RabbitMQ实战知识详细笔记,消息丢失,重复消费等问题解决方案。
| 源码(码云):https://gitee.com/yin_zhipeng/rabbit-mq-demo.git |
|---|
安装rabbitmq,可以参考,https://blog.csdn.net/grd_java/article/details/119696892,其它的内容没必要参考这篇文章
本文根据官方文档的6大模式,依次将知识点带出,比如工作模式中,多个消费者消费消息的消息丢失问题,可以通过手动应答解决。
文章目录
- 一、相关概念和介绍
-
- 1. 四大核心
- 2. 名词介绍
- 二、6大模式的前5个
-
- 1. 简单模式
- 2. 工作模式(解决消息丢失问题)
-
- 2.1 效果实现
- 2.2 消息应答机制和消息重新入队
- 2.3 消息应答机制改造
- 2.4 RabbitMQ持久化
- 2.5 不公平分发和预取值
- 2.6 发布确认
- 3. 发布/订阅模式
-
- 3.1 交换机
-
- 3.1.1 临时队列和绑定
- 3.1.2 fanout扇出类型交换机
- 4. 路由模式(direct直接类型交换机)
- 5. 主题模式(topic主题类型交换机)
- 三、死信队列
-
- 1 消息过期,消息被拒绝
- 2. 队列达到最大长度
- 四、spring boot整合
-
- 1. 延迟(延时)队列
-
- 7.1 延时队列案例
- 7.2 延迟队列的问题
- 五、spring boot发布确认模式
-
- 1. 和交换机的发布确认
- 2. 回退消息
- 3. 优先级队列,手动确认
- 六、拓展知识
-
- 1. 备份交换机
- 2. 幂等性
-
- 2.1 Redis原子性解决幂等性问题
- 3. 惰性队列
一、相关概念和介绍
应用场景
- 流量削峰:如果系统的处理能力无法满足用户的请求数量。可能会导致系统瘫痪。虽然可以当系统处理能力达到上限时,限制用户请求,让用户无法操作。此时消息队列可以做一个缓冲,让这些请求分散开排好队,依次的进行处理。但是消息队列会
- 应用解耦:消息队列可以异步的执行任务,比如要买菜,买肉,不用异步的话,需要先买肉,然后等肉切好,再去买菜。解耦后,先买肉,让肉先切着,我同时去买菜。如果菜买回来,肉没切完,那就等肉。如果肉腐烂了,坏了。那可以重新挑肉,或者直接退钱,回家告诉孩子,今天做不了饭,肉腐烂了。
- 异步处理:可以想象为,你在等水烧开的时候,顺便扫地。
常见MQ
- ActiveMQ
- 优点:单机吞吐量万级,时效性ms级,可用性高,基于主从架构实现高可用,消息可靠性较高(不容易丢失数据)
- 缺点:比较老了,官方社区(Apache)对ActiveMQ 5.x维护越来越少,高吞吐量场景使用较少。
- Kafka:为大数据而生,百万级TPS的吞吐量,让它在数据采集,传输,存储过程中发挥出色,被LinkedIn,Uber,Twitter,Netflix等大公司采纳。
- 优点:性能卓越,单机写入TPS约百万条/秒,吞吐量高。时效性ms级,可用性非常高(分布式,一个数据多个副本,少数机器宕机,不会数据丢失,或不可用),消息有序,通过控制可以保证所有消息被消费且仅被消费一次,日志领域比较成熟,功能较为简单,支持简单的MQ功能,大数据领域的实时计算和日志采集被大规模使用。
- 缺点:队列越多,load越高,消息发送响应时间越长,短轮询方式,实时性取决于轮询时间间隔,消费失败不支持重试,一台代理宕机,消息会乱序,社区更新慢。
- RocketMQ:阿里巴巴开源产品,Java实现,参考Kafka并改进,广泛应用与订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
- 优点:单机吞吐量十万级,可用性高,分布式架构,消息可以做到0丢失,功能较为完善,扩展性好,支持10亿级别消息堆积。
- 缺点:支持的客户端语言少,目前只有java和c++,c++不成熟,社区活跃度一般,没有在MQ核心中实现JMS等接口,系统要迁移,有些需要修改大量代码。
- RabbitMQ:2007年发布,基于AMQP(高级消息队列协议),可复用企业消息系统,当前最主流的消息中间件之一。
- 优点:erlang语言编写(因此高并发特性好,性能好,吞吐量万级),MQ功能比较完备,健壮,稳定,易用,跨平台,支持多种语言,支持AJAX文档齐全,管理界面好用,社区活跃度高,更新频率高。
- 缺点:贵,商业版需要收费,学习成本高。
1. 四大核心
- 生产者:就是生产消息的,也就是发快递的,消息可以想象为快递。
- RabbitMQ:也就是快递站,处理快递,具体邮寄到哪里
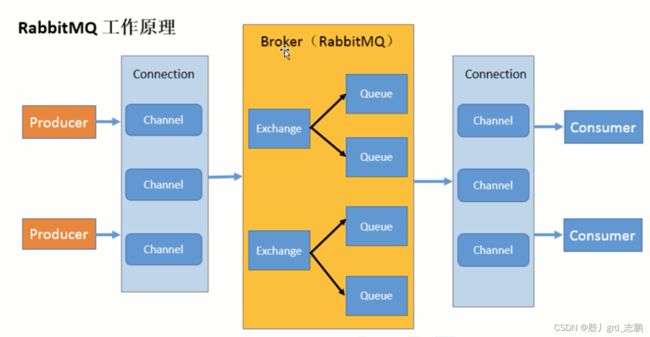
- 交换机:邮寄的策略管理,主要管理一张路由表,比如这个快递要发到北京东城区,它会匹配路由表,然后根据管理策略,找合适的快递员(队列)。比如:“我这里有个包裹,你们谁来邮寄配送一下?”,再比如“1号队列,你现在还能处理包裹吗?满了是吧!2号队列,你能吗?可以是吧?给你!!!”
- 队列:就是运输快递的快递员的车,它会将包裹交到消费者手里。交换机管理多个快递员,当然这些快递员需要是自己家的快递员(具有绑定关系的队列)。比如顺丰快递不能管人家韵达快递的快递员。
- 消费者:也就是等快递的你,快递来了,你自己处理,直接用了,或者回馈一些,评个论,退个货啥的。

2. 名词介绍
- Borker:就是RabbitMQ实体,接收和分发消息的应用。RabbitMQ Server就是Message Broker
- Virtual host:虚拟主机,多个不同用户使用同一个RabbitMQ server提供的服务时,可以划分多个vhost,每个用户在自己的vhost创建exchange/queue等。是出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似网络中的namespace概念。
- Connection:publisher/consumer和broker之间的TCP连接
- Channel:建立TCP连接开销很大,效率也低,Channel是TCP Connection内部建立的逻辑链接,多线程下,每个线程单独创建channel通讯(AMQP method中包含channel id帮助客户端和message broker识别channel),channel之间完全隔离,非常的轻量级。不用每次访问RabbitMQ都建立TCP connection。
- Exchange:message到达broker第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中,常用类型direct(点到点)、topic(发布-订阅)、fanout(广播)
- Queue:快递员的车,消息都在这里,等consumer消费者取走。
- Binding:exchange和queue之间的虚拟链接,也就是路由表,可以包含路由key(routing key)和Binding绑定信息,保存到exchange交换机的路由表中,用于message的分发依据
二、6大模式的前5个
1. 简单模式
整体架构为一个生产者P(Producer),消息队列(不用交换机,就用一个队列),和一个消费者C(consumer),效果就是P发给队列一个消息,C取一个消息
- 代码位置
- 模块依赖

<dependencies>
<!--rabbitMq依赖客户端-->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.7.3</version>
</dependency>
<!--操作文件流工具-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
- 生产者Producer代码:连接到mq,然后生成一个队列,然后把消息发送到队列即可
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.nio.charset.StandardCharsets;
/**
* 生产者
*/
public class Producer {
//交换机名词
public static final String EXCHANGE_NAME = "simpleExchange";
//队列名称
public static final String QUEUE_NAME = "simpleModel";
//路由key
public static final String ROUTING_KEY = "simpleRoutingKey";
//发消息
public static void main(String[] args) throws Exception {
//连接工厂,设计模式,可以方便我们进行配置
ConnectionFactory f = new ConnectionFactory();
//IP,连接RabbitMQ的队列,RabbitMQ是一个程序,我们需要连接使用它
f.setHost("127.0.0.1");
//用户名和密码,登录RabbitMQ的用户名和密码
f.setUsername("guest");
f.setPassword("guest");
//创建连接,根据工作原理,我们消费者和生产者都是通过连接,和MQ通信
Connection connection = f.newConnection();
//获取信道,根据工作原理,TCP连接不断开启关闭非常消耗资源,因此提供逻辑信道,连接一直建立(只建立一次),而Producer和Consumer每次连接MQ都通过信道,提高效率
Channel channel = connection.createChannel();
/**
* 跳过交换机直接生成队列
* Params:参数
* queue – the name of the queue队列名
* durable – true if we are declaring a durable queue (the queue will survive a server restart)
* true表示声明持久队列,重启mq后,队列依然存在,但是队列里面的数据,不会持久化
* 默认为false,存储在内存中
* exclusive – true if we are declaring an exclusive queue (restricted to this connection)
* true表示声明独占队列,这个队列只属于此连接,不可以有多个消费者进行消费
* autoDelete – true if we are declaring an autodelete queue (server will delete it when no longer in use)
* true表示当队列不再使用(最后一个消费者断开连接),将自动删除队列,
* arguments – other properties (construction arguments) for the queue
* 队列其它属性(构造参数),比如延迟消息等,是后面难度更高的内容
*/
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
/**
* 发布消息----注意routingKey,简单模式中,没有交换机,routingKey就是队列名字
* Params: 参数
* exchange – the exchange to publish the message to 要发送消息的交换机
* routingKey – the routing key 路由key
* XXXX一般不配置此项 mandatory – true if the 'mandatory' flag is to be set
* true表示强制的,一般不会配置此项
* XXXX一般不配置此项 immediate – true if the 'immediate' flag is to be set. Note that the RabbitMQ server does not support this flag.
* true表示立刻及时的,注意RabbitMQ不支持此标签,一般不进行配置
* props – other properties for the message - routing headers etc
* 消息的其它参数,路由报头等
* body – the message body 发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME,null,"消息".getBytes(StandardCharsets.UTF_8));
System.out.println("消息发送完毕!!!");
}
}
- 消费者Consumer代码:连接到mq,指定队列,然后消费消息即可。
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Delivery;
/**
* 消费者
*/
public class Consumer {
//交换机名词
public static final String EXCHANGE_NAME = "simpleExchange";
//队列名称
public static final String QUEUE_NAME = "simpleModel";
//路由key
public static final String ROUTING_KEY = "simpleRoutingKey";
//消费消息
public static void main(String[] args) throws Exception {
//连接工厂,设计模式,可以方便我们进行配置
ConnectionFactory f = new ConnectionFactory();
//IP,连接RabbitMQ的队列,RabbitMQ是一个程序,我们需要连接使用它
f.setHost("127.0.0.1");
//用户名和密码,登录RabbitMQ的用户名和密码
f.setUsername("guest");
f.setPassword("guest");
//创建连接,根据工作原理,我们消费者和生产者都是通过连接,和MQ通信
Connection connection = f.newConnection();
//获取信道,根据工作原理,TCP连接不断开启关闭非常消耗资源,因此提供逻辑信道,连接一直建立(只建立一次),而Producer和Consumer每次连接MQ都通过信道,提高效率
Channel channel = connection.createChannel();
/**
* 消费消息
* Params:
* queue – the name of the queue 队列名
* autoAck – true if the server should consider messages acknowledged once delivered; false if the server should expect explicit acknowledgements
* ture表示自动应答,也就是消息成功发送后,自动应答,确认消费成功。false表示不自动应答,需要手动进行应答,实战都是手动应答的。
* 如果消息丢失情况出现,需要我们进行逻辑处理后,手动进行应答,告诉人家失败了,如果自动应答我们就没办法控制了
* deliverCallback – callback when a message is delivered
* 回调(建立上下文),消费者成功接收到消息
* 一个函数式接口,需要匿名内部类,jdk1.8后,可以使用lambda表达式
* cancelCallback – callback when the consumer is cancelled
* 回调,消费者取消消费的回调
* 一个函数式接口,需要匿名内部类,jdk1.8后,可以使用lambda表达式
*/
channel.basicConsume(QUEUE_NAME, true, (String consumerTag, Delivery message) -> {
System.out.println("消费者消费成功!!!"+consumerTag+"----------------消息为:"+new String(message.getBody()));
}, (String consumerTag) -> {
System.out.println("消费者取消消费或被中断!!!"+consumerTag);
});
}
}
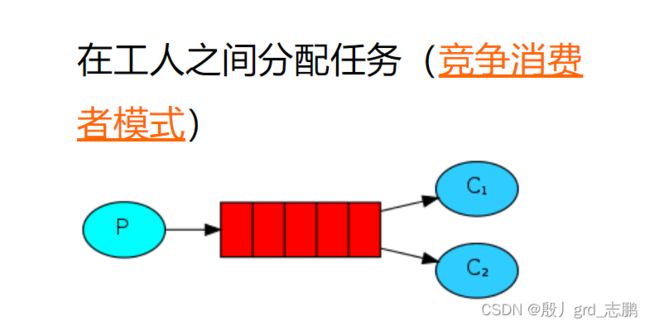
2. 工作模式(解决消息丢失问题)
整体架构为一个Producer生产者,一个队列,多个Consumer消费者。整体效果为,P生产多个消息到队列,C抢夺消息进行消费,实现多个线程C同时处理队列中的消息,节省时间。注意:多个C之间是竞争关系,队列中消息每个只能处理一次,多个C采用轮询的策略,依次处理队列中消息(如果一共就两个消费者C1和C2.那么C1先处理一个,然后C2处理,然后再C1处理,以此类推)。搞一个工具类,用来获取channel信道

import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
/**
* 封装建立RabbitMq连接工厂的工具类
*/
public class RabbitMqUtils {
//交换机名词
public static final String EXCHANGE_NAME = "workQueuesExchange";
//队列名称
public static final String QUEUE_NAME = "workQueuesModel";
//路由key
public static final String ROUTING_KEY = "workQueuesRoutingKey";
//得到一个channel
public static Channel getChannel() throws Exception{
//连接工厂,设计模式,可以方便我们进行配置
ConnectionFactory f = new ConnectionFactory();
//IP,连接RabbitMQ的队列,RabbitMQ是一个程序,我们需要连接使用它
f.setHost("127.0.0.1");
//用户名和密码,登录RabbitMQ的用户名和密码
f.setUsername("guest");
f.setPassword("guest");
//创建连接,根据工作原理,我们消费者和生产者都是通过连接,和MQ通信
Connection connection = f.newConnection();
//获取信道,根据工作原理,TCP连接不断开启关闭非常消耗资源,因此提供逻辑信道,连接一直建立(只建立一次),而Producer和Consumer每次连接MQ都通过信道,提高效率
Channel channel = connection.createChannel();
return channel;
}
}
2.1 效果实现
- 代码位置
- 生产者代码:生产多条消息到队列

import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/**
* 生产者
*/
public class Producer {
//发消息
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
/**
* 跳过交换机直接生成队列
*/
channel.queueDeclare(RabbitMqUtils.QUEUE_NAME,true,false,false,null);
/**
* 发布消息
*/
Scanner scanner = new Scanner(System.in);
while(true){
String msg = scanner.nextLine();
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME,null,msg.getBytes(StandardCharsets.UTF_8));
System.out.println("消息\""+msg+"\"发送完毕!!!");
}
}
}
- 消费者代码,多个消费者消费消息

import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
/**
* 消费者,这里用两个线程代表两个消费者工作线程
*/
public class Consumer {
public static void main(String[] args) {
Thread[] threads = new Thread[2];
for (int i = 0; i < 2; i++) {
int finalI = i;
threads[i]=
new Thread(new Runnable() {
@Override
public void run() {
try {
Channel channel = RabbitMqUtils.getChannel();
System.out.println(Thread.currentThread()+"正在等待接收消息!!!!");
channel.basicConsume(RabbitMqUtils.QUEUE_NAME, true,(consumerTag, message) -> {
System.out.println("线程"+finalI +"消费者消费成功!!!"+consumerTag+"----------------消息为:"+new String(message.getBody()));
} , consumerTag -> {
System.out.println("线程"+finalI+"消费者取消消费或被中断!!!"+consumerTag);
});
} catch (Exception exception) {
exception.printStackTrace();
}
}
});
}
for (int i = 0; i < 2; i++) {
threads[i].start();
}
}
}
2.2 消息应答机制和消息重新入队
RabbitMQ引入了消息应答机制,Producer接收到消息并且处理该消息之后,告诉RabbitMQ已经处理了,RabbitMQ可以把该信息删除。
如果某个消费者消费一个消息A时,中间出现错误,而自动应答策略下,RabbitMQ传递消息后,立即就会将消息标记为删除。此时,消息A将丢失,Producer没有成功消费消息A。此时,RabbitMQ再次发送消息B给它,还会发生同样的状况,是很严重并且非常常见的消息队列问题。
自动应答
消息发送成功,立即认为传送成功。这种方式吞吐量较高,但是数据传输安全性低。当消息发送成功,但是Producer消费者连接或channel关闭或者其它原因没有接收消息。那么消息就丢失了。Producer也没有对消息数量限制,可能消息太多,造成消息积压,使内存耗尽,从而被操作系统杀死进程,此模式适合在Producer可以高效并以某种速率处理这些消息,并且对消息可靠性要求不高的情况下使用。
手动应答:类似TCP的三次握手,发ACK确认包。
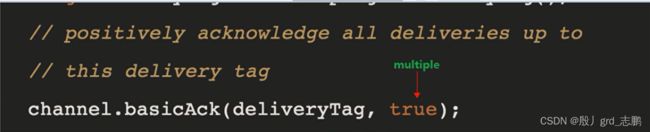
- 肯定确认:Channel.basicAck()。RabbitMQ将知道该消息处理成功,可以将其丢弃。
- 否定应答:Channel.basicNack()。代表处理失败,不可以丢弃。
- 拒绝,驳回:Channel.basicReject()。代表不处理该消息了,可以将其丢弃。
basicNack()和basicReject()的区别是前者多一个参数Multiple,可以批量应答。basicAck()也可以批量应答。减少网络堵塞。批量应答的效果是针对channel信道的,整个channel信道的所有消息,都会批量的一次性进行应答。
- true:表示批量应答channel上未应答的消息,比如channel上有传送tag的消息5,6,7,8。当前处理的tag是8。那么此时如果basicAck()进行批量应答,5-8这些没有应答的消息,都会被确认收到消息应答。
- false:也就是不批量应答,当前处理tag是8,就只会应答8这个tag。5-7这三个消息依然不会被应答。
所以,建议,使用手动应答,并且不要使用批量应答,对每一个消息,单独进行处理。
消息自动重新入队
如果消息没有发送ACK确认,RabbitMQ将认为消息没有完全处理,会将其重新排队,其它消费者如果可以处理,将很快分发给另一个消费者。

2.3 消息应答机制改造
代码位置:
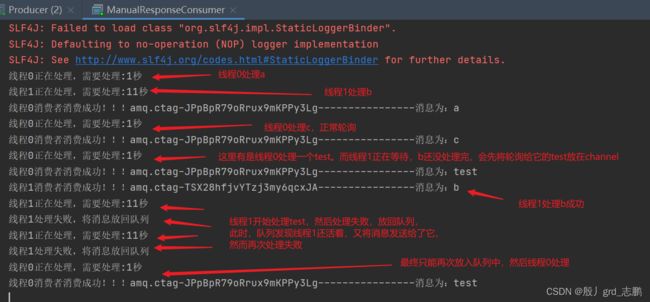
实现效果:线程0可以处理所有消息,需要1秒时间,线程1需要11秒时间,遇到消息test会处理失败,进行拒绝应答。线程1处理失败的消息,重新进入队列,让消费者进行处理。
- Producer代码:依次发送消息a,b,c,test,test,那么根据轮询,线程1处理时间会很长,它的channel中会堆积一些消息。


import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
/**
* 测试手动应答的生产者
*/
public class Producer {
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
channel.queueDeclare(RabbitMqUtils.QUEUE_NAME,true,false,false,null);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
String msg = null;
while((msg=bufferedReader.readLine())!=null){
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME,null,msg.getBytes(StandardCharsets.UTF_8));
System.out.println("消息\""+msg+"\"发送完毕!!!");
}
}
}
- Consumer代码:实现尽管线程1处理消息失败,消息也不会丢失
import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
/**
* 手动应答的Consumer
*/
public class ManualResponseConsumer {
public static void main(String[] args) throws Exception {
Thread[] threads = new Thread[2];
for (int i = 0; i < 2; i++) {
int finalI = i;
threads[i]=
new Thread(new Runnable() {
@Override
public void run() {
try {
Channel channel = RabbitMqUtils.getChannel();
channel.basicConsume(RabbitMqUtils.QUEUE_NAME, false,(consumerTag, message) -> {
try {
System.out.println("线程"+finalI+"正在处理,需要处理:"+(finalI*10+1)+"秒");
//第一个线程沉睡1秒,模拟处理时间较短的情况
//第二个线程沉睡11秒,模拟处理时间较长的情况
Thread.sleep(1000+1000*(finalI*10));
} catch (InterruptedException e) {
e.printStackTrace();
}
//模拟第二个工作线程,处理时出错的场景
if(finalI==1&&new String(message.getBody()).equals("test")){
/**
* Params:
* deliveryTag – the tag from the received AMQP.Basic.GetOk or AMQP.Basic.Deliver
* tag:message.getEnvelope().getDeliveryTag()
* multiple – true to reject all messages up to and including the supplied delivery tag; false to reject just the supplied delivery tag.
* true表批量处理
* requeue – true if the rejected message(s) should be requeued rather than discarded/dead-lettered
true表示不丢弃,回放到队列中
*/
channel.basicNack(message.getEnvelope().getDeliveryTag(),false,true);
System.out.println("线程"+finalI+"处理失败,将消息放回队列");
return;
}
System.out.println("线程"+finalI +"消费者消费成功!!!"+consumerTag+"----------------消息为:"+new String(message.getBody()));
/**
* 手动应答
* tag:message.getEnvelope().getDeliveryTag()
* 是否批量:false表示不批量
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
} , consumerTag -> {
System.out.println("线程"+finalI+"消费者取消消费或被中断!!!"+consumerTag);
});
} catch (Exception exception) {
exception.printStackTrace();
}
}
});
}
for (int i = 0; i < 2; i++) {
threads[i].start();
}
}
}
2.4 RabbitMQ持久化
RabbitMQ服务宕机后,Producer生产到队列中的消息默认会被RabbitMQ忽视,消失在大海之中。我们可以告诉RabbitMQ,持久化这些东西。只需要让它将队列和消息都标记为持久化。
队列持久化:只需要设置durable参数为true即可。但是已经声明为非持久化的队列,此时修改durabel为true会报错,需要删除队列后,重新创建。


消息持久化:前面只是持久化了队列,队列里面的消息数据,是不会持久化的。如果想要消息持久化,Producer生产者发布消息时,需要指定额外参数。
注意:这个只是简单场景可以用一用,不保证能100%持久化,比如发的时候,消息队列挂了。如果需要强有力的持久化,需要用到发布确认。这个后面介绍。
/**
* 标记消息持久化
* MessageProperties.PERSISTENT_TEXT_PLAIN
*/
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes(StandardCharsets.UTF_8));
2.5 不公平分发和预取值
| 不公平分发 |
|---|
前面我们用的都是轮询分发,你一条他一条。但是类似上面的线程0处理只需要1秒,线程1需要11秒这种场景,就不适合轮询分发。
- 不公平分发:不是公平的轮询了,而是只要你闲着,我就让你干活。能者多劳,你干的快你就多干点。不让你闲着。而正在干活的,会告诉队列,我没时间,你先别给我消息。
- 推荐采用不公平分发,充分利用每一台机器的性能,不让它闲着。
- 但是要考虑队列被撑满的问题,都正在干活,都不接受消息到channel,那么消息生产的过多,队列会被撑满。可以考虑增加Consumer工作线程
//channel.basicOos(1);表示不公平分发策略
//0:就是默认的,轮询
int perfetchCount = 1;
channel.basicOos(perfetchCount);

| 预取值 |
|---|
说白了就是往channel预取特定数量的消息,一定程度上缓解不公平分发,队列中消息堆积过多的问题
使用方法和不公平分发一样,取值0是轮询,1是不公平,2,3,4,5…这些值就是一个消费者的预取值所以,不公平分发,其实就是预取值1个的一种模式

//channel.basicOos(1);表示不公平分发策略
//0:就是默认的,轮询
//channel.basicOos(2);//表示预取值2个
int perfetchCount = 2;
channel.basicOos(perfetchCount);
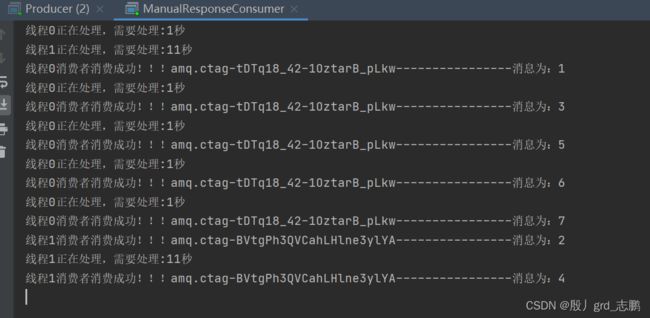
下面是预取两个的效果:可见,线程1处理了两个消息,线程0还是能者多劳
2.6 发布确认
想要完整持久化,单单开启队列和消息持久化是不行的,如果消息还没持久化完成,就宕机了,那么生产者Producer是不知道这个消息还没有持久化完成的。依然会发生消息丢失的问题
因此,生产者应该发布消息,等待MQ回复确认后,才确定消息发布成功
| 单个确认发布,这种方式很慢,不推荐 |
|---|
同步确认方式,也就是发一条,就等着MQ回复确认信息(失败或者成功),多会收到了,多会继续向下运行,发布下一条消息。
- 在发消息之前开启发布确认:channel.confirmSelect();//开启发布确认
- 发消息之后,进行等待:channel.waitForConfirms();//等待消息确认
/**
* durable = true表示持久化队列
*/
channel.queueDeclare(RabbitMqUtils.QUEUE_NAME,true,false,false,null);
// ** 开启发布确认
channel.confirmSelect();
/**
* 标记消息持久化
* MessageProperties.PERSISTENT_TEXT_PLAIN
*/
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes(StandardCharsets.UTF_8));
// ** 等待消息确认
boolean flag = channel.waitForConfirms();
if(flag){
System.out.println("消息\""+msg+"\"发送完毕!!!");
}else {
System.out.println("消息\""+msg+"\"发送失败!!!");
}
| 批量确认发布,不推荐!!!通过代码进行优化上面的单个确认方案,提高效率,但是一旦发生故障,会不知道哪个消息出现问题。原来是发一个确认一个,这个是发一堆确认一次。 |
|---|
和单个却不同的是,用一个for循环标记发了多少条,当到一定量时,进行一次确认
for(Integer i = 1;i<=1000;i++){
//发消息
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,(i+"").getBytes(StandardCharsets.UTF_8));
//每100条确认一次
if(i%100==0){
boolean flag = channel.waitForConfirms();
if(flag){
System.out.println("批量发送完毕!!!");
}else {
System.out.println("批量发送失败!!!");
}
}
}
| 异步确认发布,性价比高,可靠性和效率都高,利用回调函数达到消息可靠性传递,保证是否投递成功。 |
|---|
RabbitMQ有一个监听器,进行监听哪些消息发送成功,哪些失败
- ackCallback回调,确认收到时,RabbitMQ会回调它
- nackCallback回调,没有确认收到时,RabbitMQ会回调它
监听到后,如果有发布失败的消息,nackCallback将被RabbitMQ异步回调,我们可以将其添加到一个容器中,标识为没有成功发布的消息,以便重新发布
- 我们可以使用一个Map集合,key为发布消息的序号,channel.getNextPublishSeqNo()方法可以提供一个Long类型的序号(注意它是下一个的序号,当前的需要-1)。值为消息。
但是要注意,Producer生产者是一个线程,而监听器是异步的另一个线程,这里使用的容器,是多个线程同时使用,会有并发问题。因此需要用线程安全的容器,比如ConcurrentSkipListMap推荐的一种做法是,每条发布的消息,都直接记录在容器,当确认收到回调时,将确认的消息,从容器中删除
但是要注意,判断一下是否是批量消息,如果是批量消息,要删除的不是一个。
另外,监听器要放到发消息代码的最上面,假设你的发布消息代码在for循环里面,监听器要在for循环外,这样这一个监听器才能监听for循环里面所有的消息。如果放在for循环里面,就会出错。

package com.yzpnb.rabbitmq.manual_response;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.ConcurrentNavigableMap;
import java.util.concurrent.ConcurrentSkipListMap;
/**
* 测试手动应答的生产者
*/
public class Producer {
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
/**
* durable = true表示持久化队列
*/
channel.queueDeclare(RabbitMqUtils.QUEUE_NAME,true,false,false,null);
//开启发布确认
channel.confirmSelect();
//异步发布确认需要用的容器,存储所有已经发布,但没有确认的消息,如果确认成功,删除消息。最终,将没成功的消息重新发送
ConcurrentSkipListMap<Long, String> map = new ConcurrentSkipListMap<>();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
String msg = null;
/**
* 异步发布确认,监听器
*/
channel.addConfirmListener((deliveryTag, multiple) -> {
//确认成功的回调,将容器中元素删除
//批量的要批量删除
if(multiple){
ConcurrentNavigableMap<Long, String> confirmed = map.headMap(deliveryTag);
confirmed.clear();
}else{
map.remove(deliveryTag);
}
System.out.println("得到成功确认的消息:"+deliveryTag);
},(deliveryTag, multiple) -> {
//确认失败的回调
System.out.println("得到失败确认的消息:"+map.get(deliveryTag));
});
while((msg=bufferedReader.readLine())!=null){
/**
* 标记消息持久化
* MessageProperties.PERSISTENT_TEXT_PLAIN
*/
channel.basicPublish("",RabbitMqUtils.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes(StandardCharsets.UTF_8));
//将发布的还没有确认的消息,放入容器中
map.put(channel.getNextPublishSeqNo()-1,msg);
// ** 等待消息确认 --- 同步的,单个确认
// boolean flag = channel.waitForConfirms();
// if(flag){
// System.out.println("消息\""+msg+"\"发送完毕!!!");
// }else {
// System.out.println("消息\""+msg+"\"发送失败!!!");
// }
System.out.println("消息\""+msg+"\"发送完毕!!!");
/**
* @TODO 消息发送完毕后,记得将容器中的失败消息重新发送
*/
}
}
}
3. 发布/订阅模式
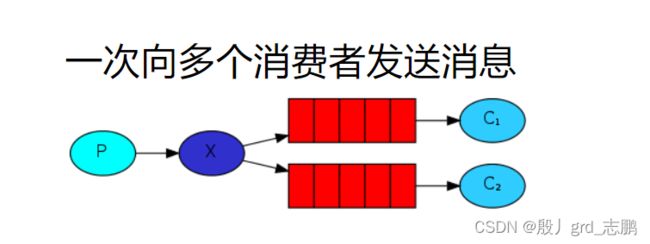
整体架构为一个Producer生产者,一个交换机,多个队列,多个Consumer。我们知道一个队列的每个消息都只能被消费一次。假设现在需要发送消息,是一个id号,需要异步记录这个id访问了网站,并且异步的给id加载一些信息。那么此时,两个消费者都需要拿到这个消息,一个队列肯定无法满足要求,因为消息只能被消费一次
- 那么就需要将同一个消息发送给多个队列,而队列中消息,还是只能消费一次
- 此时就需要交换机了,而交换机需要和队列进行绑定。可以理解为,这些队列(快递小哥)是属于这个交换机(这就快递公司)的。
- 绑定时,是通过RoutingKey来进行绑定的。可以理解为发快递的地址或路由表,目的是让消息(快递)去到对应的队列(快递小哥手里)。
3.1 交换机
RabbitMQ核心思想就是,
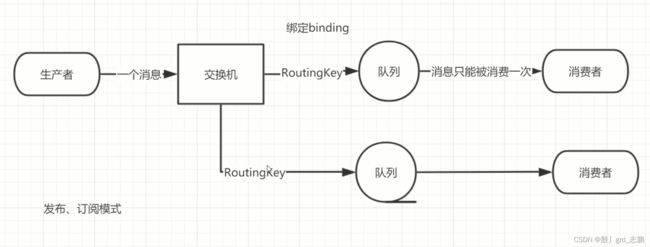
Producer生产的消息从不直接发送到队列(前面我们没有指定交换机,其实是走的默认交换机direct类型),生产者只能将消息发送给交换机。交换机的任务就是接收消息,然后将他们按照规则,进行处理。而这些消息到底是放在特定队列,还是放到许多队列,或者是丢弃它们,需要由交换机类型来决定。我们前面的代码,发布消息时,只指定交换机名称和路由Key,不会指定要发到哪个队列
交换机的类型:direct直接,topic主题,headers标题/首部,fanout扇出
direct直接类型,是默认交换机的类型(注意是默认交换机的类型,不是说direct就是默认交换机),我们可以通过""空字符串来直接使用默认交换机。这个交换机的routingKey就是队列名称(direct类型交换机的特性,后面讲)。
上面的代码,指定交换机为""那就是默认交换机,默认交换机的路由key就是队列名"hello"就是路由key

系统自带交换机:就是系统自己根据上面几种类型创建的,我们一般只在学习过程中使用它们,实际开发中,我们都是自己根据类型进行创建
上图中就是系统自带的交换机,Type一栏中显示的就是交换机的类型。
3.1.1 临时队列和绑定
临时队列,正如其名,就是个临时的,用完了自动删除的队列(我们前面声明的队列都设置了durable为true持久化,autoDelete为false不自动删除,因此它们不是临时队列)。可以做限流等等。存在于内存中。比如一个一旦消费者断开连接,队列立即就会被自动删除的队列。
比如一个和Consumer消费者绑定的队列,创建方式,也是通过代码创建,创建后在web页面的样子如下:有随机名字,Features标签为AD和EXCL
创建临时队列的方法

//会返回随机生成队列的名称
String queueName = channel.queueDeclare().getQueue();
绑定,就是交换机和队列的绑定关系,用一个RoutingKey来标识,不过这也看交换机类型,比如fanout类型交换机会广播消息给所有队列,无关RoutingKey的事。
比如direct类型交换机绑定了两个队列,队列1使用RoutingKey为1,队列2用RoutingKey为2。此时,Producer发送消息时,指定了这个交换机,并指定RoutingKey为1,那么这条消息只会发送给队列1,不会给队列2。
3.1.2 fanout扇出类型交换机
将接收到的所有消息,
广播给它知道的所有队列中(无论绑定什么routingKey)。
代码位置
- 封装一个工具类,提供交换机名,路由key,交换机类型

import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
/**
* 封装建立RabbitMq连接工厂的工具类
*/
public class RabbitMqUtils {
//交换机名词
public static final String EXCHANGE_NAME = "publishSubScribeExchange";
//队列名称
public static final String QUEUE_NAME = "publishSubScribeModel";
//路由key
public static final String ROUTING_KEY = "publishSubScribeRoutingKey";
//交换机类型direct直接,topic主题,headers标题/首部,fanout扇出
public static final String DIRECT = "direct";
public static final String TOPIC = "topic";
public static final String HEADERS = "headers";
public static final String FANOUT = "fanout";
//得到一个channel
public static Channel getChannel() throws Exception{
//连接工厂,设计模式,可以方便我们进行配置
ConnectionFactory f = new ConnectionFactory();
//IP,连接RabbitMQ的队列,RabbitMQ是一个程序,我们需要连接使用它
f.setHost("127.0.0.1");
//用户名和密码,登录RabbitMQ的用户名和密码
f.setUsername("guest");
f.setPassword("guest");
//创建连接,根据工作原理,我们消费者和生产者都是通过连接,和MQ通信
Connection connection = f.newConnection();
//获取信道,根据工作原理,TCP连接不断开启关闭非常消耗资源,因此提供逻辑信道,连接一直建立(只建立一次),而Producer和Consumer每次连接MQ都通过信道,提高效率
Channel channel = connection.createChannel();
return channel;
}
}
- Producer生产者:指定使用fanout交换机,路由key指定或者不指定都可以,因为它会广播给所有绑定的队列,但是不在这里创建队列。正常发送消息。

import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.ConcurrentSkipListMap;
/**
* Fanout交换机
* 生产者
*/
public class Producer {
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
//声明交换机,类型为fanout
/**注意:如果交换机已经存在(比如消费者先创建了),重复创建可能会报错,需要注释下面的代码,或者进行异常处理**/
/**
* Params:
* exchange – the name of the exchange 交换机名
* type – the exchange type 交换机类型
* durable – true if we are declaring a durable exchange (the exchange will survive a server restart)
* 可省略,是否持久化交换机
* autoDelete – true if the server should delete the exchange when it is no longer in use
* 可省略,是否临时交换机
* arguments – other properties (construction arguments) for the exchange
* 其它参数
*/
channel.exchangeDeclare(RabbitMqUtils.EXCHANGE_NAME,RabbitMqUtils.FANOUT);
//这里因为统一使用Consumer的临时队列,我们就不自己声明队列了。
//发布确认
channel.confirmSelect();
//容器
ConcurrentSkipListMap<Long, String> map = new ConcurrentSkipListMap<>();
//监听器
channel.addConfirmListener((deliveryTag, multiple) -> {
System.out.println("得到成功确认的消息:"+map.get(deliveryTag));
if(multiple == true)
map.headMap(deliveryTag).clear();
else
map.remove(deliveryTag);
}, (deliveryTag, multiple) -> {});
//循环接收消息
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
String msg = null;
while ((msg = bufferedReader.readLine())!=null){
//发送到指定交换机,并指定routingKey,开启消息持久化
channel.basicPublish(RabbitMqUtils.EXCHANGE_NAME,RabbitMqUtils.ROUTING_KEY, MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes(StandardCharsets.UTF_8));
map.put(channel.getNextPublishSeqNo()-1,msg);
System.out.println("消息\""+msg+"\"发送完毕!!!");
// @TODO 发送失败的消息处理
}
}
}
- 消费者:两个消费者全部创建自己的临时队列,将队列绑定在交换机,路由key指定不指定都可以。和Producer是完全相同的交换机即可。队列每个消费者持有一个。根据fanout交换机的特性,它会广播给所有绑定的队列,那么两个消费者将收到同一条消息,就算routingKey不一样。

import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
/**
* Fanout交换机
* 消费者
*/
public class Consumer {
public static void main(String[] args) throws Exception {
//一个Consumer对应一个临时队列(都不同),绑定的交换机和RoutingKey都一样
for (int i = 0; i < 2; i++) {
int finalI = i;
new Thread(new Runnable() {
@Override
public void run() {
try {
Channel channel = RabbitMqUtils.getChannel();
//声明交换机,类型为fanout
/**注意:如果交换机已经存在(比如生产者先创建了),重复创建可能会报错,需要注释下面的代码,或者进行异常处理**/
channel.exchangeDeclare(RabbitMqUtils.EXCHANGE_NAME,RabbitMqUtils.FANOUT,false,true,null);
//建立一个临时队列,不指定参数的话,就是会自动删除,不持久化的临时队列
String queueName = channel.queueDeclare().getQueue();
//开启不公平分发
channel.basicQos(2);
/**将队列绑定到交换机
* Params:
* queue – the name of the queue 要绑定的队列名
* exchange – the name of the exchange 要绑定的交换机
* routingKey – the routing key to use for the binding
*/
channel.queueBind(queueName,RabbitMqUtils.EXCHANGE_NAME,RabbitMqUtils.ROUTING_KEY);
//接收消息,不自动应答
channel.basicConsume(queueName,false,(consumerTag, message) -> {
System.out.println("线程"+finalI +"消费成功:"+new String(message.getBody()));
//手动应答,不批量应答
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
},consumerTag -> {});
} catch (Exception exception) {
exception.printStackTrace();
}
}
}).start();
}
}
}
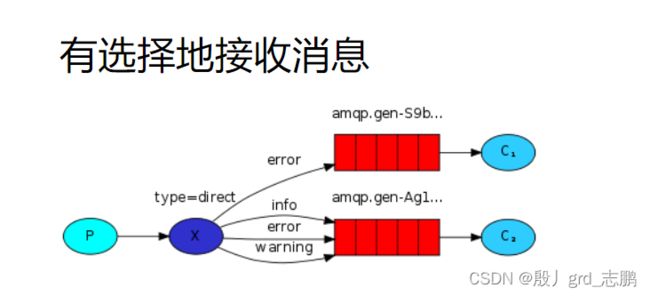
4. 路由模式(direct直接类型交换机)
direct直接交换机,和fanout不同,它不会广播,而是根据routingKey进行消息转发到相应队列,说白了,交换机会将消息会发送给绑定在自己身上,routingKey对应的队列。
代码位置
- Producer生产者:正常生产消息,指定routingKey。代码和fanout的Producer唯一不同的地方,就是交换机类型变了


//声明direct类型交换机,临时的,autoDelete参数为true,断开连接就会自动删除
channel.exchangeDeclare(RabbitMqUtils.EXCHANGE_NAME, BuiltinExchangeType.DIRECT,false,true,null);
- Consumer消费者:共三个线程,前两个线程和Producer绑定一样的RoutingKey,最后一个线程绑定RoutingKey为test。效果就是前两个线程可以同时收到消息,最后一个线程RoutingKey不一样,收不到消息。
5. 主题模式(topic主题类型交换机)
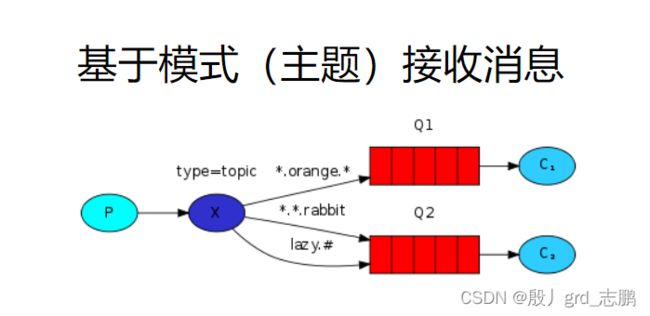
前面两个交换机可以满足部分场景,但是如果想更随心所欲的控制,通配符是个不错的选择,比如"*“星号代表任意一个单词,”#"井号代表0或多个单词假设有3个队列,路由key分别是A.B.,.B.*,#.B.#。那么我们发送消息时,指定路由key为A.B.C会发送给所有个队列,X.B.C.E只会发送给第三队列
因此topic的路由key有规定,必须是单词列表,以.点进行分隔,长度限制为不超过255字节。这样才能方便通配。比如A.Bisce.execute
也就是说,队列绑定的routingKey是通配符的,比如A.B. * 。而Producer发送时,相应发给A.B. * 这个队列,就有很多选择了,A.B.C,A.B.E等等。
代码位置:
- Producer:正常发送消息,并且可以指定RoutingKey。和fanout代码不同的地方是交换机类型,路由kek可以动态指定了
- Consumer:3个工作线程,路由key分别是A.B.,.B.*,#.B.#。正常接收消息
接收消息的路由key可以通过回调的message获取

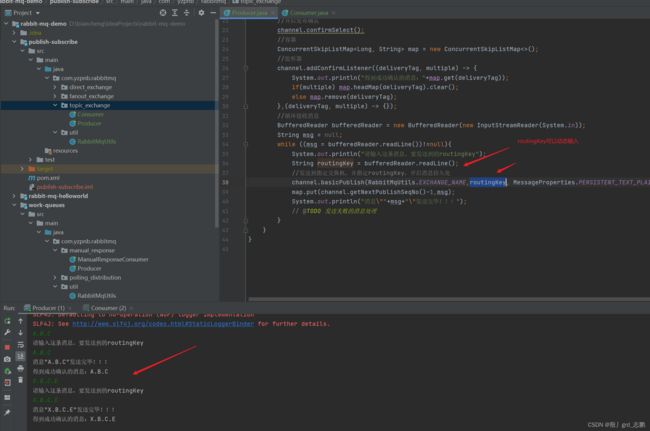
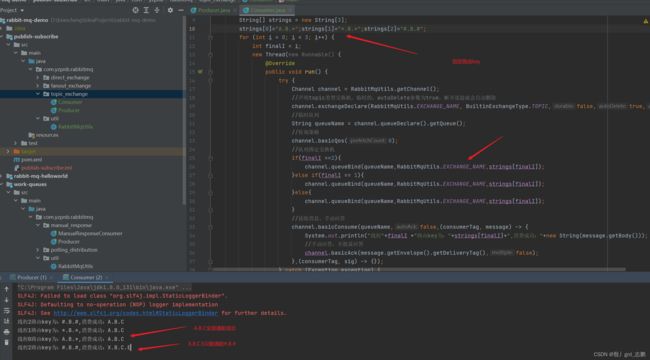
//接收消息,手动应答
channel.basicConsume(queueName,false,(consumerTag, message) -> {
//接收到消息的路由key为
System.out.println(message.getEnvelope().getRoutingKey());
System.out.println("线程"+finalI +"路由key为:"+strings[finalI]+",消费成功:"+new String(message.getBody()));
//手动应答,不批量应答
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
},(consumerTag, sig) -> {});
三、死信队列
死信,无法被消费的消息,比如已经在queue中的消息,Consumer从中取消息消费,但是因为某种原因,有些消息无法被消费,这些消息如果不处理,就变成死信,而对应的,也有了死信队列。
作用:死信队列机制,消息消费发生异常,将消息投入死信队列中。比如可以保证订单业务的消息数据不丢失,又比如用户商城下单后,没有在指定时间内支付,让其自动动失效。
死信的来源
- 消息TTL过期(存活时间)
- 队列达到最大长度(队列满,无法再添加数据到MQ)
- 消息被拒绝(basic.reject()或basic.nack()拒绝应答,并且requeue = false,也就是消费失败不放回原队列中)
效果演示,架构图
- 两个交换机,两个队列,两个消费者,分别是正常的,和处理死信的。一个Producer正常发消息给正常交换机,正常交换机给正常队列,C1消费者正常消费。当死信出现,就发给死信交换机进行处理(给死信队列,然后给C2消费)
- C1是消费者,同时也是死信的生产者
- 具体做法是,声明normal-queue队列时,指定死信交换机和死信队列,已经什么样的消息认为是死信

1 消息过期,消息被拒绝
代码位置:
- Producer代码:正常发送消息,指定消息的过期时间为10秒


AMQP.BasicProperties build = MessageProperties.PERSISTENT_TEXT_PLAIN
.builder().expiration("10000")
.build();
//发送到指定交换机,并指定routingKey,开启消息持久化
channel.basicPublish(NORMAL_EXCHANGE,NORMAL_ROUTING_KEY, build,msg.getBytes(StandardCharsets.UTF_8));
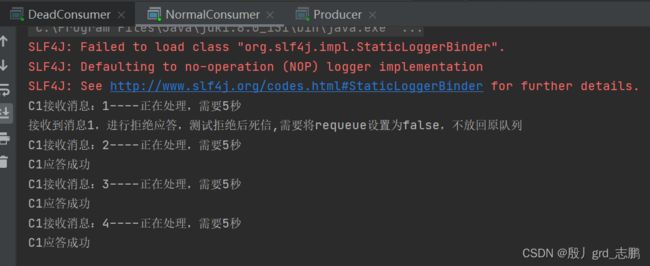
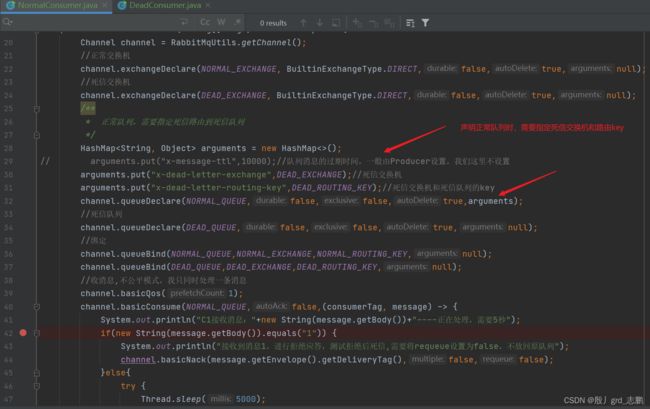
- NormalConsumer,C1消费者代码:不公平策略,每次只预取处理一个消息。需要声明正常队列时,指定死信队列的交换机和参数。另外消息如果是1,直接basic.nack()进行拒绝应答,处理消息时,每个消息处理5秒。
- Producer发送1-6共6条消息,1这个消息会直接拒绝,前往死信,2处理5秒,3处理5秒,4正好卡住10秒过期时间,进行处理,5和6会超过10秒过期时间
- 代码唯一不同的地方在于,需要多声明一组死信队列和交换机,并且正常队列需要指定死信交换机和路由key,才能将队列消息发送给死信交换机
import com.rabbitmq.client.BuiltinExchangeType;
import com.rabbitmq.client.Channel;
import com.yzpnb.rabbitmq.util.RabbitMqUtils;
import java.util.HashMap;
/**
* 正常的一个消费者
*/
public class NormalConsumer {
private static final String NORMAL_EXCHANGE = "normal_exchange";
private static final String NORMAL_QUEUE = "normal_queue";
private static final String NORMAL_ROUTING_KEY = "normal_routing_key";
private static final String DEAD_EXCHANGE = "dead_exchange";//死信交换机
private static final String DEAD_QUEUE = "dead_queue";//死信队列名
private static final String DEAD_ROUTING_KEY = "dead_routing_key";//死信路由key
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
//正常交换机
channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT,false,true,null);
//死信交换机
channel.exchangeDeclare(DEAD_EXCHANGE, BuiltinExchangeType.DIRECT,false,true,null);
/**
* 正常队列,需要指定死信路由到死信队列
*/
HashMap<String, Object> arguments = new HashMap<>();
// arguments.put("x-message-ttl",10000);//队列消息的过期时间,一般由Producer设置,我们这里不设置
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);//死信交换机
arguments.put("x-dead-letter-routing-key",DEAD_ROUTING_KEY);//死信交换机和死信队列的key
channel.queueDeclare(NORMAL_QUEUE,false,false,true,arguments);
//死信队列
channel.queueDeclare(DEAD_QUEUE,false,false,true,null);
//绑定
channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,NORMAL_ROUTING_KEY,null);
channel.queueBind(DEAD_QUEUE,DEAD_EXCHANGE,DEAD_ROUTING_KEY,null);
//收消息,不公平模式,我只同时处理一条消息
channel.basicQos(1);
channel.basicConsume(NORMAL_QUEUE,false,(consumerTag, message) -> {
System.out.println("C1接收消息:"+new String(message.getBody())+"----正在处理,需要5秒");
if(new String(message.getBody()).equals("1")) {
System.out.println("接收到消息1,进行拒绝应答,测试拒绝后死信,需要将requeue设置为false,不放回原队列");
channel.basicNack(message.getEnvelope().getDeliveryTag(),false,false);
}else{
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//不批量应答
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
System.out.println("C1应答成功");
}
},(consumerTag, sig) -> {
System.out.println("C1处理失败");
});
}
}
- DeadConsumer:C2消费者,处理死信消息,也就是1,5,6。代码和普通消费者没有不同。
2. 队列达到最大长度
C1,指定正常队列参数即可,下面我们设置队列最大长度为1.
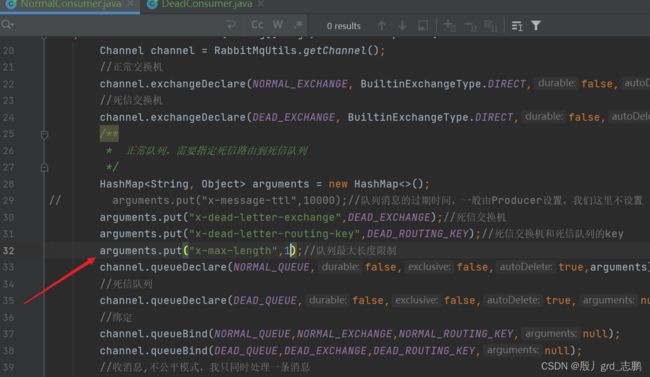
arguments.put("x-max-length",1);//队列最大长度限制
发送1-6条消息。1会立即拒绝,前往死信,然后接收2。此时3,4,5会直接前往死信,因为队列满,2处理完,6会继续前往正常队列。

四、spring boot整合
现在大家多用spring boot,整合起来,使用RabbitMQ也更加方便了
- 依赖

<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.6</version>
</parent>
<dependencies>
<!--RabbitMQ依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit-test</artifactId>
<scope>test</scope>
</dependency>
<!--spring boot依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>
- 配置文件
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
mvc:
pathmatch:
matching-strategy: ant_path_matcher # 解决spring boot 2.6.6和 swagger不兼容
server:
port: 8080
- swagger配置

1. 延迟(延时)队列
延时队列和上面死信队列用到的技术和代码是一样的。只不过我们用这种机制来实现延时处理的效果。
延时队列中的元素,希望在指定时间到了之后或之前取出和处理,可以用来存放需要在指定时间被处理的元素
- 比如,订单,十分钟之内未支付,则自动取消(放入死信队列进行处理)
- 新创建的店铺,十天内没有上传商品,自动发消息提醒
- 用户注册成功,三天内没有登录,进行短信提醒
- 用户发起退款,三天没处理,通知相关运营人员
- 预定会议后,预定时间前10分钟,提醒预定人员会议10分钟后开始
7.1 延时队列案例
生产者P生产消息,队列1的消息会有10秒延时后,进入死信队列处理。队列2的消息40秒后,进入死信队列处理。而QC队列,是由生产者P动态设置过期时间
- 大家可以想象为,P生产的是一个下载链接,有效期分别是10天或40天(我们用秒来代替),生产成功后,将其放入数据库。同时,将消息发送到对应的队列,消息里面带着下载链接在数据库的id。
- 当时间到了,进入死信队列后,消费者拿到消息,获取id,将其从数据库删除
- 下次用户再次使用下载链接时,数据库查不到,就可以返回链接已失效。
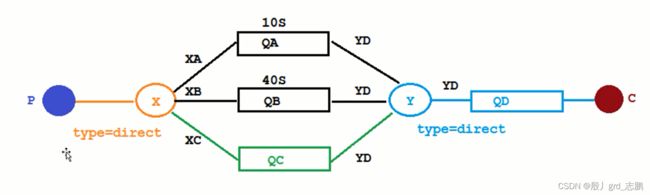

代码:用了springboot后,配置交换机,队列什么的,就不需要在Producer或Consumer代码中写了。全部写到配置类即可,非常方便。
- 配置类:
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
/**
* 延迟队列案例,RabbitMQ配置类
*/
@Configuration
public class RabbitMQTTLQueueConfing {
//普通交换机
public static final String NORMAL_EXCHANGE = "X";
//普通队列1
public static final String NORMAL_QUEUE1 = "QA";
//普通1路由key
public static final String NORMAL_ROUTING_KEY1 = "XA";
//普通队列2
public static final String NORMAL_QUEUE2 = "QB";
//普通2路由key
public static final String NORMAL_ROUTING_KEY2 = "XB";
//普通队列3
public static final String NORMAL_QUEUE3 = "QC";
//普通3路由key
public static final String NORMAL_ROUTING_KEY3 = "XC";
//死信交换机
public static final String DEAD_EXCHANGE = "Y";
//死信交换机RoutingKey
public static final String DEAD_ROUTING_KEY = "YD";
//死信队列
public static final String DEAD_QUEUE = "QD";
//绑定关系
// private static final String NORMAL_EXCHANGE_NORMAL_QUEUE1 = "XBindingQA";
// private static final String NORMAL_EXCHANGE_NORMAL_QUEUE2 = "XBindingQB";
// private static final String DEAD_EXCHANGE_DEAD_QUEUE = "YBindingQD";
//普通交换机声明
@Bean(NORMAL_EXCHANGE)
public DirectExchange NORMAL_EXCHANGE(){
//new DirectExchange(exchangeName,durable,autoDelete,arguments)
return new DirectExchange(NORMAL_EXCHANGE,false,true,null);
}
//死信交换机
@Bean(DEAD_EXCHANGE)
public DirectExchange DEAD_EXCHANGE(){
return new DirectExchange(DEAD_EXCHANGE,false,true,null);
}
//队列1 10秒过期
@Bean(NORMAL_QUEUE1)
public Queue NORMAL_QUEUE1(){
HashMap<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);//死信交换机
arguments.put("x-dead-letter-routing-key",DEAD_ROUTING_KEY);//死信交换机和死信队列的key
arguments.put("x-message-ttl",10000);//队列消息的过期时间,
// arguments.put("x-max-length",1);//队列最大长度限制
//Queue(String name, boolean durable, boolean exclusive, boolean autoDelete,@Nullable Map arguments)
return new Queue(NORMAL_QUEUE1,false,false,true,arguments);
}
//队列2 40秒过期
@Bean(NORMAL_QUEUE2)
public Queue NORMAL_QUEUE2(){
HashMap<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);//死信交换机
arguments.put("x-dead-letter-routing-key",DEAD_ROUTING_KEY);//死信交换机和死信队列的key
arguments.put("x-message-ttl",40000);//队列消息的过期时间,
return new Queue(NORMAL_QUEUE2,false,false,true,arguments);
}
//队列3 不设置过期
@Bean(NORMAL_QUEUE3)
public Queue NORMAL_QUEUE3(){
HashMap<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);//死信交换机
arguments.put("x-dead-letter-routing-key",DEAD_ROUTING_KEY);//死信交换机和死信队列的key
return new Queue(NORMAL_QUEUE3,false,false,true,arguments);
}
//死信队列
@Bean(DEAD_QUEUE)
public Queue DEAD_QUEUE(){
return new Queue(DEAD_QUEUE,false,false,true,null);
}
//绑定队列1到交换机1
@Bean//可以用@Qualifier注解将队列和交换机对象注入进来
public Binding NORMAL_EXCHANGE_NORMAL_QUEUE1(@Qualifier(NORMAL_QUEUE1) Queue queue,
@Qualifier(NORMAL_EXCHANGE) DirectExchange exchange){
//绑定,BindingBuilder.bind(队列对象).to(交换机对象).with(RoutingKey);
return BindingBuilder.bind(queue).to(exchange).with(NORMAL_ROUTING_KEY1);
}
//绑定队列2到交换机1
@Bean
public Binding NORMAL_EXCHANGE_NORMAL_QUEUE2(@Qualifier(NORMAL_QUEUE2) Queue queue,
@Qualifier(NORMAL_EXCHANGE)DirectExchange exchange){
return BindingBuilder.bind(queue).to(exchange).with(NORMAL_ROUTING_KEY2);
}
//绑定队列3到交换机1
@Bean
public Binding NORMAL_EXCHANGE_NORMAL_QUEUE3(@Qualifier(NORMAL_QUEUE3) Queue queue,
@Qualifier(NORMAL_EXCHANGE)DirectExchange exchange){
return BindingBuilder.bind(queue).to(exchange).with(NORMAL_ROUTING_KEY3);
}
//绑定死信
@Bean
public Binding DEAD_EXCHANGE_DEAD_QUEUE(@Qualifier(DEAD_QUEUE) Queue queue,
@Qualifier(DEAD_EXCHANGE)DirectExchange exchange){
return BindingBuilder.bind(queue).to(exchange).with(DEAD_ROUTING_KEY);
}
}
- Controller,Producer代码
import com.yzpnb.config.RabbitMQTTLQueueConfing;
import io.swagger.annotations.ApiOperation;
import lombok.extern.log4j.Log4j2;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Date;
@Log4j2
@RestController
@RequestMapping("/ttl")
public class SendMsgController {
@Autowired
private RabbitTemplate rabbitTemplate;
@ApiOperation("发消息给普通队列")
@GetMapping("/sendMsg/{msg}")
public void sendMsg(@PathVariable String msg){
log.info("当前时间:{},发送消息给队列1,延时10秒:{}",new Date().toString(),msg);
rabbitTemplate.convertAndSend(RabbitMQTTLQueueConfing.NORMAL_EXCHANGE,RabbitMQTTLQueueConfing.NORMAL_ROUTING_KEY1,"10秒队列:"+msg);
log.info("当前时间:{},发送消息给队列2,延时40秒:{}",new Date().toString(),msg);
rabbitTemplate.convertAndSend(RabbitMQTTLQueueConfing.NORMAL_EXCHANGE,RabbitMQTTLQueueConfing.NORMAL_ROUTING_KEY2,"40秒队列:"+msg);
log.info("当前时间:{},发送消息给队列3,延时由消费者自己设置为45秒:{}",new Date().toString(),msg);
rabbitTemplate.convertAndSend(RabbitMQTTLQueueConfing.NORMAL_EXCHANGE,RabbitMQTTLQueueConfing.NORMAL_ROUTING_KEY3, "45秒队列:"+msg,
message -> {
//设置参数
message.getMessageProperties().setExpiration("45000");
return message;
});
}
}
- consumer代码
import com.rabbitmq.client.Channel;
import com.yzpnb.config.RabbitMQTTLQueueConfing;
import lombok.extern.log4j.Log4j2;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.util.Date;
/**
* 死信队列消费者
*/
@Component
@Log4j2
public class DeadLetterConsumer {
@RabbitListener(queues = RabbitMQTTLQueueConfing.DEAD_QUEUE)
public void receiveDeadQueueMsg(Message message, Channel channel){
log.info("{}:死信队列接收到消息:{}",new Date().toString(),new String(message.getBody()));
}
}
7.2 延迟队列的问题
默认的,RabbitMQ只会关注队列中第一个元素的ttl。比如现在队列中有2个消息,ttl分别是20s,5s。
正常理解下,应该ttl为5的先执行。但是因为只关注第一个元素,也就是20s延迟的,5s的并不会提前执行。
最终的效果就是,当20s延迟的消息过期后,进入死信队列,此时才判断5s的,发现它也超时了。
RabbitMQ也提供了解决这个问题的延迟插件,使用非常简单,由于篇幅原因就不展开说了,可以参考这篇文章,十分钟就可以搞定:https://blog.csdn.net/qq_36551991/article/details/107213281
当然还有其它办法,但是不推荐,例如Java的DelayQueue。Redis的zset,Quartz,kafka的时间轮。
五、spring boot发布确认模式
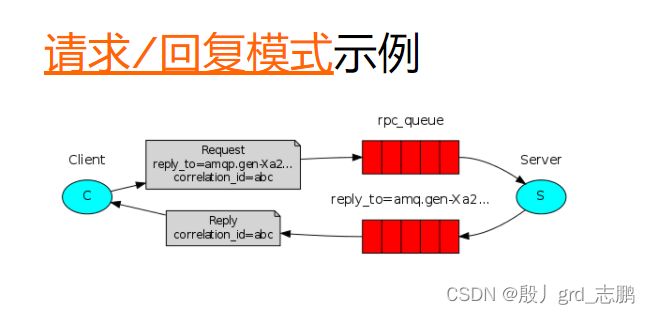
1. 和交换机的发布确认
如果交换机成功接收,需要给我们一个回调,如果失败,也需要给我们回调。RabbitTemplate.ConfirmCallback函数式接口,就搞了一个这玩意。
- 配置类:配置一个交换机,一个队列
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.CustomExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 发布确认配置类
*/
@Configuration
public class RMQPublishSubscribeConf {
public static final String CONFIRM_QUEUE = "confirm_queue";
public static final String CONFIRM_EXCHANGE = "confirm_exchange";
public static final String CONFIRM_ROUTING_KEY = "confirm_routing_key";
@Bean(CONFIRM_EXCHANGE)
public CustomExchange CONFIRM_EXCHANGE(){
//自定义类型交换机
//CustomExchange(String name, String type, boolean durable, boolean autoDelete, Map arguments)
return new CustomExchange(CONFIRM_EXCHANGE, "direct",false,true,null);
}
@Bean(CONFIRM_QUEUE)
public Queue CONFIRM_QUEUE(){
return new Queue(CONFIRM_QUEUE,false,false,true,null);
}
@Bean
public Binding CONFIRM_QUEUE_CONFIRM_EXCHANGE(@Qualifier(CONFIRM_QUEUE) Queue queue,
@Qualifier(CONFIRM_EXCHANGE) CustomExchange exchange){
//CustomExchange自定义交换机,绑定时需要.noargs()
return BindingBuilder.bind(queue).to(exchange).with(CONFIRM_ROUTING_KEY).noargs();
}
}
- 配置文件,开启发布确认,我们这里当然要使用异步确认了
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
publisher-confirm-type: correlated # none:禁用发布确认(默认),correlated:异步确认模式,发布消息成功到交换机会触发回调。simple:同步确认模式
# simple:简单模式,也就是同步确认模式,发一条确认一条。会回调,但是需要rabbitTemple调用waitForConfirms或waitForConfirmsOrDie方法做,另外waitForConfirmsOrDie返回false会关闭channel
# 关闭channel后,接下来的消息,无法发送到broker
mvc:
pathmatch:
matching-strategy: ant_path_matcher # 解决spring boot 2.6.6和 swagger不兼容
server:
port: 8080
- 我们专门搞一个类,来实现回调接口
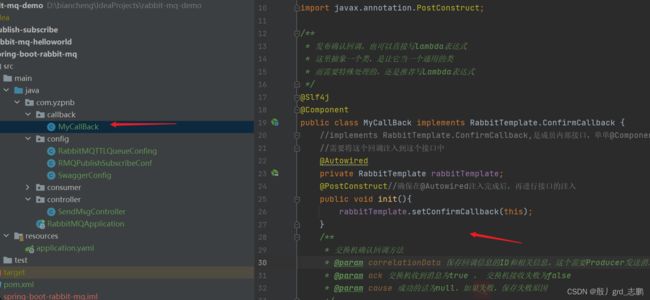
package com.yzpnb.callback;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* 发布确认回调,也可以直接写lambda表达式
* 这里抽象一个类,是让它当一个通用的类
* 而需要特殊处理的,还是推荐写Lambda表达式
*/
@Slf4j
@Component
public class MyCallBack implements RabbitTemplate.ConfirmCallback {
//implements RabbitTemplate.ConfirmCallback,是成员内部接口,单单@Component注入这个类是没用的
//需要将这个回调注入到这个接口中
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct//确保在@Autowired注入完成后,再进行接口的注入
public void init(){
rabbitTemplate.setConfirmCallback(this);
}
/**
* 交换机确认回调方法
* @param correlationData 保存回调信息的ID和相关信息。这个需要Producer发送消息时,进行指定
* @param ack 交换机收到消息为true , 交换机接收失败为false
* @param cause 成功的话为null,如果失败,保存失败原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
//CorrelationData这个对象需要发送消息时进行注入,如果没有注入,这里是null,因此需要判断
String id = correlationData.getId() != null ? correlationData.getId() : "";
//获取消息
Message message = correlationData.getReturned().getMessage();
if (ack){//成功
log.info("交换机接收成功!ID:{},消息为:{}",id,message!=null?new String(message.getBody()):"Producer发布消息时,没有提供消息给回调!!");
}else{//失败
log.info("交换机接收失败!ID:{},消息为:{},原因为:{}",correlationData.getId(),
message!=null?new String(message.getBody()):"Producer发布消息时,没有提供消息给回调!!",
cause);
}
}
}
- Consumer
- Producer:上面回调接口confirm方法的参数CorrelationData ,需要Producer发消息的时候注入


@ApiOperation("发布确认测试")
@GetMapping("/sendMsgConfrim/{msg}")
public void sendMsgConfrim(@PathVariable String msg){
log.info("当前时间:{},发送消息{}",new Date().toString(),msg);
//这个类是发布确认回调的参数,如果不传,那么回调获取不到这些信息,如果需要使用,一定要传
CorrelationData correlationData = new CorrelationData("1");
//ReturnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey)
correlationData.setReturned(new ReturnedMessage(new Message(msg.getBytes(StandardCharsets.UTF_8)),
1,"应答消息","交换机名","路由key"));
//正常发消息
rabbitTemplate.convertAndSend(RMQPublishSubscribeConf.CONFIRM_EXCHANGE,
RMQPublishSubscribeConf.CONFIRM_ROUTING_KEY, "测试正常发消息:"+msg,correlationData);
//测试交换机没有的消息
rabbitTemplate.convertAndSend(RMQPublishSubscribeConf.CONFIRM_EXCHANGE+"1111",
RMQPublishSubscribeConf.CONFIRM_ROUTING_KEY, "修改交换机名称为不存在的交换机测试:"+msg,correlationData);
}
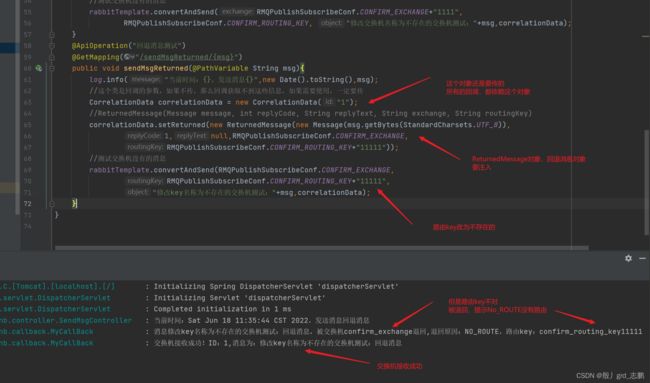
2. 回退消息
仅开启生产者确认机制,交换机收到消息,就会立即发送确认消息。而发现这个消息不可路由,消息会直接丢弃,此时生产者不知道消息被丢。
也就是说,交换机有发布确认,但是现在如果队列收不到消息,Producer没办法知道,消息还是会丢失。
Mandatory参数可以很好的解决这个问题,消息传递过程中不可达,会将消息返回Producer。
- 配置文件,开启发布退回
spring:
rabbitmq:
publisher-returns: true # 开启发布退回
- 同样的,RabbitTemplate.ReturnsCallback是RabbitTemplate提供的函数式接口。我们在这里进行处理即可,同样需要进行注入
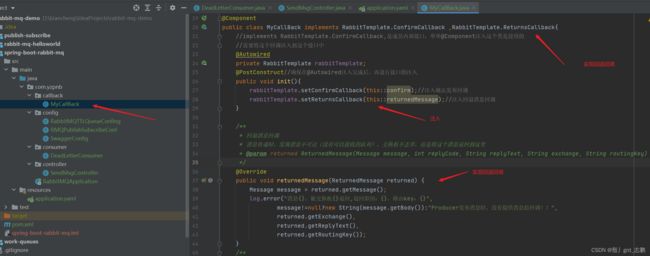
public class MyCallBack implements RabbitTemplate.ConfirmCallback ,RabbitTemplate.ReturnsCallback{
//implements RabbitTemplate.ConfirmCallback,是成员内部接口,单单@Component注入这个类是没用的
//需要将这个回调注入到这个接口中
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct//确保在@Autowired注入完成后,再进行接口的注入
public void init(){
rabbitTemplate.setConfirmCallback(this::confirm);//注入确认发布回调
rabbitTemplate.setReturnsCallback(this::returnedMessage);//注入回退消息回调
}
/**
* 回退消息回调
* 消息传递时,发现消息不可达(没有可以接收的队列),交换机不丢弃,而是将这个消息返回到这里
* @param returned ReturnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey)
*/
@Override
public void returnedMessage(ReturnedMessage returned) {
Message message = returned.getMessage();
log.error("消息{},被交换机{}退回,退回原因:{},路由key:{}",
message!=null?new String(message.getBody()):"Producer发布消息时,没有提供消息给回调!!",
returned.getExchange(),
returned.getReplyText(),
returned.getRoutingKey());
}
/**篇幅原因,省略**/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause{}
}
- Producer测试:
3. 优先级队列,手动确认
每个消息,都设定一个优先级0-255。越大越优先(排序,排前面)。另外看看spring boot怎么手动确认
- 配置文件,好好看配置,就是我们不用spring boot时,代码中设置的东西
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
# 消息确认
publisher-confirm-type: correlated # none:禁用发布确认(默认),correlated:异步确认模式,发布消息成功到交换机会触发回调。simple:同步确认模式
# simple:简单模式,也就是同步确认模式,发一条确认一条。会回调,但是需要rabbitTemple调用waitForConfirms或waitForConfirmsOrDie方法做,另外waitForConfirmsOrDie返回false会关闭channel
# 关闭channel后,接下来的消息,无法发送到broker
publisher-returns: true # 开启发布退回
template:
mandatory: true # 开启mandatory true 默认为true,Consumer可以利用basic.return将消息返还给生产者
listener:
simple:
acknowledge-mode: manual # 手动应答模式,auto为自动应答,默认auto
retry:
enabled: true # 支持重试
concurrency: 1 # 最少多少个工作线程Consumer
max-concurrency: 10 # 最多多少个
prefetch: 1 # 每个Consumer最大未完成,未确认数量,不让消息一股脑全部冲进channel,而是在队列中等待,这样可以方便我们测试优先级,因为消息到channel,队列优先级管不到
- 配置优先级队列,我们可以指定这个队列最大优先级为10,如果配置太大,会影响性能

@Bean(PRIORITY_QUEUE)
public Queue PRIORITY_QUEUE(){
HashMap<String, Object> map = new HashMap<>();
map.put("x-max-priority",10);//优先级队列,这里设置优先级范围为0-10。最大设置为0-255,但太大会浪费资源
return new Queue(PRIORITY_QUEUE,false,false,true,map);
}
- 生产者发消息时,指定优先级
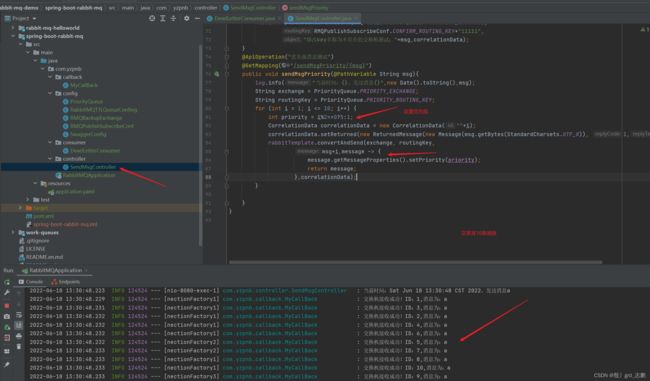
@ApiOperation("优先级消息测试")
@GetMapping("/sendMsgPriority/{msg}")
public void sendMsgPriority(@PathVariable String msg){
log.info("当前时间:{},发送消息{}",new Date().toString(),msg);
String exchange = PriorityQueue.PRIORITY_EXCHANGE;
String routingKey = PriorityQueue.PRIORITY_ROUTING_KEY;
for (int i = 1; i <= 10; i++) {
int priority = i%2==0?5:1;
CorrelationData correlationData = new CorrelationData(""+i);
correlationData.setReturned(new ReturnedMessage(new Message(msg.getBytes(StandardCharsets.UTF_8)), 1,null,exchange, routingKey));
rabbitTemplate.convertAndSend(exchange, routingKey,
msg+i,message -> {
message.getMessageProperties().setPriority(priority);
return message;
},correlationData);
}
- Consumer接收时,配置文件中配置了手动应答,可以使用手动应答了
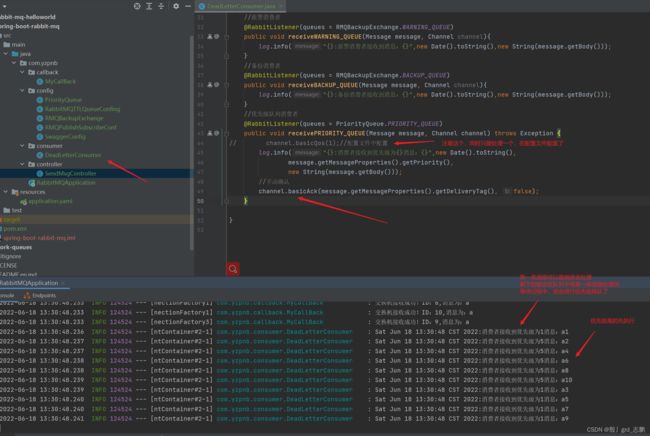
六、拓展知识
1. 备份交换机
处理到交换机,但是没到队列的消息丢失问题
如果有备份交换机,无法投递的消息(成功到交换机,但没有路由成功到队列)会优先发送给备份交换机。没有备份交换机,才会进行消息回退的回调

代码:和死信队列一样,confirm.exchange只需要设置参数,将备份交换机设置了即可,其它的就是正常配置
- 配置备份交换机
- confirm.exchange交换机,设置参数,设置备份交换机


HashMap<String, Object> arguments = new HashMap<>();
arguments.put("alternate-exchange",BACKUP_EXCHANGE);
return new CustomExchange(CONFIRM_EXCHANGE, "direct",false,true,arguments);
- 消费者测试

2. 幂等性
幂等性:就是用户对同一操作多次请求,结果一致,不会因为多次点击产生副作用。这是实际经常发生的,比如用户网络不好,已经付了钱,但是网卡了,此时又点了一次,不能让用户再付一次钱。
重复消费问题
MQ已经把消息发给消费者,但是消费者返回ack时网络中断,MQ没有收到确认消息,那么消息可能会回到队列,或者去死信队列中,或者网络重连后再次发给消费者。但是消费者已经消费过了,这时,消费者重复消费了消息。
解决思路
给消息添加唯一标识(全局ID,例如时间戳,UUID),每次消费者消费时,先判断id,是否已经消费过了。
Consumer幂等性保证
义务庞大场景下,只有id不行,producer可能就发了重复消息。此时即使Consumer收到了一样的消息,也要保证消息幂等性。
解决方案:业界主流两种
- 唯一ID+指纹码,利用数据库主键去重
- 利用redis原子性实现
唯一id+指纹码机制
就是一些规则或时间戳加别的服务给到的唯一信息码,并不一定要系统生成,一般用业务规则拼接而来,只要保证唯一性即可。然后利用查询语句判断id是否存在数据库,实现简单,但是高并发场景下不适用,因为数据库有写入瓶颈。
Redis原子性
redis执行setnx命令,天然具有幂等性。从而实现不重复消费。
2.1 Redis原子性解决幂等性问题
整体思路就是使用两个命令,setnx和getset
- setnx是原子性操作,只有value不存在时才能赋值。当第一次消费消息时,我们就可以使用这个命令,用消息唯一键作为key设置一个状态(0,1,2,分别对应失败,正在处理,成功)
- getset原子性操作,先get值,然后在set值。setnx命令只有value为空才能赋值,因此需要先get,高并发环境直接get,然后在set会出问题,因此也需要一个原子性的,先get再set整个是一个原子操作才行
- 发消息时,先提供消息id
- 手动发布确认前后,都加上redis判断和操作,看代码注释即可

import com.alibaba.fastjson.JSONObject;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.rabbitmq.client.Channel;
import io.swagger.models.auth.In;
import lombok.extern.log4j.Log4j2;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Date;
import java.util.Objects;
@Component
@Log4j2
public class LongStayConsumer {
@Autowired
RedisTemplate redisTemplate;
private static final Integer FAIL = 0;
private static final Integer CONSUMER_IS_CONSUMING = 1;
private static final Integer SUCCESS = 2;
@Autowired
private LMSPubkeysService lmsPubkeysService;
@RabbitListener(queues = LongStayMQConfig.LONG_STAY_QUEUE)
public Object receiveLONG_STAY_QUEUE(Message message, Channel channel) {
if(isRepetitive(message,channel)) return null;//如果重复消费了
//没有重复消费,正常进行
String msg = new String(message.getBody());
log.info("{}:队列{},接收到消息:{}",new Date().toString(),LongStayMQConfig.LONG_STAY_QUEUE,msg);
//如果要确认失败,告诉rabbitMQ消费失败了,需要在处理之前进行redis操作
try{
// int i = 1/0;
}catch (Exception e){
//确认消费失败
basicNackMq(channel,message,false);
}
//消费成功,
consumerSuccess(channel,message,false);
return success;
}
/**
* 消费成功,进行应答
*/
private void consumerSuccess(Channel channel, Message message, boolean multiple){
//手动确认成功
byte[] setFlag = getSetFlag(message, SUCCESS);
if(setFlag == null){//已经消费了,或者key不存在
log.info(message.getMessageProperties().getMessageId()+"不存在于redis");
}else {
basicAckMQ(channel,message,false);
}
}
/**
* 如果重复消息,判断是否已经消费成功,
* 如果成功,丢弃消息(因为它重复了)
* 如果还没成功,比如是正在消费,则不允许重复消费,不做其它操作
*/
private boolean isRepetitive(Message message, Channel channel) {
String messageId = message.getMessageProperties().getMessageId();
boolean lock = lock(messageId, 60 * 1000, CONSUMER_IS_CONSUMING);
if(!lock){//不可以重复消费
if(isSuccess(messageId)){//如果已经消费成功,不让消息回到队列
basicAckMQ(channel,message,false);
}
return true;//重复消费了
}
return false;//没有重复消费
}
/**
* 拒绝应答,告诉MQ,消费失败了,如果重复消费,判断消息当前消费状态,如果已经消费成功,丢弃消息,
* 如果没有消费成功,设置消费状态为0
*/
private void basicNackMq(Channel channel, Message message, boolean multiple) {
String messageId = message.getMessageProperties().getMessageId();
try {
Integer value = getFlag(messageId);
if(value == SUCCESS){//已经消费成功
//不允许回到队列了
channel.basicNack(message.getMessageProperties().getDeliveryTag(),false,false);
}else {
//设置状态为消费失败
redisTemplate.getConnectionFactory().getConnection().getSet(
messageId.getBytes(StandardCharsets.UTF_8),
String.valueOf(FAIL).getBytes());
//允许回到队列
channel.basicNack(message.getMessageProperties().getDeliveryTag(),false,true);
}
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
/**
* 手动确认应答
*/
private void basicAckMQ(Channel channel, Message message, boolean multiple) {
try {
channel.basicAck(message.getMessageProperties().getDeliveryTag(), multiple);
} catch (IOException e) {
e.printStackTrace();
basicNackMq(channel,message,multiple);
}
}
/**
* 判断是否已经消费成功
* @return
*/
private boolean isSuccess(String messageId) {
return getFlag(messageId) == SUCCESS;
}
/**
* 获取消息状态
*/
private Integer getFlag(String messageId){
byte[] bytes = redisTemplate.getConnectionFactory().getConnection().get(messageId.getBytes());
if(Objects.nonNull(bytes)&&bytes.length>0){
Integer value = Integer.valueOf(new String(bytes));
return value;
}
return null;
}
/**
* get后在set
*/
private byte[] getSetFlag(Message message, Integer value){
String messageId = message.getMessageProperties().getMessageId();
//设置状态为消费成功
byte[] set = redisTemplate.getConnectionFactory().getConnection().getSet(
messageId.getBytes(StandardCharsets.UTF_8),
String.valueOf(value).getBytes());
return set;
}
/**分布式锁
* 用redis实现消息原子性,避免重复消费
* @param lockKey 消息的唯一id
* @param lockExpireMils 过期时间
* @param flag 0 消费失败 1表示正在消费,2表示消费成功。如果消费失败,会让消息重新进入队列
*/
public boolean lock(String lockKey,long lockExpireMils,int flag){
return (boolean) redisTemplate.execute((RedisCallback) redisConnection -> {
long nowTime = System.currentTimeMillis();
//setNx表示value不存在就赋值,否则不赋值,常用于实现分布式锁
Boolean acquire = redisConnection.setNX(lockKey.getBytes(StandardCharsets.UTF_8),
String.valueOf(flag).getBytes());
//true表示赋值成功,也就是第一次消费
if(acquire) {
log.info("消息{}正在尝试首次消费,消费者当前想要消费状态为:{}",
lockKey,flag==2?"消费成功":"正在消费");
//设置过期时间
redisConnection.expire(lockKey.getBytes(StandardCharsets.UTF_8),nowTime+lockExpireMils+1);
return Boolean.TRUE;
}
else {//表示重复消费了
//先获取值
byte[] value = redisConnection.get(lockKey.getBytes(StandardCharsets.UTF_8));
//如果值存在,说明确实已经消费过了
if(Objects.nonNull(value)&&value.length>0){
//获取当前消息状态
Integer oldFlag = Integer.valueOf(new String(value));
log.info("消息{}正在尝试重复消费,消息当前消费状态为:{},消费者当前想要消费状态为:{}",
lockKey,oldFlag==2?"消费成功":oldFlag,flag==2?"消费成功":flag);
if(oldFlag == 0){//消费失败了,可能已经无法正常消费了
//getSet:取指定key的当前值,然后给这个key赋value值
byte[] oldValue = redisConnection.getSet(lockKey.getBytes(StandardCharsets.UTF_8),
String.valueOf(flag).getBytes());
//设置过期时间
redisConnection.expire(lockKey.getBytes(StandardCharsets.UTF_8),nowTime+lockExpireMils+1);
//key不存在时,返回false。代表key不存在或已经使用
return oldValue == null?false:Long.parseLong(new String(oldValue))<nowTime;
}else {//没过有效期
return false;
}
}
}
return Boolean.FALSE;
});
}
}
3. 惰性队列
普通队列,消息都优先放内存,惰性队列,消息都放磁盘。适用于消费者挂了,MQ挤压消息达到临界值,此时就可以将后续消息放在惰性队列中。
声明惰性队列,和搞死信队列一样,设置参数就行了。
HashMap<String, Object> map = new HashMap<>();
map.put("x-queue-mode","lazy");//声明惰性队列
return new Queue(PRIORITY_QUEUE,false,false,true,map);
也并不是全放磁盘,内存中会放消息的索引。但是对于内存来说,100万条消息,放普通队列(全在内存),1条消息按1kB算,需要1.2GB。惰性队列就放点索引,1.5M不到。
但是惰性队列消息消费时,就要先根据索引把消息从磁盘加载到内存,然后再消费,速度肯定慢,因此,适用于内存撑不住的情况下。