大数据笔记--Hive(第一篇)
目录
一、Hive
1、概述
2、Hive和数据库的比较
3、特点
①、优点
②、缺点
二、Hive的安装
1、概述
2、安装步骤
3、Hive运行日志
4、参数配置
一、Hive

1、概述
Hive原本时有Facebook公司开发后来贡献给了Apache的一套用于进行数据仓库管理的机制
Hive提供了类SQL(HQL,Hive QL)语句来管理HDFS上的大量数据,底层会将SQL转化为MapReduce来交给Hadoop YARN执行,因此,Hive的执行效率相对比较低,所以Hive适合于离线批处理场景。
2、Hive和数据库的比较
①、查询语言:数据库提供了标准的SQL语言,符合三范式的设计;Hive提供了类SQL语言,不完全符合SQL的规则。
②、数据存储位置:数据库往往是将数据落地到本地磁盘上,以文件形式来存储;Hive是将数据落地到HDFS上。
③、数据可靠:数据库如果不配置,那么往往是不可靠,即意味着单台服务器宕机,那么数据就会暂时丢失;Hive的数据基于HDFS来存储,HDFS支持多副本机制,那么也就意味着即使某一台服务器宕机也不会产生数据的丢失。
④、数据更新:数据库往往是实时捕获数据(例如注册、订单数据等都是实时产生的),因此数据库中的数据会进行大量频繁的读写;Hive中存储的数据往往是历史数据,因此数据本身一般不会产生读写。
⑤、索引:数据库中一般会自动针对主键来建立主键索引,在使用过程中也可以针对其他字段来手动建立索引;由于Hive管理的数据量相对比较大,所以在建表的时候并不会扫描数据,因此不会自动建立索引。
⑥、执行引擎:数据库往往会提供自己的执行引擎;Hive是将SQL转化为MapReduce来执行,因此Hive是基于Hadoop YARN来执行的。
⑦、可扩展性:数据库要严格遵循ACID的定义,所以数据库的扩展能力较差(到目前为止,最大的数据库集群Oracle支持最多不超过100台服务器);Hive是基于HDFS来存储,HDFS的集群规模就决定了Hive集群的扩展规模。
⑧、数据规模:数据库因为集群规模的限制,所以能存储GB级别的数据;Hive基于HDFS,因此能够轻松的存储上TB级别的数据甚至于PB级别。
3、特点
①、优点
提供了类SQL来进行操作,也就意味着Hive相对易于学习,易于推广。
Hive能够批量的处理数据,因此在大数据场景中更具有优势。
避免程序员去学习MapReduce的规则,在Hive底层会自动将SQL转化为MapReduce,降低了程序员的学习成本。
支持用户自定义函数,允许用户根据需求定义当前场景可以使用的函数。
②、缺点
Hive采用了类SQL语言,使得它本身的表达能力比较有限:当需求比较复杂的时候,此时SQL的写法可能比较复杂,甚至于SQL无法表达。
Hive的效率相对比较低:本身MapReduce的执行效率就不高,Hive还要将SQL转化为MapReduce,然后才能执行,所以就导致Hive的执行效率更低。
Hive不擅长做数据挖掘。
二、Hive的安装
1、概述
①、Hive是基于Hadoop来使用的(基于HDFS来存储,基于Hadoop YARN来执行),所以Hive的版本要受Hadoop版本的影响
②、到目前为止,Hadoop2.X支持Hive1.X和Hive2.X版本,Hadoop3.X支持Hive3.X
③、Hive在安装过程中还需要改变元数据库
在Hive中,同样需要建库建表,这个时候产生的库名、表名、字段名、分区名、分桶信息、函数、数据类型等信息都属于元数据,这些数据是用于描述Hive中数据的特点,统称为元数据。
Hive的元数据是维系在关系型数据库中的(Hive管理的数据存储在HDFS上,Hive的元数据存储在数据库中)
到目前为止,Hive1.X和Hive2.X的元数据库只支持两种:Derby和MySQL。Hive3.X的元数据库还支持Oracle等数据库。如果不指定,无论是Hive的哪一个版本,都默认使用Derby(微型,单连接)来作为元数据库,就意味着Hive每次都只能允许一个用户连接,因此需要更换Hive的元数据库
2、安装步骤
①、进入/home/software,下载或者上传Hive的安装包
cd /home/software/
rz上传本地包,我们用的版本apache-hive-3.1.2-bin.tar.gz
解压: tar -xvf apache-hive-3.1.2-bin.tar.gz
重命名: mv apache-hive-3.1.2-bin hive-3.1.2
②、配置环境变量
vim /etc/profile
在文件尾部添加
export HIVE_HOME=/home/software/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/bin保存退出,重新生效
source /etc/profile
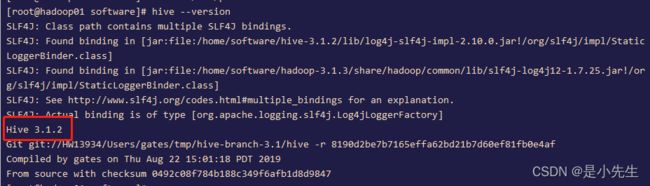
测试是否配置正确
hive --version
③、解决连接池的jar冲突
cd /home/software/hive-3.1.2/lib
rm -rf guava-19.0.jar
cp /home/software/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar ./
④、解决日志打印的jar包冲突
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.bak
⑤、Centos7中自带了残缺的MySQL发行版mariadb,需要先卸载残缺的mariadb
rpm -qa | grep -i mariadb | xargs rpm -ev --nodeps
⑥、卸载其他的MySQL
rpm -qa | grep -i mysql | xargs rpm -ev --nodeps
⑦、删除MySQL卸载遗留的文件
find / -name mysql | xargs rm -rf
find / -name my.cnf | xargs rm -rf
cd /var/lib
rm -rf mysql
⑧、安装MySQL
下载或者上传MySQL的安装包
cd /home/software/
rz
解压MySQL的安装包
tar -xvf mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar
安装MySQL,注意安装顺序,不能调换
rpm -ivh mysql-community-common-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-devel-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.33-1.el7.x86_64.rpm
⑨、启动MySQL
systemctl start mysqld
第一次安装MySQL的时候,会产生初始的密码,如果需要登录MySQL,那么首先需要去查看这个初始密码
grep 'temporary password' /var/log/mysqld.log
登录MySQL
mysql -u root -p
将初始密码输入
注意:在MySQL5.7中,密码策略相对比较复杂,要求密码中至少包含12个字符,必须包含至少1个小写字母,1个大写字母,1个数字以及1个特殊符号
更改MySQL的密码策略
set global validate_password_length=4;
set global validate_password_policy=0;
修改MySQL的密码
set password for 'root'@'localhost' = 'root';
配置MySQL的远程登录
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
quit;
重启MySQL
systemctl restart mysqld
⑩、编辑Hive
cd /home/software/hive-3.1.2/conf
编辑文件:vim hive-site.xml
添加内容:
hive.metastore.db.type mysql javax.jdo.option.ConnectionURL jdbc:mysql://hadoop01:3306/hive?useSSL=false javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword root hive.metastore.warehouse.dir /user/hive/warehouse hive.metastore.schema.verification false hive.metastore.uris thrift://hadoop01:9083 hive.server2.thrift.port 10000 hive.server2.thrift.bind.host hadoop01 hive.metastore.event.db.notification.api.auth false datanucleus.schema.autoCreateAll true
⑪、下载或上传MySQL的驱动jar包
cd ../lib
rz mysql-connector-java-5.1.27.jar

⑫、修改Hadoop的配置
cd /home/software/hadoop-3.1.3/etc/hadoop/
vim mapred-site.xml
在文件中添加如下内容:
yarn.app.mapreduce.am.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.map.env HADOOP_MAPRED_HOME=${HADOOP_HOME} mapreduce.reduce.env HADOOP_MAPRED_HOME=${HADOOP_HOME} 查看是否有初始化Hive元数据库的脚本:
cd /home/software/hive-3.1.2/scripts/metastore/upgrade/
查看是否有mysql/目录,如果没有mysql,需要上传或下载脚本 hive-mysql-tar.gz
tar -xvf hive-mysql-tar.gz

⑬、进入MySQL
mysql -u root -p
建立Hive的元数据库
create database hive;
退出数据库
quit;
⑭、初始化Hive的元数据库
schematool -initSchema -dbType mysql --verbose
启动Hadoop
start-all.sh 或者 start-dfs.sh start-yarn.sh
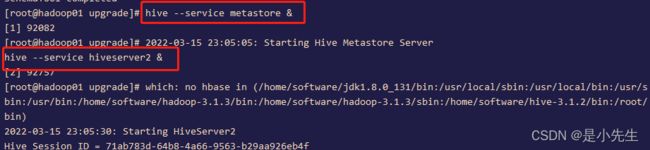
启动Hive的元数据服务
hive --service metastore &
启动hiveserver2服务
hive --service hiveserver2 &
新开窗口进入Hive的客户端
hive
3、Hive运行日志
①、Hive在运行过程中会产生运行日志,如果不指定,那么默认情况下,Hive的运行日志是放在/tmp/hive.log文件中
②、修改存放位置
进入Hive的配置文件目录
cd /home/software/hive-3.1.2/conf
复制文件
cp hive-log4j2.properties.template hive-log4j2.properties
编辑文件
vim hive-log4j2.properties
修改属性property.hive.log.dir
property.hive.log.dir = /home/software/hive-3.1.2/logs
启动Hive
hive --service hiveserver2 &
hive
4、参数配置
可以在hive-site.xml文件中来配置Hive的运行参数,这种配置方式是永久有效的,并且对所有的会话都生效
可以通过hive -hiveconf来配置Hive的运行参数,例如hive -hiveconf mapred.reduce.tasks=3;这种配置方式只在当前会话中生效,对其他会话不产生影响
在Hive的命令窗口中,可以通过set方式来配置,例如set mapred.reduce.tasks=3;同样这种方式也是只在当前会话中生效,对其他会话不产生影响
