的语义表示,将一个段落作为一个数据块进行处理。这种方法能够保留文本的完整性和连续性,但需要考虑段落的划分方式。
需要根据具体的任务和模型选择适合的数据块分块方法,以达到最佳的效果。同时,在进行文本数据分块时还需要注意一些细节问题,例如滑动窗口大小、数据重叠度、边界处理等,这些都可能对模型的精度和效率产生影响。
数据分块的Pytorch实现
在 PyTorch 中,可以使用 torch.utils.data.random_split 函数对数据进行分块。具体实现步骤如下:
- 加载数据集。
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义数据增强变换
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
dataset = datasets.ImageFolder('path/to/dataset', transform=transform) 其中,'path/to/dataset' 表示数据集所在的路径,transform 表示数据增强变换。
- 对数据集进行分块。
from torch.utils.data import random_split
# 对数据集进行分块
train_size = int(0.8 * len(dataset)) # 训练集占 80%
val_size = len(dataset) - train_size # 验证集占 20%
train_dataset, val_dataset = random_split(dataset, [train_size, val_size]) 其中,train_size 表示训练集大小,val_size 表示验证集大小,[train_size, val_size] 表示对数据集按照指定大小进行分块,返回一个由 train_dataset 和 val_dataset 组成的列表。
- 创建数据加载器。
from torch.utils.data import DataLoader
# 创建训练集和验证集的数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)其中,batch_size 表示每个 batch 的大小,shuffle=True 表示是否对数据进行洗牌(在训练集中一般会洗牌,验证集和测试集则不用),train_loader 表示训练集的数据加载器,val_loader 表示验证集的数据加载器。
至此,使用 torch.utils.data.random_split 函数对数据集进行分块的具体实现就完成了。需要注意的是,在实际应用中,还需根据需求适当地调整参数,如修改数据增强变换、改变数据加载器的 batch_size 等。
5、模型压缩及具体实现
在自然语言处理任务中,对于文本数据的压缩通常是指减少模型输入所需要的字节大小,以提高模型的训练和推理效率。以下是几种常见的文本数据压缩方法:
-
词表剪枝:将出现次数较少的单词从词表中剔除,减小词表大小。这种方法可以有效降低数据量,并且能够快速地实现。
-
Quantization(量化):将浮点数表示的权重和激活值用较少的比特位进行表示,例如将 32 位浮点数转换为 8 位整数。这种方式能够大大降低模型的存储和计算开销,同时还能够加速模型的推理速度。
-
稀疏化:将模型中的冗余参数删除或设置为 0,以减小模型的大小。稀疏化通常需要根据模型的结构来进行设计和实现。
-
压缩算法:使用压缩算法对文本数据进行压缩,例如 gzip、bzip2 等。但是这种方式通常会增加解压缩的时间成本。
需要注意的是,各种文本数据压缩方法都有其优点和缺点,需要根据具体的任务和模型来选择合适的方法。同时,压缩后的数据也要注意对解压后的数据进行有效性检验,以保证压缩后的数据与原始数据的一致性。
模型压缩的pytorch实现
在 PyTorch 中,常用的模型压缩技术包括权重剪枝、参数量化、低秩分解等。以下是这些方法的一些简单实现方法:
(1)、权重剪枝
- 定义模型,并加载预训练模型。
import torch.nn as nn
import torchvision.models as models
model = models.resnet18(pretrained=True)- 使用 PyTorch 提供的
prune模块进行剪枝。可以使用 L1 或 L2 正则化,将小于阈值的权重剪枝掉。
import torch.nn.utils.prune as prune
# 设置全局剪枝参数
prune.global_unstructured(
parameters=model.conv1.parameters(),
pruning_method=prune.L1Unstructured,
amount=0.2,
)
# 进行剪枝
prune.l1_unstructured(model.layer1[0].conv1, name="weight", amount=0.5)- 前向传播计算时,剪枝后的模型可以通过调用
prune.remove()函数来去除剪枝的效果。
# 将模型恢复到未剪枝状态
prune.remove(model.layer1[0].conv1, 'weight')
# 计算前向传播
output = model(input)(2)、参数量化
- 定义模型,并加载预训练模型。
import torch.nn as nn
import torchvision.models as models
model = models.resnet18(pretrained=True)- 使用 PyTorch 提供的
quantization模块进行量化。可以使用量化参数(quantized)或量化感知训练(quantization-aware training)。
import torch.quantization as quantization
# 量化参数
quantization.quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)
# 量化感知训练
quantization aware training(QAT)是近年来提出的一种方法,通过在训练中加入量化误差的损失函数,使模型更好地适应量化后的硬件部署环境。- 可以通过调用
model.cpu()将模型从 GPU 移动到 CPU 上进行测试和保存。
model.cpu()
torch.save(model.state_dict(), 'quantized_model.pth')(3)、低秩分解
- 定义模型,并加载预训练模型。
import torch.nn as nn
import torchvision.models as models
model = models.resnet18(pretrained=True)- 使用第三方库,如 Tensorly,将卷积层分解为多个小的卷积核。
import tensorly as tl
from tensorly.decomposition import partial_tucker
# 将第一个卷积层分解为两个小的卷积核
tl.set_backend('pytorch')
model.conv1.weight.data = partial_tucker(model.conv1.weight.data, modes=[(0, 1, 2), (3,)], rank=[16, 32])- 可以通过调用
model.cpu()将模型从 GPU 移动到 CPU 上进行测试和保存。
model.cpu()
torch.save(model.state_dict(), 'decomposed_model.pth')需要注意的是,这只是一些简单的实现方法。在实际使用中,还需要根据具体场景和需求进行选择和调整。同时,压缩后的模型可能会对性能或精度造成一定的影响,在部署时需要进行测试和评估。
6、模型蒸馏及具体实现

在深度学习中,模型蒸馏(model distillation)是指通过一个较大的“教师模型”(teacher model)来训练一个较小的“学生模型”(student model)。这种方法通常用于减少模型大小和计算成本,并优化模型的性能。
以下是模型蒸馏的一般性步骤:
-
在大规模数据集上训练一个高精度的教师模型,例如使用 BERT、GPT 等预训练模型。
-
通过教师模型对训练数据集进行推理,并将输出结果作为“软标签”(soft label),即概率分布。这种方式比“硬标签”更加灵活,可以捕捉到更多的信息。
-
在相同的数据集上训练一个较小的学生模型,同时使用教师模型的输出结果作为额外的辅助训练目标。例如,可以在交叉熵损失函数中同时考虑真实的硬标签和教师模型的软标签,以提供更加丰富的监督信号。
-
在训练过程中,可以采用一些技巧来优化模型的性能和泛化能力,例如知识蒸馏(knowledge distillation)技术、温度缩放(temperature scaling)技术等。
-
最后,可以通过一些评价指标来评估学生模型的性能,例如准确率、召回率、F1 值等。
需要注意的是,模型蒸馏虽然能够在一定程度上优化模型性能,但也存在一些限制和问题,例如过度依赖教师模型、训练数据集不足、鲁棒性差等。因此,在进行模型蒸馏时需要加以注意,并根据具体情况进行选择和调整。
模型蒸馏的pytorch实现
在 PyTorch 中,模型蒸馏的实现通常可以分为以下几个步骤:
-
定义教师模型和学生模型。通常使用预训练的大型模型作为教师模型,例如 BERT、GPT 等。学生模型可以是一个轻量的模型,例如一个较小的神经网络。
-
定义数据集和数据加载器,与常规深度学习模型训练类似。
-
定义损失函数。对于模型蒸馏来说,一般使用交叉熵损失函数,并考虑到教师模型的输出结果。可以自定义一个损失函数来同时考虑教师模型的输出结果和真实标签,例如:
class DistillationLoss(nn.Module): def __init__(self, temperature=1.0): super().__init__() self.temperature = temperature def forward(self, student_outputs, teacher_outputs, targets): # 计算学生模型的交叉熵损失 student_loss = F.cross_entropy(student_outputs, targets) # 计算教师模型的 softmax 输出结果 teacher_probs = F.softmax(teacher_outputs / self.temperature, dim=1) # 计算 KL 散度损失,衡量学生模型和教师模型之间的差距 distill_loss = nn.KLDivLoss(reduction='batchmean')(F.log_softmax(student_outputs / self.temperature, dim=1), teacher_probs) # 将学生模型的交叉熵损失和 KL 散度损失结合起来 alpha = 0.5 # 可以自行调整权重 total_loss = alpha * student_loss + (1 - alpha) * distill_loss return total_loss其中,temperature 是一个超参数,用于控制蒸馏过程中的温度。
-
定义优化器和学习率调度器,与常规深度学习模型训练类似。
-
进行模型训练。在每个训练周期中,首先使用教师模型对训练数据集进行推理,并将输出结果作为软标签。然后,使用学生模型对训练数据集进行训练,并同时考虑真实标签和软标签,例如:
for inputs, labels in train_loader: # 使用教师模型进行推理 with torch.no_grad(): teacher_outputs = teacher_model(inputs) # 使用学生模型进行训练 student_optimizer.zero_grad() student_outputs = student_model(inputs) loss = distillation_loss(student_outputs, teacher_outputs, labels) loss.backward() student_optimizer.step() - 最后,进行模型测试和保存,与常规深度学习模型训练类似。
需要注意的是,在进行模型蒸馏时,还有一些技巧和超参数需要注意,例如软标签的温度、蒸馏过程中的权重调整、学习率和训练周期等。这些超参数需要根据具体情况进行选择和调整,以提升模型的性能。
三、减小预训练语言模型的前景
减小预训练语言模型的前景可能会对其性能产生负面影响和限制。
一方面,预训练语言模型(如BERT、GPT等)在大规模语料库上进行训练,可以学习到大量的语言知识和模式,并具备强大的语言理解能力和生成能力。但是,预训练语言模型需要消耗大量的计算资源和时间,且训练过程中需要使用大量的数据和正则化技术来防止过拟合。如果减小预训练语言模型的规模或训练数据量,可能会削弱其学习能力和泛化能力,从而导致性能下降。
另一方面,预训练语言模型可以应用于多种自然语言处理任务中,如文本分类、命名实体识别、机器翻译等。这些任务通常涉及不同的语言现象和语境,需使用大规模的数据集和高效的模型来获得良好的性能。如果减小预训练语言模型的规模或训练数据量,可能会限制其在各种任务上的应用范围和表现能力。
因此,建议在保证计算资源和时间充足的前提下,尽可能地使用大规模的语料库和优化方法来训练预训练语言模型,以获得更好的性能和应用效果。同时,可以通过在预训练语言模型上进行微调等方式,来适应不同的任务需求和场景。