STL容器
C++ STL
STL实现原理及其实现
STL(Standard Template Library,标准模板库),提供了六大组件,可以相互之间组合套用,这六大组件分别是:容器(Containers),算法(Algorithms),迭代器(Iterators),仿函数(Functors),适配器(Adaptors),空间配置器(Allocator)。
STL六大组件的交互关系:
- 容器通过空间配置器取得数据存储空间。
- 算法通过迭代器访问和处理容器中的内容。
- 仿函数可以协助算法完成不同的策略变化。仿函数类似函数,可以像对象一样被传递。
- 适配器可以修饰容器和仿函数。适配器可以改变容器的接口和仿函数的行为。
- 空间配置器负责管理和释放容器的内容。
- 迭代器提供了一致的方法来访问容器中的元素。
总结一下,容器负责存储,算法负责处理,迭代器连接容器和算法,仿函数定义算法策略,适配器修饰组件,空间配置器管理内存。
1. 容器
容器是用来管理和存储各种数据结构的。stl提供了多种容器,如vector、list、deque、set、map等,从实现角度来看,STL容器是一种class template。
2.算法
算法是对容器中数据进行操作和处理的函数,如sort、find、copy、for_each等。从实现角度来看,STL算法是一种function template。
3. 迭代器
迭代器是算法和容器之间的桥梁,共有五种类型,从实现角度来看,迭代器是一种将operator*、operator->、operator++、operator-等指针相关操作予以重载的class template。
STL中的容器有都附带有自己的专属迭代器,这些迭代器的实现由容器的设计者根据容器的内部结构来完成。虽然不同容器可能有不同的迭代器实现,但它们都会遵循迭代器的借口规范,以保证算法可以与不同容器一起工作。
原生指针(nation pointer)也是一种迭代器。
4.仿函数
仿函数是行为类似函数,可以作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或class template。
5. 适配器
适配器是一种用来修饰容器或者仿函数或迭代器的借口的东西。
适配器允许同一算法作用在不同类型的容器上,或者改变仿函数对象的行为。
STL提供的queue和stack是数据结构,看似容器实际上更像是容器适配器,因为它们底层依赖于deque,并通过利用deque来完成操作,从而无需关心具体实现细节,专注于提供的队列和栈操作。
6. 空间配置器
空间配置器负责空间的配置和管理。从实现角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的class template。
通常的std::allocator分配器包括allocate和deallocate两个函数,它们分别使用operator new()和operator delete(),而这两个操作的底层实际上是通过调用malloc()和free()来实现的。然而,使用malloc()在每次分配时会带来额外的开销,因为每个分配的元素都需要附加的信息。
STL的优点
-
高可重用性
STL中几乎所有代码都采用了模板类和模板函数的方式实现,这使得代码可以根据不同的数据类型进行实例化,从而提供了更好的代码重用性。
-
高性能
STL的容器和算法都经过高度优化,底层实现采用了高效的数据结构和算法。例如,关联容器如map和set利用红黑树实现,能够在大规模数据中高效地进行查找和插入操作,从而提供卓越的性能。
-
高移值性
STL的设计使得在不同的项目和平台之间移植代码变得更加容易。
-
数据和操作分离
STL将数据和操作分开,这是其重要特性之一。容器类别负责数据的管理,而算法定义了操作的方式。迭代器则作为中间层,将容器和算法联系在一起。这种分离使得代码更加模块化,易于维护和扩展。
string容器
string是字符容器,内部维护了一个动态的字符数组。
与普通的字符数组相比,string容器有三个优点:1. 使用时不必考虑内存分配和释放的问题;2. 他可以动态管理内存(可扩展);3. 提供了大量操作容器的API。
劣势:1. 由于需要动态管理内容和支持丰富的操作,string容器可能在某些情况下不如简单的字符数组高效;2. string容器占用的内容比字符数组更多。
构造和析构
-
构造string容器
-
string():创建一个空字符串。string str1; -
string(const char* s):从 C 风格字符串创建。string str2("hello"); -
string(const string& str):复制构造函数string str3(str2); -
string(const char* s, size_t n):从 C 风格字符串的前 n 个字符创建。string str4("hello world", 5); // "hello" -
string(const string& str, size_t pos, size_t n):从另一个字符串的子串创建。string str5(str2, 1, 3); // "ell" -
string(size_t n, char c):创建一个包含 n 个字符 c 的字符串。string str6(5, 'a'); // "aaaaa"
-
析构string容器
~string() 负责释放分配给字符串的内存。
输入输出
-
输入
-
cin
使用cin进行输入
- 输入时,遇到空格、制表符、或回车会终止。
string s;
cin >> s;
cout << s << endl; // 输出用户输入的字符串直到空格、制表符或回车。
-
getline
- 可以读取整行,知道用户按下Enter键。
- 在使用
getline之前,需要包含头文件
#include -
输出
-
使用C++11新特性的for
string s1 = "abcdefh";
for(auto c:s1){
cout<<c<<" ";
}
-
使用运算符[] +size()函数
s1[0]; s1[1];
-
使用迭代器
string s1 = "hello world";
for(auro i = s1.begin(); i != s1.end(); i++){
cout<< *i <<" ";
}
比较操作 compare
-
比较两个字符串是否相等
bool operator==(const string &str1, const string &str2) const;
-
比较当前字符串和另一个字符串的大小
int compare(const string &str) const;
此函数返回一个整数,用于表示两个字符串的比较结果:
- 如果返回值 < 0,则当前字符串小于
str。 - 如果返回值 = 0,则两个字符串相等。
- 如果返回值 > 0,则当前字符串大于
str。
-
比较当前字符串的子串和另一个字符串
int compare(size_t pos, size_t n, const string &str) const;
从当前字符串的 pos 位置开始,取 n 个字符组成的子串,并与 str 进行比较。
-
比较两个字符串的特定子串
int compare(size_t pos, size_t n, const string &str, size_t pos2, size_t n2) const;
此函数比较当前字符串从 pos 位置开始的 n 个字符组成的子串,与 str 中从 pos2 位置开始的 n2 个字符组成的子串。
-
与C风格字符串比较
int compare(const char *s) const;
int compare(size_t pos, size_t n, const char *s) const;
int compare(size_t pos, size_t n, const char *s, size_t pos2) const;
这些函数允许您将C++的 string 对象与C风格字符串(也即 char 指针)进行比较。逻辑与之前的比较函数类似,但目标是C风格字符串。
compre()函数有异常,慎用
特性操作
-
max.size()
查询string对象的最大长度,这个值很大,通常不使用,意义不大。
-
capacity()
容器是已为字符串分配的内存大小(以字符为单位)。
此函数返回以为字符串分配的内存。
-
length() 与 size()
这两个函数都显示字符串的长度。唯一不同的是,length()是返回字符串语义的长度,size()是返回容器语义的长度。对于std::string而言,这两者是等价的。
std::string str = "Hello";
std::cout << "Length of string: " << str.length() << std::endl;
std::cout << "Size of string: " << str.size() << std::endl;
-
empty()
判断容器是否为空,如果字符串长度为0,该函数返回ture。
-
clear()
清空容器内所有内容,使其长度为0。
-
shrink_to_fit()
请求释放未使用的内存,使字符串容量与其大小匹配。
std::string str = "Hello, World!Hello, World!Hello, World!";
std::cout << "Capacity before shrink: " << str.capacity() << std::endl;
str = "Hi";
str.shrink_to_fit();
std::cout << "Capacity after shrink: " << str.capacity() << std::endl;
-
reserve(size_t size)
请求改变字符串的容量。如果你知道字符串将变得很大,可以预先设置容量,以避免多次重新分配。
std::string str;
std::cout << "Initial capacity: " << str.capacity() << std::endl;
str.reserve(100);
std::cout << "Capacity after reserve: " << str.capacity() << std::endl;
-
resize(size_t len, char c)
调整字符串的大小。如果新的大小大于原来的大小,则使用字符 ‘c’ 填充额外的空间。
std::string str = "Hello";
std::cout << "Before resize: " << str << std::endl;
str.resize(10, '!');
std::cout << "After resize: " << str << std::endl; // 输出 "Hello!!!!!"
-
总结
-
预分配内存
当你知道要构建一个非常大的字符串时,使用reserve可以提高效率。这是因为,不经常进行内存重新分配,性能会更好。
std::string largeStr;
largeStr.reserve(10000); //预分配内存空间
for(int i = 0; i < 10000; ++i) {
largeStr += "a"; //没有经常的内存重新分配
}
-
trimming
使用shrink_to_fit和resize来减少字符串的大小或内存占用。
std::string str = "Hello, World!";
str.resize(5); // str现在是"Hello"
str.shrink_to_fit(); //释放多余的内存
赋值操作 assign
-
使用 ‘=’ 运算法进行赋值
-
使用
assign(const char *s)
使用C风格字符串(字符指针)来赋值。
std::string str;
str.assign("Hello, world!");
std::cout << str; // 输出: Hello, world!
-
使用
assign(const string &str) -
使用
assign(const char *s, size_t n)
赋值一个C风格字符串的前n个字符。
-
使用
assign(const string &str, size_t pos, size_t n)
从另一个std::string的pos位置开始,取n个字符来赋值。
-
使用范围赋值
assign(T begin, T end)
使用迭代器指定的范围进行赋值。
std::string original = "Hello, world!";
std::string rangeStr;
rangeStr.assign(original.begin() + 7, original.end());
std::cout << rangeStr; // 输出: world!
-
使用
assign(size_t n, char c)
用指定数量的字符来赋值。
std::string str;
str.assign(5, '*');
std::cout << str; // 输出: *****
在实际应用中,当你处理文本或字符串数据时,经常需要提取、替换或分配新值。例如,如果你正在编写一个从网站抓取数据的程序,你可能会截取网页的某一部分,使用assign函数可以很容易地得到你想要的部分;
如果你正在编写一个游戏,你可能需要用assign(size_t n, char c)来创建一个由特定字符组成的字符串,例如创建一个用于显示玩家生命值的血条。
截取操作 substr
substr()可以允许你从一个较大的字符串中提取一个子字符串。
-
基础说明
substr()函数有两个参数:
pos(默认值为0):表示子字符串开始的位置。n(默认值为npos):表示子字符串的长度。
如果n是npos(这是其默认值),那么子字符串会从pos位置开始,直到字符串的结尾。
std::string s = "TianMx is great!";
std::string sub1 = s.substr(0, 6); // "TianMx"
std::string sub2 = s.substr(7); // "is great!"
-
sub1截取了从位置0开始的6个字符。 -
sub2从位置8开始截取直到字符串的结尾。 -
注意事项
- 如果
pos大于字符串的长度,substr()函数会抛出std::out_of_range异常。 - 如果
pos + n大于字符串的长度,substr()会返回从pos开始到字符串结束的部分。
插入操作 insert
insert()主要用于将一个字符串、字符数组、字符或者其他类型的数据插入到string的指定位置。
-
插入整个字符串到指定位置
语法:string& insert(size_t pos, const string& str);
std::string s1 = "I love coding!";
s1.insert(2, " really");
std::cout << s1; // 输出: I really love coding!
-
插入子字符串到指定位置
语法:string& insert(size_t pos, const string& str, size_t subpos, size_t sublen = npos); 在 s1 的 pos 位置插入 str 从 subpos 开始长度为 sublen 的子字符串。
std::string s1 = "I love languages!";
s1.insert(7, "programming ", 0, 11);
std::cout << s1; // 输出: I love programming languages!
-
插入重复字符到指定位置
在位置 pos 插入 n 个重复的字符 c。
std::string s1 = "Stars!";
s1.insert(5, 3, '*');
std::cout << s1; // 输出: Stars***
-
使用迭代器插入字符或字符序列
-
a. 插入重复字符
iterator insert(iterator p, size_t n, char c);
在迭代器 p 指向的位置插入 n 个字符 c。
-
b. 插入单一字符
iterator insert(iterator p, char c);
在迭代器 p 指向的位置插入字符 c。
-
插入字符序列
template <class InputIterator>
iterator insert(iterator p, InputIterator first, InputIterator last);
在迭代器 p 指向的位置插入从 first 到 last 的字符序列。
删除操作 erase
erase()函数,允许你删除指定位置的字符。
-
删除从指定位置开始的字符
string &erase(size_t pos = 0, size_t n = npos);
该方法从字符串中的 pos 位置开始删除 n 个字符。
std::string str = "Hello, beautiful World!";
str.erase(7, 10); // 删除从索引7开始的10个字符。
std::cout << str; // 输出: Hello, World!
-
使用迭代器删除字符
虽然你提到这部分内容对你而言不那么重要,但它在处理某些高级应用时非常有用,尤其是当你和其他STL容器或算法结合使用时。
-
a. 删除单一字符
iterator erase(iterator it);
这个函数删除迭代器 it 所指向的字符,并返回指向删除字符之后的位置的迭代器。
std::string str = "Hello, World!";
std::string::iterator it = str.begin() + 5;
str.erase(it);
std::cout << str; // 输出: Hell, World!
-
b. 删除字符序列
iterator erase(iterator first, iterator last);
这个函数删除从 first 到 last(不包括 last)的字符,并返回指向删除字符之后的位置的迭代器。
std::string str = "Hello, beautiful World!";
std::string::iterator it1 = str.begin() + 7;
std::string::iterator it2 = it1 + 10;
str.erase(it1, it2);
std::cout << str; // 输出: Hello, World!
交换操作
-
swap方法:交换两个字符串的内容
std::string s1 = "apple";
std::string s2 = "banana";
s1.swap(s2);
std::cout << "s1: " << s1 << ", s2: " << s2; // 输出: s1: banana, s2: apple
-
交换的实现方式
- 小字符串优化(Short String Optimization,SSO): 根据实现细节,当字符串的长度小于一定的限制(通常在15到23个字符之间,取决于具体实现)时,它可能不是存储在动态内存中,而是存储在对象内部的固定大小的数组中。这被称为SSO。在这种情况下,交换两个字符串通常涉及交换内部的数据。
- 大字符串的交换: 当字符串的长度超出SSO的范围时,它们的数据将在动态内存中存储。在这种情况下,交换操作通常涉及交换两个字符串的指针、长度和容量,而不是实际的字符数据。
总结:小数据量时交换内容,大数据量时交换地址。
连接操作 append
append()函数允许我们把两个字符串连接起来。
-
operator+=
string str1 = "Hello";
string str2 = " World";
str1 += str2;
cout << str1; // 输出 "Hello World"
-
append(const char *s): 把C风格字符串s追加到A的末尾。
string str = "Hello";
str.append(" World");
cout << str; // 输出 "Hello World"
-
append(const string &str): 这与
operator+=类似,将另一个字符串str追加到A的末尾。
string str1 = "Hello";
string str2 = " World";
str1.append(str2);
cout << str1; // 输出 "Hello World"
-
append(const char *s, size_t n): 这不仅允许你指定要追加的C风格字符串,还可以指定从其开始要追加多少字符。
string str = "Hello";
str.append(" World!!!", 6);
cout << str; // 输出 "Hello World"
-
append(const string &str, size_t pos=0, size_t n=npos): 从字符串
str的第pos个位置开始,追加n个字符到A。如果不指定n,则默认追加到str的结尾。
string str1 = "Hello";
string str2 = " Wonderful World";
str1.append(str2, 11, 5); //从第11个位置开始,追加5个字符
cout << str1; // 输出 "Hello World"
-
template: 这是一个模板方法,允许你指定一个字符范围从append(T begin, T end) begin到end来追加到A。
string str1 = "Hello";
string str2 = "ABCDEFG";
str1.append(str2.begin() + 1, str2.begin() + 4); // 追加"B", "C", "D"
cout << str1; // 输出 "HelloBCD"
-
append(size_t n, char c): 这允许你追加n个相同的字符c到A的末尾。
string str = "Hello";
str.append(5, '!');
cout << str; // 输出 "Hello!!!!!"
替换操作 replace
-
基于位置的替换
-
replace(size_t pos, size_t len, const string& str)
从位置pos开始,替换长度为len的字符为字符串str。
string str = "Hello World!";
str.replace(6, 5, "Universe");
cout << str; // 输出 "Hello Universe!"
-
replace(size_t pos, size_t len, const string& str, size_t subpos, size_t sublen = npos)
在原字符串中从位置pos开始,替换长度为len的字符,使用字符串str从subpos位置开始的sublen长度的字符。
string str = "Hello World!";
string newStr = "Universe is big";
str.replace(6, 5, newStr, 0, 8);
cout << str; // 输出 "Hello Universe!"
-
replace(size_t pos, size_t len, const char* s)
与第一个方法类似,但是使用C风格的字符串s来替换。
string str = "Hello World!";
str.replace(6, 5, "Universe");
cout << str; // 输出 "Hello Universe!"
-
replace(size_t pos, size_t len, const char* s, size_t n)
从原始字符串的pos位置开始,替换长度为len的字符为s的前n个字符。
string str = "Hello World!";
str.replace(6, 5, "Universe is big", 8);
cout << str; // 输出 "Hello Universe!"
-
replace(size_t pos, size_t len, size_t n, char c)
从原始字符串的pos位置开始,替换长度为len的字符为n个字符c。
string str = "Hello World!";
str.replace(6, 5, 3, '*');
cout << str; // 输出 "Hello ***!"
-
基于迭代器的替换
string str = "Hello World!";
str.replace(str.begin() + 6, str.begin() + 11, "Universe");
cout << str; // 输出 "Hello Universe!"
查找操作
查找操作是字符串处理中的核心功能,用于在字符串中定位特定的字符或子串。
-
find
-
size_t find(const string& str, size_t pos = 0) const;
从位置pos开始,查找子串str第一次出现的位置。
string s = "Hello, Hello!";
size_t pos = s.find("Hello");
cout << pos; // 输出 "0"
-
rfind
与find相似,但从右到左进行搜索。
-
size_t rfind(const string& str, size_t pos = npos) const;
从位置pos开始,从右到左查找子串str第一次出现的位置。
string s = "Hello, Hello!";
size_t pos = s.rfind("Hello");
cout << pos; // 输出 "7"
-
find_first_of
-
size_t find_first_of(const string& str, size_t pos = 0) const;
从位置pos开始,查找在str中的任何字符首次出现的位置。
string s = "apple";
size_t pos = s.find_first_of("aeiou");
cout << pos; // 输出 "0"
-
find_last_of
与find_first_of类似,但从右到左进行搜索。
-
find_first_not_of
-
size_t find_first_not_of(const string& str, size_t pos = 0) const;
从位置pos开始,查找第一个不在str中的字符的位置。
string s = "aaapple";
size_t pos = s.find_first_not_of("a");
cout << pos; // 输出 "3"
-
find_last_not_of
与find_first_not_of类似,但从右到左进行搜索。
Vector 容器
Vector容器其基本思想是对数组进行封装,是其能够自动管理存储空间的分配和回收,同时提供丰富的成员函数。
其基本特点:
- 连续存储的内存
- 动态数组,可以重新分配大小
- 支持随机访问,可以使用下标访问
- 插入或删除元素会导致迭代器失效
构造和析构
-
构造Vector
-
默认构造:创建一个空的
vectorstd::vector<int> v1; -
填充构造: 创建一个包含指定数量的元素,所有元素的值都相同。
vector<int> vec2(5,100); -
范围构造:通过其他容器或数组创建
vectorint arr[5] = {1,2,3,4,5}; vector<int> vec2(arr, arr+9); -
拷贝构造:通过复制另一个
vector来创建新的vectorvector<int> vec3(vec2); // 从vec3拷贝创建vec4 -
初始化列表
vector<int> vec6{1, 2, 3, 4, 5}; // 使用初始化列表创建vector
元素操作
-
reference at(int pos):返回pos位置元素的引用
-
reference front():返回首元素的引用
-
reference back():返回尾元素的引用
-
iterator begin():返回向量头指针,指向第一个元素
-
iterator end():返回向量尾指针,指向向量最后一个元素的下一个位置
-
reverse_iterator rbegin():反向迭代器,指向最后一个元素
-
reverse_iterator rend():反向迭代器,指向第一个元素前一个的位置
#include 插入和删除
-
追加元素
-
void push_back(const T& value);简单地说,它在
vector的末尾追加一个元素。 -
void emplace_back(…);此方法与
push_back类似,但它允许直接在vector末尾构造一个元素,而无需先创建临时对象。
-
在指定位置插入元素
-
iterator insert(iterator pos, const T& value);这允许在指定位置之前插入一个元素。
-
iterator emplace(iterator pos, …);与
insert类似,但允许直接在指定位置构造元素。 -
iterator insert(iterator pos, iterator first, iterator last);这允许在指定位置插入其他容器或
vector的一个范围。
-
删除元素
-
void pop_back();从
vector的尾部删除一个元素。 -
iterator erase(iterator pos);&iterator erase(iterator first, iterator last);分别删除指定位置的元素和删除指定区间的元素。
#include 特性操作
- max_size():返回
vector可能容纳的最大元素数。这通常是一个非常大的数字,由系统资源和平台限制。 - capacity():这告诉你
vector目前为止预留了多少空间。例如,即使你只有5个元素,vector可能预留了10个元素的空间。 - size():告诉你
vector中有多少个元素。 - empty():告诉你
vector是否为空。 - clear():清空
vector的所有元素,但不会减少它的容量。 - reserve(size_t size):用于预留至少
size大小的容量。如果size大于当前的容量,则重新分配内存。否则不会发生任何事情。 - shrink_to_fit():尝试减少
vector的容量以匹配其大小。实际上释放不必要的内存。 - resize(size_t size):改变
vector的大小。如果size比当前大,则新位置用默认值初始化。如果size小,则超出的元素将被销毁。 - resize(size_t size, const T &value):与上面相同,但如果
size比当前大,新位置将用给定的value初始化。
交换操作
void swap(vector // 把当前容器与v交换。
交换的是动态数组的地址。
比较操作
bool operator == (const vector
bool operator != (const vector
赋值操作
- vector &operator=(const vector &v)
- 这是一个赋值运算符,用于将一个
vector的内容复制到另一个vector。 - 示例:
vectorA = vectorB;将vectorB的内容复制到vectorA。
- 这是一个赋值运算符,用于将一个
- vector &operator=(initializer_list il)
- 使用初始化列表为
vector赋值。 - 示例:
vector这将重新为nums = {1, 2, 3}; nums = {4, 5, 6}; nums赋值为4, 5, 6。
- 使用初始化列表为
- void assign(initializer_list il)
- 功能与上面的运算符相同,但使用了不同的方法名。
- 示例:
vectornums = {1, 2, 3}; nums.assign({4, 5, 6});
- void assign(Iterator first, Iterator last)
- 使用另一个容器或相同容器的某个部分来为
vector赋值。 - 示例:
vector此时numsA = {1, 2, 3, 4, 5}; vector numsB; numsB.assign(numsA.begin(), numsA.begin() + 3); numsB包含1, 2, 3。
- 使用另一个容器或相同容器的某个部分来为
- void assign(const size_t n, const T& value)
- 将
vector的内容设置为n个相同的元素。 - 示例:
vector这将使nums; nums.assign(5, 100); nums的内容为100, 100, 100, 100, 100。
- 将
#include Vector嵌套
Vector容器的一个强大特性就是它可以嵌套其他容器,包括其自身。这使我们能够创建多维的数据结构。比如vector,我们有一个外部vector名为v,它的每个元素都是一个vector(即一个整数列表)。
#include 。
vector<int> v; // 创建一个容器v,它将作为容器vv的元素。
v = { 1,2,3,4,5 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
v = { 11,12,13,14,15,16,17 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
v = { 21,22,23 }; // 用统一初始化列表给v赋值。
vv.push_back(v); // 把容器v作为元素追加到vv中。
// 用嵌套的循环,把vv容器中的数据显示出来。
for (int ii = 0; ii < vv.size(); ii++)
{
for (int jj = 0; jj < vv[ii].size(); jj++)
cout << vv[ii][jj] << " "; // 像二维数组一样使用容器vv。
cout << endl;
}
}
迭代器
迭代器的设计目的是提供一个像指针一样的行为,访问容器中元素的通用方法。基于迭代器,我们可以使用相同的代码来迭代并操作不同容器中的元素,而不必关心容器的具体实现。
迭代器有基本操作有:赋值(=)、解引用(*)、比较(==和 !=)、从左向右遍历(++)
一般情况下吗,迭代器是指针和移动指针的方法,因此他们被称为指针类似的对象。
-
迭代器的分类
-
正向迭代器:
正向迭代器它允许你从到到尾遍历容器。可以使用
++来移动迭代器到写一个元素。容器名<元素类型>::iterator 迭代器名; // 正向迭代器。容器名<元素类型>::const_iterator 迭代器名; // 常正向迭代器。相关的成员函数:
iterator begin();const_iterator begin();const_iterator cbegin(); // 配合auto使用。iterator end();const_iterator end();const_iterator cend(); -
双向迭代器
双向迭代器具有正向迭代器的所有功能,并增加了向前移动的能力,即可以使用
--运算符。容器名<元素类型>:: reverse_iterator 迭代器名; // 反向迭代器。容器名<元素类型>:: const_reverse_iterator 迭代器名; // 常反向迭代器。相关的成员函数:
reverse_iterator rbegin();const_reverse_iterator crbegin();reverse_iterator rend();const_reverse_iterator crend(); -
随机访问迭代器
随机访问迭代器具有双向迭代器的所有功能,并增加了直接跳到某个位置的能力。
随机访问迭代器支持的操作:
-
用于比较两个迭代器相对位置的关系运算(<、<=、>、>=)。
-
迭代器和一个整数值的加减法运算(+、+=、-、-=)。
-
支持下标运算(iter[n])。
-
-
输入和输出迭代器
这些迭代器特别设计用于数据流。输入迭代器用于从数据源(如输入流)读取数据,而输出迭代器用于写入数据到目标(如输出流)。
// 从控制台读取数据到vector std::istream_iterator<int> start(std::cin); std::istream_iterator<int> end; std::vector<int> nums(start, end); // 将vector数据写入控制台 std::copy(nums.begin(), nums.end(), std::ostream_iterator<int>(std::cout, " "));
-
失效的迭代器
当你对容器进行修改操作时(如:删除、添加元素),容器内部的结构可能会发生变化,导致已经获取的迭代器无效。
std::vector vec = {1, 2, 3, 4, 5};
auto it = vec.begin() + 2;
vec.push_back(6);
// 此时,"it" 可能已经失效,尝试使用它可能会导致未定义的行为。
std::cout << *it << std::endl; // 未定义的行为
-
超出范围
end() 和 rend() 函数返回的迭代器并不指向容器中的实际元素,而是指向容器的“结束”位置。尝试解引用这些迭代器会导致未定义的行为。
std::vector<int> vec = {1, 2, 3, 4, 5};
auto it = vec.end();
// 错误的操作,会导致未定义的行为
int value = *it;
cout << value << endl;
-
不同类型的迭代器之间的转换
不同容器的迭代器类型是不同的,不能互相替代。例如,vector 的迭代器和 list 的迭代器在内部工作方式上有很大差异。
std::vector<int> vec = {1, 2, 3};
std::list<int> lst = {4, 5, 6};
std::vector<int>::iterator vecIt = vec.begin();
// 下面的赋值是错误的
// std::list::iterator lstIt = vecIt;
基于范围的for循环
基于范围的for循环时C++11中新增的一个特性,旨在简化在结合上迭代的代码。它自动处理迭代的开始和结束,使代码更加简洁且易于阅读。
std::vector<int> numbers = {1, 2, 3, 4, 5};
for (int num : numbers) {
std::cout << num << " ";
}
// 输出: 1 2 3 4 5
int num定义了循环中用于接收每个元素的变量。在每次循环迭代时,num都会被赋予numbers向量中的下一个整数值。
背后的伪代码:
{ auto it = numbers.begin(); auto it_end = numbers.end(); for (; it != it_end; ++it) { int num = *it; std::cout << num << " "; } }
-
注意点
-
迭代的范围:基于范围的for循环可以用于任何支持
begin()和end()的对象,如STL容器(vector,list,set, …)和数组。 -
数组退化为指针:当数组作为函数参数时,它退化为指针。因此,在函数内部,您不能直接用它作为基于范围的for循环的范围,除非还传递数组的大小。
-
结构体和类的迭代:当容器中的元素是结构体或类时,为了避免不必要的复制,建议使用引用。加上const可以确保不会修改原始元素。
struct Point { int x, y; }; std::vector<Point> points = {{1,2}, {3,4}, {5,6}}; for (const Point &p : points) { std::cout << "(" << p.x << ", " << p.y << ") "; } -
迭代器失效:这通常在修改容器时出现。在基于范围的for循环中,最好避免对容器进行修改,以避免迭代器失效。
基于范围的for循环在现代C++代码中非常普遍,它大大简化了代码,减少了错误,并提高了代码的可读性。实际上,在C++20中,基于范围的for循环进一步增强,允许多个变量进行结构化绑定。
std::map<std::string, int> map = {{"apple", 5}, {"banana", 8}};
for (const auto &[key, value] : map) {
std::cout << key << ": " << value << std::endl;
}
list容器
list 是Cpp标准库中的一个双向链表容器,它允许快速的插入和删除操作,与vector容器相比,list在内部实现上截然不同。
list容器是一个双向链表,所以它不支持随机访问。这就意味着你不能像使用vector那样使用下标直接访问其元素。
由于链表需要额外的空间来存储前后指针,list通常有更大的内存开销。
构造函数
#include
#include 特性操作
大多数和上面的vector容器一样,不做赘述。
#include
int main() {
std::list<int> lst = {1, 2, 3, 4, 5};
// 使用size()
std::cout << "Size of lst: " << lst.size() << std::endl; // Output: 5
// 使用empty()
std::cout << "Is lst empty? " << (lst.empty() ? "Yes" : "No") << std::endl; // Output: No
// 使用resize()
lst.resize(7);
std::cout << "Size after resizing to 7: " << lst.size() << std::endl; // Output: 7
for(auto i: lst) {
std::cout << i << " "; // Output: 1 2 3 4 5 0 0
}
std::cout << std::endl;
lst.resize(4);
std::cout << "Size after resizing to 4: " << lst.size() << std::endl; // Output: 4
for(auto i: lst) {
std::cout << i << " "; // Output: 1 2 3 4
}
std::cout << std::endl;
lst.resize(6, 100);
std::cout << "Size after resizing to 6: " << lst.size() << std::endl; // Output: 6
for(auto i: lst) {
std::cout << i << " "; // Output: 1 2 3 4 100 100
}
std::cout << std::endl;
// 使用clear()
lst.clear();
std::cout << "Size after clearing: " << lst.size() << std::endl; // Output: 0
}
元素操作
- front()
front()函数返回容器的第一个元素的引用。如果容器为空,此函数的行为是未定义的。const T& front() const版本返回一个常量引用,意味着你不能使用这个函数来修改容器的第一个元素。
- back()
back()函数返回容器的最后一个元素的引用。如果容器为空,此函数的行为是未定义的。const T& back() const版本返回一个常量引用,这意味着你不能使用这个函数来修改容器的最后一个元素。
#include
int main() {
std::list<int> lst = {1, 2, 3, 4, 5};
// 使用front()
std::cout << "First element of lst: " << lst.front() << std::endl; // Output: 1
// 使用back()
std::cout << "Last element of lst: " << lst.back() << std::endl; // Output: 5
// 修改容器的第一个和最后一个元素
lst.front() = 10;
lst.back() = 50;
for(auto i: lst) {
std::cout << i << " "; // Output: 10 2 3 4 50
}
std::cout << std::endl;
const std::list<int> const_lst = {6, 7, 8, 9, 10};
// 在常量列表上使用front()和back()
std::cout << "First element of const_lst: " << const_lst.front() << std::endl; // Output: 6
std::cout << "Last element of const_lst: " << const_lst.back() << std::endl; // Output: 10
}
赋值操作
#include
int main() {
std::list<int> lst1 = {1, 2, 3};
std::list<int> lst2 = {4, 5, 6};
// 使用operator=赋值
lst1 = lst2;
for (int num : lst1) {
std::cout << num << " "; // Output: 4 5 6
}
std::cout << std::endl;
// 使用统一初始化列表赋值
lst1 = {7, 8, 9};
for (int num : lst1) {
std::cout << num << " "; // Output: 7 8 9
}
std::cout << std::endl;
// 使用assign()方法赋值
lst1.assign({10, 11, 12});
for (int num : lst1) {
std::cout << num << " "; // Output: 10 11 12
}
std::cout << std::endl;
// 使用迭代器范围赋值
lst1.assign(lst2.begin(), lst2.end());
for (int num : lst1) {
std::cout << num << " "; // Output: 4 5 6
}
std::cout << std::endl;
// 使用数量和值进行赋值
lst1.assign(3, 100);
for (int num : lst1) {
std::cout << num << " "; // Output: 100 100 100
}
std::cout << std::endl;
}
交换、反转、排序、归并
- swap()
void swap(list&l);
交换两个list容器的内容。它交换的是链表结点的地址,所以该操作是非常高效的,时间复杂度为 O(1)。
- reverse()
void reverse();
反转list容器中的元素顺序。这个操作也是高效的,因为它只需要更改链表节点的指针方向。
- sort()
void sort();
对list容器中的元素进行升序排序。void sort(_Pr2 _Pred);
根据给定的二元比较函数_Pred对list容器中的元素进行排序。注意:此函数是稳定的,也就是说相等元素的相对顺序不会改变。
- merge()
void merge(list&l);
将另一个list容器(它也应该是已排序的)归并到当前容器中,使当前容器仍然保持排序状态。这是一个高效操作,因为它只是在内部重新连接节点。
#include
#include 比较操作
bool operator == (const vector
bool operator != (const vector
#include
int main() {
std::list<int> list1 = {1, 2, 3, 4, 5};
std::list<int> list2 = {1, 2, 3, 4, 5};
std::list<int> list3 = {5, 4, 3, 2, 1};
std::list<int> list4 = {1, 2, 3};
// 使用operator==
if (list1 == list2) {
std::cout << "list1 is equal to list2." << std::endl;
} else {
std::cout << "list1 is not equal to list2." << std::endl;
}
// 使用operator!=
if (list1 != list3) {
std::cout << "list1 is not equal to list3." << std::endl;
} else {
std::cout << "list1 is equal to list3." << std::endl;
}
if (list1 != list4) {
std::cout << "list1 is not equal to list4." << std::endl;
} else {
std::cout << "list1 is equal to list4." << std::endl;
}
return 0;
}
插入和删除
-
插入
1.
push_back(const T& value)将元素添加到容器的尾部。
2.
emplace_back(…)在容器尾部直接构造一个元素。
3.
insert(iterator pos, const T& value)在指定位置之前插入元素。
4.
emplace(iterator pos, …)在指定位置之前直接构造元素。
5.
insert(iterator pos, iterator first, iterator last)在指定位置插入一个范围的元素。
6.
push_front(const T& value)在容器的开头插入一个元素。
7.
emplace_front(…)在容器的开头直接构造一个元素。
-
删除
1.
pop_back()从容器尾部移除一个元素。
2.
erase(iterator pos)删除指定位置的元素。
3.
erase(iterator first, iterator last)删除指定范围的元素。
#include
int main() {
std::list<int> myList, anotherList;
// 1. push_back
myList.push_back(5);
myList.push_back(6);
// 2. emplace_back
myList.emplace_back(9);
// 3. insert
auto it = myList.begin();
myList.insert(++it, 7);
// 4. emplace
it = myList.begin();
myList.emplace(++it, 8);
// 5. range insert
anotherList = {10, 11};
it = myList.begin();
myList.insert(++it, anotherList.begin(), anotherList.end());
// 6. pop_back
myList.pop_back();
// 7. erase single element
it = myList.begin();
myList.erase(++it);
// 8. erase range
auto it1 = myList.begin(), it2 = myList.begin();
std::advance(it1, 2);
std::advance(it2, 3);
myList.erase(it1, it2);
// 9. push_front
myList.push_front(4);
// 10. emplace_front
myList.emplace_front(3);
// Printing the list after all operations
for (int val : myList) {
std::cout << val << " ";
}
std::cout << std::endl;
return 0;
}
-
特性删除操作
-
void remove(const T& value);功能:从链表中删除所有值等于
value的元素。 -
void remove_if(_Pr1 _Pred);功能:删除链表中所有满足一定条件的元素。该条件由一元谓词函数
_Pred决定。 -
void unique();功能:删除链表中所有相邻的重复元素,只保留一个。
-
#include
int main() {
std::list<int> numbers = {1, 2, 3, 3, 4, 4, 4, 5};
numbers.remove(4);
for (int num : numbers) std::cout << num << " "; // 输出: 1 2 3 3 5
std::cout << "\n";
numbers = {1, 2, 3, 4, 5, 6};
numbers.remove_if([](int n) { return n % 2 == 0; });
for (int num : numbers) std::cout << num << " "; // 输出: 1 3 5
std::cout << "\n";
numbers = {1, 1, 2, 2, 2, 3, 4, 4};
numbers.unique();
for (int num : numbers) std::cout << num << " "; // 输出: 1 2 3 4
return 0;
}
连接操作
splice 函数:
void splice(iterator position, list& other):将other中的所有元素移到*this中,位于position之前。void splice(iterator position, list& other, iterator i):将i指向的元素从other移到*this,位于position之前。void splice(iterator position, list& other, iterator first, iterator last):将[first, last)范围的元素从other移到*this,位于position之前。
注意:splice 会修改 other 容器,因此除非特别需要,否则不要在同一个循环中同时迭代 *this 和 other。
#include
int main() {
std::list<int> list1 = {1, 2, 3};
std::list<int> list2 = {4, 5, 6};
// 将 list2 的所有元素连接到 list1 的末尾
list1.splice(list1.end(), list2);
// list2 现在应该是空的
std::list<int> list3 = {7, 8, 9};
auto it = list3.begin();
std::advance(it, 1);
// 将 list3 中的第二个元素(值为8)连接到 list1 的第二个位置
list1.splice(std::next(list1.begin()), list3, it);
// 打印 list1 来查看结果
for (int val : list1) {
std::cout << val << " ";
}
std::cout << std::endl;
return 0;
}
stack容器
stack是一个容器适配器,它提供了栈的功能。实际上stack不是一个真正的容器,而是基于其他STL容器的一个适配器。默认情况,它是基于deque实现的,但你也可以指定其他容器(如:vector、list等)作为其底层实现。
构造函数
-
默认构造函数
explicit stack(const Container& cont = Container());该构造函数创建一个空的
stack对象。如果提供了一个底层容器cont,则stack会用其内容进行初始化;否则,它会使用底层容器的默认构造函数创建一个空容器。 -
拷贝构造函数
stack(const stack& other);该构造函数创建一个新的
stack对象,并复制other中的所有元素。注意,此构造函数只复制元素,不复制底层容器的属性。 -
移动构造函数
stack(stack&& other);该构造函数将
other中的所有元素移动到新创建的stack对象中。之后,other将为空。 -
初始化列表构造函数 (如果底层容器支持):
stack(std::initializer_list<T> init, const Container& cont = Container());
简单完整示例:
#include
int main() {
// 使用默认构造函数创建一个空stack
std::stack<int> s1;
// 使用初始化列表和std::vector作为底层容器
std::stack<int, std::vector<int>> s2({1, 2, 3, 4, 5});
// 使用一个已存在的list作为底层容器
std::list<int> lst = {6, 7, 8, 9, 10};
std::stack<int, std::list<int>> s3(lst);
// 使用拷贝构造函数
std::stack<int, std::vector<int>> s4(s2);
// 打印stack s2 和 s4 的内容
std::cout << "Elements of s2: ";
while (!s2.empty()) {
std::cout << s2.top() << " ";
s2.pop();
}
std::cout << "\nElements of s4: ";
while (!s4.empty()) {
std::cout << s4.top() << " ";
s4.pop();
}
return 0;
}
特性操作
栈的主要特性是LIFO(last in first out)。
-
push():在栈顶添加一个元素
void push(const T& value); -
pop():移除栈顶的元素。注意这个函数不返回栈顶元素的值。
void pop(); -
top():返回栈顶元素的引用。常量版本是返回一个常量引用,非常量版本返回一个可修改的引用。
bool empty() const; -
empty()
-
size()
-
swap():交换两个栈的内容。此操作应是无异常抛出的,但具体取决于底层容器的
swap操作是否为noexcept。void swap(stack& other) noexcept(/* see below */);
std::stack 没有提供直接访问其内部元素或迭代器的功能。这是为了确保其 LIFO 特性。如果你需要访问或迭代栈内部的元素,可能需要考虑直接使用底层容器(如 std::vector、std::list 或 std::deque)或使用其他数据结构。
简单示例:
#include 比较操作
Relational Operators:
==和!=:这两个操作符用于比较两个栈的内容是否相等或不相等。<、<=、>、>=:这些操作符用于按字典顺序比较两个栈的内容。
字典顺序
当我们说“按字典顺序”或“词典式”比较时,我们是指按照在字典中列出词语的顺序进行比较。这种比较方式是基于序列或列表的元素逐个进行的。
对于两个序列进行词典式比较,以下是基本规则:
- 逐元素比较:从第一个元素开始,逐个比较两个序列的对应元素。
- 首个不同元素决定顺序:在比较过程中,一旦遇到两个不相等的元素,那么这两个元素的顺序就决定了整个序列的顺序。
- 较短序列先结束:如果一个序列在另一个序列之前结束(即它的长度更短),并且它们的共有部分都是相同的,那么较短的序列在词典顺序上被认为是较小的。
- 完全相同的序列:如果两个序列从开始到结束的所有元素都相同,那么它们在词典顺序上是相等的。
用一个简单的例子来解释,假设我们有两个单词:apple 和 appetite。
- 首先,比较它们的第一个字符:
a和a,它们是相同的。 - 然后,比较第二个字符:
p和p,也相同。 - 第三个字符:
p和p,仍然相同。 - 第四个字符:
l和e,不同了。由于l在字母表中位于e之后,所以apple在词典顺序上是大于appetite的。
queue容器
queue容器模拟了队列这一先进先出(FIFO)的数据结构。queue容器是的逻辑结构是队列,但它的物理结构可以是数组或链表。queue主要用于多线程之间的数据共享。
queue容器不支持迭代器。
构造函数
-
默认构造函数
queue(); -
拷贝构造函数
queue(const queue& q); -
移动构造函数
queue(queue&& q);
常用函数
-
入队操作
void push(const T& value);将给定的元素
value添加到队列的尾部。 -
就地构造元素并入队 (C++11 引入)
void emplace(…);使用给定的参数直接在队尾就地构造一个元素。这种方法通常更高效,因为它避免了额外的拷贝或移动操作。
-
获取队列大小
size_t size() const;返回队列中的元素个数。
-
判断队列是否为空
bool empty() const;如果队列为空则返回
true,否则返回false。 -
访问队头元素
T &front();返回队列的头部元素。注意,这返回的是可修改的引用。
-
只读方式访问队头元素
const T &front() const;返回队列的头部元素,但是返回的是只读的引用,不能用来修改队头元素。
-
访问队尾元素
T &back();返回队列的尾部元素。和
front()类似,这也返回的是可修改的引用。 -
只读方式访问队尾元素
const T &back() const;返回队列的尾部元素,但是返回的是只读引用,不能用来修改队尾元素。
-
出队操作
void pop();删除队列的头部元素。这个操作不会返回被删除的元素。
下面是一个简单示例:
#include 其他操作
示例内容如下:
#include deque容器
-
物理结构
- 分段连续的存储:不同于
vector的单一连续内存块,deque采用多个连续的分段空间来存储数据。每个分段空间都有固定的长度,并存放连续的元素。 - 中控数组:为了使得这些分段能被统一管理和高效访问,
deque使用一个中控数组来存放所有分段的首地址。因此,虽然整体上deque不是连续存储的,但由于中控数组的存在,可以实现近似连续的访问效果。 - 动态增长:当
deque的一端分段空间填满后,它会动态地分配新的空间,并更新中控数组,以容纳更多的元素。
-
迭代器
- 随机访问:deque提供了随机访问迭代器,这意味着我们可以在常数时间内访问任意元素,虽然实际的访问时间可能略长于vector,因为需要先通过中控数组。
- 复杂性:由于deque的分段存储特性,其迭代器的实现较为复杂。但对于用户来说,使用方法与其他容器类似。
-
特点
- 高效的两端操作:deque在其两端(头部和尾部)插入或删除元素的效率非常高,不需要像vector那样移动其他元素。
- 中间插入效率:在deque的中间插入或删除元素的效率相对较低,因为涉及到多段的元素移动。
- 随机访问性能:虽然deque支持随机访问,但由于其分段存储结构和中控数组的存在,其随机访问效率略低于vector。
- 空间使用:由于分段连续的存储特性,deque在空间使用上可能略微浪费,因为每个分段可能不会完全填满
构造函数
构造函数和之前的vector list等容器都大差不差,唯一需要注意的一点是,当我们使用迭代器或指针表示范围来构造函数(不光构造函数)时,这个范围总是表示为一个半开区间[first, last)。这意味着范围包括first所指的元素,但不包括last所指向的元素。
#include 添加函数
deque它允许在其两端进行插入和删除操作(其物理结构是分段的连续空间)。
简单示例:
+-----+ +-----+ +-----+
| seg |<--->| seg |<--->| seg |
+-----+ +-----+ +-----+
每个 seg(段)都包含多个元素,但所有的 seg 本身并不是物理连续的。为了跟踪所有这些段,deque 维护了一个中心控制块,其中包含指向这些段的指针。
-
添加元素的函数操作
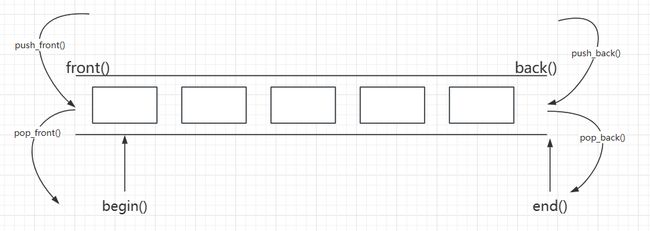
-
push_front(const T& x)
在deque的前端插入一个元素。 -
push_back(const T& x)
在deque的尾端添加一个元素。 -
insert(iterator it, const T& x)
这个函数在给定的迭代器it所指向的位置之前插入一个元素。 -
insert(iterator it, int n, const T& x)
这个函数在给定的迭代器 it 所指向的位置之前插入 n 个相同的元素。 -
insert(iterator it, iterator first, iterator last)
这个函数在给定的迭代器
it所指向的位置之前插入由迭代器范围[first, last)指定的元素。
简答示例:
#include 删除函数
-
pop_front() -
pop_back() -
erase(iterator position) -
erase(iterator first, iterator last)
这个函数用于删除由迭代器范围[first, last)指定的元素。 -
clear()
这个函数用于删除deque中的所有元素。
下面是简单示例:
#include 访问函数
-
at(size_t index) -
operator[] (size_t index) -
front() -
back() -
data()
返回一个指向deque的第一个元素的指针,这允许C-style数组访问。但是,需要注意的是,由于deque的分段内部表示,这个指针可能不会指向连续的内存区域。
注意:
- 使用
at()函数时总是安全的,因为它会检查索引是否在有效范围内。如果索引超出界限,at()会抛出一个out_of_range异常。 - 使用
operator[]时必须小心,因为它不执行边界检查。如果索引超出界限,结果是未定义的,并可能导致程序崩溃或其他未定义的行为。 front()和back()函数在调用时也要小心,确保deque不是空的,否则它们的行为是未定义的。
#include 容量函数
-
size() -
max_size() -
resize(size_t newSize) -
empty() -
shrink_to_fit()
简答示例:
#include 特殊操作
assign()
为deque分配新值,替换其当前内容。
swap()
交换两个deque容器的内容。
emplace_front() & emplace_back()
在deque的前端或末端直接构造元素。
emplace()
在指定的位置直接构造元素。
简答示例:
#include set& multiset容器
set 和 multiset都是基于红黑树实现的,能够确保元素总是按特定的顺序排序。
-
set是一个集合容器,其中的元素总是唯一的,因此它们的值不能重复。 -
multiset允许容器里有重复的元素。
构造函数
全都和上面容器的构造函数示例一样。
#include 插入和删除
-
插入操作
-
单一元素插入
使用
insert函数插入一个元素。它返回一个pair,其中.first是一个迭代器,指向插入的元素或是已经存在的元素,.second是一个bool值,表示元素是否被成功插入(只对set有效,因为multiset允许重复)。std::set<int> s; auto result = s.insert(5); if (result.second) { std::cout << "Inserted successfully!" << std::endl; } -
范围插入
可以一次性插入一个范围的元素。
std::vector<int> v = {1, 2, 3, 4, 5}; std::set<int> s; s.insert(v.begin(), v.end()); -
使用初始化列表插入
std::set<int> s; s.insert({1, 2, 3, 4, 5});、
-
-
删除操作
-
通过迭代器删除
使用
erase函数可以通过指定一个迭代器来删除一个元素。std::set<int> s = {1, 2, 3, 4, 5}; auto it = s.find(3); if (it != s.end()) { s.erase(it); } -
通过键删除
直接使用元素值删除元素。这将删除与给定值匹配的元素(在
multiset中可能删除多个)。s.erase(3); // 删除值为3的元素 -
通过迭代器范围删除
可以删除一个迭代器范围内的所有元素。
auto start = s.find(2); auto end = s.find(5); s.erase(start, end); // 删除从2开始到5(不包括5)的所有元素 -
清空
s.clear();
注意:当插入元素时,
set和multiset不会改变已经存在的元素的位置。这意味着迭代器、指针和引用在插入时仍然有效。然而,当元素被删除时,指向它们的迭代器、指针和引用都会变得无效。 -
大小与交换
#include 特性操作
-
查找操作
-
find(key):查找具有特定键值的元素。如果找到,则返回指向该元素的迭代器;否则,返回
end()。 -
count(key):返回与特定键匹配的元素数。对于
set,结果是 0 或 1;对于multiset,结果可以是任何非负整数。 -
lower_bound(key)和upper_bound(key):返回特定键值的范围的开始和结束迭代器。
-
equal_range(key):返回一个迭代器对,表示与给定键匹配的连续元素范围。
-
#include -
emplace 和 emplace_hint
这两个函数提供了在容器中就地构造元素的方式,而不需要先创建元素然后再插入。它们可以提高效率,因为它们可能减少了不必要的临时对象的构造和销毁。
-
emplace(args...):就地构造并插入元素。 -
emplace_hint(position, args...):在指定位置附近尝试就地构造并插入元素,可能提高插入效率。
set<std::pair<int, std::string>> s; s.emplace(1, "one"); -
set与multiset的区别
Multiset可以看做是set的一个拓展版本。它继承了set的所有特性,但是与set最大的区别在于,multiset允许存储重复元素。
插入操作:对于 multiset,只要给定的数据既不是非法数据也不是空数据,insert() 操作都会成功,无论这个数据是否已经存在于容器中。而在 set 中,如果尝试插入已经存在的元素,该元素不会被插入。
查找操作:multiset 的 find() 函数:当使用 find() 在 multiset 中搜索一个特定的值时,返回的是与该值匹配的第一个元素的迭代器。即使有多个相同的值存在,find() 也只返回第一个。如果没有找到匹配的元素,它返回 end() 迭代器。
与 find() 类似,lower_bound() 在 multiset 中也是返回匹配值的第一个元素的迭代器。其实,对于 multiset 中的所有返回迭代器位置的函数(如 lower_bound(), upper_bound()),它们都会返回与给定值匹配的第一个元素的位置。
pair键值对
pair是stl中一个模板类,他允许我们将两个数据组合成一个单一的数据。
使用:pari来定义。
内部定义:
template <typename T1, typename T2>
struct pair{
T1 first;
T2 second;
};
pair容器中持有两个元素,一个称为first,另一个称为second。这两个元素可以是相同的类型,也可以是不同的类型。
-
make_pair
make_pair函数用于简化pair对象的创建。其优点是可以自动推导参数类型,使得我们不必显示地指定pair中元素的类型。
用法:
int main() {
auto p = make_pair(1, "Hello");
cout << p.first << " " << p.second << endl; // 1 Hello
// 这里,p 的类型自动推导为 std::pair-
实现
make_pair的实现相对简单。它是一个模板函数,接受两个参数并返回一个由这两个参数类型组成的pair对象。以下是大致的实现:
template <typename T1, typename T2>
std::pair<T1, T2> make_pair(T1 x, T2 y) {
return pair<T1, T2>(x, y);
}
-
注意
- 引用类型:
make_pair在处理引用时会有一些特殊的行为。例如,如果你传递一个int&给make_pair,它将创建一个pair,其中的元素类型是int,而不是int&。 - 与
auto关键字的结合使用:make_pair通常与auto关键字一起使用,使得类型自动推导更加简洁。
map & multimap容器
map和multimap是关联容器,它存储键值对的元素,并根据键值对排序。map确保每个键值对之间都是唯一的,而multimap允许多个元素拥有相同的键。
构造和初始化
#include 插入操作
主要说一下和上面几个容易有不同的几个插入函数。
-
emplace_hint()
它允许你提供一个“提示”迭代器,表明新元素应该被插入的位置。如果你已知元素应该插入的大致位置,emplace_hint()会提高性能。
-
insert_or_assign()insert_or_assign()是map容器特有的,它插入一个新键值对或更新现有键的值。如果键已经存在,它的值将被分配给新的值。 -
try_emplace()这也是
map特有的。与emplace相似,但只有在键不存在的情况下才插入。
由于 multimap 允许多个相同的键,所以不支持 insert_or_assign() 和 try_emplace()。
#include 删除操作
对于map和multimap可以使用erase()删除。
#include 查找和统计
-
find()
-
如果找到该键,则返回一个指向该键的迭代器;否则,返回
end()迭代器。 -
注意: 在
map和multimap中都可使用。但在multimap中,如果存在多个具有相同键的元素,find()只会返回第一个匹配元素的迭代器。
-
count()
- 计算具有特定键的元素的数量。
- 具有该键的元素的数量。
- 对于
map,因为键是唯一的,所以count()的结果只能是 0(不存在)或 1(存在)。但对于multimap,这是一个非常有用的方法,因为你可以有多个具有相同键的元素。
-
equal_range()
-
返回一个迭代器对,这对迭代器定义了与给定键相匹配的所有元素的范围。
-
一个
pair,其中first是指向第一个匹配元素的迭代器,second是指向最后一个匹配元素之后的元素的迭代器。 -
在
map中,这个方法的返回的迭代器对的两个成员要么是相同的(如果键不存在),要么first指向该键,second指向下一个键。但在multimap中,这个方法特别有用,因为你可能有多个具有相同键的元素。
#include