达摩院CVPR2023人脸重建论文HRN解读——REALY榜单冠军模型
前言
高保真 3D 人脸重建在许多场景中都有广泛的应用,例如 AR/VR、医疗、电影制作等。尽管大量的工作已经使用 LightStage 等专业硬件实现了出色的重建效果,从单一或稀疏视角的单目图像估计高精细的面部模型仍然是一个具有挑战性的任务。 本文中,我们将介绍来自达摩院的CVPR2023最新的人脸重建论文,该工作在单图人脸重建榜单REALY上取得正脸、侧脸双榜第一,并在其他多个数据集中取得了SOTA的效果。


1. 论文&代码
论文题目:A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
论文地址:https://arxiv.org/abs/2302.14434
项目主页:https://younglbw.github.io/HRN-homepage/
ModelScope (demo) : https://www.modelscope.cn/models/damo/cv_resnet50_face-reconstruction/summary
2. 摘要
受限于 3DMM 的低维表征,大多数基于 3DMM 的人脸重建方法无法恢复高频面部细节,如皱纹、酒窝等。一些方法尝试引入细节贴图或非线性操作,结果仍然不理想。 为此,我们在本文中提出了一种新颖的层次化表征网络 (HRN),以实现单图的高精细人脸重建。 具体来说,我们对人脸几何细节进行了解耦并引入了层次表征来实现精细的人脸建模。 同时,结合面部细节的3D先验,提高重建结果的准确性和真实性。 我们还提出了一个de-retouching模块,以实现更好的几何和纹理解耦。 值得注意的是,通过考虑不同视图的细节一致性,我们的框架可以扩展到多视图重建。 在两个单视图和两个多视图人脸重建基准上的大量实验表明,我们的方法在重建精度和视觉效果方面优于现有方法。
3. 方法解读
3.1 核心思想
现有的一些方法 [1、2、3] 尝试通过预测displacement map来捕捉高频面部细节,例如皱纹等,并取得了不错的效果。但是,displacement map由于其定义方式,无法对更大尺度的细节进行建模,例如下巴、脸颊的轮廓细节等。为此,我们将人脸的几何进行拆解,并分别用不同的表征分别对其进行表示,如上图所示。具体的,我们将人脸几何拆分为低频部分、中频细节以及高频细节:
- 低频部分描述了人脸的整体骨架(胖瘦、五官位置及大致形状),对于这个部分,我们使用现有的参数化3DMM方法,利用低维的系数及对应形状基进行表征。
- 中频部分描述了人脸骨架基础上的较大尺度的细节(如肌肉走向、面部轮廓等),该部分我们利用在UV空间的3通道的deformation map作为表征,其描述了每个顶点在低频基础上的xyz三方向上的形变。
- 高频部分描述了人脸的小尺度的细节,比如皱纹等,该部分我们利用displacement map进行像素尺度上的细节建模。
总体来说,我们将人脸几何拆分为三个部分,并根据其尺度大小及细节特征,引入了三种层次化的表征,分别从人脸、顶点、像素三个不同颗粒度进行建模,实现人脸的精准化、精细化重建。
3.2 网络结构
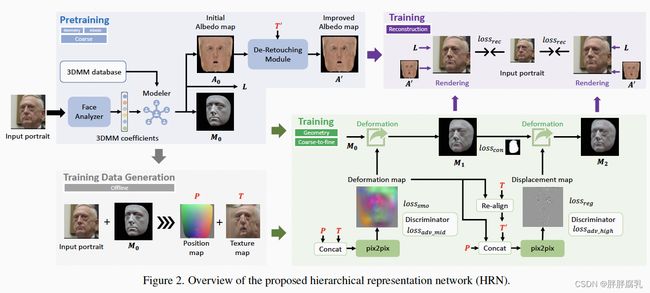
在HRN (hierarchical representation network) 网络结构中,我们整体采用了coarse-to-fine的框架,首先,我们利用现有的3DMM-based方法deep3d[4],预测人脸的低频几何部分(图2蓝色区域),同时,我们可以获得对应的position map以及texture map,这两者将作为细节预测的输入。而后,我们分别利用两个串联的pix2pix网络,预测deformation map以及displacement map(图2绿色区域)。最后,我们结合预测的精细化几何、光照、优化后漫反射贴图,进行可微分渲染,得到重建后的人脸图像(图2紫色区域)。通过将中频、高频的渲染人脸分别与原图计算损失,可引导人脸的几何形变,从而获得对应的几何细节。在此整体流程中,我们还引入了一些新颖的模块和损失函数,来提升建模精度。
3.3 3D细节先验

尽管可以使用重建损失从单个图像中粗略地重建面部细节,但由于其本质是个高度ill-posed的任务,仅从单图获取的细节存在模糊性和歧义性。 添加额外的正则化可能有助于缩小解空间,但也会导致细节准确性和保真度严重下降。 为了解决这个问题,我们从真实3D数据中获取真实的人脸3D细节,从而作为先验信息引导网络的预测。如上图,我们利用提出的网络结构,对真实的3D mesh进行拟合,从而获得deformation map以及displacement map的groud-truth。而后,我们在网络训练中,引入判别器网络,用真实的分布引导细节图的生成。消融实验表明,引入3D细节先验可使预测的人脸几何更加的平滑、真实。
3.4 De-Retouching模块
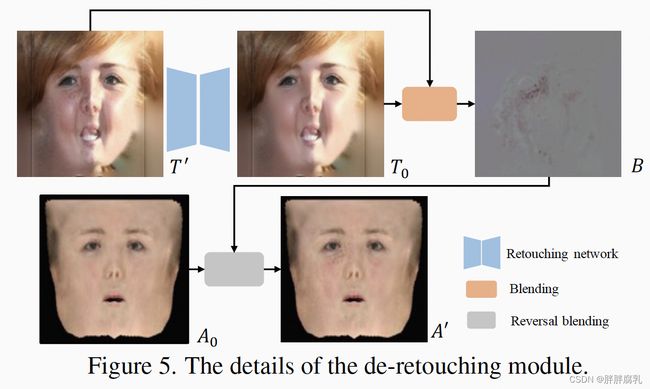
人脸图像是几何、光照和面部漫反射率组合的结果。 之前的工作假设面部漫反射率是平滑的,并使用 3DMM 的低频反照率对其进行建模。 然而,实际皮肤纹理充满了高频细节,如痣、疤痕、雀斑和其他瑕疵,这给几何细节学习带来了歧义,尤其是在单视图人脸重建任务中。 受[5]的启发,我们提出了一个De-Retouching模块,旨在生成具有高频细节的面部反照率,并促进更精确的几何和外观解耦。我们首先从FFHQ数据集中收集了10, 000张人脸图像,并训练了一个retouching网络G,去除人脸的瑕疵等高频细节。给定人脸纹理 T’ ,我们首先使用 G 去除其纹理细节并得到 T0,如上图所示。而后,我们旨在将纹理细节烘焙到粗糙的反照率 A0 中以获得优化后的反照率 A’ 用于渲染 . 我们假设从 A0 到 T0 的光照应该与从 A’ 到 T’ 的光照一致,如:

其中 S 表示shading,⊙ 表示逐元素矩阵乘法。 然后我们可以求解方程并获得 A’ 为:

其中 ϕ(T0) 避免了 0 附近的值爆炸,默认情况下 ε = 1e−6。 与 A0 相比,优化后的反照率 A’ 包含更多高频纹理细节,这减轻了几何和纹理之间的歧义,尤其是在单视图人脸重建任务中。
3.5 Contour-aware Loss
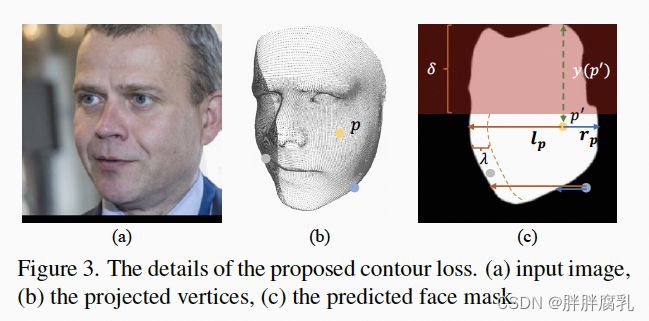
我们提出了一种新颖的轮廓感知损失 L_con 来实现面部轮廓的精确建模。 L_con 作用在中频几何M1 (figure 2)上,旨在拉动边缘的顶点以对齐面部轮廓。 如上图所示,我们首先将 M1 的顶点投影到图像空间中。 然后我们使用预训练的面部抠图网络 [6] 预测面部掩码M_face 并进行后处理以获得每一行的左侧和右侧点。 给定顶点 p 和 M_face 上对应的投影点 p’,我们得到向量 l_p 和 r_p(从 p’ 到水平方向的边缘点)。 那么L_con可以描述为:

可以看到,L_con 惩罚了人脸 soft margin 之外的顶点(如上图中的蓝色和灰色点)并将它们拉到人脸轮廓,同时保持人脸内部的顶点不动。我们只关注面部轮廓的下部以避免头发的干扰。 与常见的分割损失相比,L_con 给出了更直接的人脸轮廓优化方向,也更容易训练。消融研究也证实了 Lcon 在提升重建轮廓精度中的有效性。
3.6 MV-HRN
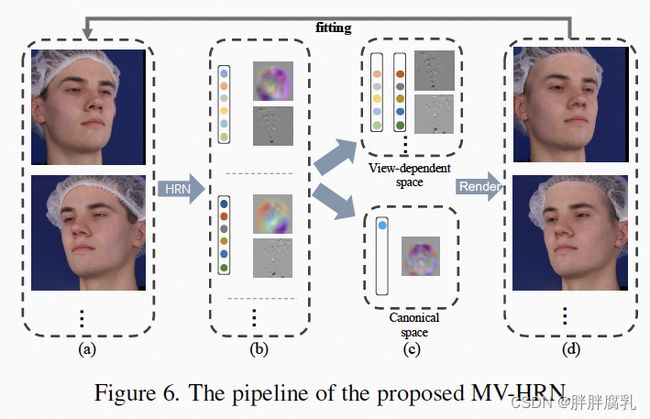
归功于层次化建模以及3D先验引导,我们可以轻易地将HRN适用于多视角人脸重建任务中。通过添加不同视角之间的几何一致性,我们可以使用两到三个少量的视角完成整体面部几何的精确建模。 上图显示了 MV-HRN 的流程。 我们假设人脸低频部分和中频细节在不同视图之间是一致的,而照明、姿态、表情和高频细节等应该是视角相关的。 因此,我们引入了一个标准空间以及视角独立空间,分别对共享的固有面部形状以及每个视图的姿势、光照、表情和高频细节等进行建模。 通过拟合过程,在不同视角图像的监督下,脸型逐渐被限制在更小、更准确的空间内。 实验表明,MV-HRN 在短时间内(不到一分钟)仅给出少量(2∼5)个图像视图即可实现准确重建。
4. 实验结果
4.1 与SOTA方法对比
4.1.1 定性对比


可以看出,无论是在单图,还是多图重建中,我们的方法在几何的精确性上以及细节的还原度上都相比于现有方法有较大提升。
4.1.2 定量对比
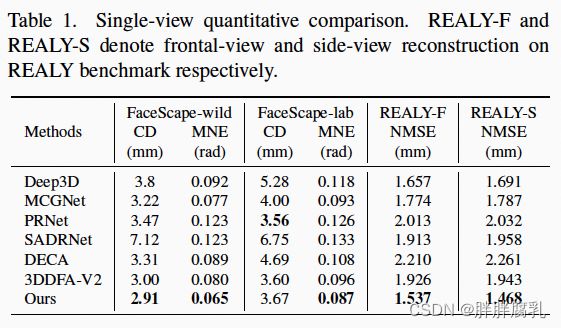
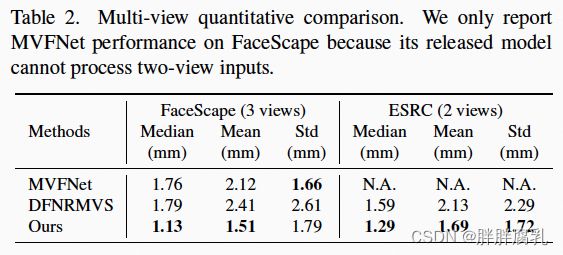
同样,在与真实mesh的平均误差等定量指标的对比中,我们的方法也在多个单图、多图人脸重建benchmark中超越了现有的SOTA方法。
4.2 消融实验





5. 参考
[1] Anpei Chen, Zhang Chen, Guli Zhang, Kenny Mitchell, and Jingyi Yu. Photo-realistic facial details synthesis from single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9429–9439, 2019. 1, 6
[2] Yudong Guo, Juyong Zhang, Jianfei Cai, Boyi Jiang, and Jianmin Zheng. Cnn-based real-time dense face reconstruction with inverse-rendered photo-realistic face images. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2018. 1
[3] E. Richardson, M. Sela, R. Or-El, and R. Kimmel. Learning detailed face reconstruction from a single image. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 1
[4] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019. 2, 4, 6
[5] Biwen Lei, Xiefan Guo, Hongyu Yang, Miaomiao Cui, Xuansong Xie, and Di Huang. Abpn: Adaptive blend pyramid network for real-time local retouching of ultra highresolution photo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2108–2117, 2022. 2, 5
[6] Jinlin Liu, Yuan Yao, Wendi Hou, Miaomiao Cui, Xuansong Xie, Changshui Zhang, and Xian-sheng Hua. Boosting semantic human matting with coarse annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8563–8572, 2020. 4