小黑子—Java从入门到入土过程:第九章-IO流
Java零基础入门9.0
- Java系列第九章- IO流
-
- 1. 初识IO流
- 2. IO流的体系
-
- 2.1 字节流
-
- 2.1.1 FileOutputStream 字符串输出流
-
- 2.1.1 - I 字符串输出流的细节
- 2.1.1 - II FileOutputStream写数据的3种方式
- 2.1.1 -III FileOutputStream写数据的两个小问题
- 2.1.2 FileInputStream 字符串输入流
-
- 2.1.2 - I FileInputStream 书写细节
- 2.1.2 - II FileInputStream 循环读取
- 2.2 文件拷贝
-
- 2.2.1 文件拷贝的弊端
- 2.2.2 FileInputStream 一次读取多个字节
- 2.2.3 文件拷贝改写
- 2.3 字符流
-
- 2.3.1 FileReader
-
- 2.3.1 - I 空参read
- 2.3.1 - II 有参read
- 2.3.1- III 字符输入流原理解析
- 2.3.2 FileWriter
-
- 2.3.2 - I 字符输入流原理解析
- 2.4 字节流和字符流综合练习
-
- 2.4.1 练习一:拷贝文件夹
- 2.4.2 练习二:加密和解密文件夹
- 2.4.3 练习三:修改文件夹中的数据
- 3. IO流中不同JDK版本捕获异常的方式
- 4.字符集
-
- 4.1 计算机储存规则
- 4.2 ASCII 字符集
- 4.3 GBK 字符集
- 4.4 字符集详解
- 4.5 乱码
- 4.6 编码和解码的方法
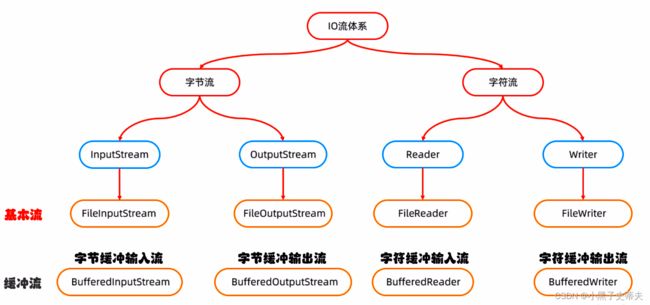
- 5.IO流体系高级流
-
- 5.1 缓冲流
-
- 5.1.1 字节缓存流
-
- 5.1.1 - I 字节缓存流提高效率原理
- 5.1.2 字符缓存流
- 5.1.3 综合练习
-
- 5.1.3 - I 练习一:拷贝文件
- 5.1.3 - II 练习二:拷贝文件
- 5.1.3 - III 练习三:软件运行次数
- 5.2 转换流
-
- 5.2.1 基本练习
- 5.2.1 - I 练习1:手动创建GBK文件把中文读取到内存当中
- 5.2.2 - II 把一段中文按照GBK的形式写到本地文件
- 5.2.3 - III 将本地文件的GBK转换为UTF-8
- 5.2.4 - IIIV
- 5.3 序列流(对象操作输出流)
-
- 5.3.1 序列化流(对象操作输出流)
- 5.3.2 反序列化流(对象操作输出流)
- 5.3.3 序列化流和反序列化流的细节
- 5.3.4 序列化流和反序列化流的综合练习:用对象流读写多个对象
- 5.4 打印流
-
- 5.4.1 字节打印流
- 5.4.2 字符打印流
- 5.5 解压缩流
- 5.6 压缩流
-
- 5.6.1 压缩单个文件
- 5.6.2 压缩多个文件
- 5.7 常用工具包 Commons-io
- 5.8 Hutool工具包
- 6. IO流的综合练习
-
- 6.1 网络爬虫
-
- 6.1.1 爬取姓式
- 6.1.2 爬取名字
- 6.1.3 数据处理
- 6.2 利用糊涂包生成假数据
- 6.3 带权重的随机数
- 6.4 登录注册
- 6.5 配置文件
-
- 6.5.1 properties配置文件
Java系列第九章- IO流
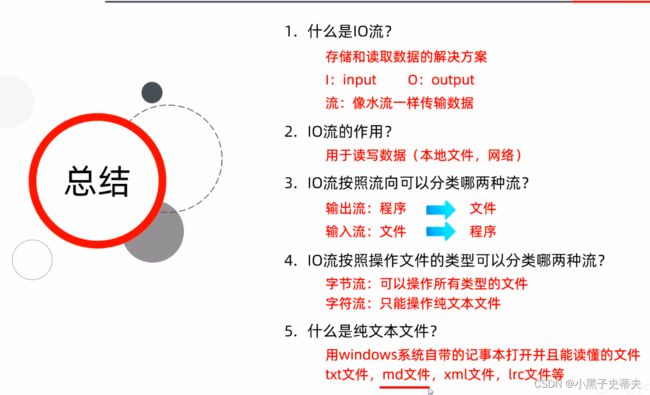
1. 初识IO流
IO流:存储和读取数据的解决方案
比如:
在玩游戏的时候,游戏进度的数据是保存在内存当中的
内存中的数据特点就是不能永久化的存储程序,程序停止,数据丢失
这时就需要添加一个存档功能,在存储的过程当中就是把数据保存到文件当中
想实现以上:
- 要知道文件在哪里
- 要知道如何进行数据传输,包括如何保存数据、如何读取数据
- IO流就是为此出现的,其与File文件息息相关

File类只能对文件本身进行操作,不能读写文件里面储存的数据
IO流做的事情:
IO流:用于读写文件中的数据(可以读写文件,或网络中的数据…)
- output:写出数据,把程序中的数据保存到本地文件当中
- input:读取数据,把本地数据加载到程序当中
IO流中,谁在读,谁在写?以谁为参照物看读写的方向呢?
以程序(内存)为参照物进行读写
IO流的分类:

纯文本文件:Windows自带的记事本打开能读懂的文件
小结:
2. IO流的体系

2.1 字节流
字节流子类:

字节流读取中文的时候会出现乱码,文件中不要有中文
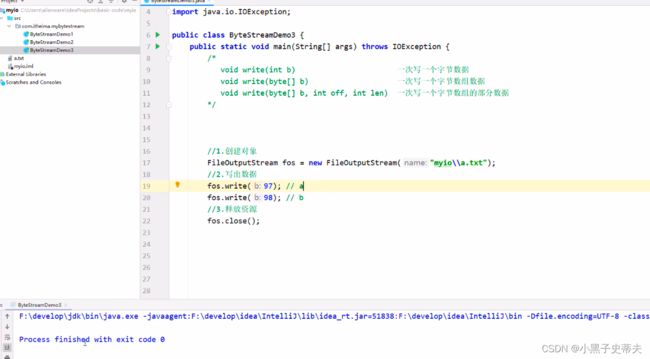
2.1.1 FileOutputStream 字符串输出流
FileOutputStream
操作本地文件的字节输出流,可以把程序中的数据写到本地文件中

import java.io.FileOutputStream;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
//1.创建对象
//写出 输出流 OutputStream
//本地文件 File
//异常抛出处理,检查一下当前文件下是否有a.txt
FileOutputStream fos = new FileOutputStream("javaprogram1\\a.txt");
//写出数据
fos.write(97);
//3.释放资源
fos.close();
}
}
图解:
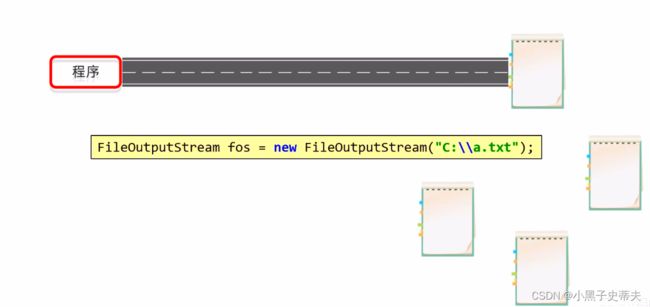


FileOutputStream的原理
就是创建了一个程序与文件之间的通道
write就是将书写的内容通过通道传输到文件之中
close就是再将这个连接的通道“敲碎”
2.1.1 - I 字符串输出流的细节
1、创建字节输出流对象
- 细节1:参数是字符串表示的路径或者是File对象都是可以的
- 细节2:如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的
- 细节3:如果文件已经存在,则会清空文件
2、写数据
- 细节:write方法的参数是整数,但是实际上写道本地文件中的是整数在ASCII上对应的字符
比如:97 - a;100 - d
如果想要写入97,就57-"9",55 - "7"写两次

3、释放资源
- 每次使用完流之后都要释放资源,就是将文件从内存运行中停止,这样后续就能够继续操作文件了,不然是操作不了的
2.1.1 - II FileOutputStream写数据的3种方式

1.一次写一个字节数据

2.一次写一个字节数组的数据
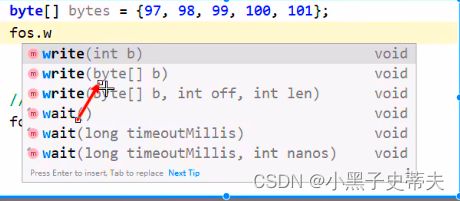
原本a.txt文件存在,那么清空时就把文件内容删除掉,然后重新写入想要的内容,所以不会是覆盖效果
3.一次写一个数组的部分数据
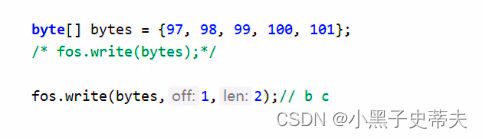
关于wirte的第三种使用:
- 参数一:数组
参数二:起始索引
参数三:个数
2.1.1 -III FileOutputStream写数据的两个小问题
写数据的两个小问题:想要换行写以及再次写不会清空而是继续写的续写

换行写:
再次写出一个换行符就可以了
- windows:
\r\n, \r表示回车,\n表示换行 - Linux:
\n - Mac:
\r
细节:
- 在Windows操作系统当中,java对回车换行进行了优化,
虽然完整的是\r\n,但是我们写其中一个\r或者\n就可以
java也可以实现换行,因为java在底层会补全
建议:
不要省略,还是写全了
续写:
如果想要续写,打开续写开关即可
开关位置:创建对象的第二个参数
默认false:表示关闭续写,此时创建对象会清空文件
手动传递true:表示打开续写,此时创建对象不会清空文件
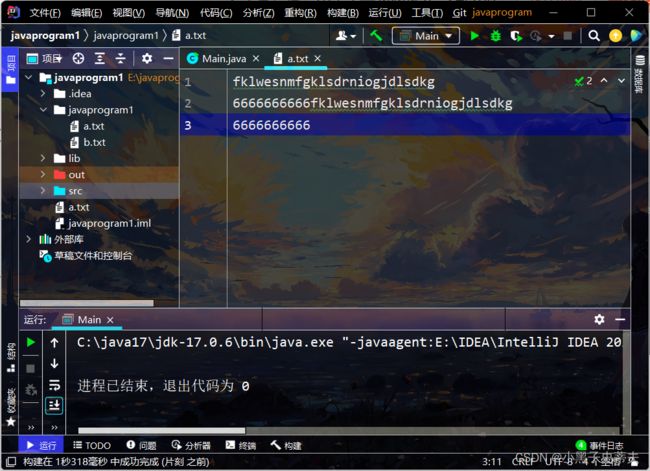
public class Main {
public static void main(String[] args) throws IOException {
//1.创建对象
FileOutputStream fos = new FileOutputStream("javaprogram1\\a.txt",true);
//写出数据
String str = "fklwesnmfgklsdrniogjdlsdkg";
byte[] bytes1 = str.getBytes();
fos.write(bytes1);
String wrap = "\r\n";//换行符
byte[] bytes2 = wrap.getBytes();
fos.write(bytes2);
String str2 = "6666666666";
byte[] bytes3 = str2.getBytes();
fos.write(bytes3);
//3.释放资源
fos.close();
}
}
小结:

2.1.2 FileInputStream 字符串输入流

public class Main {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
int b1 = fis.read();//只能读取一个字符,读不到了就返回-1
System.out.println(b1);
fis.close();
}
}
如果还想读后面的数据,笨方法是一个一个写

2.1.2 - I FileInputStream 书写细节
1、创建字节输入流对象
细节:如果文件不存在,就直接报错
java为什么会这么设计呢?
- 输出流:不存在,创建——把数据写到文件当中
- 输入流:不存在,为什么不直接创建而是报错? 因为创建出来的文件是没有数据的,没有任何意义。
所以java就没有设计这种无意义的逻辑,文件不存在直接报错
程序中最重要的是:数据
2、读取数据
- 细节1:一次读一个字节,读出来的是数据在ASCII上对应的数字
- 细节2:读到文件末尾了,read方法返回-1
- 细节3:如果后面是空格,空格对应的ASCII码是32
- 细节4:如果后面是-1的,那么读取时先读
-,再读1,不会把其作为一个整体
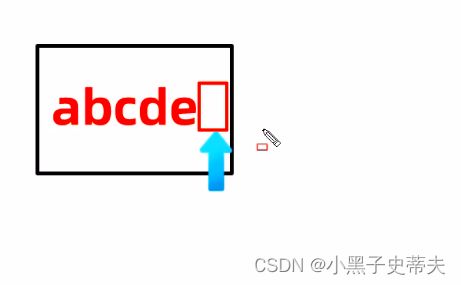
3、释放资源
- 细节:每一次使用完流必须要释放资源
2.1.2 - II FileInputStream 循环读取

public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//循环读取
int b;
while((b=fis.read())!=-1){
System.out.print((char)b);
}
fis.close();
}
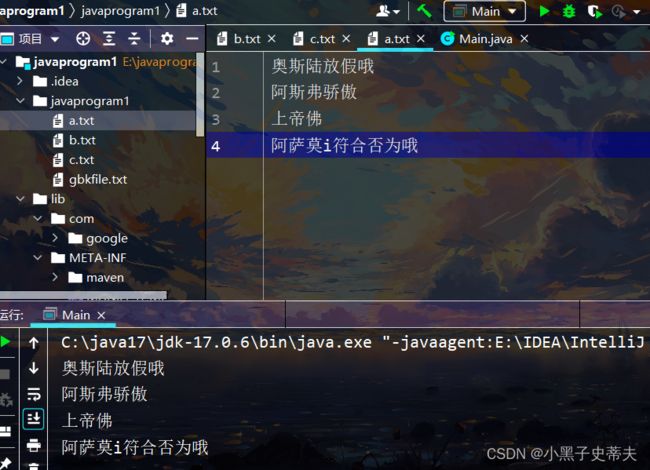
a.txt:
fsdejfkijsadrhgeasdklhgukjsadrhg

为什么要定义b,我把读取到的数据直接进行判断然后打印不行吗?
比如:
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//循环读取
while ((fis.read()) != -1) {
System.out.println(fis.read());
}
fis.close();
}
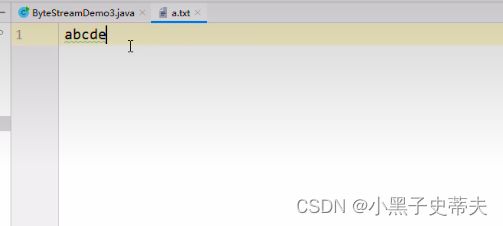
a.txt:
abcde

read:表示读取数据,而且每读取一个数据就移动一次指针
- 当写了两个read的时候,在开始的时候
读取到a进入到循环体当中,又调用了一次fis.read,所以第二次读的时候读到b,也就是98 - 再次进行循环,循环中又有一个read,第三次读取
读到c,然后到循环体中第四次读取读到d,所以就是100 - 再循环,第五次
读到e,到循环体中第六次读取,往后指针指向为空,所以返回-1
2.2 文件拷贝

public static void main(String[] args) throws IOException {
//读取文件
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//要拷贝到的文件
FileOutputStream fos = new FileOutputStream("javaprogram1\\b.txt");
//循环读取
int b;
long beginTime = System.currentTimeMillis();//开始时间
while ((b = fis.read()) != -1) {
fos.write(b);
}
//一个释放资源原则:先开的最后关闭
fos.close();
fis.close();
//计算拷贝时间
long endTime = System.currentTimeMillis();//结束时间
System.out.println("拷贝文件花费了:" + (endTime - beginTime) + "毫秒");
}
2.2.1 文件拷贝的弊端

为什么会慢呢?
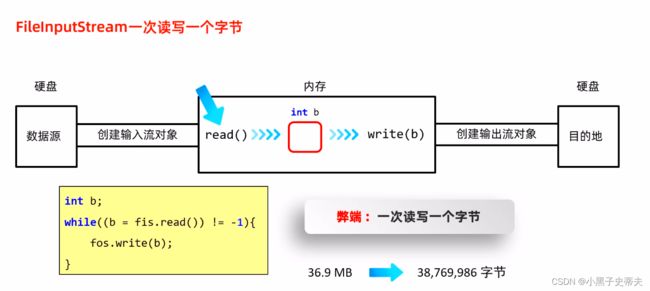
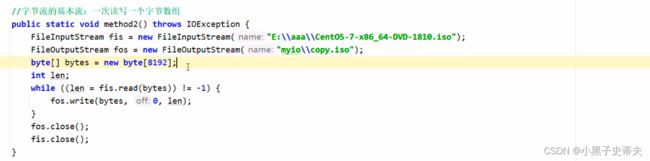
2.2.2 FileInputStream 一次读取多个字节

public static void main(String[] args) throws IOException {
//读取文件
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//设计读取的数组
byte[] bytes = new byte[2];
//一次读取多个字节数据,具体读多少,跟数组长度有关
//返回值:本次读取到了多少给字节数据
int len1 = fis.read(bytes);
System.out.println(len1);
String str1 = new String(bytes);
System.out.println(str1);
int len2 = fis.read(bytes);
System.out.println(len2);
String str2 = new String(bytes);
System.out.println(str2);
int len3 = fis.read(bytes);
System.out.println(len3);
String str3 = new String(bytes);
System.out.println(str3);//为什么是ed?
int len4 = fis.read(bytes);
System.out.println(len4);//-1
String str4 = new String(bytes);
System.out.println(str4);//为什么最后还是ed
fis.close();
}
图解:
第一次读取:

第二次读取:
- 在第二次读取到cd的时候,会把原来ab的位置覆盖
然后把数组里面的内容拿出来变成字符串,所以打印cd
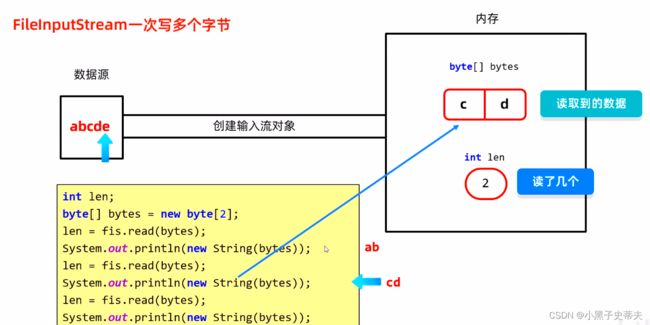
第三次读取:
- 第三次读取的时候,数据只剩下e没有两个,所以只能读到一个e把c覆盖了,而d没有被覆盖
读了一个数据,所以这次len为1
因此,在读取的时候打印的就是e和残留的d
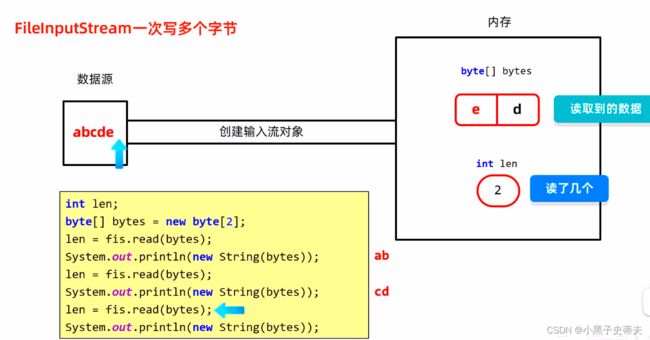
如果还要读取第四次,那么不管还是原来空参的read方法,还是现在带有数组的read方法,只要读不到数据方法就返回-1,还要打印的话里面数组数据没有被任何数据覆盖,所以打印的就是ed
解决方案:
字符串中的方法可以把字节数组的一部分变成字符串
public static void main(String[] args) throws IOException {
//读取文件
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//设计读取的数组
byte[] bytes = new byte[2];
//一次读取多个字节数据,具体读多少,跟数组长度有关
//返回值:本次读取到了多少给字节数据
int len1 = fis.read(bytes);
System.out.println(len1);
String str1 = new String(bytes,0,len1);//表示每次获取数组中从0索引开始,一共要把len1个元素变成字符串
System.out.println(str1);
int len2 = fis.read(bytes);
System.out.println(len2);
String str2 = new String(bytes,0,len2);
System.out.println(str2);
int len3 = fis.read(bytes);
System.out.println(len3);
String str3 = new String(bytes,0,len3);
System.out.println(str3);
fis.close();
}

2.2.3 文件拷贝改写
public static void main(String[] args) throws IOException {
//读取文件
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
FileOutputStream fos = new FileOutputStream("javaprogram1\\b.txt");
//拷贝
int len;
long start = System.currentTimeMillis();
byte[] bytes = new byte[1024];
while((len=fis.read(bytes))!=-1){
fos.write(bytes,0,len);
System.out.println(len);
}
//释放资源
fos.close();
fis.close();
long end = System.currentTimeMillis();
System.out.println((end - start)+"毫秒");
}
2.3 字符流

2.3.1 FileReader
2.3.1 - I 空参read
1、创建字符输入流对象

2、读取数据
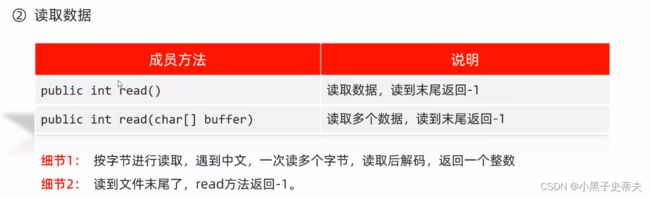
3、释放资源

read() 细节:
- read():默认也是一个字节一个字节的读取的,如果遇到中文就会一次读取多个
- 在读取之后,方法的底层还会进行解码并转成十进制
最终把这个十进制作为返回值
这个十进制的数据也表示在字符集上的数字
英文:
文件里面的二进制数据比如 0110 0001
read方法进行读取,解码并转成十进制比如27721
想要看到中文汉字,就是把这些十进制数据,再进行强转就可以了
public static void main(String[] args) throws IOException {
//1.创建对象并关联本地文件
FileReader fr = new FileReader("javaprogram1\\a.txt");
//2.读取数据
//字符流的底层也是字节流,默认也是一个字节,UTF-8一次读三给字节
//如果遇到中文就会一次读取多个,GBK一次读两个字节,UTF-8一次读三个字节
int ch;
while((ch= fr.read())!=-1){
System.out.print((char) ch);
}
//3.释放资源
fr.close();
}
2.3.1 - II 有参read
public static void main(String[] args) throws IOException {
//1.创建对象并关联本地文件
FileReader fr = new FileReader("javaprogram1\\a.txt");
char[] chars = new char[2];
int len;
//read(chars):读取数据,解码,强转三步合并了,把强转之后的字符放到数组当中
//相当于空参的read+强转类型转换
while ((len= fr.read(chars))!=-1){
//把数组中的数据变成字符串再进行打印
System.out.print(new String(chars,0,len));
}
fr.close();
}

2.3.1- III 字符输入流原理解析
创建输入流对象,底层会创建长度为:8192的字节数组——缓冲区
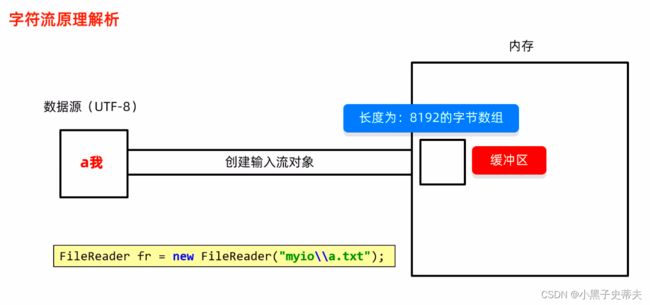
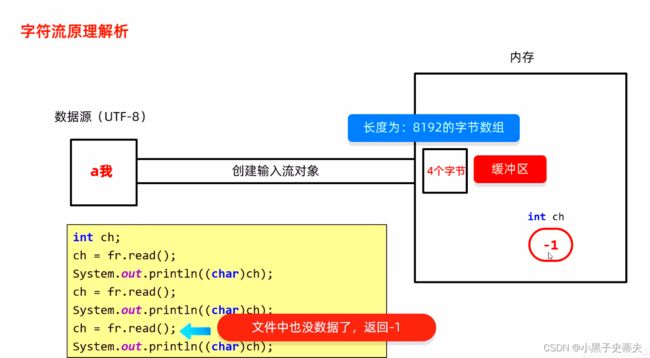
1、在内存中定义未赋值的变量ch
2、第一次读取,判断数据是否可以被读取;如果没有,从文件中读取数据,尽可能装满缓冲区,每次都从缓冲区中读取数据提高效率
3、第一次从缓冲区中读,读的是第一个字节,按照UTF-8的形式进行解码并且转成十进制,再赋值给变量ch,所以其记录的就是97,然后强制打印a
4、第二次读取中,发现剩下的3个字节是中文的,所以一次性会读取3个字节按照UTF-8的形式进行解码,转成十进制25105,再赋值给ch,然后强转成字符再进行打印
5、第三次读取中,发现在内存当中已经没有要读的东西了,然后从文件中读取。但是,文件中也没有剩余的数据了,那么就返回-1,最后把-1赋值给ch

public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("javaprogram1\\a.txt");
fr.read();//把文件中的数据放到缓冲区当中
//然后被FileWriter清空了文件
FileWriter fw = new FileWriter("javaprogram1\\b.txt");
//如果再次使用fr进行读取,会读取到数据吗?
//会把缓冲区中的数据全部读取完毕,但是只能读取缓冲区中的数据,文件中剩余数据无法再次读取
//因为已经被清空掉了
int ch;
while((ch=fr.read())!=-1){
System.out.print((char)ch);
}
fw.close();
fr.close();
}
2.3.2 FileWriter
FileWriter构造方法:

FileWriter成员方法:

FileWriter书写细节:

public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("javaprogram1\\a.txt");
//写出一个字符
fw.write(25105);//我
//写出一个字符串
fw.write("我是煞笔");//我是煞笔
//写出一个字符串数组
char[] chars = {'a','b','c','我'};
fw.write(chars);//abc我
//写出字符数组的一部分
fw.write(chars,0,2);//ab
fw.close();
}
2.3.2 - I 字符输入流原理解析

在写出的时候,它会把所有的数据按照UTF-8进行编码,一个中文变成3个字节,一个英文变成1个字节
跟字节流是不一样的:
字节流是没有缓冲区,是直接写到文件当中的目的地
字符流是有缓冲区的
- 那么数据是什么时候才能真正地保存到目的地呢?
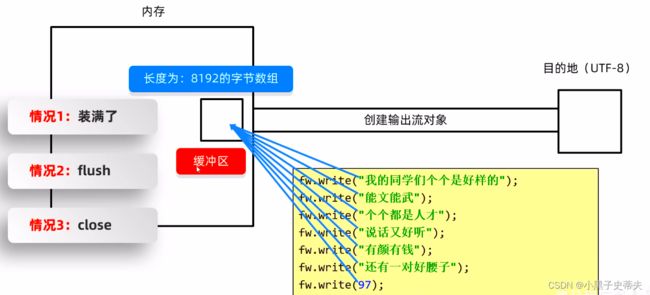
flush和close方法

区别:
- 如果用flush,那么下面还可以继续写数据
- 如果用close,那么就直接关流,下面写数据就报错
当数据超过缓冲区的存储时,比如8193,缓冲区放不下,那么此时缓冲区装不下,其数据就会自动地保存到文件当中
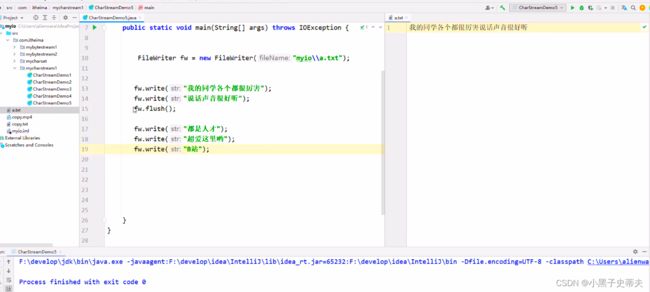
flush方法相当于把已经放到缓冲区的数据,刷新到本地文件,所以当程序运行完毕之后,上面的数据在文件当中就已经有了,而下面的数据还在缓冲区当中
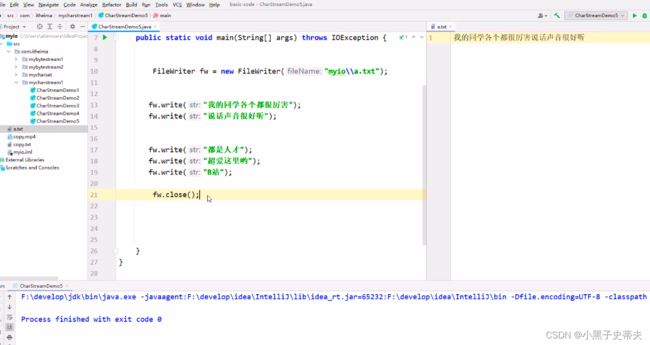
如果下面进行关流,那么它在断开链接之前,首先会检查一下缓冲区里面有没有数据。如果有,就会把剩余的所有数据都刷新到本地当中
2.4 字节流和字符流综合练习

2.4.1 练习一:拷贝文件夹

public class Main {
public static void main(String[] args) throws IOException {
//1.创建数据源
File src = new File("F:\\aaa\\ccc");
//2.创建对象表示目的地
File dest =new File("F:\\aaa\\fff");
//3.调用方法开始拷贝
copydir(src,dest);
}
public static void copydir(File src,File dest) throws IOException {
dest.mkdirs();//如果dest文件夹不存在那么自动创建
//1.进入数据源
File[] files = src.listFiles();
//2.遍历数组
if(files!=null){
for (File file : files) {
if(file.isFile()){
//3.判断为文件,就用字节流拷贝
//拷贝的时候一定是从文件开始,从文件结束
FileInputStream fis = new FileInputStream(file);//假设a.txt
//所以拷贝的时候要拷贝到dest文件夹里面
FileOutputStream fos = new FileOutputStream(new File(dest,file.getName()));//将其拷贝到dest当作,这个文件也叫了a.txt
//利用字节数组进行拷贝,速度快点
byte[] bytes = new byte[1024];
int len;
while((len=fis.read())!=-1){
fos.write(bytes,0,len);
}
fos.close();
fis.close();
System.out.println("拷贝成功");
}else {
//4.为文件夹,就递归
//第二个参数表示要拷贝文件夹的里面
copydir(file,new File(dest,file.getName()));
}
}
}
}
}


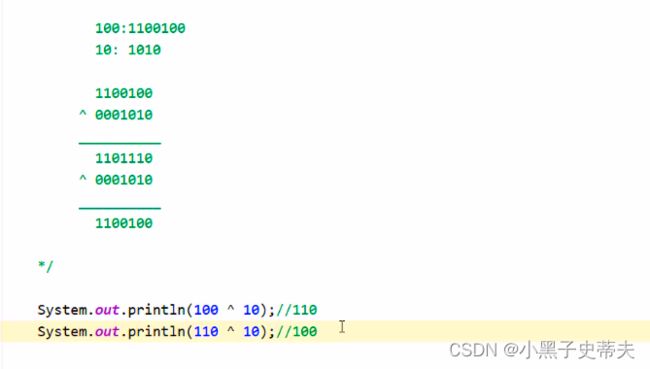
2.4.2 练习二:加密和解密文件夹

了解^:异或,在二进制下两给相同就false,两个不同就true
加密:
public static void main(String[] args) throws IOException {
//1.创建对象关联原始文件
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//2.创建对象关联加密文件
FileOutputStream fos = new FileOutputStream("javaprogram1\\b.txt");
//3.加密处理
int b;
while((b=fis.read())!=-1){
fos.write(b^2);//数字任意定
}
//4.释放资源
fos.close();
fis.close();
}
2.4.3 练习三:修改文件夹中的数据

1.
public class Main {
public static void main(String[] args) throws IOException {
//1.读取数据
//在读取的时候我需要的是那个整体,而不是直接索引打印,这样的话只能看而不能用
//所以要把其拼接到StringBuilder当中
FileReader fr = new FileReader("javaprogram1\\a.txt");
StringBuilder sb = new StringBuilder();
int b;
while ((b = fr.read()) != -1) {
sb.append((char) b);
}
fr.close();
System.out.println(sb);
//2.排序
//那就先把StringBuilder里面的数据先变成字符串之后才能调用split方法按照 - 进行切割
String sbStr = sb.toString();
String[] arrStr = sbStr.split("-");
//然后想要把字符串变成int类型的,就循环一遍用Integer.parseInt,然后把转换的数存到数组当中
ArrayList<Integer> list = new ArrayList<>();
for (String s : arrStr) {
int i = Integer.parseInt(s);
list.add(i);
}
Collections.sort(list);
System.out.println(list);
//3.写出
FileWriter fw = new FileWriter("javaprogram1\\b.txt");
for (int i = 0; i < list.size(); i++) {
if (i == list.size() - 1) {
fw.write(list.get(i) + "");
} else {
fw.write(list.get(i) + "-");
}
}
fw.close();
}
}
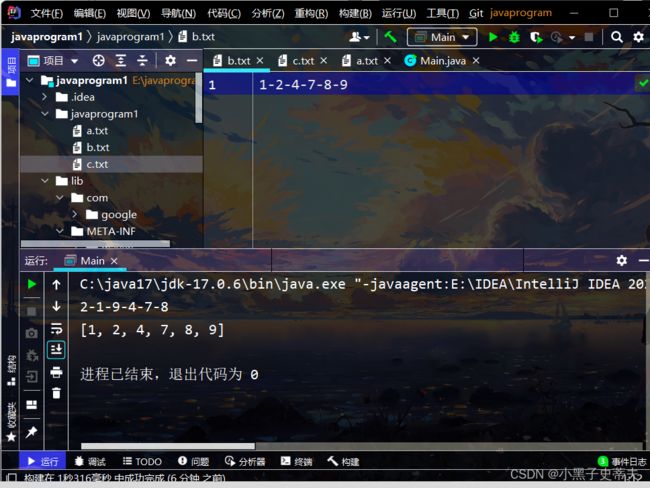
2.简化版
public class Main {
public static void main(String[] args) throws IOException {
//1.读取数据
//在读取的时候我需要的是那个整体,而不是直接索引打印,这样的话只能看而不能用
//所以要把其拼接到StringBuilder当中
FileReader fr = new FileReader("javaprogram1\\a.txt");
StringBuilder sb = new StringBuilder();
int b;
while ((b = fr.read()) != -1) {
sb.append((char) b);
}
fr.close();
System.out.println(sb);
//2.排序
Integer[] arr = Arrays.stream(sb.toString()
.split("-"))
.map(Integer::parseInt)//方法引用,把字符串转换为整数
.sorted()//默认升序排序
.toArray(Integer[]::new);//排完后收集起来,收集到int类型的数组当中
System.out.println(Arrays.toString(arr));
//3.写出
FileWriter fw =new FileWriter("javaprogram1\\b.txt");
//那么用上面去把数组里面的 ,变成 - 呢?
//用repalce方法
String s = Arrays.toString(arr).replace(",", "-");
//根据数组逗号位置,从索引1开始截取,到数组最后一个位置停止
String result = s.substring(1, s.length() - 1);
System.out.println(result);
fw.write(result);
fw.close();
}
}
3. IO流中不同JDK版本捕获异常的方式
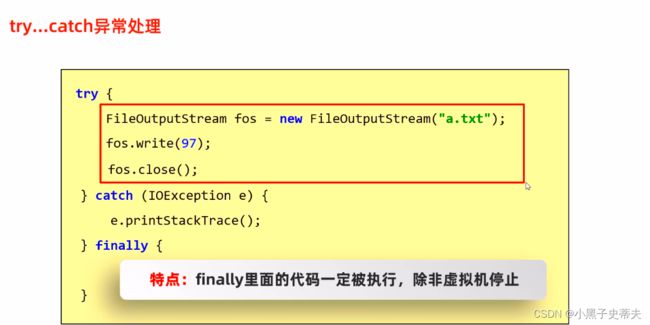
老版本try…catch下面还有个finally
特点:finally里面的代码一定被执行,除非虚拟机停止(JVM退出),什么意思?
如果在try当中写了一个system.exit(0)或者因为其他原因导致虚拟机都停止了,那么finally里面的代码是执行不到的

所以就非常适合将释放资源等扫尾代码放到finally之中
麻烦代码:
public class Main {
public static void main(String[] args) {
//ctrl + alt + t 快捷迅速环绕
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//读取文件
fis = new FileInputStream("javaprogram1\\a.txt");
fos = new FileOutputStream("javaprogram1\\b.txt");
//拷贝
int len;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
System.out.println(len);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//释放资源
//fos fis只能在try里面的局部变量中使用
//一般来说可以把其放到大括号外面,但这次不能把整个创建对象都放到外面去
//因为这个创建对象的代码它是有编译时异常的,但如果放到外面没有初始化那也会报错
//所以放到外面只定义空值,而不会去创建其对象
//之后报错的就是close方法,还要对其进行异常处理
//再嵌套try……catch方法即可
//可如果读入文件的时候没有当前路径,fis记录的值就还是null
//在finall用null去调用方法,就肯定会报空指针异常
//因此还要写一个非空判断
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
简化代码的接口:
在JDK7的时候java推出了一个简单的接口AutoCloseable
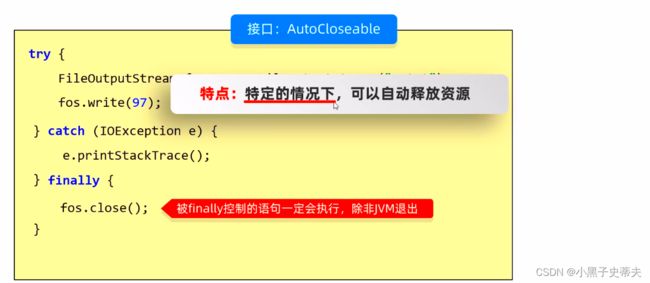
不同JDK下的书写方式:
JDK7的方法了解就行,JDK7注意:
不能把所有创建对象的代码都写在小括号当中,
只有实现了AutoCloseable的类才能在小括号当中创建对象

JDK7写法:
public static void main(String[] args) {
try (
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
FileOutputStream fos = new FileOutputStream("javaprogram1\\b.txt")
)
{
//拷贝
int len;
byte[] bytes = new byte[1024];
while((len=fis.read(bytes))!=-1){
fos.write(bytes,0,len);
System.out.println(len);
}
} catch (IOException e) {
e.printStackTrace();
}
//释放资源的代码直接不要
}
JDK9写法:
public static void main(String[] args) throws FileNotFoundException {
//在外面进行抛出处理
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
FileOutputStream fos = new FileOutputStream("javaprogram1\\b.txt");
try (fis ; fos)
{
//拷贝
int len;
byte[] bytes = new byte[1024];
while((len=fis.read(bytes))!=-1){
fos.write(bytes,0,len);
System.out.println(len);
}
} catch (IOException e) {
e.printStackTrace();
}
//释放资源的代码直接不要
}
4.字符集
4.1 计算机储存规则


4.2 ASCII 字符集
首先是熟悉的ASCII表,就是一个字符集,也叫做编码表
128个数据(对于西方的sucker来说足够使用了)

所以计算机在存储英文的时候一个字节就足以
ASCII编码规则:前面补0,补齐8位
解码直接转,前面补不补零无所谓

如果是汉字该怎么办?

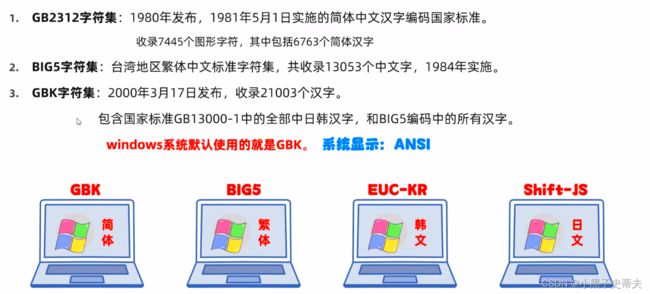

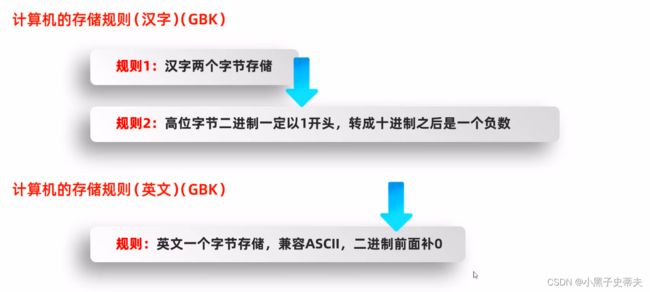
4.3 GBK 字符集
英文用一个字节存储,完全兼容ASCII
GBK英文编码规则:不足8位,前面补0

汉字:两个字节存储
前面的字节叫做高位字节
后面的字节叫做低位字节
高位字节二进制一定以1开头,转成十进制之后是一个负数
汉字编码规则:不需要变动


英文与中文的比较:

小结:

4.4 字符集详解

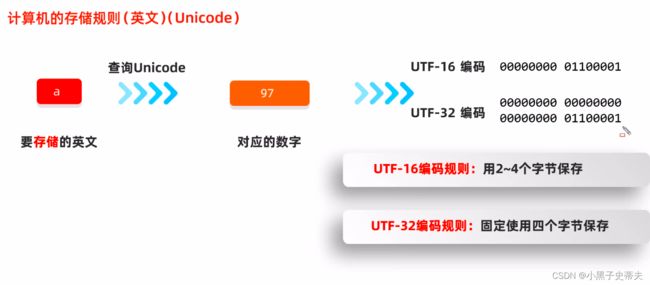
本来可以用1个字节表示的,却硬要用2个字节,导致空间过于浪费
所以后面又出了UTF-8编码规则:
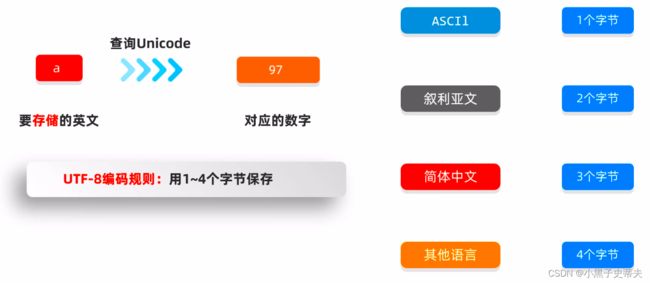
比如英文UTF-8编码时:

中文UTF-8编码时:

练习:
UTF-8是一个字符集吗?
不是,UTF-8只是字符集中的一个编码方式

小结:

4.5 乱码
原因1:读取数据时未读完整个汉字
原因2:编码和解码时的方式不统一

2.
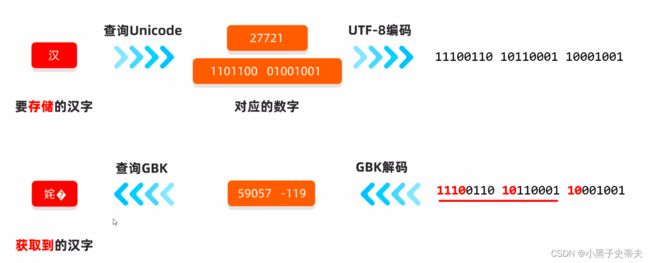
如何不产生乱码?


在拷贝的时候,数据没有丢失,在用记事本打开的时候用的字符集和编码表,同数据源是一样的,那是不会出现乱码的
4.6 编码和解码的方法

public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
//1.编码
String str = "ai你哟";
byte[] bytes1 = str.getBytes();//-28-67-96表示你 -27-109-97表示哟
System.out.println(Arrays.toString(bytes1));
//这个GBK方式有编译时异常,抛出即可
byte[] bytes2 = str.getBytes("GBK");
System.out.println(Arrays.toString(bytes2));//-60 -29组成 你 -45 -76组成哟
//2.解码
String s1 = new String(bytes1);
System.out.println(s1);
String s2 = new String(bytes1, "GBK");
System.out.println(s2);//当原本用UTF-8的编码却用GBK解码,结果就会出现乱码
}

5.IO流体系高级流

5.1 缓冲流
缓冲流一共有四种

5.1.1 字节缓存流
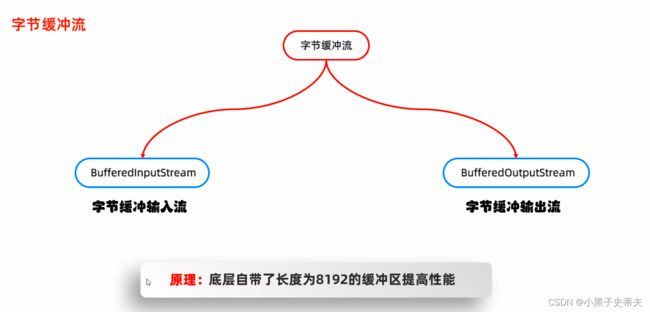


第一个构造是关于字节输入流,在它里面会默认有一个8192长度的缓冲区
第二个是除了传递一个字节输入流以为,还能手动设定缓冲区的大小
小练习:

1.一次操作一个字节
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("javaprogram\\a.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("javaprogram\\b.txt"));
int b;
while((b=bis.read())!=-1){
bos.write(b);
}
//释放资源
//为什么只需要关闭缓冲流,而基本流不用关闭了?
//源码在关闭缓冲流的时候会自动关闭基本流
bos.close();
bis.close();
}
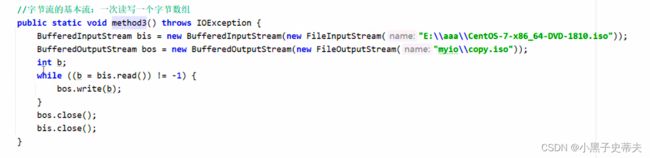
2.一次读写多个字节
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("javaprogram\\a.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("javaprogram\\b.txt"));
byte[] arr= new byte[3];
int len;
while((len=bis.read(arr))!=-1){
bos.write(arr,0,len);
}
//释放资源
//为什么只需要关闭缓冲流,而基本流不用关闭了?
//源码在关闭缓冲流的时候会自动关闭基本流
bos.close();
bis.close();
}
5.1.1 - I 字节缓存流提高效率原理

真正把数据写到文件的还是基本流,它会把缓冲区中的数据写道本地文件当中
细节:缓存输入流的缓冲区与缓冲输出流的不是一同个东西

中间的变量b就是充当一个倒手,在左右这两个缓冲区之间进行来回的倒腾数据,这一段都是在内存当中进行的,运行速度很快
所以倒手的时间可以忽略不记,其真正节约的是读和写时,跟硬盘打交道的时间
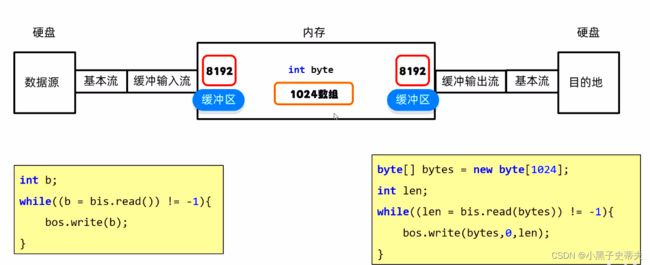
数组的倒手,运行更快
5.1.2 字符缓存流

字符缓冲流的构造方法:

字符缓冲流的特有方法:

方法会自动判断你是上面操作系统
1.单行输入
public static void main(String[] args) throws IOException {
//1.创建字符缓冲流的对象
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
//2.读取数据
//细节
//readLine方法在读取的时候,一次读一整行,遇到回车换行结束
// 但是不会把回车换行读到内存当中
String lien1 = br.readLine();
System.out.println(lien1);
String line2 = br.readLine();
System.out.println(line2);
br.close();
}
2.全部输入
public static void main(String[] args) throws IOException {
//1.创建字符缓冲流的对象
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line;
while((line=br.readLine())!=null){
System.out.println(line);
}
}
3.字符缓冲输出
public static void main(String[] args) throws IOException {
//1.创建字符缓冲流的对象
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\b.txt"));
//2.写出
bw.write("阿斯蒂芬和");
//换行 br.wirte("\r\n")这个方法不够跨平台
bw.newLine();//这个方法是BufferedWriter这个类独有的换行
bw.close();
}
小结:

5.1.3 综合练习
5.1.3 - I 练习一:拷贝文件

方法2和4都是比较快的


5.1.3 - II 练习二:拷贝文件

1.ArrayList排序
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line;
ArrayList<String> list = new ArrayList<>();
while((line=br.readLine())!=null){
list.add(line);
}
br.close();
//2.排序
//排序规则:按照每一行前面的序号进行排序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
//获取o1 o2
int i1 = Integer.parseInt(o1.split("\\.")[0]);
int i2 = Integer.parseInt(o2.split("\\.")[0]);
return i1-i2;//1 2 3 4 5 6..
}
});
//写出
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\b.txt"));
for (String s : list) {
bw.write(s);
bw.newLine();
}
bw.close();
}
2.TreeMap排序
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line;
//2.排序
TreeMap<Integer,String> tm = new TreeMap<>();
while((line=br.readLine())!=null){
String[] arr = line.split("\\.");
//0索引时 表序号 1索引时 表内容
tm.put(Integer.parseInt(arr[0]),arr[1]);//要是想看到序号arr[1]变成line就行
}
System.out.println(tm);
br.close();
//写出
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\b.txt"));
//然后获取treemap的每个键值对对象entrySet,然后遍历
Set<Map.Entry<Integer, String>> entries = tm.entrySet();
for (Map.Entry<Integer, String> entry : entries) {
//entry表示每个键值对,获取其值
String value = entry.getValue();
bw.write(value);
bw.newLine();
}
bw.close();
}

5.1.3 - III 练习三:软件运行次数
IO流原则:
什么时候用就什么时候创建
什么时候不用再什么时候关闭

public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line = br.readLine();//0 字符串
int count = Integer.parseInt(line);
//表示当前软件又运行了一次
count++;//1
//2.判断
if(count<=3){
System.out.println("欢迎使用本软件,第"+count+"次免费使用");
}else{
System.out.println("本软件只能免费使用3次");
}
//3.把当前自增之后的count写出到文件当中,这样就可以保证每次重新调用的时候count不被刷新
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\a.txt"));
bw.write(count+"");//后面加""的目的是让其变为字符串
bw.close();
}
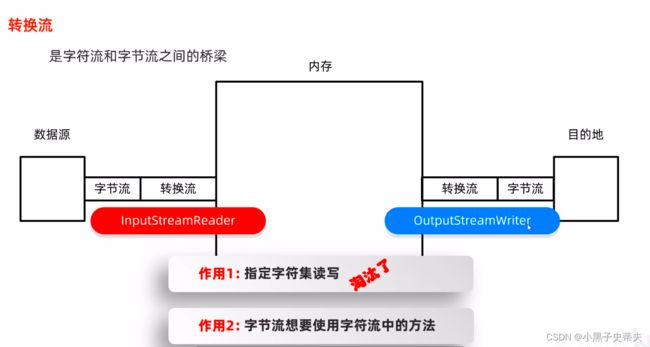
5.2 转换流
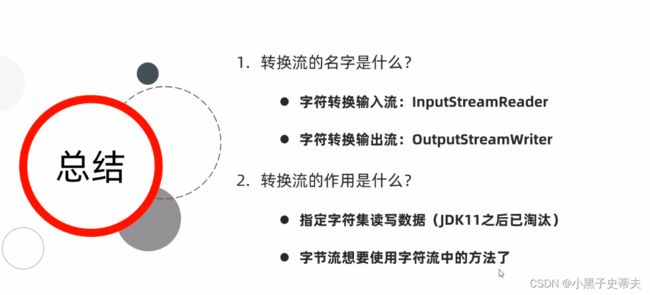
转换流是字符流和字节流之间的桥梁

当创建了转换流对象的时候,需要包装一个字节输入流,再包装之后这个字节流它就变成了字符流,就拥有了字符流的特性:
- 读取数据不会乱码
- 可以根据字符集一次读取多个字节
所以转换流的输入流也叫InputStreamReader
前面的InputStream表示可以把字节流转换成字符流,后面的Reader表示转化流本身是字符流的一员,爹是Reader
同理,转化流的输出流叫OutputStreamReader
idea默认的字符编码是UTF-8
文件另存的文件编码ANSI就是GBK

- 第一个参数的是需要关联一个字节输入流,使用平台默认的字符编码
- 第二个参数除了关联字节输入流以外,还需要指定char set name字符编码,可以小写也可以大写(专业点)
- 下面两个同理一样的,一般都是用上面两个
5.2.1 基本练习
5.2.1 - I 练习1:手动创建GBK文件把中文读取到内存当中

public static void main(String[] args) throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream("javaprogram1\\gbkfile.txt"),"GBK");
int ch;
while((ch=isr.read())!=-1){
System.out.print((char)ch);
}
isr.close();
System.out.println("------------------------------");
FileReader fr = new FileReader("javaprogram1\\gbkfile.txt", Charset.forName("GBK"));
int b;
while((b=fr.read())!=-1){
System.out.print((char)b);
}
fr.close();
}
基本流里指定用来表示字符编码的,使用Charset.forName
5.2.2 - II 把一段中文按照GBK的形式写到本地文件
- 需求2
public static void main(String[] args) throws IOException {
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("javaprogram1\\gbkfile.txt"),"GBK");
osw.write("李在干神魔");
osw.close();
//上面这个方法了解一下就行了
FileWriter fw = new FileWriter("javaprogram1\\gbkfile.txt");
fw.write("李在干神魔");
fw.close();
}

5.2.3 - III 将本地文件的GBK转换为UTF-8
- 需求3
JDK11以前的方案
public static void main(String[] args) throws IOException {
InputStreamReader isr = new InputStreamReader(new FileInputStream("javaprogram1\\gbkfile.txt"),"GBK");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("javaprogram1\\a.txt"),"UTF-8");
int b;
while((b= isr.read())!=-1){
osw.write(b);
}
osw.close();
isr.close();
}
替代方案:

5.2.4 - IIIV

public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
//用fis读取肯定会有乱码,所以要把字节流变成字符流
InputStreamReader isr = new InputStreamReader(fis);
//要读一整行InputStreamReader搞定不了,缓冲流才行
BufferedReader br = new BufferedReader(isr);
String line;
while ((line=br.readLine())!=null){
System.out.println(line);
}
br.close();
}
总结:
5.3 序列流(对象操作输出流)
5.3.1 序列化流(对象操作输出流)
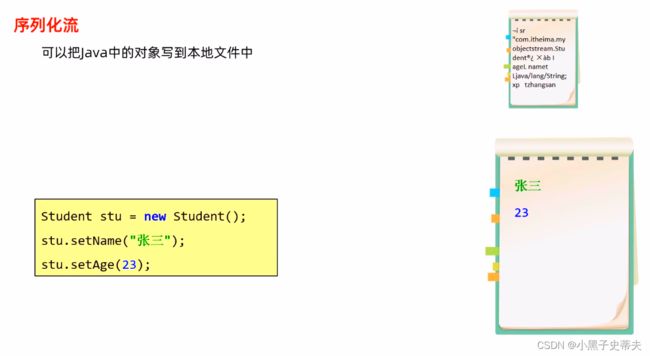
区别于直接写对象进文件当中,序列化流写进的数据我们看不懂,要通过反序列化流把数据

Serializable接口里面是没有抽象方法,这被称为标记型接口。可以理解成:一个物品的合格证
一旦实现了这个接口,那么就表示当前的类就可以被序列化
public static void main(String[] args) throws IOException {
Student stu = new Student("magua",24);
//创建序列化流的对象/对象操作输出流
ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("javaprogram1\\a.txt"));
//写出数据
oos.writeObject(stu);
oos.close();
}

5.3.2 反序列化流(对象操作输出流)

public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("javaprogram1\\a.txt"));
Object o = ois.readObject();
System.out.println(o);
ois.close();
}

如果说一个类实现了一个接口,表明这个类就是可序列化的,那么Java底层会根据其成员变量、静态变量、构造方法、成员方法……计算出里面的序列号,也就是版本号


但是此时如果修改了里面javabean里面的代码,就会重新计算其版本号。当用反序列化流读取版本号1到内存时,两个版本号不一样就直接报错

处理方案:
固定版本号就行了
static:表示这类的所有对象都共享同一个版本号
final:最终表示版本号不会发生变化
long:版本号的数字比较长,所以不要用int来说
serialLVersionUID:统一的变量名ID

idea系统设置快速设置serialLVersionUID

设置完成之后,alt+回车 自动生成
5.3.3 序列化流和反序列化流的细节
对上面反序化流
1.
Student类:
public class Student implements Serializable {
private static final long serialVersionUID = 650157805827481085L;
private String name;
private int age;
private String address;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
//toString重写
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
2.如果不想某个进行序列化流本地文件,比如address对其保密,那么重信生成JavaBean即可,然后把自动生成的serialVersionUID删掉,在不想序列化流的地方加transient
- transient:瞬态关键字
作用:不会把当前属性序列化到本地文件当中
Student类:
public class Student implements Serializable {
@Serial
private static final long serialVersionUID = 650157805827481085L;
private String name;
private int age;
private transient String address;
public Student() {
}
public Student( String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
/**
* 获取
* @return address
*/
public String getAddress() {
return address;
}
/**
* 设置
* @param address
*/
public void setAddress(String address) {
this.address = address;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + ", address = " + address + "}";
}
}
序列化测试:
public static void main(String[] args) throws IOException {
Student stu = new Student("magua",25,"guangdoor");
ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("javaprogram1\\a.txt"));
oos.writeObject(stu);
oos.close();
}
反序列化测试:
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("javaprogram1\\a.txt"));
Student o = (Student) ois.readObject();
System.out.println(o);
ois.close();
}
可见地址无法被序列查询
小结:

5.3.4 序列化流和反序列化流的综合练习:用对象流读写多个对象

Stuend类同上,不用transient
序列化测试类:
public static void main(String[] args) throws IOException {
Student stu1 = new Student("magua",25,"guangdoor");
Student stu2 = new Student("zhangsan",26,"xinrimuli");
Student stu3 = new Student("lisi",27,"wuhu");
ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("javaprogram1\\a.txt"));
oos.writeObject(stu1);
oos.writeObject(stu2);
oos.writeObject(stu3);
oos.close();
}
反序列化测试类:
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("javaprogram1\\a.txt"));
Student o1 = (Student) ois.readObject();
Student o2 = (Student) ois.readObject();
Student o3 = (Student) ois.readObject();
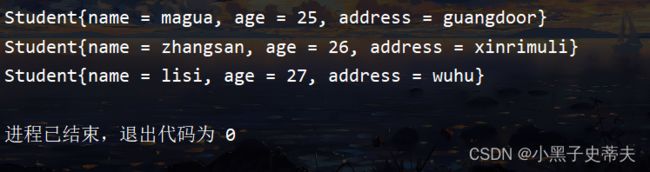
System.out.println(o1);
System.out.println(o2);
System.out.println(o3);
ois.close();
}
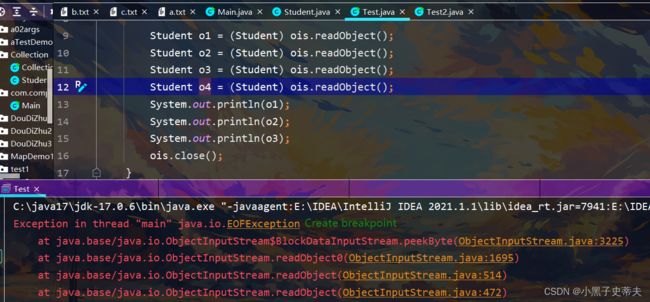
但是这样的代码真的好吗?
假设序列化对象是别人创建的,序列化了多少个忘记了,就只能到序列化的文件看,但是这是看不懂的。当进行反序列化的时候,就不知道序列化多少个了,总不能一直读读到出异常
解决方案:
如果要把多个对象序列化到本地文件当中,就一般都会把这些所有对象放到集合里面,再序列化集合就行了
序列化测试:
public static void main(String[] args) throws IOException {
Student stu1 = new Student("magua",25,"guangdoor");
Student stu2 = new Student("zhangsan",26,"xinrimuli");
Student stu3 = new Student("lisi",27,"wuhu");
ArrayList<Student> list =new ArrayList<>();
list.add(stu1);
list.add(stu2);
list.add(stu3);
ObjectOutputStream oos =new ObjectOutputStream(new FileOutputStream("javaprogram1\\a.txt"));
oos.writeObject(list);
oos.close();
}
反序列化测试:
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("javaprogram1\\a.txt"));
ArrayList<Student> list = (ArrayList<Student>)ois.readObject();//强转ois读取的对象为ArrayList
5.4 打印流


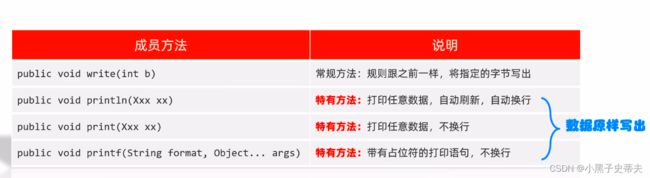
5.4.1 字节打印流
构成方法:

成员方法:
细说参数:
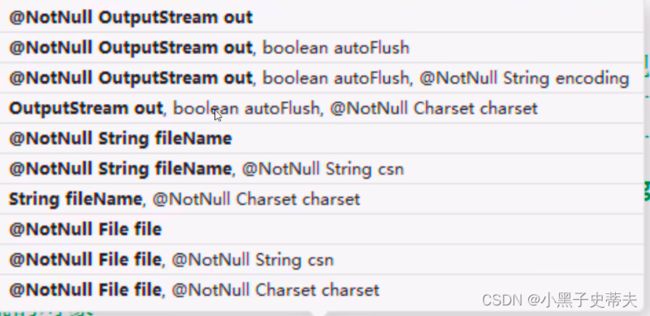
- 第一个构造我们可以传递字节输出流
- 第二个构造除了可传递字节输出流以外,还有boolean类型的变量autoFlush,自动刷新
- 第三个构造,有3个参数,第1参数字节输出流的基本流,第2参数自动刷新,第3参数字符串形式的encoding(字符编码)
- 第四个构造,与第三个构造类似,不过后面的字符编码是Charset类型的,不能写成字符串
- 第五个构造,直接关联文件的路径(字符串类型的)
- 下方构造是关联文件路径的,同理一、二、三、四,只不过有个字符编码类型是csn
public static void main(String[] args) throws IOException, ClassNotFoundException {
PrintStream ps = new PrintStream(new FileOutputStream("javaprogram1\\a.txt"),true,"UTF-8");
ps.println(97);//写出+自动刷新+自动换行
ps.print(true);
ps.printf("%s李在赣神魔%s","akm","阿克曼");
ps.close();
}

还有,System.out.println就用到了打印流
System是javabean里面已经定义好的一个类

out是在System里面的一个静态变量,System.out相当于获取的就是一个打印流的对象,不需要自己来创建,虚拟机会创建。其默认指向控制台

public static void main(String[] args) throws IOException {
//获取打印流的对象,此打印流在虚拟机启动的时候,有虚拟机创建,默认指向控制台
//特殊的打印流,系统中的标准输出流,不能关闭,在系统中是唯一的
PrintStream ps = System.out;
//调用打印流中的方法println
//写出数据,自动换行,自动刷新
ps.println("123");
ps.close();
//当流关闭了,再也无法打印
ps.println("aslkifdhas");
System.out.println("12314");
}

5.4.2 字符打印流
字符流底层有缓冲区,想要自动刷新需要开启true
构造方法:与字节打印流差不多

成员方法:基本上与字节打印流一模一样

代码展示:
public static void main(String[] args) throws IOException, ClassNotFoundException {
PrintWriter pw = new PrintWriter(new FileWriter("javaprogram1\\a.txt"),true);
pw.println("阿克曼,李在赣神魔");
pw.print("曼?不想look可以blue");
pw.close();
}

小结:

5.5 解压缩流

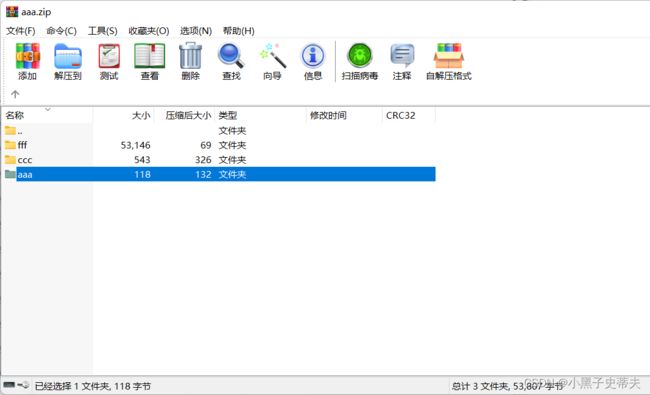
要想解压,电脑当中首先要有一个压缩包,那么这个压缩包要是zip作为后缀的,不能是其他


1.
public class Main {
public static void main(String[] args) throws IOException {
//1.创建一个File表示要解压的压缩包
File src = new File("F:aaa.zip");
//2.创建一个File表示解压的目的地
File dest = new File("F:\\");
//调用方法
unzip(src,dest);
}
public static void unzip(File src , File dest) throws IOException {
//解压的本质:把压缩包里面的每一个文件或者文件夹读取出来,按照层级拷贝到目的地当中
//创建一个解压缩流用来读取压缩包中的数据
ZipInputStream zip = new ZipInputStream(new FileInputStream(src));
//要先获取到压缩包里面的每一个zipentry对象
ZipEntry entry = zip.getNextEntry();
System.out.println(entry);
}
}

2.
public class Main {
public static void main(String[] args) throws IOException {
//1.创建一个File表示要解压的压缩包
File src = new File("F:aaa.zip");
//2.创建一个File表示解压的目的地
File dest = new File("F:\\");
//调用方法
unzip(src,dest);
}
public static void unzip(File src , File dest) throws IOException {
//解压的本质:把压缩包里面的每一个文件或者文件夹读取出来,按照层级拷贝到目的地当中
//创建一个解压缩流用来读取压缩包中的数据
ZipInputStream zip = new ZipInputStream(new FileInputStream(src));
//要先获取到压缩包里面的每一个zipentry对象
ZipEntry entry;
//保证zip包里面对各个对象文件不为空才循环
while((entry=zip.getNextEntry())!=null){
System.out.println(entry);
//isDirectory()用于判断是不是文件夹
if(entry.isDirectory()){
//是文件夹,则需要在目的地 dest处创建一个同样的文件夹
File file = new File(dest,entry.toString());//但是第二个参数不能写zip entry,没有这个类型,就要把其变成字符串才行
file.mkdirs();//如果创建目录,则该函数返回true
}else {
//为文件:则需要读取到压缩包中的文件,并把他存放到目的地dest文件夹中(按照层级目录进行存放)
FileOutputStream fos = new FileOutputStream(new File(dest,entry.toString()));
int b;
while((b=zip.read())!=-1){
//写到目的地
fos.write(b);
}
fos.close();
//表示在压缩包中的一个文件处理完了
zip.closeEntry();;
}
}
zip.close();
}
}

5.6 压缩流

5.6.1 压缩单个文件
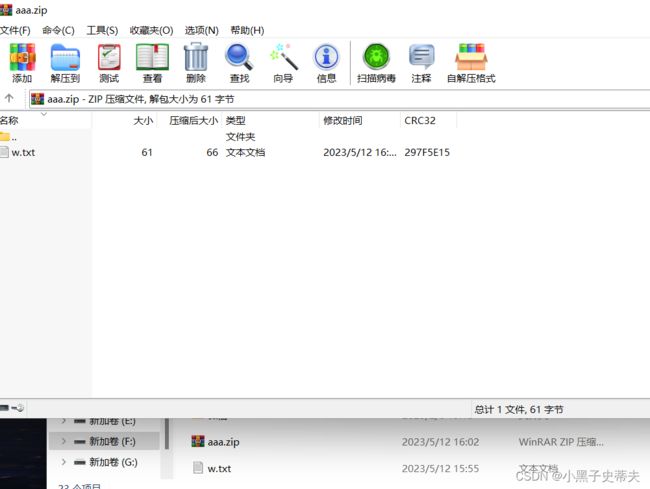
ublic class Main {
public static void main(String[] args) throws IOException {
//1.创建表示要压缩的文件
File src = new File("F:\\w.txt");
//2.创建表示压缩包的位置
File dest = new File("F:\\");
toZip(src,dest);
}
public static void toZip(File src, File dest) throws IOException {
//创建压缩流关联压缩包
//aaa.zip是在F盘的根目录下面的,压缩的时候把w.txt这文件写到压缩包当中,所以就不能只写一个dest(这个只是表示F盘的目录)
//要添加子级路径才可以
ZipOutputStream zos =new ZipOutputStream(new FileOutputStream(new File(dest,"aaa.zip")));
//创建zipentry对象,表示压缩包里面的每一个文件和文件夹
ZipEntry entry = new ZipEntry("w.txt");
//把ZipEntry放到压缩包当中 putNextEntry
zos.putNextEntry(entry);
//把src文件中的数据写到压缩包当中
FileInputStream fis = new FileInputStream(src);
int b;
while((b=fis.read())!=-1){
zos.write(b);
}
fis.close();
zos.closeEntry();
zos.close();
}
}
5.6.2 压缩多个文件
ZipEntry里面的参数:表示压缩包里面的路径
所以就可以在压缩包里面,创建不同层级的子文件夹
ZipEntry entry = new ZipEntry("bbb\\w.txt");
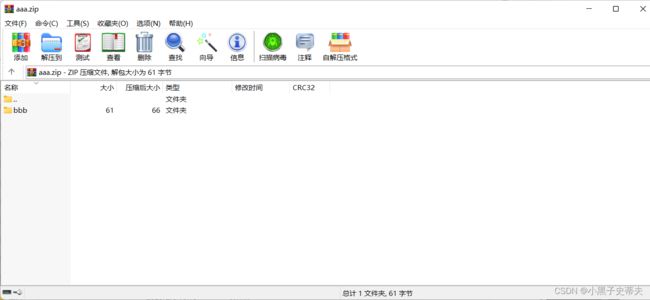
代码案例:
public class Main {
public static void main(String[] args) throws IOException {
//1.创建File对象表示要压缩的文件夹
File src = new File("F:\\aaa");
//2.创建表示压缩包放在哪里,也就是父级路径
File destParent = src.getParentFile();//根目录F:
//3.创建表示压缩包的路径
File dest = new File(destParent, src.getName() + ".zip");
//4.创建压缩流关联压缩包
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(dest));
//5.获取src里面的每一个文件,变成ZipEntry对象,放到压缩包当中
toZip(src,zos,src.getName());
//释放
zos.close();
}
//要获取src里面的每一个文件,变成ZipEntry对象,放入导压缩包当中
//参数一:数据流
//参数二:压缩流
//参数三:压缩包内部的路径
public static void toZip(File src,ZipOutputStream zos, String name) throws IOException {
//1.进入src文件夹
File[] files = src.listFiles();
//遍历src文件夹数组
for (File file : files) {
if(file.isFile()){
//如果为文件,则变成ZipEntry对象,放入到压缩包当中
//但是如果ZipEntry里面放入file.toString的话,里面会有创建根目录也就是D盘在压缩包里面
//当不想要根目录,想要数据源本身的文件夹路径开始时,传递src.getName(相当于传递了aaa)+\\+file.getName(文件名)
ZipEntry entry = new ZipEntry(src.getName() + "\\" + file.getName());
zos.putNextEntry(entry);
//读取文件中的数据写到压缩包
FileInputStream fis = new FileInputStream(file);
int b;
while((b=fis.read())!=-1){
zos.write(b);
}
fis.close();
zos.closeEntry();
}else {
//如果为文件夹-则递归
toZip(file,zos,name+"\\"+file.getName());
}
}
}
}
5.7 常用工具包 Commons-io


Commons-io使用步骤:

Commons-io 常见方法:
1.FileUtils类

2.IOUtils类

导入Commons-io到idea的lib中
当包可以展开时就说明导入成功

代码案例:
public class Main {
public static void main(String[] args) throws IOException {
File src1 = new File("javaprogram1\\a.txt");
File dest1 = new File("javaprogram1\\b.txt");
FileUtils.copyFile(src1,dest1); //复制文件src的内容到dest文件里面
File src2 = new File("F:\\aaa");
File dest2 = new File("F:\\bbb");
FileUtils.copyDirectory(src2,dest2);//复制aaa文件夹里面的内容到bbb文件夹当中
FileUtils.copyDirectoryToDirectory(src2,dest2);//复制aaa整个文件夹到bbb文件夹当中
FileUtils.deleteDirectory(src2);//删除文件夹aaa
FileUtils.cleanDirectory(dest2);//清空文件夹bbb
}
}
5.8 Hutool工具包


Hutool官网
Hutool中文使用文档
API帮助文档
代码案例:
public class Main {
public static void main(String[] args) throws IOException {
//FileUtil类的file:强大之处:可以便捷拼接路径
File file = FileUtil.file("F:\\", "aaa", "bbb");
System.out.println(file);
//FileUtil类的touch:当父级路径不存在时不会报错,会帮助把父级路径一起创建出来
File touch = FileUtil.touch(file);
System.out.println(touch);
//FileUtil类的writeLines:把集合种的数据写到文件中,覆盖
ArrayList<String> list1 = new ArrayList<>();
list1.add("abc");
list1.add("abc");
list1.add("abc");
File file2 = FileUtil.writeLines(list1, "F:\\a.txt", "UTF-8");
System.out.println(file2);
//FileUtil类的appendLines:把集合种的数据添加文件中,不覆盖
ArrayList<String> list2 = new ArrayList<>();
list2.add("was");
list2.add("was");
list2.add("was");
File file3 = FileUtil.writeLines(list2, "F:\\a.txt", "UTF-8");
System.out.println(file3);
//FileUtil类的readLines:指定字符编码,把文件中的数据读到集合中
List<String> list = FileUtil.readLines("F:\\a.txt", "UTF-8");
System.out.println(list);
}
}

6. IO流的综合练习
6.1 网络爬虫
6.1.1 爬取姓式

public class Test1 {
public static void main(String[] args) throws IOException {
//1.定义变量记录网址
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
String familyNameNet = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d";
//2.爬取数据,把王总上所有的数据拼接成一个字符串
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
String familyNameStr = webCrawler(familyNameNet);
//3.这些获取了网站的前端代码字符串,还需要通过正则表达式将想要的内容获取出来
ArrayList<String> familyNameTempList = getDate(familyNameStr,"(.{4})(,|。)",1);
System.out.println(familyNameTempList);
}
/*
作用:根据正则表达式获取字符串中的数据
参数一:代表完整的字符串
参数二:正则表达式
参数三:代表正则表达式的第几组,赵钱孙李。显然要获取在标点符号前面
返回值:真正想要的值
*/
private static ArrayList<String> getDate(String str, String regex,int index) {
//1.创建集合存放数据
ArrayList<String> list = new ArrayList<>();
//2.按照正则表达式的规则获取数据 Pattern.compile
Pattern pattern = Pattern.compile(regex);
//按照pattern的规则,将网址的前端代码字符串转换为姓氏
Matcher matcher = pattern.matcher(str);//文本匹配器
while(matcher.find()){//用find查找想要的文本元素是否被找到了
list.add(matcher.group(index));//将文本匹配器获取正则第index括号里面的东西
}
return list;
}
/*
作用:从网络中爬取数据,把数据拼接成字符串返回
形参:网址
返回值:爬取到所有的数据
*/
public static String webCrawler(String net) throws IOException {
//1.定义StringBuilder拼接爬取到的数据
StringBuilder sb = new StringBuilder();
//2.创建URL对象,这个就表示网址
//统一资源标识符(Uniform Resource Identifier ,URL)是采用一种特定语法标识一个资源的字符串。
//所标识的资源可能是服务器上的一个文件。Java的URL网络类可以让你通过URL去练级网络服务器并获取资源
URL url = new URL(net);
//3.链接上这个网址
//细节:必须要保证网络畅通,而且这个网址可以链接上
URLConnection conn = url.openConnection();
//4.读取数据,怎么读取?
//一般通过IO流读取,获取输入流读到,但是InputStream是字节流,网站有中文该怎么办?
//所以要转换为字符流InputStreamReader
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
int b;
while((b=isr.read())!=-1){
sb.append((char) b);//一定要强转,不然获取到的是数字
}
isr.close();
//5.直接返回StringBuilder的字符串形式
return sb.toString();
}
}

接下来的任务就是把集合里面的姓氏分开
6.1.2 爬取名字
AnyRule插件:在字符编码中获取范围,比如说中文的范围


女孩的网站名字需要重新找新的规则,不能以空格和回车为标准进行分割
所以要将一整行作为一个元素来进行分割处理

ArrayList<String> boyNameTempList = getDate(boyNameStr,"([\\u4E00-\\u9FA5]{2})(、|。)",1);//如果是(..)(、|。),这样获取的名字里面就有数字标点等组合,而要求的是只要有汉字
System.out.println(boyNameTempList);
ArrayList<String> girlNameTempList = getDate(girlNameStr,"((.. ){4}(..))",0);
System.out.println(girlNameTempList);
![]()
6.1.3 数据处理
//4.处理数据
//先处理familyNameTempList姓氏
//方案:把每一个姓氏拆开并添加到一个新的集合当中
ArrayList<String> familyNameList = new ArrayList<>();
for (String str : familyNameTempList) {
//此时str为 赵钱孙李 周吴郑王
//任务就是将每个姓氏都拆开
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
familyNameList.add(c+"");//以字符串的形式放进集合
}
}
System.out.println(familyNameList);
//男生名字
//处理方案:去除其中的重复元素
ArrayList<String> boyNameList = new ArrayList<>();
for (String str : boyNameTempList) {
if(!boyNameList.contains(str)){//如果男生名字集合里面没有相同的内容才指向添加
boyNameList.add(str);
}
}
System.out.println(boyNameList);
//女生的名字
//处理方案:把里面读到每一个元素用空格进行切割,就可以得到
ArrayList<String> girlNameList = new ArrayList<>();
for (String str : girlNameTempList) {
String[] arr = str.split(" ");
//获取到分割后的女孩名字字符串数组后,再将器每个元素循环出来放到集合当中
for (int i = 0; i < arr.length; i++) {
girlNameList.add(arr[i]);
}
}
System.out.println(girlNameList);

生成数据
public class Test1 {
public static void main(String[] args) throws IOException {
//1.定义变量记录网址
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
String familyNameNet = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d";
//2.爬取数据,把王总上所有的数据拼接成一个字符串
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
String familyNameStr = webCrawler(familyNameNet);
//3.这些获取了网站的前端代码字符串,还需要通过正则表达式将想要的内容获取出来
ArrayList<String> familyNameTempList = getDate(familyNameStr,"(.{4})(,|。)",1);
ArrayList<String> boyNameTempList = getDate(boyNameStr,"([\\u4E00-\\u9FA5]{2})(、|。)",1);//如果是(..)(、|。),这样获取的名字里面就有数字标点等组合,而要求的是只要有汉字
ArrayList<String> girlNameTempList = getDate(girlNameStr,"((.. ){4}(..))",0);
//4.处理数据
//先处理familyNameTempList姓氏
//方案:把每一个姓氏拆开并添加到一个新的集合当中
ArrayList<String> familyNameList = new ArrayList<>();
for (String str : familyNameTempList) {
//此时str为 赵钱孙李 周吴郑王
//任务就是将每个姓氏都拆开
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
familyNameList.add(c+"");//以字符串的形式放进集合
}
}
System.out.println(familyNameList);
//男生名字
//处理方案:去除其中的重复元素
ArrayList<String> boyNameList = new ArrayList<>();
for (String str : boyNameTempList) {
if(!boyNameList.contains(str)){//如果男生名字集合里面没有相同的内容才指向添加
boyNameList.add(str);
}
}
System.out.println(boyNameList);
//女生的名字
//处理方案:把里面读到每一个元素用空格进行切割,就可以得到
ArrayList<String> girlNameList = new ArrayList<>();
for (String str : girlNameTempList) {
String[] arr = str.split(" ");
//获取到分割后的女孩名字字符串数组后,再将器每个元素循环出来放到集合当中
for (int i = 0; i < arr.length; i++) {
girlNameList.add(arr[i]);
}
}
System.out.println(girlNameList);
//5.生成数据
//姓名(唯一)-性别-年龄
ArrayList<String> list = getInfos(familyNameList, boyNameList, girlNameList, 10, 10);
Collections.shuffle(list);
System.out.println(list);
//6.写出数据,用流
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\a.txt"));
for (String str : list) {
bw.write(str);
bw.newLine();
}
bw.close();
}
/*
作用:获取男生和女生的信息:比如张三-男-24
参数一:装着姓氏的集合
参数二:装着男生名字的集合
参数三:装着女生名字的集合
参数四:表示男生的个数
参数五:表示女生的个数
*/
public static ArrayList<String> getInfos(ArrayList<String> familyNameList,ArrayList<String> boyNameList,ArrayList<String> girlNameList,int boyCount,int girlCount){
//1.生成男生不重复的姓名
HashSet<String> boyhs = new HashSet<>();
while(true){
if(boyhs.size()==boyCount){
//男生名字足够了
break;
}
//随机通过Collections.shuffle打乱集合的方式进行
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
//拼接
boyhs.add(familyNameList.get(0)+boyNameList.get(0));
}
System.out.println(boyhs);
//2.生成女生不重复的姓名
HashSet<String> girlhs = new HashSet<>();
while(true){
if(girlhs.size()==girlCount){
//男生名字足够了
break;
}
//随机通过Collections.shuffle打乱集合的方式进行
Collections.shuffle(familyNameList);
Collections.shuffle(girlNameList);
//拼接
girlhs.add(familyNameList.get(0)+girlNameList.get(0));
}
System.out.println(girlhs);
//3.调试成名字-男-年龄 添加到集合当中
ArrayList<String> list = new ArrayList<>();
Random r = new Random();
//想要[18~27] - 18 = 0~9
//例如:尾部+1 => 9+1=10
for (String boyName : boyhs) {
int age = r.nextInt(10) + 18;//加上18后就到了18~27的范围选取
list.add(boyName+"-男"+"-"+age);
}
//4.调试成名字-女-年龄 添加到集合当中
for (String girlName : boyhs) {
int age = r.nextInt(8) + 18;//加上18后就到了16~25的范围选取
list.add(girlName+"-女"+"-"+age);
}
return list;
}
/*
作用:根据正则表达式获取字符串中的数据
参数一:代表完整的字符串
参数二:正则表达式
参数三:代表正则表达式的第几组,赵钱孙李。显然要获取在标点符号前面
返回值:真正想要的值
*/
private static ArrayList<String> getDate(String str, String regex,int index) {
//1.创建集合存放数据
ArrayList<String> list = new ArrayList<>();
//2.按照正则表达式的规则获取数据 Pattern.compile
Pattern pattern = Pattern.compile(regex);
//按照pattern的规则,将网址的前端代码字符串转换为姓氏
Matcher matcher = pattern.matcher(str);//文本匹配器
while(matcher.find()){//用find查找想要的文本元素是否被找到了
list.add(matcher.group(index));//将文本匹配器获取正则第index括号里面的东西
}
return list;
}
/*
作用:从网络中爬取数据,把数据拼接成字符串返回
形参:网址
返回值:爬取到所有的数据
*/
public static String webCrawler(String net) throws IOException {
//1.定义StringBuilder拼接爬取到的数据
StringBuilder sb = new StringBuilder();
//2.创建URL对象,这个就表示网址
//统一资源标识符(Uniform Resource Identifier ,URL)是采用一种特定语法标识一个资源的字符串。
//所标识的资源可能是服务器上的一个文件。Java的URL网络类可以让你通过URL去练级网络服务器并获取资源
URL url = new URL(net);
//3.链接上这个网址
//细节:必须要保证网络畅通,而且这个网址可以链接上
URLConnection conn = url.openConnection();
//4.读取数据,怎么读取?
//一般通过IO流读取,获取输入流读到,但是InputStream是字节流,网站有中文该怎么办?
//所以要转换为字符流InputStreamReader
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
int b;
while((b=isr.read())!=-1){
sb.append((char) b);//一定要强转,不然获取到的是数字
}
isr.close();
//5.直接返回StringBuilder的字符串形式
return sb.toString();
}
}
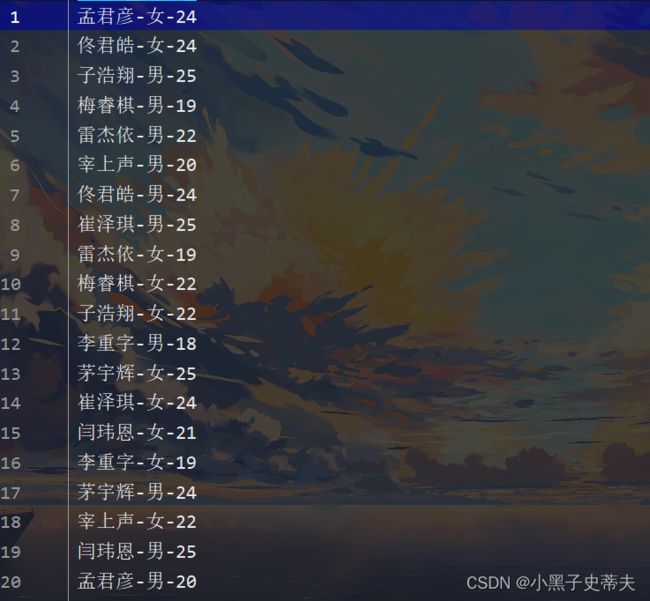
6.2 利用糊涂包生成假数据
Hutool包爬取
public class Test1 {
public static void main(String[] args) throws IOException {
//1.定义变量记录网址
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
String familyNameNet = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d";
//爬取利用糊涂包直接获取网址的前端代码
String familyNameStr = HttpUtil.get(familyNameNet);
String boyNameStr = HttpUtil.get(boyNameNet);
String girlNameStr = HttpUtil.get(girlNameNet);
//3.利用正则表达式获取数据,把其中符合要求的数据获取出来
// ArrayList familyNameTempList = getDate(familyNameStr,"(.{4})(,|。)",1);
// ArrayList boyNameTempList = getDate(boyNameStr,"([\\u4E00-\\u9FA5]{2})(、|。)",1);//如果是(..)(、|。),这样获取的名字里面就有数字标点等组合,而要求的是只要有汉字
// ArrayList girlNameTempList = getDate(girlNameStr,"((.. ){4}(..))",0);
//对照着写,可以写ArrayList集合接收,只不过该方法ReUtil.findAll返回的是List集合,要进行强转成ArrayList,要么就直接用List接收
List<String> familyNameTempList = ReUtil.findAll("(.{4})(,|。)", familyNameStr, 1);
List<String> boyNameTempList = ReUtil.findAll("([\\u4E00-\\u9FA5]{2})(、|。)", boyNameStr, 1);
List<String> girlNameTempList = ReUtil.findAll("((.. ){4}(..))", girlNameStr, 0);
System.out.println(familyNameTempList);
System.out.println(boyNameTempList);
System.out.println(girlNameTempList);
//4.处理数据和生成数据还是要自己写的
ArrayList<String> familyNameList = new ArrayList<>();
for (String str : familyNameTempList) {
//此时str为 赵钱孙李 周吴郑王
//任务就是将每个姓氏都拆开
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
familyNameList.add(c+"");//以字符串的形式放进集合
}
}
System.out.println(familyNameList);
//男生名字
//处理方案:去除其中的重复元素
ArrayList<String> boyNameList = new ArrayList<>();
for (String str : boyNameTempList) {
if(!boyNameList.contains(str)){//如果男生名字集合里面没有相同的内容才指向添加
boyNameList.add(str);
}
}
System.out.println(boyNameList);
//女生的名字
//处理方案:把里面读到每一个元素用空格进行切割,就可以得到
ArrayList<String> girlNameList = new ArrayList<>();
for (String str : girlNameTempList) {
String[] arr = str.split(" ");
//获取到分割后的女孩名字字符串数组后,再将器每个元素循环出来放到集合当中
for (int i = 0; i < arr.length; i++) {
girlNameList.add(arr[i]);
}
}
System.out.println(girlNameList);
//5.生成数据
//姓名(唯一)-性别-年龄
ArrayList<String> list = getInfos(familyNameList, boyNameList, girlNameList, 10, 10);
Collections.shuffle(list);
System.out.println(list);
//6.写出数据采用hutool包
//细节:
//糊涂包的相对路径,不是相当于当前项目而言的,而是相对class文件而言的
FileUtil.writeLines(list,"names.txt","UTF-8");
}
/*
作用:获取男生和女生的信息:比如张三-男-24
参数一:装着姓氏的集合
参数二:装着男生名字的集合
参数三:装着女生名字的集合
参数四:表示男生的个数
参数五:表示女生的个数
*/
public static ArrayList<String> getInfos(ArrayList<String> familyNameList,ArrayList<String> boyNameList,ArrayList<String> girlNameList,int boyCount,int girlCount){
//1.生成男生不重复的姓名
HashSet<String> boyhs = new HashSet<>();
while(true){
if(boyhs.size()==boyCount){
//男生名字足够了
break;
}
//随机通过Collections.shuffle打乱集合的方式进行
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
//拼接
boyhs.add(familyNameList.get(0)+boyNameList.get(0));
}
System.out.println(boyhs);
//2.生成女生不重复的姓名
HashSet<String> girlhs = new HashSet<>();
while(true){
if(girlhs.size()==girlCount){
//男生名字足够了
break;
}
//随机通过Collections.shuffle打乱集合的方式进行
Collections.shuffle(familyNameList);
Collections.shuffle(girlNameList);
//拼接
girlhs.add(familyNameList.get(0)+girlNameList.get(0));
}
System.out.println(girlhs);
//3.调试成名字-男-年龄 添加到集合当中
ArrayList<String> list = new ArrayList<>();
Random r = new Random();
//想要[18~27] - 18 = 0~9
//例如:尾部+1 => 9+1=10
for (String boyName : boyhs) {
int age = r.nextInt(10) + 18;//加上18后就到了18~27的范围选取
list.add(boyName+"-男"+age);
}
//4.调试成名字-女-年龄 添加到集合当中
for (String girlName : boyhs) {
int age = r.nextInt(8) + 18;//加上18后就到了16~25的范围选取
list.add(girlName+"-女"+age);
}
return list;
}
}


6.3 带权重的随机数

了解一下微服务:
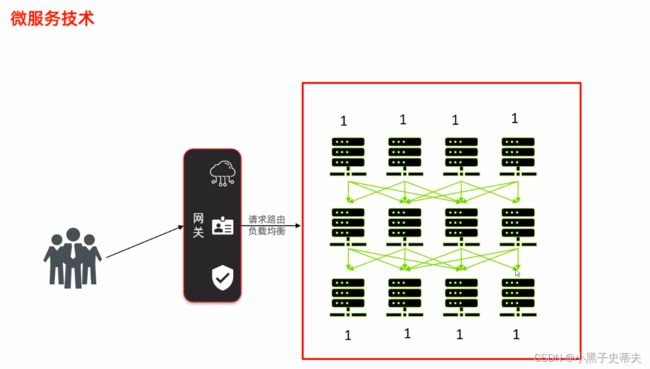
用户在上网的时候不知道该访问哪台服务器,所以在中间就会有一个服务网关,它会根据算法来计算哪个服务器人多了哪个人少了,然后在调整服务器的权重,让用户到人少的地方
梳理过程:

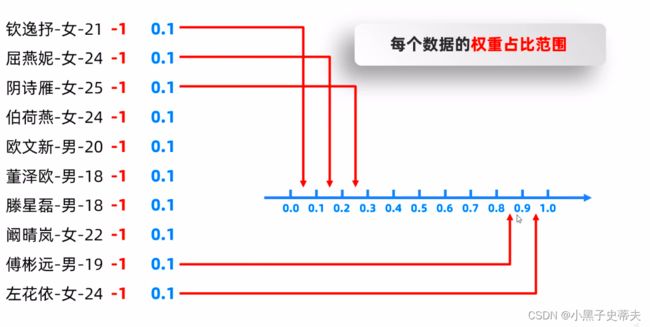
那么这10%的概率怎么计算呢?
之前学的是往集合里面添加七个1、三个0,再根据1和0的占比情况来决定概率

但是这样做只适合数据比较少的情况(男生和女生这两个种类),一旦数据比较多,种类一旦多起来了,就不能再这样子表示了
new方案:
去求出每个数据中的权重占比


Student类:
public class Student {
private String name;
private String gender;
private int age;
private double weight;
public Student() {
}
public Student(String name, String gender, int age, double weight) {
this.name = name;
this.gender = gender;
this.age = age;
this.weight = weight;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return gender
*/
public String getGender() {
return gender;
}
/**
* 设置
* @param gender
*/
public void setGender(String gender) {
this.gender = gender;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
/**
* 获取
* @return weight
*/
public double getWeight() {
return weight;
}
/**
* 设置
* @param weight
*/
public void setWeight(double weight) {
this.weight = weight;
}
public String toString() {
return name+"-"+gender+"-"+age+"-"+weight;
}
}
测试类:
public class Test1 {
public static void main(String[] args) throws IOException {
//1.把文件中所有的学生信息读取到内存当中,并封装一个Student对象再放到集合里,才方便统一进行管理
ArrayList<Student> StudnetList = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\names.txt"));
String line;
while((line=br.readLine())!=null){
String[] arr = line.split("-");
Student stu = new Student(arr[0], arr[1], Integer.parseInt(arr[2]), Double.parseDouble(arr[3]));
StudnetList.add(stu);
}
br.close();
System.out.println(StudnetList);
//2.计算总权重
double weight = 0;
for (Student stu : StudnetList) {
weight = weight + stu.getWeight();
}
System.out.println(weight);
//3.计算每个人的权重占比
double[] arr = new double[StudnetList.size()];
int index = 0;
for (Student stu : StudnetList) {
arr[index]=stu.getWeight()/weight;
index++;
}
System.out.println(Arrays.toString(arr));
//蓝色权重占比部分完成
//4.计算权重占比范围
for (int i = 1; i < arr.length; i++) {
arr[i] = arr[i]+arr[i-1];
}
System.out.println(Arrays.toString(arr));
//5.随机抽取
//获取一个0 ~ 1.0之间的随机数
double Rnumber = Math.random();//小数参与的计算是不精确的,当时不影响范围的选取
System.out.println(Rnumber);
//接下来判断number在arr中的位置,就不要一个一个遍历了,不够便捷
//二分查找法
//Arrays.binarySearch方法返回:-插入点-1 ,这个插入点表示如果在数组当中就应该是什么位置
//怎么获取number这个数据在数组当中的插入点位置?
//获取插入点 = -方法返回值-1
int result = -Arrays.binarySearch(arr,Rnumber)-1;
Student stu = StudnetList.get(result);
System.out.println(stu);
//6.被点到了,概率降低,修改当前学生的权重
double w = stu.getWeight() / 2;
stu.setWeight(w);
//7.把集合中的数据再次写到文件中
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\names.txt"));
for (Student student : StudnetList) {
bw.write(student.toString());
bw.newLine();
}
bw.close();
}
}


6.4 登录注册

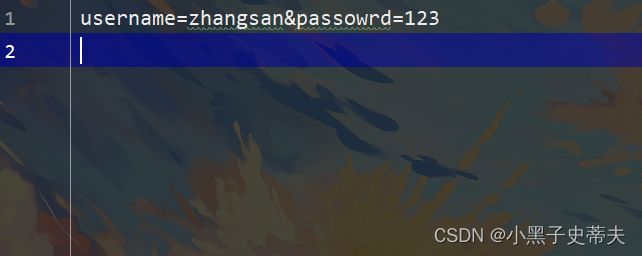
public static void main(String[] args) throws IOException {
//1.读取正确的用户名和密码
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line = br.readLine();//一行信息
br.close();
String[] userInfo = line.split("&");
System.out.println(Arrays.toString(userInfo));
String[] userList = userInfo[0].split("=");
String[] passwordList = userInfo[1].split("=");
System.out.println(Arrays.toString(userList));
System.out.println(Arrays.toString(passwordList));
String rightUsername = userList[1];
String rightPassword = passwordList[1];
//2.键盘录入输入
Scanner sc = new Scanner(System.in);
System.out.println("请输入用户名:");
String username = sc.nextLine();
System.out.println("请输入密码:");
String password = sc.nextLine();
//3.判断
if(rightUsername.equals(username)&&rightPassword.equals(password)){//不能用username == rightUsername && password==rightPassword,因为原本不是统一在栈里面的真实数据
System.out.println("登录成功");
}else {
System.out.println("登录失败");
}
}
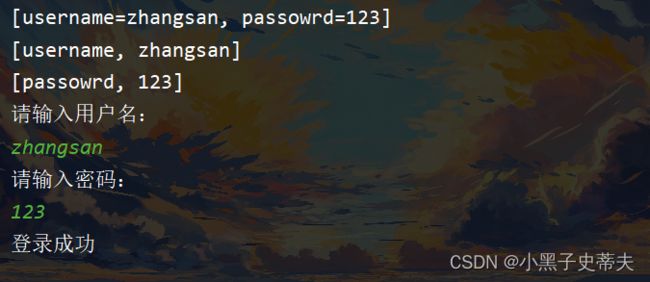
2.


修改以下代码:
public class Main {
public static void main(String[] args) throws IOException {
//1.读取正确的用户名和密码
BufferedReader br = new BufferedReader(new FileReader("javaprogram1\\a.txt"));
String line = br.readLine();//一行信息
br.close();
String[] userInfo = line.split("&");
System.out.println(Arrays.toString(userInfo));
String[] userList = userInfo[0].split("=");
String[] passwordList = userInfo[1].split("=");
String[] countList = userInfo[2].split("=");
System.out.println(Arrays.toString(userList));
System.out.println(Arrays.toString(passwordList));
System.out.println(Arrays.toString(countList));
String rightUsername = userList[1];
String rightPassword = passwordList[1];
int count = Integer.parseInt(countList[1]);
//2.键盘录入输入
Scanner sc = new Scanner(System.in);
System.out.println("请输入用户名:");
String username = sc.nextLine();
System.out.println("请输入密码:");
String password = sc.nextLine();
//3.判断
if(rightUsername.equals(username)&&rightPassword.equals(password)&&count<3){//不能用username == rightUsername && password==rightPassword,因为原本不是统一在栈里面的真实数据
System.out.println("登录成功");
writeInfo("username"+rightUsername+"&password="+rightPassword+"&count=0");
}else {
count++;
if(count<3){
System.out.println("登录失败,还剩下"+(3-count)+"次机会");
}else {
System.out.println("登录失败,用户账号被锁定");
}
writeInfo("username"+rightUsername+"&password="+rightPassword+"&count="+count);
}
}
public static void writeInfo(String content) throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\a.txt"));
bw.write(content);
bw.close();
}
}
6.5 配置文件

6.5.1 properties配置文件
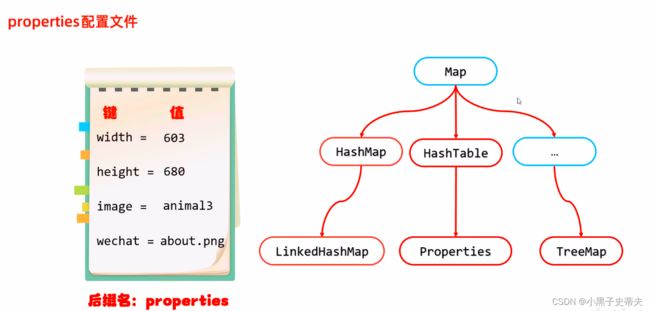
properties配置文件都是按照键值对的形式存储的
properties不是一个泛型类,那么在添加数据的时候就可以添加任意的数据类型,但是一般只会添加字符串类型的数据

properties作为map集合的基本用法:
public class Main {
public static void main(String[] args) {
//1.创建
Properties prop = new Properties();
//2.添加数据
prop.put("aaa","111");
prop.put("bbb","222");
prop.put("ccc","333");
prop.put("ddd","444");
//3.遍历集合
Set<Object> keys = prop.keySet();
for (Object key : keys) {
Object value = prop.get(key);
System.out.println(key+"="+value);
}
System.out.println("==================");
Set<Map.Entry<Object, Object>> entries = prop.entrySet();
for (Map.Entry<Object, Object> entry : entries) {
Object key = entry.getKey();
Object value = entry.getValue();
System.out.println(key+"="+value);
}
}
}

properties与IO流结合的操作:
public static void main(String[] args) throws IOException {
//1.创建
Properties prop = new Properties();
//2.添加数据
prop.put("aaa","111");
prop.put("bbb","222");
prop.put("ccc","333");
prop.put("ddd","444");
//麻烦的代码
/*BufferedWriter bw = new BufferedWriter(new FileWriter("javaprogram1\\a.txt"));
Set> entries = prop.entrySet();
for (Map.Entry entry : entries) {
Object key = entry.getKey();
Object value = entry.getValue();
bw.write(key+"="+value);
bw.newLine();
}
bw.close();
*/
//使用properties的特有方法
FileOutputStream fos = new FileOutputStream("javaprogram1\\a.txt");
prop.store(fos,"test");
fos.close();
//读取本地properties文件里面的数据
FileInputStream fis = new FileInputStream("javaprogram1\\a.txt");
prop.load(fis);
fis.close();
System.out.println(prop);
}
