SAM【2】:Personalize-SAM
文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
-
- 1.2.1. PerSAM
- 1.2.2. PerSAM-F
- 1.2.3. Improve DreamBooth
- 2. Method
-
- 2.1. Preliminary
-
- 2.1.1. A Revisit of Segment Anything
- 2.1.2. Personalized Segmentation Task
- 2.2. Training-free PerSAM
-
- 2.2.1. Positive-negative Location Prior
- 2.2.2. Target-guided Attention
- 2.2.3. Target-semantic Prompting
- 2.2.4. Cascaded Post-refinement
- 2.3. Fine-tuning of PerSAM-F
-
- 2.3.1. Ambiguity of Mask Scales
- 2.3.2. Learnable Scale Weights
- 2.4. Better Personalization of Stable Diffusion
-
- 2.4.1. A Revisit of DreamBooth
- 2.4.2. PerSAM-assisted DreamBooth
- 总结
前言
PerSAM 作为一种无需训练的 Segment Anything Model 的个性化方法,仅使用一次性数据,即用户提供的图像和粗略的掩码来高效地定制 SAM。但同时,PerSAM 更像是一种对高效选择 prompt 的尝试,而并非对 SAM 进行微调,如果想要将 PerSAM 应用在自然图像以外的数据集中,可能不会是一个好的选择。
原论文链接:Personalize Segment Anything Model with One Shot
1. Abstract & Introduction
1.1. Abstract
尽管 SAM 具有通用性,但针对特定视觉概念定制 SAM 而无需人工提示的问题仍有待探索。本文为 SAM 提出了一种无需训练的个性化方法,称为 PerSAM。
在只给定一张带有参考掩码的图像的情况下,PerSAM 首先通过位置先验(location prior)定位目标概念,然后通过目标引导注意(target-guided attention)、目标语义提示(target-semantic prompting)和级联后细化(cascaded post-refinement)三种技术在其他图像或视频中分割目标概念。
为了进一步减轻掩码模糊性,本文提出了一种高效的单次微调变体 PerSAM-F。在冻结整个 SAM 的基础上,我们为多尺度掩码引入了两个可学习的权重,在 10 秒内只需训练 2 个参数即可提高性能。
此外,本文的方法还可以增强 DreamBooth,为文本到图像的生成个性化稳定扩散,从而摒弃背景干扰,更好地学习目标外观。
1.2. Introduction
SAM 是最近提出的,具有强大 zero-shot 能力的,可提示分割范式。即把用户的提示作为输入,并返回预期的掩码。SAM 可接受的提示足够通用,包括点、方框、遮罩和自由形式文本,因此可以分割视觉环境中的任何内容。有关 SAM 的具体内容,可以参考我的另一篇 blog:SAM【1】:Segment Anything
但是,SAM 本身却无法分割特定的视觉概念。对于每张图片,用户都需要在不同的背景下定位目标对象,然后根据精确的提示激活 SAM 进行分割。
1.2.1. PerSAM
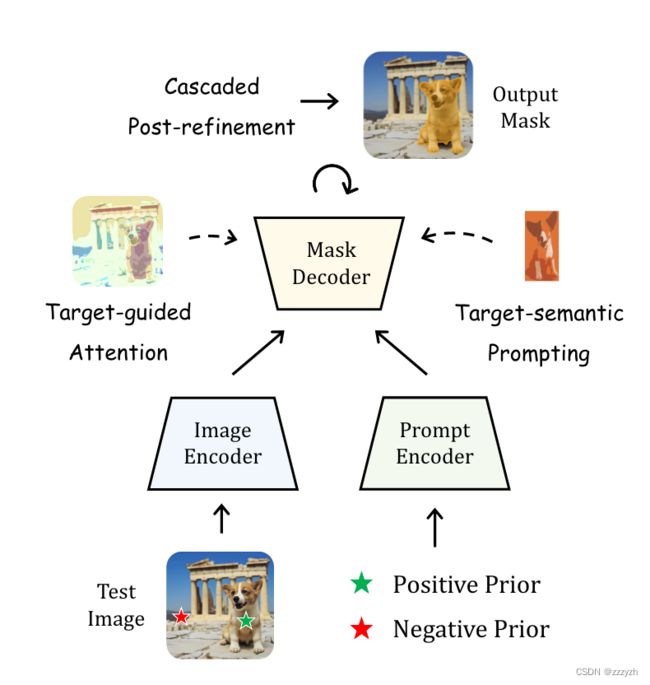
为此,本文提出了 PerSAM(具体运行流程如下图所示),一种无需训练的个性化 Segment Anything Model 方法。

PerSAM 仅使用一次数据(即用户提供的图像和粗略的掩码)就能高效地定制 SAM。具体而言,PerSAM 首先利用 SAM 的图像编码器和给定的掩码来编码参考图像中目标对象的嵌入。然后,PerSAM 计算目标对象与新测试图像上所有像素之间的特征相似性。在此基础上,PerSAM 选择两个点作为正负对,将其编码为提示标记,并作为 SAM 的位置先验。
Target-guided Attention- 本文通过计算的特征相似性来引导每个
token在SAM的解码器中映射cross-attention层 - 这迫使 prompt tokens 主要集中在前景目标区域,以进行有效的特征交互
- 本文通过计算的特征相似性来引导每个
Target-semantic Prompting- 为了更好地为
SAM提供高级目标语义,本文将原始的低级提示token与目标对象的embedding相融合,这为解码器提供了更充分的视觉线索来进行个性化分割
- 为了更好地为
Cascaded Post-refinement- 为了获得更精细的分割结果,本文采用了两步后细化策略
- 利用
SAM逐步完善其生成的掩码,这个过程只需要额外花费 100ms
1.2.2. PerSAM-F
通过上述的结构设计,PerSAM 可以在各种情况下对目标主体提供良好的个性化分割。但是,如果需要分割的主体包含层次结构,存在模棱两可的情况时,PerSAM 将很难确定合适大小的遮罩作为分割输出(SAM 会提供 3 个比例不同的分割遮罩做备选)。
微调变体 PerSAM-F 可以有效的缓解这个问题,即冻结整个 SAM,以保留其预先训练的知识,并在 10 秒内仅微调 2 个参数。
具体来说,本文使 SAM 能够以不同的掩码比例生成多个分割结果。为了针对不同对象自适应地选择最佳尺度,本文对每个尺度采用了可学习的相对权重,并进行加权求和作为最终的掩码输出。
1.2.3. Improve DreamBooth
本文建议利用 PerSAM 有效地分割目标对象,并只对少量拍摄图像中的前景区域进行稳定扩散监督,从而实现更多样化和更高保真的合成。
有效地帮助 DreamBooth 更好地微调 Stable Diffusion,实现个性化文本到图像的生成。
2. Method
2.1. Preliminary
2.1.1. A Revisit of Segment Anything
SAM 由三个主要部分组成:提示编码器、图像编码器和轻量级掩码解码器,本文分别将其称为 E n c P Enc_P EncP、 E n c I Enc_I EncI 和 D e c M Dec_M DecM
作为一个可提示的框架,SAM 输入图像 I I I 和一组提示 P P P(如前景或背景点、边界框或待完善的粗略遮罩)。SAM 首先利用 E n c I Enc_I EncI 获取输入图像特征,然后利用 E n c P Enc_P EncP 将人类给出的提示编码为 c c c 维 tokens,即
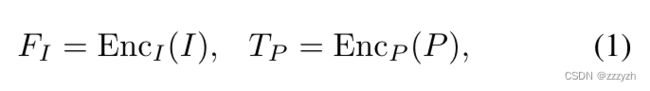
参数含义如下:
- F I ∈ R h × w × c F_I \in \mathbb{R}^{h \times w \times c} FI∈Rh×w×c
- 与读入数据的方法有关,不同读入数据的方法维度的排列会有差别(
SAM源代码中使用cv2读入数据)
- 与读入数据的方法有关,不同读入数据的方法维度的排列会有差别(
- T P ∈ R k × c T_P \in \mathbb{R}^{k \times c} TP∈Rk×c
- h , w h, w h,w:表示图像特征的分辨率
- k k k:表示提示的长度
然后,将编码后的图像和提示输入解码器 D e c M Dec_M DecM,进行基于注意力的特征交互。SAM 通过将多个可学习标记 T M T_M TM 作为提示标记的前缀来构建解码器的输入标记。这些掩码标记负责生成最终的掩码输出。解码过程可以表述为如下所示,其中 M M M 是 SAM 预测的 zero-shot mask
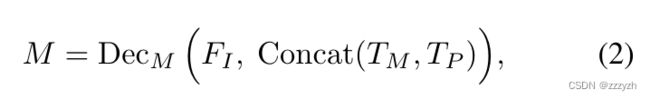
2.1.2. Personalized Segmentation Task
本文定义了一项新的个性化分割任务,用户只需提供一张参考图片和一个表示目标视觉概念的遮罩。给定的遮罩既可以是精确的分割图像,也可以是用户在线绘制的粗略草图。
2.2. Training-free PerSAM
Training-free PerSAM 的整体流程如下所示:
2.2.1. Positive-negative Location Prior
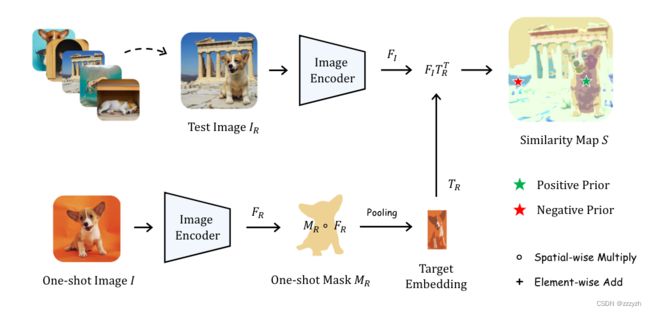
以用户提供的图像 I R I_R IR 和遮罩 M R M_R MR 为条件,PerSAM 利用 SAM 获得目标对象在新测试图像 I I I 上的位置先验,具体过程如下图所示:
- One-shot:除了 test image 外还需要提供一个基准 image
- 将 test image 和 one-shot image 通过 Image Encoder 编码后计算相似度
- 选择相似度最高和最低的两个点作为位置先验
- 最高 -> Positive,最低 -> Negative
- SAM 将倾向于分割正点周围的连续区域,而丢弃测试图像上的负点
具体公式推导如下
本文应用 SAM 的预训练图像编码器提取 I I I 和 I R I_R IR 的视觉特征,即

其中, F I , F R ∈ R h × w × c F_I, F_R \in \mathbb{R}^{h \times w \times c} FI,FR∈Rh×w×c
然后,利用参考掩码 M R ∈ R h × w × 1 M_R \in R^{h \times w \times} 1 MR∈Rh×w×1 从 F R F_R FR 中得出目标视觉概念内像素的特征,并采用平均池化方法将其全局视觉嵌入 T R ∈ R 1 × c T_R \in R^{1 \times c} TR∈R1×c 汇总为

其中, ∘ \circ ∘ 表示空间乘法。空间乘法通常用于合并或修改两幅图像或特征图的像素值。生成的矩阵或向量中的每个元素都是输入矩阵或向量中相应元素的乘积
有了目标嵌入 T R T_R TR,就可以通过计算 T R T_R TR 与测试图像特征 F I F_I FI 之间的余弦相似度 S S S 来获取位置置信度图:

为了给 SAM 提供测试图像上的位置先验,本文从 S S S 中选择了相似度值最高和最低的两个像素坐标,分别记为 P h P_h Ph 和 P l P_l Pl。前者代表目标物体最可能的前景位置,后者则反向表示背景。然后,将它们视为正负点对,并输入到提示编码器中,即
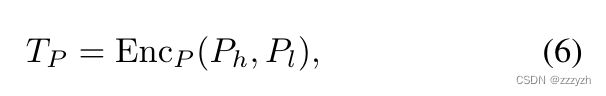
其中 T P ∈ R 2 × c T_P \in \mathbb{R}^{2 \times c} TP∈R2×c 作为 SAM 解码器的提示标记
这样,SAM 就会倾向于分割正点周围的连续区域,而丢弃测试图像上的负点
2.2.2. Target-guided Attention
本文进一步提出了一种更明确的 SAM 解码器交叉注意机制的指导方法,即把特征聚集集中在前景目标区域内
等式 5 中计算出的相似性图 S S S 可以清晰地指出测试图像上目标视觉概念内的像素,所以,本文利用 S S S 来调节每个标记到图像交叉注意层中的注意图

通过注意力偏置,token 会被迫捕捉更多与目标对象相关的视觉语义,而不是不重要的背景。这有助于在注意力层中进行更有效的特征交互,并以无需训练的方式提高 PerSAM 的最终分割精度
2.2.3. Target-semantic Prompting
原始的 SAM 只能接收携带低级位置信息的提示,如点或盒的坐标;为了加入更多个性化提示,本文建议额外利用目标概念的视觉嵌入 T R T_R TR 作为 PerSAM 的高级语义提示
具体来说,本文先将目标嵌入与等式 2 中的所有输入 tokens 进行 concat 操作

然后再输入如下图所示的每个解码器模块中,2.2.3 小节提到的 Target-guided Attention 在每个解码器模块中加入的位置也如下图所示

在简单 token 整合的帮助下,PerSAM 不仅能获得低层次的位置先验信息,还能获得带有辅助视觉线索的高层次目标语义
2.2.4. Cascaded Post-refinement
通过上述技术,用户可以从 SAM 解码器中获得了测试图像的初始分割掩码,但其中可能包括一些粗糙边缘和背景中的孤立噪声
为了进一步完善分割结果,本文将分割得到的初始分割掩码再次送回 SAM 中以进行两步后处理:
- 第一步,用初始分割掩码和之前的正负位置先验来提示
SAM解码器 - 第二步,计算出第一步中掩码的边界框,并用这个边界框提示解码器,以实现更精确的目标定位
上述的后处理操作仅需 100ms,但是可以实现高效地迭代细化
2.3. Fine-tuning of PerSAM-F
2.3.1. Ambiguity of Mask Scales
无需训练的 PerSAM 可以处理大多数情况,并获得令人满意的分割精度。但是,有些目标对象包含层次结构,在分割时会产生多个不同尺度的遮罩,这导致 PerSAM 有时无法选择合适的比例的 mask

如上图所示,平台顶部的茶壶由壶盖和壶身两部分组成。如果正先验(用绿星表示)位于壶身,而负先验(用红星表示)并不排除类似颜色的平台,那么 PerSAM 在分割时就会产生歧义
SAM 给出的解决方法即同时生成三个尺度的多个遮罩,分别对应物体的整体、部分和子部分。然后,用户需要手动从三个遮罩中选择一个,这种方法虽然有效,但会消耗额外的人力
2.3.2. Learnable Scale Weights
为实现具有适当遮罩比例的自适应分割,本文引入了一种微调变体 PerSAM-F
PerSAM-F 首先参考 SAM 的解决方案,输出三个比例的掩码,分别称为 M1、M2 和 M3。在此基础上,本文采用两个可学习的掩码权重( w 1 w_1 w1、 w 2 w_2 w2),并通过加权求和计算最终的掩码输出,

其中, w 1 w_1 w1、 w 2 w_2 w2 的初始值均为 1/3。为了学习最佳权重,本文在参考图像上进行一次微调,并将给定的掩码视为 GT
需要注意的是,本文冻结了整个 SAM 模型,以保留其预先训练的知识,并且只在 10 秒内微调了 w 1 w_1 w1、 w 2 w_2 w2 这两个参数
2.4. Better Personalization of Stable Diffusion
2.4.1. A Revisit of DreamBooth
对预先训练的文本到图像模型(如 stable diffusion 进行微调)以合成用户指定的特定视觉概念的图像
但是 DreamBooth 会计算整个重建图像与 GT 的 L2 loss,导致生成的图像中会包含冗余背景信息,从而覆盖新生成的背景
2.4.2. PerSAM-assisted DreamBooth
利用 PerSAM 或 PerSAM-F 对所有前景目标进行分割,并舍弃背景区域内像素的梯度反向传播
只对 stable diffusion 进行微调,以记忆目标对象的视觉外观,而不对背景进行监督,以保持其多样性

总结
本文最突出的贡献有以下两点:
- 通过 one-shot,模型不再需要每次都从 mask 中生成 prompt,这对于医学图像这种获取图像标签较为困难的工作有着非常重要的借鉴意义
- 同时,fine-tune 模型是一个体量非常庞大的工作,本文提出的方法只需要 2 个参数就可以定制化
SAM,这对之后SAM的微调工作指明了一个新的方向
参考博客