doris 记录
doris 文档
—>>> Doris 官网
https://www.wenjiangs.com/doc/fgifo6j1
https://www.bookstack.cn/read/doris-1.1-en/GettingStarted.md
doris on k8s
https://github.com/mfanoffice/k8s-doris
doris 读写流程
https://blog.csdn.net/Hello_Java2018/article/details/124806318
doris 数据模型与存储结构
https://blog.csdn.net/Hello_Java2018/article/details/124806269
Apache DORIS安装使用测试报告
https://blog.csdn.net/hf200012/article/details/117925032
用户
root | admin 默认初始化密码为空
root@mysql-business-m8bp8:/# mysql -h 172.16.34.233 -P 9030 -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 5.7.37 Doris version 1.1.0-rc05-Unknown
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SET PASSWORD FOR 'root' = PASSWORD('123456');
Query OK, 0 rows affected (0.02 sec)
mysql>
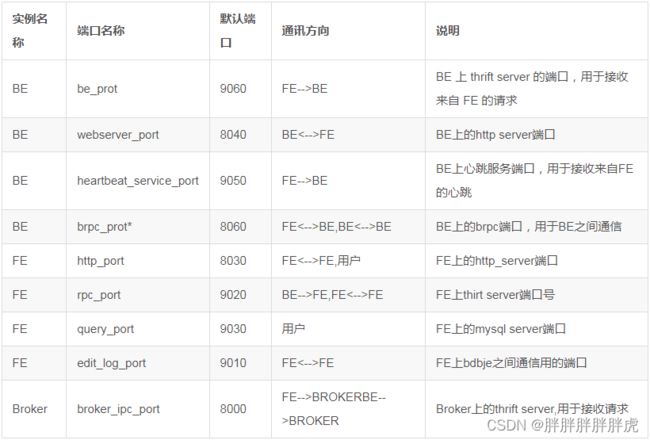
默认端口
shell
Stream Load
[root@sealos-k8s-node-10 /]# ll | grep table1_data
-rw-r--r-- 1 root root 55 8月 4 18:15 table1_data
[root@sealos-k8s-node-10 /]# curl --location-trusted -u root:123456 -H "label:table1_20170707" -H "column_separator:," -T table1_data http://127.0.0.1:8030/api/test_db/table1/_stream_load
{
"TxnId": 2,
"Label": "table1_20170707",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 5,
"NumberLoadedRows": 5,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 55,
"LoadTimeMs": 262,
"BeginTxnTimeMs": 44,
"StreamLoadPutTimeMs": 114,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 45,
"CommitAndPublishTimeMs": 56
}

alter
- 修改表字段
ALTER TABLE tbl1 MODIFY COLUMN k1 BIGINT SUM NULL DEFAULT “1”;
节点操作
show proc ‘/backends’
alter system add backend ‘xxxx:9050’
alter system drop backend ‘xxxx:9050’
show proc ‘/frontends’\G;
alter system add follower ‘xxxx:9010’
alter system add observer ‘xxxx:9010’
mysql> show proc '/frontends'\G;
*************************** 1. row ***************************
Name: 172.16.34.233_9010_1659595429680
IP: 172.16.34.233
HostName: sealos-k8s-node-10
EditLogPort: 9010
HttpPort: 8030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 1608049249
Join: true
Alive: true
ReplayedJournalId: 341905
LastHeartbeat: 2022-08-17 19:44:55
IsHelper: true
ErrMsg:
Version: 1.1.0-rc05-Unknown
CurrentConnected: Yes
1 row in set (0.05 sec)
show proc ‘/brokers’\G;
alter system add broker ‘xxx:8000’
alter system drop broker ‘xxx:8000’
mysql> show proc '/brokers'\G;
*************************** 1. row ***************************
Name: broker_name
IP: 172.16.34.233
HostName: sealos-k8s-node-10
Port: 8000
Alive: true
LastStartTime: 2022-08-04 16:12:29
LastUpdateTime: 2022-08-17 19:46:50
ErrMsg:
1 row in set (0.00 sec)
字段操作
### 删除字段
ALTER TABLE <tableName> DROP COLUMN <columeName>;
### 删除字段
ALTER TABLE <tableName> DROP COLUMN <columeName>;
### 新增默认为空的字段
ALTER TABLE <tableName> ADD COLUMN <columeName> <columeType> DEFAULT NULL;
### 新增不为空的字段
ALTER TABLE <tableName> ADD COLUMN <columeName> <columeType> NOT NULL;
###### demo
ALTER TABLE attence ADD COLUMN attence_name VARCHAR(20) DEFAULT NULL;
ALTER TABLE attence ADD COLUMN age VARCHAR(20) NOT NULL;
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv;
ALTER TABLE <tableName> MODIFY COLUMN <columeName> <columeType>(修改后的长度)
###### demo
ALTER TABLE indonesia.shopitem MODIFY COLUMN name varchar(400) NULL COMMENT "商品名字"
alter table <表名> change <字段名> <字段新名称> <字段的类型>。
元数据
https://www.wenjiangs.com/doc/3jmy8n6d
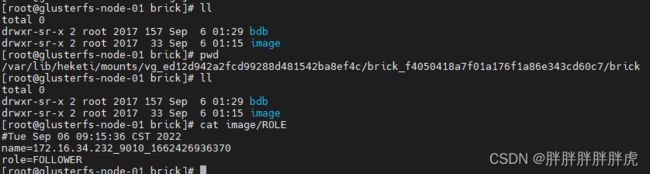
fe

- bdb 目录
我们将 bdbje 作为一个分布式的 kv 系统,存放元数据的 journal。这个 bdb 目录相当于 bdbje 的 “数据目录”。
其中 .jdb 后缀的是 bdbje 的数据文件。这些数据文件会随着元数据 journal 的不断增多而越来越多。当 Doris 定期做完 image 后,旧的日志就会被删除。所以正常情况下,这些数据文件的总大小从几 MB 到几 GB 不等(取决于使用 Doris 的方式,如导入频率等)。当数据文件的总大小大于 10GB,则可能需要怀疑是否是因为 image 没有成功,或者分发 image 失败导致的历史 journal 一直无法删除。
je.info.0 是 bdbje 的运行日志。这个日志中的时间是 UTC+0 时区的。我们可能在后面的某个版本中修复这个问题。通过这个日志,也可以查看一些 bdbje 的运行情况。
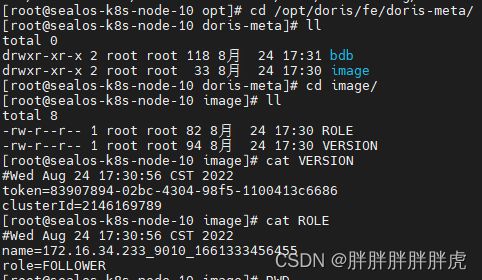
- image 目录
image目录用于存放 Doris 定期生成的元数据镜像文件。通常情况下,你会看到有一个 image.xxxxx 的镜像文件。其中 xxxxx 是一个数字。这个数字表示该镜像包含 xxxxx 号之前的所有元数据 journal。而这个文件的生成时间(通过 ls -al 查看即可)通常就是镜像的生成时间。
你也可能会看到一个 image.ckpt 文件。这是一个正在生成的元数据镜像。通过 du -sh 命令应该可以看到这个文件大小在不断变大,说明镜像内容正在写入这个文件。当镜像写完后,会自动重名为一个新的 image.xxxxx 并替换旧的 image 文件。
只有角色为 Master 的 FE 才会主动定期生成 image 文件。每次生成完后,都会推送给其他非 Master 角色的 FE。当确认其他所有 FE 都收到这个 image 后,Master FE 会删除 bdbje 中旧的元数据 journal。所以,如果 image 生成失败,或者 image 推送给其他 FE 失败时,都会导致 bdbje 中的数据不断累积。
ROLE 文件记录了 FE 的类型(FOLLOWER 或 OBSERVER),是一个文本文件。
VERSION 文件记录了这个 Doris 集群的 cluster id,以及用于各个节点之间访问认证的 token,也是一个文本文件。
ROLE 文件和 VERSION 文件只可能同时存在,或同时不存在(如第一次启动时)。
建表
建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition12,]])
[ENGINE = [olap|mysql|broker|hive]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)];
- 建表demo
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01
00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最
间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);
数据类型
https://blog.csdn.net/cai_and_luo/article/details/118600628
修改表参数
alter table <表名> set ("xxx" = "xxx")
分区
- Partition & Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照Hash的方式分桶,分桶的规则是要找用户指定的分桶列的值进行Hash后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
Tablet之间的数据是没有交集的,独立存储的。Tablet也是数据移动、复制等操作的最小物理存储单元。
Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
Range Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);
List Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);
AGGREGATE KEY 数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为 Key 列。而其余则为 Value 列。
定义列时,可参照如下建议:
Key 列必须在所有 Value 列之前。
尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串。
对于不同长度的整型类型的选择原则,遵循 够用即可。
对于 VARCHAR 和 CHAR 类型的长度,遵循 够用即可。
所有列的总字节长度(包括 Key 和 Value)不能超过 100KB。、
- 分区与分桶
Doris 支持两层的数据划分。第一层是 Partition,仅支持 Range 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。
也可以仅使用一层分区。使用一层分区时,只支持 Bucket 划分。
1)Partition
Partition 列可以指定一列或多列。分区列必须为 KEY 列。多列分区的使用方式在后面 多列分区 小结介绍。
不论分区列是什么类型,在写分区值时,都需要加双引号。
分区列通常为时间列,以方便的管理新旧数据。
分区数量理论上没有上限。
当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改。
Partition 支持通过 VALUES LESS THAN (…) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。通过,也支持通过 VALUES […) 指定同时指定上下界,生成一个左闭右开的区间。
综分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。通过 VALUES LESS THAN 语句增加分区时,分区的下界紧接上一个分区的上界。
不可添加范围重叠的分区。
2)Bucket
如果使用了 Partition,则 DISTRIBUTED … 语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。
分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
分桶列的选择,是在查询吞吐和 查询并发之间的一种权衡:
如果选择多个分桶列,则数据分布更均匀。如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的IO影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
分桶的数量理论上没有上限。
- 关于 Partition 和 Bucket 的数量和数据量的建议。
a. 一个表的 Tablet 总数量等于 (Partition num * Bucket num)。
b. 一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。
c. 单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。
当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。
在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。
一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。
举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个。50GB:32个。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。
表的数据量可以通过 show data 命令查看,结果除以副本数,即表的数据量。
show partitions from <表名>
分桶
tablet
tablet 相关:https://blog.csdn.net/ppfreedom/article/details/125021626
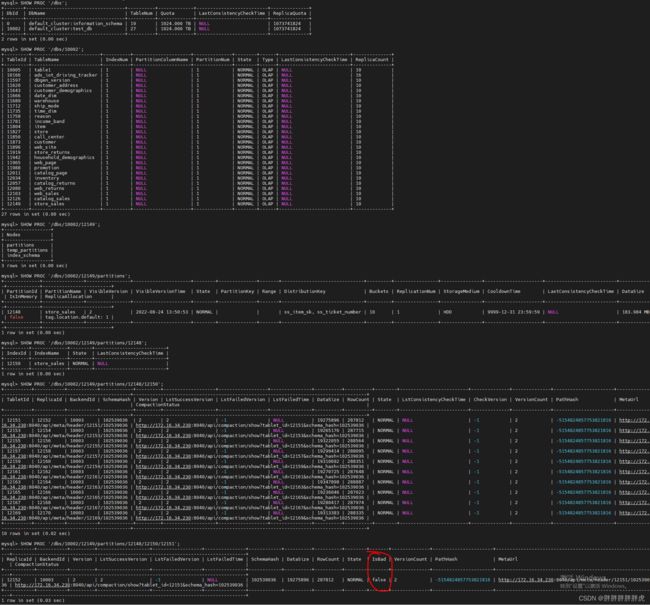
show tablet xxx
mysql> show tablet 11576;
+-------------------------+-------------+---------------+-------------+-------+---------+-------------+---------+--------+-------+------------------------------------------------------------+
| DbName | TableName | PartitionName | IndexName | DbId | TableId | PartitionId | IndexId | IsSync | Order | DetailCmd |
+-------------------------+-------------+---------------+-------------+-------+---------+-------------+---------+--------+-------+------------------------------------------------------------+
| default_cluster:test_db | store_sales | store_sales | store_sales | 10002 | 11574 | 11573 | 11575 | true | 0 | SHOW PROC '/dbs/10002/11574/partitions/11573/11575/11576'; |
+-------------------------+-------------+---------------+-------------+-------+---------+-------------+---------+--------+-------+------------------------------------------------------------+
1 row in set (0.00 sec)
be 数据存储


engine 引擎
示例中,ENGINE 的类型是 olap,即默认的 ENGINE 类型。在 Doris 中,只有这个
ENGINE 类型是由 Doris 负责数据管理和存储的。其他 ENGINE 类型,如 mysql、broker、
es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数
据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据。
数据模型
aggregate
-
SUM:求和,多行的 Value 进行累加。
-
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
-
replace_if_not_null
-
MAX:保留最大值。
-
MIN:保留最小值。
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
uniq
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `user_name`)
duplicate
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入
Duplicate数据模型来满足这类需求
sqlCREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`)
这种数据模型区别于 Aggregate 和 Uniq 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以。
这种数据模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储。
动态分区
"dynamic_partition.enable" = "true"
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
在实现方式上, FE会启动一个后台线程,根据fe.conf中dynamic_partition_enable 及 dynamic_partition_check_interval_seconds参数决定该线程是否启动以及该线程的调度频率。每次调度时,会在注册表中读取动态分区表的属性,并根据动态分区属性动态添加及删除分区。
CREATE TABLE example_db.dynamic_partition
(
k1 DATE,
k2 INT,
k3 SMALLINT,
v1 VARCHAR(2048),
v2 DATETIME DEFAULT "2014-02-04 15:36:00"
)
ENGINE=olap
DUPLICATE KEY(k1, k2, k3)
PARTITION BY RANGE (k1)
(
PARTITION p20200321 VALUES LESS THAN ("2020-03-22"),
PARTITION p20200322 VALUES LESS THAN ("2020-03-23"),
PARTITION p20200323 VALUES LESS THAN ("2020-03-24"),
PARTITION p20200324 VALUES LESS THAN ("2020-03-25")
)
DISTRIBUTED BY HASH(k2) BUCKETS 32
PROPERTIES(
"storage_medium" = "SSD",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-3",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "32"
);
demo:创建一张调度单位为天,不删除历史分区的动态分区表
create table student_dynamic_partition1
(id int,
time date,
name varchar(50),
age int
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10",
"replication_num" = "1"
);
properties
-
dynamic_partition.enable: 是否开启动态分区特性,可指定为 TRUE 或 FALSE。如果不填写,默认为 TRUE。 -
dynamic_partition.time_unit: 动态分区调度的单位,可指定为 DAY WEEK MONTH,当指定为 DAY时,动态创建的分区名后缀格式为yyyyMMdd,例如20200325。当指定为 WEEK 时,动态创建的分区名后缀格式为yyyy_ww即当前日期属于这一年的第几周,例如 2020-03-25 创建的分区名后缀为 2020_13, 表明目前为2020年第13周。当指定为 MONTH 时,动态创建的分区名后缀格式为 yyyyMM,例如 202003。 -
dynamic_partition.start: 动态分区的开始时间, 以当天为基准,超过该时间范围的分区将会被删除。如果不填写,则默认为Integer.MIN_VALUE 即 -2147483648。 -
dynamic_partition.end: 动态分区的结束时间, 以当天为基准,会提前创建N个单位的分区范围。 -
dynamic_partition.prefix: 动态创建的分区名前缀。 -
dynamic_partition.buckets: 动态创建的分区所对应的分桶数量。
Rollup
+----------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-------+---------+-------+
| siteid | int(11) | No | true | 10 | |
| citycode | smallint(6) | No | true | N/A | |
| username | varchar(32) | No | true | | |
| pv | bigint(20) | No | false | 0 | SUM |
| uv | bigint(20) | No | false | 0 | SUM |
+----------+-------------+------+-------+---------+-------+
ALTER TABLE table1 ADD ROLLUP rollup_city(citycode, pv);
物化视图
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过 CREATE MATERIALIZED VIEW 实现。
create materialized view store_amt as
select store_id, sum(sale_amt) from sales_records group by store_id;
SHOW ALTER TABLE MATERIALIZED VIEW FROM sales_records ;
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
| 22036 | sales_records | 2020-07-30 20:04:28 | 2020-07-30 20:04:57 | sales_records | store_amt | 22037 | 5008 | FINISHED | | NULL | 86400 |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
> create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+-----------------------------------------------------------------------------+
| Explain String |
+-----------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:<slot 2> `store_id` | <slot 3> sum(`sale_amt`) |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 4:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: <slot 2> `store_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:AGGREGATE (merge finalize) |
| | output: sum(<slot 3> sum(`sale_amt`)) |
| | group by: <slot 2> `store_id` |
| | |
| 2:EXCHANGE |
| |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: <slot 2> `store_id` |
| |
| 1:AGGREGATE (update serialize) |
| | STREAMING |
| | output: sum(`sale_amt`) |
| | group by: `store_id` |
| | |
| 0:OlapScanNode |
| TABLE: sales_records |
| PREAGGREGATION: ON |
| partitions=1/1 |
| rollup: store_amt |
| tabletRatio=10/10 |
| tabletList=22038,22040,22042,22044,22046,22048,22050,22052,22054,22056 |
| cardinality=0 |
| avgRowSize=0.0 |
| numNodes=1 |
+-----------------------------------------------------------------------------+
45 rows in set (0.006 sec)
数据导入
mysql> show load order by createtime desc limit 1\G
broker load
https://blog.csdn.net/hf200012/article/details/120431528
LOAD LABEL order_bill_2021_0915_3
(
DATA INFILE("hdfs://namenodeservice1/user/data/hive_db/data_ods.db/purchase_hive_iostock/*/*")
INTO TABLE ods_purchase_hive_iostock_delta
COLUMNS TERMINATED BY "\\x01"
FORMAT AS "orc" (lgort,mblnr,mblpo,werks,ebeln,ebelp,aufnr,rsnum,rspos,kdauf,kdpos,bwart,menge,meins,matnr,bukrs,waers,dmbtr,shkzg,bstme,bstmg,temp1,temp2,temp3,temp4,temp5,rq)
COLUMNS FROM PATH AS (budat)
SET (budat=budat,lgort=lgort,mblnr=mblnr,mblpo=mblpo,werks=werks,ebeln=ebeln,ebelp=ebelp,aufnr=aufnr,rsnum=rsnum,rspos=rspos,kdauf=kdauf,kdpos=kdpos,bwart=bwart,menge=menge,meins=meins,matnr=matnr,bukrs=bukrs,waers=waers,dmbtr=dmbtr,shkzg=shkzg,bstme=bstme,bstmg=bstmg,temp1=temp1,temp2=temp2,temp3=temp3,temp4=temp4,temp5=temp5,rq=rq)
where 1=1
)
WITH BROKER "hdfs_broker"
(
"dfs.nameservices"="my_cluster",
"dfs.ha.namenodes.my_cluster" = "nn1,nn2",
"dfs.namenode.rpc-address.my_cluster.nn1" = "222:8000",
"dfs.namenode.rpc-address.my_cluster.nn2" = "117:8000",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "ddd.COM",
"kerberos_keytab_content" = "BQHIININ1111URAAE="
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
mysql> show load order by createtime desc limit 1\G
*************************** 1. row ***************************
JobId: 76391
Label: label1
State: FINISHED
Progress: ETL:N/A; LOAD:100%
Type: BROKER
EtlInfo: unselected.rows=4; dpp.abnorm.ALL=15; dpp.norm.ALL=28133376
TaskInfo: cluster:N/A; timeout(s):10800; max_filter_ratio:5.0E-5
ErrorMsg: N/A
CreateTime: 2019-07-27 11:46:42
EtlStartTime: 2019-07-27 11:46:44
EtlFinishTime: 2019-07-27 11:46:44
LoadStartTime: 2019-07-27 11:46:44
LoadFinishTime: 2019-07-27 11:50:16
URL: http://192.168.1.1:8040/api/_load_error_log?file=__shard_4/error_log_insert_stmt_4bb00753932c491a-a6da6e2725415317_4bb00753932c491a_a6da6e2725415317
JobDetails: {"Unfinished backends":{"9c3441027ff948a0-8287923329a2b6a7":[10002]},"ScannedRows":2390016,"TaskNumber":1,"All backends":{"9c3441027ff948a0-8287923329a2b6a7":[10002]},"FileNumber":1,"FileSize":1073741824}
stream load
因数据质量问题,使用steam load方式导入,在导入时设置max_filter_ratio,默认是零容忍错误导入。
curl --location-trusted -u root -H "label:bigtable20210617_01" -H "column_separator:|" -H "max_filter_ratio:0.9" -T consumer_address.bat http://172.16.34.127:32031/api/test_db/consumer_address/_stream_load
routine load – kafka 流式导入
CREATE ROUTINE LOAD test_db.kafka_test on <doris表名>
columns terminated by ',',
columns(id, name, age)
PROPERTIES
(
"desired_concurrent_number"="1",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list"= "broker1:9091,broker2:9091",
"kafka_topic" = "my_topic",
"property.group.id" = "test_doris_group",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.enable.auto.commit" = "false"
-- "property.security.protocol" = "ssl",
-- "property.ssl.ca.location" = "FILE:ca.pem",
-- "property.ssl.certificate.location" = "FILE:client.pem",
-- "property.ssl.key.location" = "FILE:client.key",
-- "property.ssl.key.password" = "abcdefg"
);
#####
# 从指定的时间点开始消费
#####
CREATE ROUTINE LOAD example_db.test_job ON example_tbl
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "30",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200"
) FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092",
"kafka_topic" = "my_topic",
"property.kafka_default_offsets" = "2021-10-10 11:00:00"
);
- help show routine load
数据导出
export
help export
查询
explain
explain graph
explain
join 查询优化
–>>> https://cn.selectdb.com/cloud-docs/%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97/%E6%95%B0%E6%8D%AE%E6%9F%A5%E8%AF%A2/JOIN%E4%BC%98%E5%8C%96
broadcast join
shuffle join
colocation join
colocation join 功能,是一组拥有CGS的表组成一个CG。保证这些表对应的数据分片会落在同一个be节点上,那么使得两表再进行join的时候,可以通过本地数据进行join ,减少数据在节点之间的网络传输时间。
colocation group(CG):一个CG中会包含一张及以上的Table。在同一个group内的Table有着相同 Colocation Group Schema,并且有着相同的数据分片分布Colocation Group Schema(CGS):用于描述一个CG中的Table,和colocation 相关的通用的Schema信息。包括分桶列类型,分桶数和副本数等
为了使得 Table 能够有相同的数据分布,同一 CG 内的 Table 必须保证以下属性相同:
分桶列和分桶数
- 分桶列,即在建表语句中
DISTRIBUTED BY HASH(col1, col2, ...)中指定的列。分桶列决定了一张表的数据通过哪些列的值进行 Hash 划分到不同的 Tablet 中。同一 CG 内的 Table 必须保证分桶列的类型和数量完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。 - 副本数
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
查看查询计划,如果 Colocation Join 生效,则 Hash Join 节点会显示 colocate: true。
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
+----------------------------------------------------+
| Explain String |
+----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:`tbl1`.`k1` | |
| PARTITION: RANDOM |
| |
| RESULT SINK |
| |
| 2:HASH JOIN |
| | join op: INNER JOIN |
| | hash predicates: |
| | colocate: true |
| | `tbl1`.`k2` = `tbl2`.`k2` |
| | tuple ids: 0 1 |
| | |
| |----1:OlapScanNode |
| | TABLE: tbl2 |
| | PREAGGREGATION: OFF. Reason: null |
| | partitions=0/1 |
| | rollup: null |
| | buckets=0/0 |
| | cardinality=-1 |
| | avgRowSize=0.0 |
| | numNodes=0 |
| | tuple ids: 1 |
| | |
| 0:OlapScanNode |
| TABLE: tbl1 |
| PREAGGREGATION: OFF. Reason: No AggregateInfo |
| partitions=0/2 |
| rollup: null |
| buckets=0/0 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
+----------------------------------------------------+
- show proc ‘colocation_group’
修改
alter table <table名> set "colocation_with" = "group2"'
bucket shuffle join
Bucket Shuffle Join是在 Doris 0.14 版本中正式加入的新功能。旨在为某些Join查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询。
Doris支持的常规分布式Join方式包括了shuffle join和broadcast join。这两种join都会导致不小的网络开销:
举个例子,当前存在A表与B表的Join查询,它的Join方式为HashJoin,不同Join类型的开销如下:
Broadcast Join: 如果根据数据分布,查询规划出A表有3个执行的HashJoinNode,那么需要将B表全量的发送到3个HashJoinNode,那么它的网络开销是3B,它的内存开销也是3B。
Shuffle Join: Shuffle Join会将A,B两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为 A + B,内存开销为B。
在FE之中保存了Doris每个表的数据分布信息,如果join语句命中了表的数据分布列,使用数据分布信息来减少join语句的网络与内存开销,这就是Bucket Shuffle Join,原理如下图:

SQL语句为 A表 join B表,并且join的等值表达式命中了A的数据分布列。而Bucket Shuffle Join会根据A表的数据分布信息,将B表的数据发送到对应的A表的数据存储计算节点。Bucket Shuffle Join开销如下:
网络开销:B < min(3B, A + B)
内存开销:B <= min(3B, B)
可见,相比于Broadcast Join与Shuffle Join, Bucket Shuffle Join有着较为明显的性能优势。减少数据在节点间的传输耗时和Join时的内存开销。相对于Doris原有的Join方式,它有着下面的优点:
首先,Bucket-Shuffle-Join降低了网络与内存开销,使一些Join查询具有了更好的性能。尤其是当FE能够执行左表的分区裁剪与桶裁剪时。
其次,同时与Colocate Join不同,它对于表的数据分布方式并没有侵入性,这对于用户来说是透明的。对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
最后,它可以为Join Reorder提供更多可能的优化空间。
show variable like '%bucket_shuffle_join%'
set enable_bucket_shuffle_join = true
routine filter
routine filter旨在为某些 Join 查询在运行时动态生成过滤条件,来减少扫描的数据量,避免不必要的I/O和网络传输,从而加速查询
bucket shuffle join 与 shuffle join
- shuffle join:小表数据无法放入内存则进行 shuffle join ,将两张表都按照key进行Hash,然后进行join,分布到各个计算节点进行join
- bucket shuffle join:本地性能优化,减少数据在节点传输的消耗
在FE进行分布式查询规划时,优先选择的顺序为 Colocate Join -> Bucket Shuffle Join -> Broadcast Join -> Shuffle Join。但是如果用户显式hint了Join的类型,如:
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
则上述的选择优先顺序则不生效。
数据备份
创建一个远端仓库路径
CREATE REPOSITORY `hdfs_ods_dw_backup`
WITH BROKER `broker_name`
ON LOCATION "hdfs://hadoop1:8020/tmp/doris_backup"
PROPERTIES (
"username" = "",
"password" = ""
)
执行备份
语法:
BACKUP SNAPSHOT [db_name].{snapshot_name}
TO `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)],
...
)
PROPERTIES ("key"="value", ...);
示例:
BACKUP SNAPSHOT test_db.backup1
TO hdfs_ods_dw_backup
ON
(
table1
);
查看备份任务
SHOW BACKUP [FROM db_name]
查看远端仓库镜像
语法:
SHOW SNAPSHOT ON `repo_name`
[WHERE SNAPSHOT = "snapshot" [AND TIMESTAMP = "backup_timestamp"]];
- 示例一:查看仓库 hdfs_ods_dw_backup 中已有的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup;
- 示例二:仅查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份:
SHOW SNAPSHOT ON hdfs_ods_dw_backup WHERE SNAPSHOT = "backup1";
- 示例三:查看仓库 hdfs_ods_dw_backup 中名称为 backup1 的备份,时间版本为 “2021-05-05-15-34-26” 的详细信息:
SHOW SNAPSHOT ON hdfs_ods_dw_backup
WHERE SNAPSHOT = "backup1" AND TIMESTAMP = "2021-05-05-15-34-26";
取消备份
取消一个正在执行的备份作业语法:取消 test_db 下的 BACKUP 任务
CANCEL BACKUP FROM test_db;
备份恢复
将之前通过 BACKUP 命令备份的数据,恢复到指定数据库下。该命令为异步操作。提交成功后,需通过 SHOW RESTORE 命令查看进度。
仅支持恢复 OLAP 类型的表
支持一次恢复多张表,这个需要和你对应的备份里的表一致
使用语法
RESTORE SNAPSHOT [db_name].{snapshot_name}
FROM `repository_name`
ON (
`table_name` [PARTITION (`p1`, ...)] [AS `tbl_alias`],
...
)
PROPERTIES ("key"="value", ...);
说明:
同一数据库下只能有一个正在执行的 BACKUP 或 RESTORE 任务。
ON 子句中标识需要恢复的表和分区。如果不指定分区,则默认恢复该表的所有分区。所指定的表和分区必须已存在于仓库备份中
可以通过 AS 语句将仓库中备份的表名恢复为新的表。但新表名不能已存在于数据库中。分区名称不能修改。
可以将仓库中备份的表恢复替换数据库中已有的同名表,但须保证两张表的表结构完全一致。表结构包括:表名、列、分区、Rollup等等。
可以指定恢复表的部分分区,系统会检查分区 Range 或者 List 是否能够匹配。
PROPERTIES 目前支持以下属性:
“backup_timestamp” = “2018-05-04-16-45-08”:指定了恢复对应备份的哪个时间版本,必填。该信息可以通过 SHOW SNAPSHOT ON repo; 语句获得。
“replication_num” = “3”:指定恢复的表或分区的副本数。默认为3。若恢复已存在的表或分区,则副本数必须和已存在表或分区的副本数相同。同时,必须有足够的 host 容纳多个副本。
“timeout” = “3600”:任务超时时间,默认为一天。单位秒。
“meta_version” = 40:使用指定的 meta_version 来读取之前备份的元数据。注意,该参数作为临时方案,仅用于恢复老版本 Doris 备份的数据。最新版本的备份数据中已经包含 meta version,无需再指定。
使用示例
- 示例一
从 example_repo 中恢复备份 snapshot_1 中的表 backup_tbl 到数据库 example_db1,时间版本为 “2021-05-04-16-45-08”。恢复为 1 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_1`
FROM `example_repo`
ON ( `backup_tbl` )
PROPERTIES
(
"backup_timestamp"="2021-05-04-16-45-08",
"replication_num" = "1"
);
- 示例二
从 example_repo 中恢复备份 snapshot_2 中的表 backup_tbl 的分区 p1,p2,以及表 backup_tbl2 到数据库 example_db1,并重命名为 new_tbl,时间版本为 “2021-05-04-17-11-01”。默认恢复为 3 个副本:
RESTORE SNAPSHOT example_db1.`snapshot_2`
FROM `example_repo`
ON
(
`backup_tbl` PARTITION (`p1`, `p2`),
`backup_tbl2` AS `new_tbl`
)
PROPERTIES
(
"backup_timestamp"="2021-05-04-17-11-01"
);
演示
RESTORE SNAPSHOT test_db.backup1
FROM `hdfs_ods_dw_backup`
ON
(
table1 AS table_restore
)
PROPERTIES
(
"backup_timestamp"="2022-04-01-16-45-19"
);
查看恢复任务
可以通过下面的语句查看数据恢复的情况
SHOW RESTORE [FROM db_name]
取消恢复
下面的语句用于取消一个正在执行数据恢复的作业:取消 example_db 下的 RESTORE 任务。
CANCEL RESTORE FROM example_db;
删除备份仓库
该语句用于删除一个已创建的仓库。仅 root 或 superuser 用户可以删除仓库。这里的用户是指Doris的用户
语法:
DROP REPOSITORY `repo_name`;
说明:
删除仓库,仅仅是删除该仓库在 Doris 中的映射,不会删除实际的仓库数据。删除后,可以再次通过指定相同的 broker 和 LOCATION 映射到该仓库。
示例:删除名为 hdfs_ods_dw_backup 的仓库:
DROP REPOSITORY `hdfs_ods_dw_backup`;
Flink doris | dlink doris
Flink & doris 参数说明,数据类型对应:https://www.wenjiangs.com/doc/yuyigzb1
flink-doris-connector-1.13_2.11-1.0.3.jar
CREATE TABLE flink_doris (
siteid INT,
citycode SMALLINT,
username STRING,
pv BIGINT
)
WITH (
'connector' = 'doris',
'fenodes' = '172.16.34.233:8030',
'table.identifier' = 'test_db.table1',
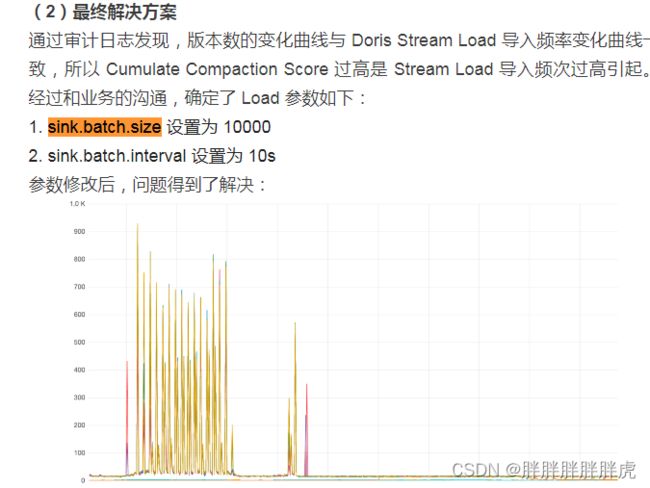
'sink.batch.size'='1000',
'sink.batch.interval' = '10000'
'username' = 'root',
'password' = '123456'
)
---
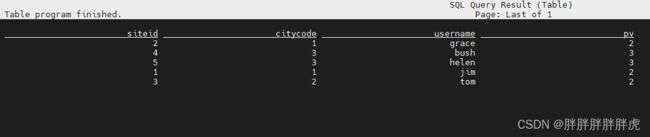
mysql> select * from flink_doris ;
+--------+----------+----------+------+
| siteid | citycode | username | pv |
+--------+----------+----------+------+
| 1 | 1 | jim | 2 |
| 4 | 3 | bush | 3 |
| 2 | 1 | grace | 2 |
| 3 | 2 | tom | 2 |
| 5 | 3 | helen | 3 |
+--------+----------+----------+------+
5 rows in set (0.03 sec)
doris batch
dlink

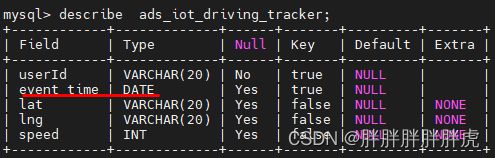
doris on es
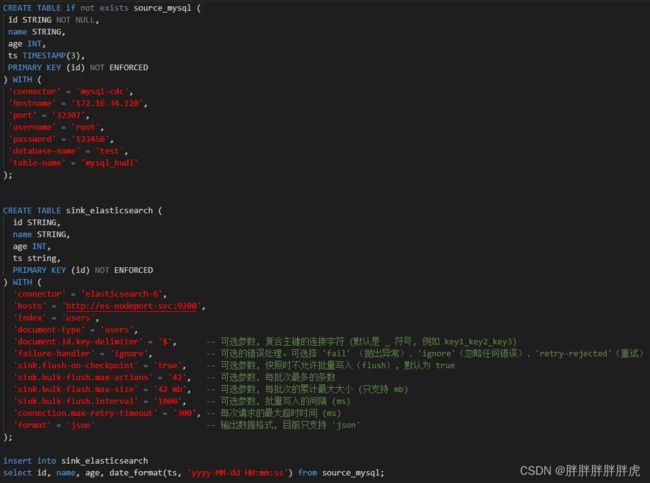

use test;
update mysql_hudi set age=30 where id='id14';
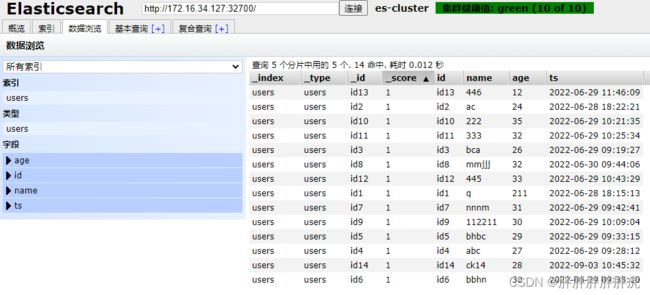
use test_db;
CREATE EXTERNAL TABLE if not exists `es_test1` (
`_id` varchar COMMENT "",
`id` varchar COMMENT "",
`name` varchar COMMENT "",
`age` int COMMENT "",
`ts` varchar COMMENT ""
) ENGINE=ELASTICSEARCH
PROPERTIES (
"hosts" = "http://172.16.34.127:32700",
"index" = "users",
"type" = "users",
"user" = "",
"password" = ""
);

问题记录
candidate backends is empty
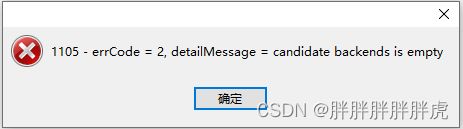
alter system add backend '172.16.34.230:9050'
show proc '/backends'
be节点只有一个,建表遇到问题
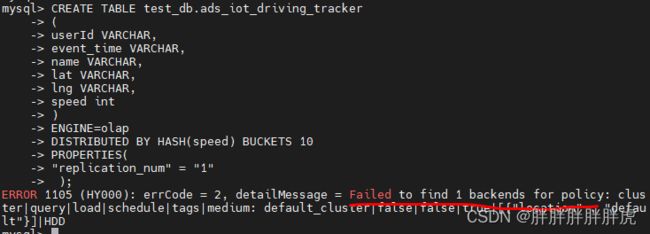
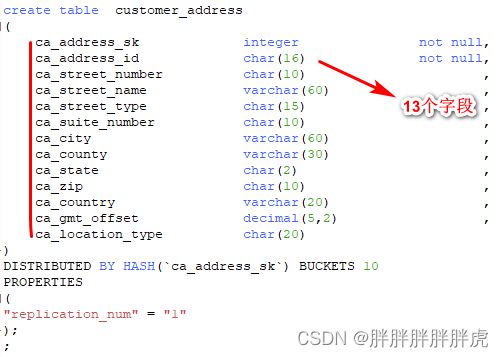
Create olap table should contain distribution desc |
create table customer_address
(
ca_address_sk integer not null,
ca_address_id char(16) not null,
ca_street_number char(10) ,
ca_street_name varchar(60) ,
ca_street_type char(15) ,
ca_suite_number char(10) ,
ca_city varchar(60) ,
ca_county varchar(30) ,
ca_state char(2) ,
ca_zip char(10) ,
ca_country varchar(20) ,
ca_gmt_offset decimal(5,2) ,
ca_location_type char(20)
)
;
DISTRIBUTED BY HASH(`ca_address_sk`) BUCKETS 10
###
Failed to find 3 backends for policy:
副本数默认为 3
create table customer_address
(
ca_address_sk integer not null,
ca_address_id char(16) not null,
ca_street_number char(10) ,
ca_street_name varchar(60) ,
ca_street_type char(15) ,
ca_suite_number char(10) ,
ca_city varchar(60) ,
ca_county varchar(30) ,
ca_state char(2) ,
ca_zip char(10) ,
ca_country varchar(20) ,
ca_gmt_offset decimal(5,2) ,
ca_location_type char(20)
)
DISTRIBUTED BY HASH(`ca_address_sk`) BUCKETS 10
PROPERTIES
(
"replication_num" = "3"
);
Column[event_time] type[VARCHAR] cannot be a range partition key.
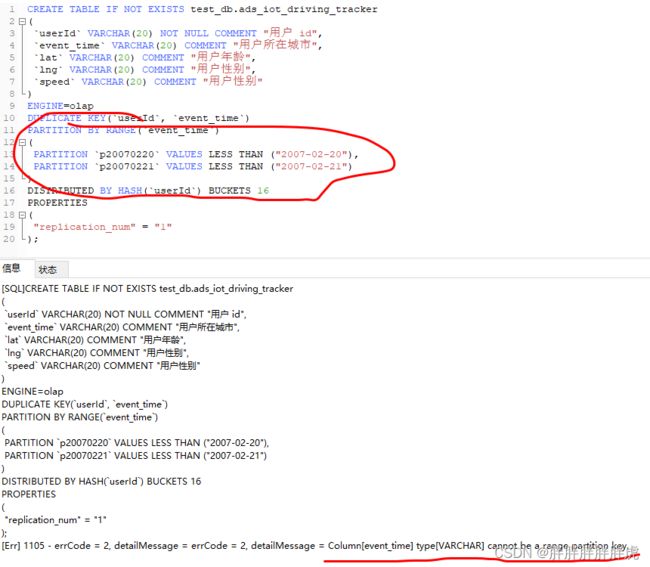
be节点为 Alive: false
mysql> show proc '/backends'\G;
*************************** 1. row ***************************
BackendId: 10003
Cluster: default_cluster
IP: 172.16.34.128
HostName: sealos-k8s-node-03
HeartbeatPort: 9050
BePort: 9060
HttpPort: 8040
BrpcPort: 8060
LastStartTime: 2022-09-03 10:35:08
LastHeartbeat: 2022-09-05 11:23:09
Alive: false
SystemDecommissioned: false
ClusterDecommissioned: false
TabletNum: 0
DataUsedCapacity: 0.000
AvailCapacity: 36.139 GB
TotalCapacity: 49.976 GB
UsedPct: 27.69 %
MaxDiskUsedPct: 27.69 %
Tag: {"location" : "default"}
ErrMsg: java.net.ConnectException: Connection refused (Connection refused)
Version: 1.1.0-rc05-Unknown
Status: {"lastSuccessReportTabletsTime":"2022-09-05 11:23:10","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false}
1 row in set (0.00 sec)
waiting to receive first heartbeat from frontend before doing tablet report
too many filtered rows
- 加载数据与对应doris表字段不一致,调整一致即可
- 对应doris表无对应数据分区,调整数据或分区即可
# cat customer_address.dat | curl --location-trusted -u root:123456 -H "label:customer_address2" -H "timeout:1200" -H "column_separator:|" -T - http://172.16.34.127:32030/api/test_db/customer_address/_stream_load
{
"TxnId": 58491,
"Label": "customer_address2",
"TwoPhaseCommit": "false",
"Status": "Fail",
"Message": "too many filtered rows",
"NumberTotalRows": 52,
"NumberLoadedRows": 0,
"NumberFilteredRows": 52,
"NumberUnselectedRows": 0,
"LoadBytes": 5502165,
"LoadTimeMs": 192,
"BeginTxnTimeMs": 0,
"StreamLoadPutTimeMs": 1,
"ReadDataTimeMs": 17,
"WriteDataTimeMs": 188,
"CommitAndPublishTimeMs": 0,
"ErrorURL": "http://172.16.34.230:8040/api/_load_error_log?file=__shard_0/error_log_insert_stmt_9649720a2d4907e9-86b0766ca5765485_9649720a2d4907e9_86b0766ca5765485"
}

删除最后一个分割符 sed 's/.$//'
# cat customer_address.dat | sed 's/.$//' | curl --location-trusted -u root:123456 -H "label:customer_address2" -H "timeout:1200" -H "column_separator:|" -T - http://172.16.34.127:32030/api/test_db/customer_address/_stream_load
{
"TxnId": 58492,
"Label": "customer_address2",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 50000,
"NumberLoadedRows": 50000,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 5452165,
"LoadTimeMs": 706,
"BeginTxnTimeMs": 2,
"StreamLoadPutTimeMs": 3,
"ReadDataTimeMs": 15,
"WriteDataTimeMs": 686,
"CommitAndPublishTimeMs": 13
}
数据类型不一致或字段长度导致 too many filtered rows


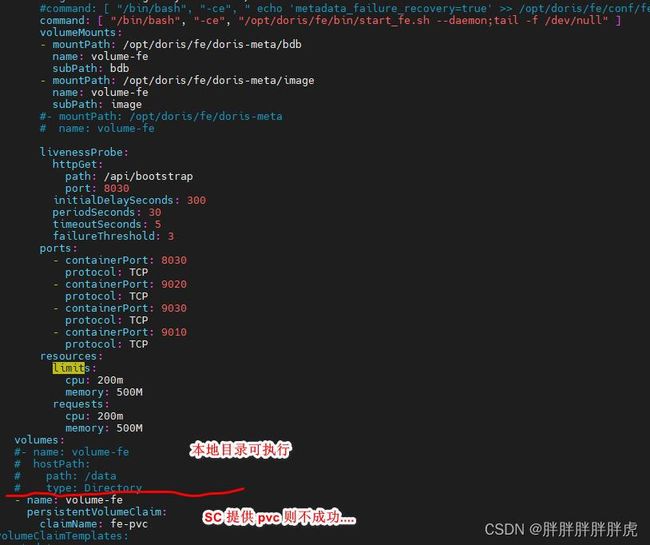
---->>> fe 节点启动问题(k8s 挂载 glusterfs)
https://mp.weixin.qq.com/s/ECCQCPgJ1-hTNpd6xJLkhA
containers:
- name: doris-fe
env:
- name: FE_IPADDRESS
valueFrom:
fieldRef:
fieldPath: status.podIP
image: docker-registry-node:5000/doris-fe:v1.1
command: [ "/bin/bash", "-ce", " /opt/doris/fe/bin/start_fe.sh --daemon;tail -f /dev/null" ]
volumeMounts:
- mountPath: /opt/doris/fe/doris-meta
name: volume-fe
...
volumeClaimTemplates:
- metadata:
name: volume-fe
annotations:
volume.beta.kubernetes.io/storage-class: "gluster-heketi"
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi

command: [ "/bin/bash", "-ce", "echo 'metadata_failure_recovery=true' >> /opt/doris/fe/conf/fe.conf ; /opt/doris/fe/bin/start_fe.sh --daemon;tail -f /dev/null" ]
只读权限…
[root@sealos-k8s-node-09 opt]# id
uid=0(root) gid=2017 groups=2017
[root@sealos-k8s-node-09 opt]# ll
total 0
drwxr-xr-x 1 1008 1008 16 7月 10 22:00 doris
[root@sealos-k8s-node-09 opt]# cd doris/fe/
[root@sealos-k8s-node-09 fe]# ll
total 24
drwxr-xr-x 1 1008 1008 20 9月 7 18:33 bin
drwxr-xr-x 1 1008 1008 31 9月 7 18:34 conf
drwxrwxrwx 1 1008 1008 30 9月 7 18:33 doris-meta
drwxr-xr-x 2 1008 1008 20480 7月 10 21:39 lib
drwxr-xr-x 1 1008 1008 106 9月 7 18:34 log
drwxr-xr-x 2 1008 1008 62 7月 10 21:39 spark-dpp
drwxr-xr-x 3 1008 1008 20 7月 10 21:39 webroot
[root@sealos-k8s-node-09 fe]# cd doris-meta/
[root@sealos-k8s-node-09 doris-meta]# ll
total 8
drwxrwsrwx 2 root 2017 4096 9月 7 18:33 bdb
drwxrwsrwx 2 root 2017 4096 9月 7 18:34 image
---->>> https://www.freeaihub.com/post/108710.html

注释掉挂载则可以启动…
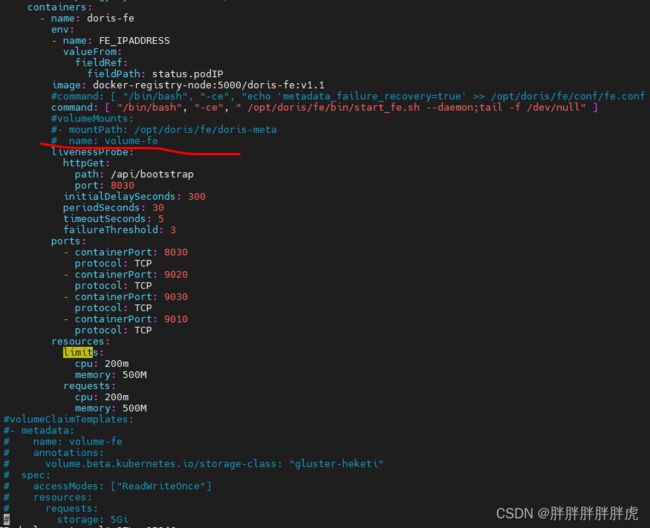
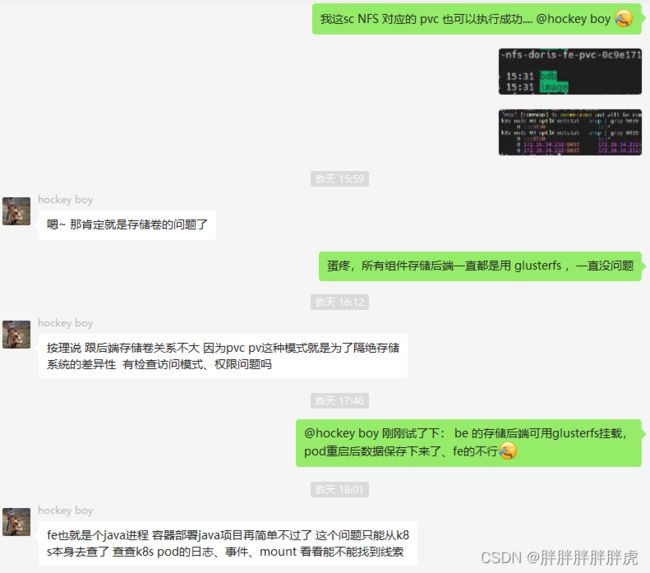
============ 分割线 ================
与存储后端有关,fe 挂载 sc NFS 可执行,但是挂载 glusterfs 则报错(存储卷实际是挂载上了);be 却可以挂载启动数据不丢
Log information is incorrect,problem is likely persistent. Environment is invalid and must be closed.
添加链接描述

https://www.cnblogs.com/1394htw/p/12843326.html

Failed to get scan range, no queryable replica found in tablet: 11093
2022-08-24 11:26:26,540 ERROR (Thread-54|105) [ReportHandler.deleteFromMeta():583] backend [10003] invalid situation. tablet[10009] has few replica[1], replica num setting is [1]

https://www.oschina.net/news/149604


Label Already Exists
https://www.modb.pro/db/57964
-
- lable不能显示删除,导入时可以不指定label,这样会自动生成
curl --location-trusted -u test:dorisdb H "column_separator:," -T table1_data http://192.168.80.32:8030/api/example_db/table1/_stream_load
-
- 导入时指定其它标签名称
curl --location-trusted -u test:dorisdb -H "label:table1_201707071" -H "column_separator:," -T table1_data http://127.0.1.1:8030/api/example_db/table1/_stream_load
doris 导入数据质量容错的问题
https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/stream-load-manual



企业应用
Doris在作业帮实时数仓中的应用实践
https://mp.weixin.qq.com/s/Gz_2ocus7rRqm2jp_m8Ctg
doris 博客记录
尚硅谷doris记录
https://jishuin.proginn.com/p/763bfbd794fa
https://jishuin.proginn.com/p/763bfbd794f9
doris记录
https://www.jianshu.com/nb/51720738
海量数据!秒级分析!Flink+Doris构建实时数仓方案
https://zhuanlan.zhihu.com/p/533329686
Apache Doris Parquet文件读取
https://www.modb.pro/db/44972
–> 好未来 x DorisDB:全新实时数仓实践
https://baijiahao.baidu.com/s?id=1707517995738130216&wfr=spider&for=pc
Apache Doris 基于 Bitmap的精确去重和用户行为分析
https://blog.bcmeng.com/post/doris-bitmap.html
张家锋 doris
https://www.modb.pro/u/312592
https://blog.csdn.net/hf200012/category_11130751.html
–>>>Apache Doris 实战指南
–>> 硬刚doris
https://mp.weixin.qq.com/s/D6DExlFjjmE05Db0afABXQ
https://mp.weixin.qq.com/s/YSifdvGLiKsIAafb7mXnWw
https://mp.weixin.qq.com/s/6kPJLw4WujJtZi2mE1Z4QA
https://mp.weixin.qq.com/s/obOBHTy8EXGSBH5cOv0z4g
https://mp.weixin.qq.com/s/0TlCm0FvgyfMB-kTSzoZ-w
Doris Connector 结合 Flink CDC 实现 MySQL 分库分表 Exactly Once精准接入
本篇文档演示怎么基于Flink CDC 并结合 Apache Doris Flink Connector 及 Doris Stream Load的两阶段提交,实现MySQL数据库分库分表实时高效的接入到 Apache Doris 数据仓库中进行分析。
https://segmentfault.com/a/1190000042187515
Doris 记录
https://blog.csdn.net/m0_54252387/category_11907725.html